EMNLP 2021 (Emnlp2023)


多标签文本分类是自然语言处理中的一类经典任务,训练模型为给定文本标记上不定数目的类别标签。然而实际应用时,各类别标签的训练数据量往往差异较大(不平衡分类问题),甚至是长尾分布,影响了所获得模型的效果。重采样(Resampling)和重加权(Reweighting)常用于应对不平衡分类问题,但由于多标签文本分类的场景下类别标签间存在关联,现有方法会导致对高频标签的过采样。 本项工作中,我们探讨了优化损失函数的策略,尤其是平衡损失函数在多标签文本分类中的应用。 基于通用数据集 (Reuters-21578,90 个标签) 和生物医学领域数据集(PubMed,18211 个标签)的多组实验,我们发现一类分布平衡损失函数的表现整体优于常用损失函数。研究人员近期发现该类损失函数对图像识别模型的效果提升,而我们的工作进一步证明其在自然语言处理中的有效性。
多标签文本分类是自然语言处理(NLP)的核心任务之一,旨在为给定文本从标签库中找到多个相关标签,可应用于搜索(Prabhu et al., 2018)和产品分类(Agrawal et al., 2013)等诸多场景。图 1 展示了通用多标签文本分类数据集 Reuters-21578 的样例数据(Hayes and Weinstein, 1990)。
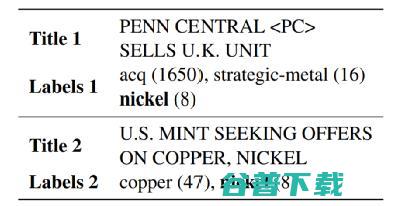
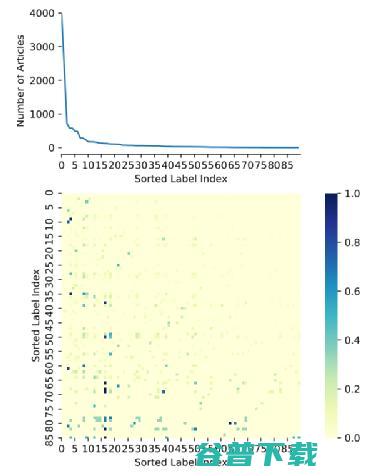
图2 Reuters-21578的长尾分布和标签连锁现象。

图3 损失函数的具体设计。

表1 实验用数据集的基本信息


罗氏集团制药部门中国 CIO 该工作来自于合作团队在生物医学领域的深度学习应用探索。相比于日常文本,生物医学领域的语料往往更专业,而标注更稀疏,导致 AI 应用面临“最后一公里”的落地挑战。本论文从稀疏标注的长尾分布等问题入手,由 CV 前沿研究引入损失函数并优化,使得既有 NLP 模型可以在框架不变的情况下将训练资源向实例较少的类别平衡,进而实现整体的模型效果提升。很高兴看到此策略在面临类似问题的日常文本上同样有效,希望继续与院校、企业在前沿技术的研究与应用上扎实共创。

版权文章,未经授权禁止转载。详情见 转载须知 。



百一测评是亚信科技(中国)旗下功能强大的,免费的企业级在线考试系统。用户群包括:[一]企业事业类:校园招聘大规模在线笔试、员工考核、人才职业测评,能力测评,技能测评;[二]学校类:K12电子作业平台、技工学校技能评测、高校知识竞赛;[三]资格证模考:在线模考试卷、资格证题库等。同时支持手机考试、电脑考试的企业级在线考试云平台和在线考试系统。

云上杭州官网-云上公司注册,简称云上杭州官网-云上公司注册,是互联网线上虚拟园区,通过互联网的办法提供线下园区几乎所有的配套服务。除电子营业执照办理外,还能提供政策申报与兑现、线上培训、引导基金等服务。

江苏湿井电器制造有限公司专业销售工业除湿机,加湿器设备公司,提供恒温恒湿机,调温除湿机,防爆除湿机,防爆除湿机,工业除湿器,工业抽湿机等,销往:长沙,武汉,沈阳除湿机,杭州,广州,南京除湿机,郑州,西安,太原,兰州,银川,西宁除湿机,乌鲁木齐,呼和浩特,海口,南宁除湿机,大连,深圳,福州,济南,石家庄,长春,昆明,沈阳抽湿机等城市,承接各种工业除湿器耐低温除湿机等科技型企业之一.

唯我品牌策划专业提供公关活动,活动策划,年会策划庆典策划开业庆典策划开业庆典,启动仪式,发布会,公关活动案例,公关活动形式,搭建制作,活动制作,舞美制作,公关传播等上千场各式活动的策划和管理经验案例在等你!

东方哲学应用传承传递传播

广州安捷救护车出租专业高危病人长途跨省转运护送,提供全国及跨国包机,专业接送其他公司不敢接不能接的重患,设备齐全,安全及时送达到目的地,一家方便、快捷、舒适的正规救护车租赁

云投稿网是国内专业的论文投稿自助平台,全天24小时自助投稿;本投稿网站收录了数千本学术期刊,方便了各界学者对期刊更好的了解,向适合自己文章的杂志投稿,丰富了我国期刊网数据资源,是国内学术期刊网中值得推荐的网站之一。

正阳纺机供销调剂公司主营二手清花机,二手气流纺设备,二手梳棉机,二手并条机,二手粗纱机,二手络筒机等二手纺织设备.

广西大胜利农资有限公司

韩国5年多次签证,韩国10年多次签证,韩国留学签证,日本3年多次签证,日本5年多次签证,美国10年多次

成都哪家医院治疗失眠较好,成都治疗失眠医院:成都棕南医院精神科,环境优美,交通方便,主任医师带队,一堆一面诊,收费透明,平价医院,一直以来,深受广大患者的好评 !地址:成都市二环路南二段19号。

GermanyTrinit德国特瑞尼特是一家专业从事采暖材料设计、生产、销售的品牌制造商,产品品类涵盖采暖管道、分集水器、电热执行器、地暖温控器、散热器阀门、地暖挤塑保温板等辅材及配件。


各位同事,大家上午好,今天是2024年1月2号,是我们新年上班的第一天,今天我们的开会内容主要是回顾2023年公司整体发展的情况,1.人员方面整个2023年是我们松松公司人员是最稳定的一年,招聘了2位兼职、离职了1位同事,但也是我们花在人力资源上最少的一年,2023年的前四个月,尤其是春节前后,应该是人心最不稳的前四个月,但是到了后半...。

健康饮用水管对于现在装修行业来说有着很大的需求,水管工程属于隐蔽工程,对于水管的质量,品牌的认可度都很高,龙胜管业品牌创办时间就很长,在市场经营已经有20多年时间,龙胜管业品质怎么样,加盟费用高吗,龙胜管业经过很多年的努力以后,能够在给水管、采暖管、开关插座、灯具照明、集成吊顶、换气扇等一些领域做的更出色,把水电建材产品做好生产和批发...。

寿司是日本的传统美食,后来传入中华,并发展成为中华民众喜爱的食品之一,有投入者想要做寿司这一行,不知道外带寿司店加盟哪一家好,中之禾餐饮就是一个不错的选择,这家店在提供堂食的同时,也为消费者提供外送业务,您可以经过网络预定或者打电话预定的方式来选择您喜爱的寿司类型,中之禾餐饮提供的寿司种类繁多,营养丰富,口感多样,深受广大消费者的喜爱...。

再过几天就是农历春节了,路边的灯笼、门上的福字、窗上的窗花,每天都在提醒我们年更近了点,打个车去赶大集、逛庙会、看舞狮,也是不少人会选择的迎春节方式,这其中被称为,太平乐,的舞狮往往会吸引不少人的眼光,与传统舞狮一样,游戏世界里也有一个舞兽少年,嘉明,,新近走进了大家的视野,并与,原神,游戏一起,走到了滴滴出行App中,2月2日,滴滴...。

2020于全体银行而言,是一场无预告的终极考验,一轮最直观的金融科技对决,疫情让网点流量骤降到接近于0,全方位挑战银行线上服务水平,检验那些连年增加的科技投入,有多少真正变作数字化、智能化的一点一滴,踏进2021,银行们迎来周密复盘、整装待发的最好时间节点,在过去这一年,银行更努力地摆脱大象转身的刻板印象,告别以往被各路创新推着走的窘...。

十年前,小红书初创,站在UGC和PGC的十字路口,小红书创始人星矢,毛文超,决心选择了,UGC,方向,一个原因是,PGC只能提供标准答案,亲身经历有时候比权威更重要,十年后,小红书用户过亿,坚持的仍是,UGC,内核,50%流量分给素人,另外50%交给算法,成为当下过亿产品独树一帜般的存在,这种,反常识,的思考和抉择,让人们看到了主流内...。

发表在其它家用投影仪品牌2024,11,2715,19雷神银翼F60是一款千元价位的投影仪,雷神本是一个显示器品牌,做投影仪还算手生,那么雷神银翼F60投影仪怎么样呢,下面就来全方面了解一下,看看雷神银翼F60投影仪是否可以满足家用观影需求,雷神银翼F60投影仪怎么样,1.光学参数在亮度方面,雷神银翼F60的实际亮度达到800CVIA...。

彩纸屋是一款专注于少儿编程学习的优秀软件。为您提供入门级别的编程界面,极大的提高了孩子们的编程学习兴趣

怎么连接远程的数据库怎么连接远程的数据库软件 选择数据库,安全性,点击新建链接服务器。选择链接服务器属性,常规,输入名称:TEST,选择ORACLE数据库提供程序,输入名称、数据源。进行安全性设置。首先本地通过在安装目录bin下disql命

8月二手房、新房成交量同比下降,北京楼市静待房地产新政,房源,郭毅,二手房,签约量,房地产,北京市,北京楼市,新房成交量,新建商品住宅

CAD迷你画图,CAD迷你画图是一款小巧便捷、经典的CAD制图软件,功能专业齐全,简洁易用。CAD迷你画图免费版支持PDF随心转换、云图库、云字体、智能3D等等众多黑科技,您可以免费下载。

站长字体(font.chinaz.com)提供毛笔字体免费下载,以及毛笔字体在线预览服务,您可以实时预览并下载您所需要的字体。

10月6日消息,以,马力欧红色,作为主配色的,NintendoSwitch,OLED版,马力欧红色套装,于今日全球同步发售,建议零售价2599元,官方表示,,NintendoSwitch,OLED版,马力欧红色套装,的主色调,是经典角色马力欧服装外观中的,马力欧红色,,基座背面还设计有马力欧的剪影和隐藏金币,此外,套装中的2只Joy,...。

凭什么她有最新、最热门的电影和歌曲;凭什么我们都要听她指挥,她说怎样就怎样;凭什么小主人都不和我玩游戏了;凭什么大家都不用我视频了,只要喊她一声就能和爷爷奶奶通话,一回来就围着她转……,,,不要问凭什么,要问什么屏,这是,继今年4月20日,腾讯首次发布其智能音箱产品,腾讯听听之后,腾讯在该领域的又一动作,2018年12月18日下午...。

发表在大眼橙投影仪2024,10,2809,26大眼橙C1D高亮版是大眼橙C1D的升级版本,主要提升了投影亮度,具体大眼橙C1D高亮版投影仪怎么样呢,下面就分享大眼橙C1D高亮版投影仪的详细参数配置,看看这款投影仪优缺点有哪些,是否可以符合家用需求,大眼橙C1D高亮版投影仪怎么样,1.光学参数在亮度方面,大眼橙C1D高亮版的实际亮度达...。

寸头种类主要有三种,寸头是一种很常见的发型,指的是头发的长度剪得很短,基本上接近头皮,根据不同的剪发方式和风格,寸头主要分为以下三种类型,1.基础寸头,这是最经典的寸头样式,头发的两侧和后部被剪得非常短,几乎接近皮肤,头顶的头发稍微留长,可以稍微梳理一下,呈现出自然的线条,这种寸头适合各种场合和年龄段,给人一种干练、利落的感觉,2.渐...。

广州某名目售楼处受访者供图,长假第一天加第二天,贝壳在全广州卖了1000多套新房,我卖了2套,10月3日,贝壳广州区域中介陈敏,化名,通知,每日经济资讯,记者,片面敞开限购,叠加,止跌回稳,定和谐一系列组合拳,广州楼市的购置力被迅速激活,很多中介小哥又进入了,一天只吃一顿,的超长待机形态,家里人都不允许我干这行,我的肠胃也不好,但...。
