多模态技术在产业界的应用与未来展望 快手科技李岩 (多模态技术在医疗中的应用)
 快手
AI影响因子
活动快手主题演讲
快手
AI影响因子
活动快手主题演讲
在 CNCC2018「高通量媒体内容理解论坛」上,快手科技多媒体内容理解部负责人李岩发表了题为「多模态内容生产与理解」的演讲,讲述了带领多媒体内容理解部在多模态研究上取得的一些进展。
李岩在演讲中表示,多模态技术有两大应用方向,一是会改变人机交互的方式,二是将使信息分发更加高效;视频本身就是一个多模态的问题,而快手则拥有海量的多模态数据,多模态的研究对于快手来说是非常重要的课题;目前快手已经在语音识别与合成、智能视频配乐、通过 2D 图像驱动 3D 建模特效、视频精准理解等领域对多模态技术进行研发应用。
以下为演讲的主要内容:

大家好,首先我来简单介绍一下快手,在这个平台,用户能够被广阔的世界看到,也能够看到广阔的世界,我们可以看一下快手的数据: 70 亿条视频总量、1500 万日新增视频,日均的使用时长超过 60 分钟等,所以快手平台上有非常多的多媒体数据,同时也有非常多的用户交互数据,比如我们每天有 1.3 亿用户观看超过 150 亿次视频的播放数据。
我们知道视频是视觉、听觉、文本多种模态综合的信息形式,而用户的行为也是另外一种模态的数据,所以视频本身就是一个多模态的问题,再加上用户行为就更是一种更加复杂的多模态问题。所以多模态的研究对于快手来说,是非常重要的课题。
多模态技术两大应用方向:人机交互与信息分发
我认为多模态技术会有两大主要的应用。
第一,多模态技术会改变人机交互的方式,我们与机器交互的方式将会越来越贴近于更令人舒适、更自然的方式。
第二,多模态技术会使得信息的分发更加高效。

多模态技术研究的三个难点:语义鸿沟、异构鸿沟、数据缺失
其实在目前来看,多模态研究难度还是非常高的。
其中大家谈得比较多的是语义鸿沟,虽然近十年来深度学习和大算力、大数据快速发展,计算机视觉包括语音识别等技术都取得了非常大的进展,但是截至现在,很多问题还没有得到特别好的解决,所以单模态的语义鸿沟仍然是存在的。
再者,由于引入了多种模态的信息,所以怎样对不同模态之间的数据进行综合建模,会是一个异构鸿沟的问题。
另外,做语音、做图像是有很多数据集的,大家可以利用这些数据集进行刷分、交流自己算法的研究成果。但是多模态的数据集是非常难以构建的,所以我们在做多模态研究时是存在数据缺失的问题的。
下面我会分享我们在多模态这个方面所做的事情,以及这些技术是怎么样帮助快手平台获得更好的用户体验和反馈的。
多模态技术如何实现更好的记录
首先,多模态技术将实现更好的记录。随着智能手机的出现,每个人都可以用手机上摄像头去记录周围的世界,用麦克风去存储周围的音频信息;而在以前,生成视频,尤其生成一些比较专业的视频,都是导演干的事情。但现在,我们通过手机就能够做到,这里面会有非常多的多模态技术研究来辅助人们更好地记录。
我们希望整个记录过程是更加便捷、个性化、有趣,同时也是普惠的,具体我将分别通过四个案例分享。
1、语音转文字打造便捷字幕生成体验
一个视频里,音频部分对于整个视频的信息传递是非常重要的。网上有很多带有大量字幕的、以讲述为主的视频,这样的视频制作其实是一件很麻烦的事情,因为一个一个去输入文字是很痛苦的,像过去在广电系统专业工作室就需要很多用于字幕编辑的工具软件。而如果我们通过语音识别技术,把语音直接转成文字,就可以很轻松地通过手机编辑生成一个带字幕视频。
2、语音合成实现个性化配音
另外一个技术叫做个性化配音,假如在一个视频中,你不喜欢听男性配音,而希望听到由一位女士配音,我们就可以通过语音合成技术满足个性化的诉求。
语音识别及合成技术都会使我们记录的过程变得更加便捷、有趣,但这两个技术在做视觉或者多媒体的圈子里面关注度不是特别高,只是偶尔会在做语音的圈子里去聊这些问题。包括在语音圈子里面,语音识别和合成现在往往是两波人在做。

随着深度学习技术的出现,语音识别和合成这两个问题其实在某种程度上是非常对称的,因为语音识别是从语音到文字,语音合成是从文字到语音。语音识别的时候,我们提取一些声学的特征,经过编码器或者 Attention 的机制,实现从语音到文字的转化;语音合成的技术和算法,其实也涉及编码器或者 Attention 的机制,二者形成了比较对称的网络。所以我们把语音识别和合成看成是一个模态转换的特例,从神经网络建模角度来看,是一个比较一致、容易解决的问题。

具体神经网络在设计的时候,虽然二者内容机制其实还是有一些不同,但更大的趋势是这里面将来会有更多的趋同,因为我们知道随着相关算法的发展,计算一定是朝着一个更加简化,更加统一的方向发展。就像深度学习的出现,其实就是通过计算的方式取代了手工来获取有效的特征。多模态的转换领域里面也出现了这样的特点,这是一件非常有意思的事情。
3、根据视频内容自动生成音乐
音乐也是短视频非常重要的一部分,有录视频经验的同学可以感受到,为一个场景配合适的音乐是一个很难的事情。过去,有不少用户为了与音乐节拍一致,努力配合音乐节奏拍摄,极大限制了拍摄的自由度。我们希望用户可以随意按照自己想要的节奏录制,所以让机器通过用户拍摄的视频内容,自动生成符合视频节奏的音乐,这样视频画面与音乐节奏就会更匹配、更一致。
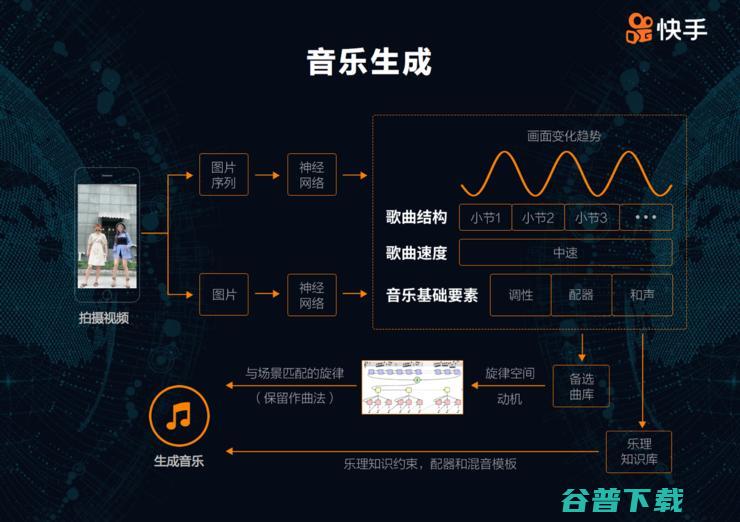
音乐生成涉及很多具体的技术,我们也做了非常多的研究,其中一个问题是懂音乐的不懂计算机科学,懂计算机科学的人不懂音乐。想要把短视频配乐这个问题研究好,需要要有做音乐和做 AI 的人一起集成创新,这方面我们也做了非常多的工作。
4、2D 图像驱动 3D 建模实现 Animoji 效果
通过苹果的发布会,大家应该都了解 Animoji 这项技术,iphoneX 有一个标志性的功能,就是通过结构光摄像头实现 Animoji,现在国内手机厂商也越来越多地采用结构光的方式去实现 Animoj。而快手是国内较早实现不使用结构光,只用 RGB 图像信息就实现 Animoji 效果的企业。

用户不必去花上万元去买 iphoneX,只要用一个千元的安卓手机,就可在快手的产品上体验 Animoji 的特效,从而能够在不暴露脸部信息的同时展现细微的表情变化,例如微笑、单只眼睛睁单只眼睛闭等,让原来一些羞于表演自己才艺的人,也可以非常自如地表达。我们觉得做技术有一个非常快乐的事情,就是让原来少数人才能用的技术,变得更普惠。

其实解决这样一个问题是非常难的,因为即使是像苹果这样的公司,也是采用了结构光这样配置额外硬件的方式来解决。想让每一个用户都能享受到最尖端的技术,快手面临着硬件的约束,只能通过 2D 的 RGB 视觉信息对问题进行建模、求解,这里面包括了像 Landmark 人脸关键点检测、实时重建人脸三维模型等技术,把 2D 和 3D 两种不同模态的信息做建模、做对齐。
我们也能看到现在市场上可能有一些小型的 APP 在做类似的事情,但体验很差,而我们的整体体验还是非常好非常流畅的,这也需要归功于深度神经网络模型的量化,通过压缩和加速解决手机性能问题,可适配任意机型。
多模态技术如何实现精准理解视频内容
刚才我讲的是我们多模态技术怎样去帮助用户更好地记录,我们同时也希望通过一个更好的分享机制,让用户发布的视频能够被更多感兴趣的人看到。这也涉及视频推荐里面多模态的一些问题。

对视频内容的理解其实是非常难的,这个里面我做了两个比较有意思的事情。
第一,我们强调音频和视觉的多模态综合的建模,而不是仅仅是单独的视觉或者音频,视觉和听觉两种媒体的融合,会是未来一个非常重要的事情。
第二,在工业界做的事情和在学术界做的事情有很大不同,我们有非常多的用户数据,这些用户数据是不在传统多媒体内容研究范畴里面的,但是工业界可以很好地利用这些数据,更好地做内容理解。


给大家举个例子,一个男子表演口技的视频中,如果关闭声音,仅凭画面信息,我们并不知道他是在做什么,可能会觉得是在唱歌或唱戏。这说明如果仅仅是通过视觉的话,你可能无法获得真实的信息。我们对世界的理解一定是多模态的理解,而不仅仅是视觉的理解。
像这样的视频在快手数据库中有 70 亿,想要理解这么多的视频内容,必须借助多模态技术。所以我们在这方面也做了非常多的工作,从文本、视觉、听觉角度去做了很多单模态的建模,包括多模态的综合建模、有序与无序,以及多模态特征之间怎样进行异构的建联,在很多任务内部的分类上也做了改进。
第二点需要强调的是,像 ImageNET 等很多的学术界研究内容理解的任务有非常好的标注数据集,但是这个数据集对于工业界来说还是太小,且多样性不够。我们平台每天有 1.3 亿多用户以及超过 150 亿次的视频播放,这个数据是非常大的。如果有 150 亿的标注数据,做算法就会有很大的帮助,但是现实上是不具备的。


那怎样将研究分析技术与海量数据更好地做到两者的融合呢?我们通过融合行为数据和内容数据,进行综合建模,同样大小的人工标注量,利用海量的用户行为数据,能够获得比纯内容模型更好的性能,对视频有了一个更好的理解,进而在多媒体内容的理解和分析方面的算法研究有了非常大的进展,这就使我们在工业界和传统学术界做这个事情时会更有优势。
未来多模态研究的热点:特征表达与特征对齐
总结一下,多模态内容解决的问题里面涉及一些模态的转化,比如怎样通过 2D 图像驱动 3D,怎样通过语音生成文本或者通过文本生成语音,怎样通过视觉驱动音乐。另外一个应用是我们怎样通过融合更多信息来驱动内容的理解,其实都是一个多模态的问题。在学术界有很多研究还是停留在单模态,但我个人认为未来多模态会成为更有价值的研究方向。
多模态研究会有两个难点或者说热点:
第一是多模态的特征表达,也就是在多模态研究框架下怎样设计单模态的特征,这是一个非常重要的问题。
第二是多模态特征之间如何对齐,也就是有没有更好的算法对视觉、听觉和行为的部分进行统一的建模,这是未来的一个热点。

第一,多模态未来会持续带来更新的人机交互方式,比如我们刚才讲的 Animoji 技术,其实它带来的是一种可以通过人脸控制手机自动生成 Avatar(虚拟动画)的体验。原来实现这些效果,需要在好莱坞专门设一个特效室来实现这一点,而现在普通用户都能享受这样的技术,所以人机交互会由原来重的、贵的、笨的方式转变为便宜的、每个人都能参与的而且便捷的方式。
第二,我认为多模态技术会带来新的内容形态,原来接入信息更多是从文本、页面中获得,现在有视频,未来可能还会有 AR 或者其它的形式。我觉得多模态 AR 很重要的一点就是强调沉浸感,这种沉浸感其实是通过听觉和视觉综合作用才能产生的。
第三,我认为多模态亟需新的算法和大型的数据,因为这两者可能会是一个某种意义上可以相互折算的问题。以目前的机器学习算法来讲,需要海量的数据才能解决好这个问题,因为现在深度学习、内容理解的成果,某种意义上是监督学习的成果,有足够的样本、算力,所以现在的算法能力基本上还停留在对算力和数据有着非常大要求的阶段。而多模态的大型数据是非常难建的,而且多模态解的空间是更大的。因为一个模态解的空间是 n,另外一个是 m,它最后是一个乘积、一个指数级的变化,所以数据集要多大才足够是一个很难的这个问题,可能需要新的算法来对这个问题进行建模。
原创文章,未经授权禁止转载。详情见 转载须知 。



深圳注册公司为创业者提供注册深圳公司、代理记账报税、工商注册变更、深圳商标注册等企业服务!-财税1688

八通网(www.bato.cn)是北京最大的生活社区网站,北京通州门户,北京城市副中心,是百万居民生活交流平台。

好房尽在搜狐焦点网

牛肉面品牌一挑香牛肉面是哈尔滨面馆加盟,黑龙江牛肉面加盟,哈尔滨牛肉面加盟的好品牌,一挑香牛肉面属于哈尔滨一挑香餐饮有限公司,是一家集店面策划、店铺经营、招商加盟、运营指导为一体的专业快餐经营机构。

山东宇捷空调设备有限公司常年从事高大空间空调机组,高大空间冷暖机组,高大空间冷热机组,高大空间射流机组,高大空间专用吊顶空调,高大空间专用吊装空调等空调末端产品的生产销售,欢迎新老客户前来咨询。

广东固盾不锈钢防火玻璃门厂家销售电话:18075925566为您设计不锈钢防火玻璃门图纸及技术解答,广东固盾厂有十余年不锈钢防火玻璃门制作经验,具有不锈钢甲级,不锈钢乙级防火玻璃门资质,不锈钢防火玻璃门通过消防产品认证,为您提供不锈钢门安装、生产、制作技术指导。在湖南,广东,湖北,江西,贵州,广西,海南及其他销售不锈钢防火门及不锈钢防火玻璃门,诚招不锈钢门代理商!

成都文峰生物科技、酵母浸粉、蛋白胨

思尔德苏州实验室装修公司[热线:13004597457],面向(苏州、昆山、常熟、吴江、吴中、新区、相城、园区等附近地区)提供实验室装修设计,无尘车间装修设计、净化厂房车间装修规划设计,食品厂房装修改造及实验室设备,钢木/全钢实验台,抽风柜药品柜等批发

这里有多种特殊功能性进口品牌液体硅胶,有机硅密封胶,固态硅橡胶,耐高温硅胶销售,同时普及硅胶(硅橡胶)相关百科知识。销售的硅胶有瓦克,迈图陶熙,信越,耐高温硅胶,防静电硅胶,自粘型硅胶...

南京今科货架工厂是一家专业从事工业货架及仓储设备研发,生产,销售,安装于一体的大型货架制造企业.货架工厂产品涵盖:工厂货架,库房货架,仓储货架,仓库货架,重型货架,轻型货架,冷库货架,钢制托盘料箱,货架阁楼平台,钢平台.

温州市永星工程机械有限公司是一家专业从事吊车机械化和非机械化起重吊装作业的专业吊装公司.

趣中介是一家专注于知识产权交易的网站,为您提供专业的交易平台和独特创意的展示。我们致力于连接创意人才与商业机会,让您掌握知识产权的价值,实现商业增长。立即访问趣中介,发现潜在合作伙伴,开启创新之旅。


除了有很多年龄小的孩子比较喜欢看动漫这种类型的影视作品,其实还有很多的人是从小看动漫长大的,所以随着年龄的增长,依旧很喜欢看,那么看动漫哪个app全部免费呢,今天小编就给大家详细的介绍几款,既可以让用户了解有哪些精彩的动漫内容,还没有任何的收费问题,一起来了解一下,喜欢看动漫的人可下载这款软件,里边汇集了精彩的动漫内容,也会对动漫迷们...。
刚刚,Neuralink分享了脑机接口研究的最新进展,第二位参与者成功植入Neuralink,接入五分钟就能用意念控制光标,还能使用CAD软件,玩,反恐精英,,Soeasy!马斯克在推特上转发了这一消息,截止中午12点,目前已有近6千名读者在马斯克的推文下留言互动,有读者开玩笑表示,他不是这次实验参与者,但希望自己是下一个,杨立昆也跟...。

身处机器学习时代的我们通常头脑被目标函数和优化算法所充斥,这可能会将我们禁锢到认知的角落中无法脱身,当我们跳出这个怪圈儿,将一直所追求的,优化目标,变成,泛化能力,时,说不定能够事半功倍,得到意想不到的好处,比如,我们甚至可以去要求那种高深莫测的,直觉,在这篇文章中,谷歌机器人方向研究科学家EricJang将介绍一个深度学习构建工程...。

小鹏汽车今年又一爆款诞生,C级车,全系标配高阶智驾,800V,续航602km,710km,超大空间,入门版只要18.68万元,超长续航版只要19.88万元,对于此次的小鹏P7,,小鹏汽车已经按照小鹏MONAM03上市5倍流量对服务器进行了扩容,但服务器依然崩溃,据悉小鹏官网的流量是MONAM03上市时的20倍,今年以来,小鹏汽车从低谷...。

她在学校被老师,认为是偷手机,一直纠缠着,她又和被偷手机的同学被传有恋爱关系,经受不住压力,回家要被妈妈骂了几句,所以跳楼陕西一高三女生坠楼身亡父亲称后悔在女儿说被欺负时劝她要想开点,问题就出在我们只看到了父母,应该教育,的角度,却没有从孩子的角度去思考问题,孩子想要的是,父母和他们分享故事,父母看到他们渴望亲昵的期待,如果父母看不到...。

发表在专业问答2022,11,1814,08展示机型信息,品牌型号,索尼X80J系统版本,当贝OS定制版电视机亮度很暗很暗可能是电视机内部的显像管老化或者损坏导致,可以更换元器件解决;可能是电视的亮度调到了最低,可以调高亮度解决;可能是当前电压不稳导致,可以使用稳压器来稳定电压解决,电视机亮度很暗很暗哪里坏了电视机亮度很暗很暗可能会是...。

汽车是当下人们出行的必备工具,而且现在家家户户都有汽车,所以汽车相关的行业得到快速的发展,想要清楚出行更加的安全,就要定期进行对车辆进行保养和维修,并且也哟啊定期清理,这样才能保持汽车状态很好,因此人们对洗车店有较大的需求量,随着汽车保有量不断地增加,创业者看到洗车店项目的商机,想要加盟,但不知道,浙江洗车店加盟什么品牌好,每个洗车品...。

据泰国媒体报道,7月13日,泰国警方发现一具遗体,疑心为此前失踪的中国女性YanRuimin,兖女士,,警方正在启动DNA关系检测,▲泰国警方在农村地域发现疑似受益人遗体泰国警方称,嫌疑人为MaQingyan,6月30日曾在曼谷租车,7月1日,兖女士乘坐这辆车,今日晚些时刻,监控摄像头曾拍下嫌疑人与兖女士独特乘坐此车的画面,起初,嫌疑...。

亲,依据传统文明,中年女人被蛇咬是一种不祥的预兆,意味着将会有可怜的事件出现,传说中,被蛇咬会带来灾祸,比如家庭分裂,孩子失踪,病痛等等,另外,被蛇咬也或许意味着家庭成员的死亡,或许是好友的变故,此外,被蛇咬也或许预示着财富的散失,比如财富损失,财务艰巨等,此外,被蛇咬还或许预示着职业开展的艰巨,比如失业,被解雇,升职碰壁等,总之,被...。

鼓浪屿作为国度5A级游览景区、环球文明遗产地,是许多游客到厦门必打卡的抢手景区,但是近期一段期间,不时有外地游客反映,到这里游览套路多、破费高、体验差,这终究是怎样回事,总台记者到来登船码头和景点,以游客身份启动暗访考查,出租车司机诱导游客前往游览社购置低价套票记者看到厦门轮渡码头的路边,停着很长一排出租车,一旦有外地游客发生,司机们...。

[全球网报道记者李梓瑜],今天俄罗斯,RT,、,以色列时报,7月2日征引美国,纽约时报,信息称,数十名以色列初级将领示意,他们宿愿以总理内塔尼亚胡与巴勒斯坦伊斯兰抵制静止,哈马斯,达成开战协定,以便为或者与黎巴嫩真主党迸发抗争做好预备,对此,内塔尼亚胡回应称,这不会出现,,将继续成功,覆灭哈马斯,抗争指标,RT称,新一轮巴以抵触将进...。

英菲克PW1H鼠标驱动是专为英国菲克PW1H鼠标设计的专用驱动。主要用于鼠标与电脑的连接,可以轻松解决各种连接异常问题。

他们不是演员,却渴望拥有属于自己的舞台,当2017年最后一个晚上,数以万计观众都在观看各大卫视的跨年晚会时,有那么一群人却在镜头前开着他们的跨年,轰趴,,那就是网络直播,直播已然成为这个时代特有的展现方式,平均每天会有超过2亿人辗转在各个直播平台上,不过,近两年网络直播爆火让很多人看到了新世界,一夜成名似乎变得很简单,其中不乏一些无所...。

左图SatyaNadella,微软,,右图SundarPichai,谷歌,据外媒Re,code的报道,冤家仇敌关系的谷歌和微软近日达成一项协议,双方将撤销在全球各地对对方发起的监管投诉,此外,这项协议还提到,未来双方将会努力通过协商来解决问题,而不轻易投诉到监管层或者利用法律武器,对此,谷歌发言人表示,我们两家公司的竞争激烈,但我们...。

发表在专业问答2021,1,2215,44展示机型信息,品牌型号,坚果U2Pro、iPhone12、华为p40系统版本,JMGO4.0、iOS14.3、EMUI10.2.0软件版本,坚果投屏1.1.50将坚果激光电视和手机连接到同一wifi网络中;打开坚果激光电视上的坚果投屏,并记录设备名称;打开手机端的屏幕镜像或多屏互动,搜索相应设...。

发表在极米投影仪2022,7,2117,51据消息称,极米将在国内上新一款吸顶灯,极米吸顶灯投影L1,这款极米神灯之前在海外日本发布过,国内暂时对于吸顶灯投影仪产品少之又少,相信发布后会带来一片惊叹,对于这款极米吸顶灯投影L1虽然是灯,但本质还是一个投影仪,其内部又拥有怎么样的配置呢,极米吸顶灯投影L1参数又如何,我们往下看,极米吸顶...。

代码说明,本页面的认证代码为站长联盟,zzadx,专用评测代码,站长需懂简单html知识,直接复制代码粘贴到联盟网站相应页面即可使用,本代码不适用于其他广告联盟网站请勿获取!文字认证,文字链接代码认证适用所有类型的广告联盟,复制代码后放在站长联盟,zzadx,网站首页底部或友情链接位置处,普通认证,普通联盟认证标志适用所有类型的广告联...。
