对话潞晨科技尤洋 只有开源才能走得更远丨AGI十人谈 AI大模型没有知识产权 (北京潞晨科技有限公司)

作者丨何思思
编辑丨林觉民
2021年北京中关村多了一家科技公司——潞晨科技。
作为一家创业公司,潞晨科技这个名字可能还不被大家所熟知,但是其创始人尤洋却凭借“ACM SIGHPC杰出博士论文奖、NUS校长青年教授、亚洲福布斯30岁以下精英榜”等多个头衔,被业界熟知。
谈到最近火出圈的大模型,其实尤洋早在2018年就参与了谷歌BERT的训练,并把训练时间从3天降到了76分钟。据尤洋介绍,至今仍有企业在使用当时训练BERT时设计的方法。
而潞晨科技的创立要从2020年说起,彼时的尤洋刚刚从美国加利福尼亚大学伯克利分校毕业并获得博士学位,这一年 OpenAI 发布了当时全球规模最大的预训练语言模型 GPT-3,正是在这时尤洋有了做大模型的想法。
尤洋告诉: GPT-3出来时并没有出圈,但当时我就预判到大模型一定是未来的一大发展趋势,因为疫情影响,所以一直在等一个机会。
直到2021年这个想法才真正落地了,同年7月尤洋只身一人创办了潞晨科技,同时这件事情也受到了资本的青睐,成立近一年半的时间潞晨科技已经完成了3轮融资。其中包括了创新工场、真格基金两家VC机构的超千万元投资。
值得注意的是,创立之初潞晨科技就选择了一条和其他厂商不同的路线,即不做通用大模型,围绕降本增效做文章,本质上是为了降低大模型的训练成本,提高大模型的训练速度。
缘何这么做?
尤洋曾公开表示过,过去六年大模型参数量每18个月增长了40倍,过去三年每18月增长了340倍,而硬件的增长速度大概每18个月增长1.7倍,完全跟不上节奏。训练成本高、周期长,是当前大模型企业最需要克服的难题。
同时,他还表示,我的本职专长是研究高性能计算,用很朴实的话说,就是想办法让大模型训练的越快,越省钱。
可以说,尤洋选择的路线是验证其研究成果最有效的途径。
了解到,目前潞晨科技的研发主要分为三部分:一是做大模型训练系统——Colossal-AI;二是训练100亿到200亿参数的行业模型;三是做PaaS(Platform as a Service)平台。其中Colossal-AI系统已经有世界500强,2000强的客户在使用。
“现阶段的重点是Colossal-AI系统的开发,未来不管是GPT、PaLM还是任何一家大模型都可以用Colossal-AI训练,因为我们的系统就是帮他们省钱省时间的”尤洋补充道。
谈到具体能降多少成本?尤洋这样说:“假如用最基本的方案训练GPT 大概要1000 万美金,假如用业界最好的方案,能把成本降到300万美金,我们的方案则可以降到140万美金,也就是在最便宜的方案上再降一半,当然这些是绝对优化,如果加上收敛性优化可能降的会更多,但也会影响模型。”
成本只是一方面,与其他厂商不同的是,潞晨更注重“开源”二字,因为在尤洋看来,AI发展到现在正是因为它足够开放,未来AI竞争的焦点是生态,即有多少人在用你的软件,有多少人在给你反馈,只有反馈多了你才能不断迭代优化,才能吸引更多用户。
“一个好的AI生态,应该有三四千个用户或者三四千家企业去使用去贡献,这样整个生态的力量势必会比大厂的实力要强。”
以下是和尤洋的对话:
大学教授创办AI公司,技术契合,想让企业低成本获得大模型
:作为一名大学老师,为什么想要创业?
尤洋: 主要是技术比较契合,GPT是2020年出来的,当时GPT1、2的影响力还不是很大,后来GPT3也没有出圈。但GPT3出来的时候我已经在思考这件事情了,当时我就有一种预判,大模型肯定是未来的一大趋势,但大模型在各行业落地的难点就是计算成本。
我本职的技术专长是研究高性能计算,用很朴实的话说,就是想办法让大模型训练的越快,越省钱。比如之前我们和谷歌合作,训练出了当时最好的模型BERT,训练时间从3天降到了76分钟,也产生了一些价值,现在也有很多人在用我们当时设计的方法。
其实2020年刚毕业时就在思考这件事,2021年年初我就觉得需要创业了,但赶上了疫情,其实一直在找机会。
:最初受谁影响做这件事的?
尤洋: 2021年之前就有一些VC找过我,像李开复老师2021年四五月份就联系到了我,7月份我来北京和他们见了一面,过了不到一周他们就给我发了投资意向书。
:所以是李开复让你下定决心做这件事的?
尤洋: 我觉得让我下定决心的是我们对技术的判断,其实在李开复老师之前,一些个人天使也有投资意向。
:18个月完成三轮融资,是谁先投的?
尤洋: 创新工场最先给的投资意向书,真格基金知道创新工场给了,也迅速跟进了,所以我们2021年8月份就完成了融资,对外PR后蓝驰联系到了我们,9月份和他们老板见了一面,十一之前就给我发了投资意向书。只不过十一假期之后到元旦前我们一直在做公司的VIE结构,浪费了很多时间。
:资金有了具体怎么搭建团队的?2020年就开始了?
尤洋: 对,其实我们公司成立时只有我自己一个人,正好当时新加坡国立大学的一批学生毕业了,就把他们邀请过来了,然后又从社会上招募了几个人。
:潞晨的融资一直很顺利,您认为资方看中的是什么?
尤洋: 和我之前训练BERT的经历有关,我的那项技术创新工场内部的AI 工程院现在也在用,我觉得这是投我的一个原因,再加上我是美国博士,其实在业界还是有一定知名度的。
创新工场投我们的时候,我们什么也没有,他们看的就是我个人的一些积累和之前做过的一些有用的东西,蓝驰投我们的时候,我们刚想好要做开源社区,他们可能对开源社区也比较看好,最近一轮红杉资本投我们是已经初见一些效果了,并且他们也比较相信开源。
三条线齐头并进,被动获客高于主动获客
:潞晨给自己设定的大模型路线是什么样的?
尤洋: 主要分为三部分:一是做训练大模型的系统—Colossal-AI;理论上不管GPT、LLaMA还是其他大模型都可以用Colossal-AI训练,因为我们的系统就是帮他们省钱省时间的;二是训练大模型,做100亿到200亿参数的面向行业的垂直模型;三是做PaaS平台,把需要训练大模型的人集成到我们的平台上去,这样三个飞轮就能形成一个正向的循环。
:现在做到哪一步了?
尤洋: 三个团队在同时做,主要精力还在Colossal-AI上面,当然第二部分也在做,主要帮助企业做大模型的私有化部署,第三部分未来的商业化可能会多一些。
:具体怎么给客户提供服务?
尤洋: 要么买我们的企业版软件,要么用Colossal-AI训练自己的大模型,然后我们给他的机器做优化。
:Colossal-AI的效果如何了?
尤洋: 其实我们自己测试了,肯定是能降低成本的,并且现在已经有很多人在用了。
:所以说现在Colossal-AI已经做得很成熟了?
尤洋: 没有绝对好的事情,我们的产品3到6个月会升级一次,要想变得更稳定的话,还是需要一定时间去迭代的。
:具体点比如王小川或者其他家用Colossal-AI训练的话,成本大概能降低到多少?
尤洋: 我们做过计算,假如用最基本的方案,比如Python、DDP等没有经过优化方法训练GPT 大概要1000 万美金。比如用业界最好的方案,能降到300万美金,效果也不会打折扣,因为是矩阵张量优化,不是收敛性优化,收敛性优化会影响模型精度。那我们的方案可以降到140万美金,就是在最便宜的方案上再降一半,当然这些都是绝对优化,如果加上收敛性优化可能降的会更多,但也会影响模型。
:效果已经这么好了,那岂不是其他企业想做都做不下去了?
尤洋: 我不这么认为,我觉得AI行业没有知识产权,也没有IP,包括GPT也是在谷歌Transformer的架构上做的,如果技术长期闭源的话,其实是不可持续的。
我坚信AI能发展到今天就是因为它的开放性,没有任何人能够认为自己的生成式AI就是独特的且有很高壁垒的,我觉得未来竞争的是生态,就是说有多少人在用你的软件,有多少人在给你反馈,因为只有给你提供的反馈多了,你才能不断迭代优化它,这样才能吸引更多用户。
我觉得一个好的AI生态,应该有三四千个用户或者三四千家企业去使用去贡献,这样整个生态的力量肯定比大厂的实力要强。
:目前商业化做得怎么样?
尤洋: 比较顺利,虽然PaaS还没有很成熟,但第一部分已经在挣钱了,现在我们已经有很多世界500强、2000强的客户了,包括国内这几家创业公司都是我们的潜在客户,像阿里通义千问、百度文心一言、MiniMax可能都用过Colossal-AI了。
:PaaS层产品什么时候能发布出来?
尤洋: 8月1号之前会发布出来。
:了解到潞晨现在的客户国外偏多国内偏少?
尤洋: 两方面原因:第一我们公司成立的时间比较短,成立的前一个月主要在搭建团队,需要一定的时间过渡,第二其实我们也有很多国内客户,比如某些AI企业已经成立专门的团队在研究Colossal-AI了,当然我们现在也有很多目标客户,像传统的车厂、药厂、石油公司、金融机构等。
:为什么把传统行业作为目标客户?
尤洋: 因为传统企业是有长期付费意愿的,普惠AI时代是传统行业内部的一次AI升级,最终AI有多普及还是要看传统行业,现在有好几家汽车企业在自己训练,因为他们觉得这是一项核心技术,也没有绝对壁垒。包括一些头部证券公司对原创技术也是非常渴望的。
:未来重点放在国外还是国内?
尤洋: 其实无所谓,毕竟我们是一家小公司,没必要把自己限制的太死。再就是我们做的是开源社区,是一个被动获客的过程,不太需要主动BD,所以现在美国、中东、新加坡以及东南亚的客户都有。
:如果主动获客的话,会选择哪些区域?
尤洋: 主动获客的话,我觉得优先级:中国市场第一,东南亚市场第二,中东市场第三。被动获客的话肯定就没有任何限制了。
AI没有知识版权,只有开源才能走的更远
:为什么觉得开源生态很重要?
尤洋: 我觉得有两方面原因:一方面,把开源社区做好确实能创造更大的价值。我们做的是风险投资,但是当很多人都在用时,就能产生了一定的社会价值,我们的钱也算没打水漂。从投资人的角度来说,他们也能认可,因为投资人的钱也是从社会上募资而来的。
另一方面,毕竟创业做公司肯定想变现上市,我觉得本质上To B、AI最核心的竞争力是要和用户建立一个强的信任绑定关系,所以我觉得开源很重要。
:所以在创立潞晨前就想好要做开源了?
尤洋: 成立公司一个月内决定要做开源这件事儿。
:现在整个生态是什么样的状态?
尤洋: 这个生态中目前主要有三类企业:第一类是深度用户,他们可以贡献一些代码,帮我们去优化软件;第二类是用了我们的软件觉得很好的企业,在这个过程中会形成依赖关系;第三类是给我们反馈问题的企业。这三类企业中大小公司都有。
:有多少人专门负责开源生态的运营工作?
尤洋: 我们安排了两三个人在引导,其实做生态的意义就是让别人用,帮别人解决问题,然后别人发现问题了,我们再不断完善,当然我们自己也会设定一些重要的发展方向。
:所以做开源生态不需要铺太多的人?
尤洋: 对,我觉得人数应该不会超过20人,不管这个开源社区有2万人用还是100 人用。因为我觉得他需要一部分人去维护一个核心的内核,把内核维护好了,其他边边角角的,其实只要这个东西有很多人用,是有人会自发做贡献的。
:和英伟达的合作其实也是为了生态?
尤洋: 对,目前我们在英伟达的生态里,在他们的生态里其实我们有望拿到一些低价的算力,英伟达也给我们开源社区贡献了一些新功能,也都会优先适配Colossal-AI。
国内大模型都有机会,谁率先跑出来,需年底见分晓
:国内大模型会呈现怎样的发展局面?
尤洋: 主要分为两个方向。国外内市场最多有两三家能走出来,大概今年年底能看出来。
最终国内通用大模型市场最多能容下两三个,大厂肯定会占据一半,剩下的一个名额可能是创业公司。这就迫使其他创业公司必须转型做行业模型,行业模型其实没有通用大模型值钱,所以大部分创业公司的最终估值会下降很多。
:您看好哪家的大模型?
尤洋: 最领先的要么是大厂,要么是 MiniMax 和智谱。这几家肯定已经训练出了大模型,其他几家有的只是一个雏形,还在微调阶段甚至还没到训练阶段。其实到火山云上看一下卡的使用量也可以看出来,MiniMax 和智谱已经使用了 1000 张 gpu 卡了,其他几家都是 200 张。
平心而论,我觉得百度可能还真是最领先的。
:那创业公司呢?
尤洋: 我觉得是智谱。
有几个原因,第一,中国和美国的国情不一样,中国AI项目的论文一般都出自大学,而美国是Google、Facebook、OpenAI等,也就是说中国的技术源泉源自大学,最优秀的 AI人才也在大学;第二,我觉得大模型一旦做大,面临的是政治问题,美元基金最终会受限,所以像智谱这种纯人民币的反而有优势;第三,唐杰老师有丰富的学术、技术经验的积累,另外唐杰老师的清华背景对大模型的发展会有很大帮助。
:那您觉得国内大模型的决胜点是什么?
尤洋: 数据、算力、算法。算力和数据应该是最重要的,如何把算力合理地用起来,也非常重要。
原创文章,未经授权禁止转载。详情见 转载须知 。


4399闯关小游戏大全收录了国内外4399双人闯关小游戏,单人闯关小游戏,三人闯关小游戏,闯关类小游戏,双人闯关冒险小游戏,好玩就拉朋友们一起来玩吧!

饼干的做法_家常饼干的做法非常简单易学。豆果美食提供的图文饼干的家常做法大全和饼干的视频,用最短的时间让你学会饼干的做法

57G游戏网为大家提供最好玩的游戏下载,游戏攻略和最新的外服手游网游资讯。

广州彩熠灯光股份有限公司

扬中市正大机电设备制造有限公司「www.jsyzzd100.com」位于江苏镇江,深孔焊机,管板内孔焊机,管板全位置自动脉冲钨极氩弧焊机,管板自动焊机,全自动管板焊机生产厂家,钛管焊接,现场焊接与技术服务.

物通网是集物流查询、物流配货的专业一站式物流货运信息网,是货运物流公司、货车、快递公司、搬家公司、海运公司、空运公司、发货商的汇聚地,是物流货运信息非常全面、社会需求面极广、实用性极强的物流行业网站!

赣州大兄弟刀具有限公司(www.dxdtool.net)主要制造折弯成形刀,背封机刀,枕式机刀等器具,公司团队有15年从业经验,亦精于研究生产替代进口的异形非标刀具模具,以经济、实用、快捷的供货方式取代昂贵、急需的进口零部件!

慧域名网(huiyuming.com)是国内互联网域名综合服务平台,服务范围涵盖了域名注册查询、到期域名抢注、域名买卖交易、域名续费管理等多项业务,玩域名,认准慧域名网。

猫谁宠物网是一个专注于宠物知识分享的平台,为您提供全方位的猫宠物相关信息,包括饲养指南、健康护理、训练技巧等,让您成为合格的宠物主人。

安徽世纪畅享停车产业化服务有限公司

175手游网(175syg.com),为广大手机游戏玩家提供全方位的安卓手游开服表、ios手游大全,是手游玩家下载手机游戏首选的最佳服务平台。

金山打字通在线练习版集在线打字练习、在线打字测试、英文打字测试、中英文打字练习、五笔打字练习以及键盘练习于一体的在线金山打字练习软件,边打字边测速非常容易提高打字速度!


每一个人都有属于自己的家乡梦,现在网上有很多模拟城市小镇类型的游戏,那么2023我的城市小镇游戏大全有哪些,在游戏中玩家可以打造自己梦想中的生活,还可以远离繁琐的都市生活,下面就是小编分享给大家的关于城市小镇的游戏推荐,1、,梦想城镇,在这里玩家可以享受轻松和愉悦的生活,作为一个农场主可以根据的自己的规划,打造未来的城镇发展,可以雇佣...。

今天为大家带来有一个老奶奶的游戏叫什么2022,老奶奶系列的特别游戏,这些游戏里面,老奶奶成为了最特别的存在,玩家可以在游戏里扮演老奶奶,也可以在游戏里帮助需要帮助的老奶奶,现在就让我们一起来看看有哪些游戏吧,1、,宫爆,老奶奶家族篇,这款游戏是一款关于老奶奶的游戏,游戏里有唯美的场景和华丽的音乐,还有超嗨的连招系统,玩家可以操控人物...。

为解决有线、无线、直播卫星、IPTV和互联网电视等广播电视和网络视听领域应用生态自成体系、相互隔离的,老大难,问题,由国家广播电视总局广播电视科学研究院牵头研发的智能电视操作系统,TVOS4.0,日前在北京正式发布,当前,超高清、智能化、万物互联、绿色节能是视听领域的发展大势,顺应这一趋势,TVOS协同了半导体、媒体、安全、连接、智能...。

小时候贪玩,每次放学回到家书包一扔,约上三五好友就溜了,那时候贼爱打篮球,饭不吃行,不让打篮球不行,回到家就是一顿臭骂,妈妈们常说的一句话,你看看别人家的孩子怎么样怎么样,,这也是我们最不爱听的话,那时候孩子都是别人家的听话,别人家的好……长大了以为自由了,没人念叨了,我发现我又错了,我们口中的,自由职业者,就是别人眼中的无业游民,...。

广袤农村,空气清新,资源丰足,人口集聚,由于的重视,近年来的发展可圈可点,不管是智慧之选、创业,还是安家、定居,较之城市都有着明显的优势,由此,越来越多的人选择扎根农村,开疆辟土,那么,农村做什么生意好呢,下面,小编特别整理了时下具有潜力和价值的几个项目,以飨众位,农村做什么生意好——儿童托管报纸、电视、视频等报道,我们知道,由于年轻...。

随AI技术的不断深入发展,医学人工智能应用如雨后春笋般迅速涌现,在医疗领域遍地开花,尤其是自2020年初新冠疫情爆发之后,AI更是在战疫一线被广泛应用,AI凭借其智能化、自动化的特点,通过强大算力解锁复杂数据、处理海量数据,不仅能够帮助医生减轻工作负担、提高诊疗效率、精准节约医疗成本,帮助提高病人舒适度、做好风险预测,AI在多个医疗场...。

消费者在购买投影幕布时,会发现几乎所有的品牌都会给出两个基本的光学参数,增益和可视角度,这两个参数会直接影响投影图像的成像质量,这是两个重要的关键因素,下面由冠叶小编将这两个关键性因素展开话题,帮助大家深入了解投影幕布最基本的性能指标,2018.7.27,15.28.34,2881.jpg增益是用于衡量幕布反射投影光线效率的物理量,它...。

全球时报综合报道,澳大利亚,悉尼先驱晨报,2日报道称,知情人士泄漏,澳大利亚总理阿尔巴尼斯选择不参与行将在华盛顿举办的北约峰会,而是派出由澳大利亚副总理兼国防部长马尔斯率领的代表团参会,悉尼先驱晨报,报道称,阿尔巴尼斯原本估量与日本、韩国和新西兰等所谓,印太四国,成员独特参与9日开局的北约成立75周年纪念峰会,报道称,在未能确认峰...。

汽车置换就是用旧车换新车,1.车辆置换是客户以二手车的评价价值加上额外的付款从产品经销商处购置新车的业务;2.假设你改换了你以前的二手车,你将以现金方式补救改换的车主,选用置换车相对划算,相关于二手车市场的参差不齐,很难解决,尤其是,业主谁不不太懂车的都是最容易拿到套路的,给的多少钱也相差很大,因此,假设你不不了解二手车市场的买卖流程...。

运动混搭风正流行,整个秋天都想这么穿!,正装,秋天,运动风,休闲风,运动装,优雅风,阔腿裤,混搭风,身材比例

外媒:2架乌克兰直升机在顿涅茨克坠毁,6名乌军人员丧生,顿涅茨克,乌克兰,直升机,米-8,乌军,坠毁

Spline(3D图形设计工具)是一款简易实用,功能全面的3D图形设计软件,因此设计师们只要利用该软件,就可以帮助自己快速完成3D图形的设计,因为该软件可以支持以2D的方式进行3D设计,无需3D设计基

疫情期间,美团启动了,春归计划,,计划招聘超过1000名毕业生,提供超过3000个社招职位,不仅如此,美团还表示,从2020年1月20日到3月18日,美团已经累计招聘了33.6万名骑手,由此可以看出,在这次疫情下美团并没有任何放缓脚步的迹象,2020年,是美团过去十年的终点,但同时也是下一个十年的起点,01团购业务,从死人堆里爬出来风...。

大家好,我是阿阳,上一篇文章讲了如何去注册账号,这篇文章来说说怎么来选品,要知道在CSGO这个游戏里,每一件装备的价格是随市场有波动的,和股市的K线图一样,而我们所谓的选品呢,就是在饰品市场里去找到能给我们带来利润的装备,选品我们要到网易buff的饰品市场当中去选装备,这里我们需要提前注册一个网易buff账号,后面我们卖装备、提现都要...。
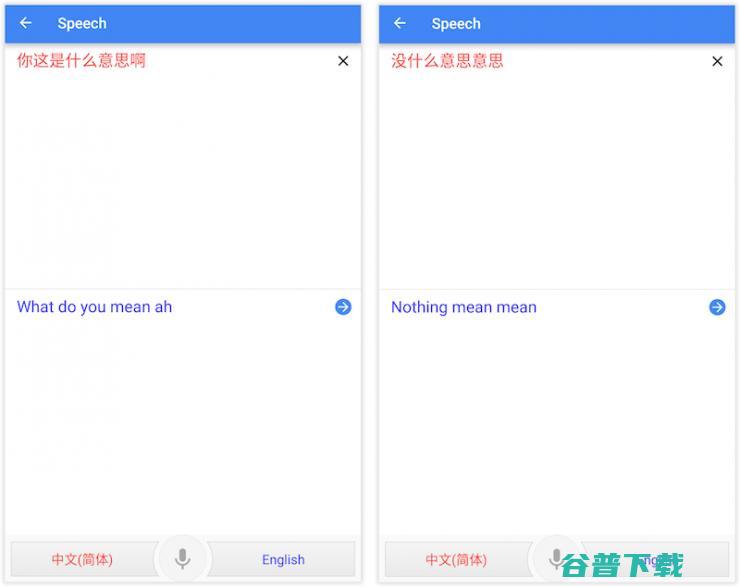
一名新入职场的翻译员,担心越来越厉害的机器翻译抢了自己饭碗,于是在知乎上发问,,这个行业还有没有前途,老司机们纷纷上前安慰,其中一位说,年轻人你兔样兔森破,让机器翻译一下上面这个对话,看能不能搞定,再来担心吧,不知道,年轻人,有没有去试,雷锋网去试了试,发现行业公认最厉害的Google翻译和微软翻译,MicrosoftTransla...。

抖音怎样加入吃喝玩乐榜,抖音软件里有超多同城的圈子,小伙伴们可以加入圈子里就可以感受更多的榜单,还有各种吃喝玩乐的美食,非常的方便,那么怎么加入呢,还不清楚的用户就一起来看看吧!...。

发表在奥图码投影机2021,3,1513,53奥图码cinemapro4k投影机是奥图码uhd566的升级版,那么这款奥图码cinemapro4k投影机怎么样呢,相比uhd566又有哪些升级,下面我们从它的参数配置分析一下,一、奥图码cinemapro4k光学参数奥图码cinemapro4k采用传统灯泡光源,亮度为3000流明,内置0...。
