快试试这个Kaggle大数据集高效访问教程 数据太多而无法使用 (快试试这个家常烧饼做法)
译者:AI研习社( 季一帆 )
双语原文链接: Tutorial on reading large>大规模数据集

我敢肯定,你在解决某些问题时,一定报怨过没有足够的数据,但偶尔也会抱怨数据量太多难以处理。本文探讨的问题就是对超大规模数据集的处理。
在数据过多的情况下,最常见的解决方案是根据RAM采样适量数据,但这却浪费了未使用的数据,甚至可能导致信息缺失问题。针对这些问题,研究人员提出多种不同的非子采样方法。需要注意的时,某一方法是无法解决所有问题的,因此在不同情况下要根据具体需求选择恰当的解决方案。
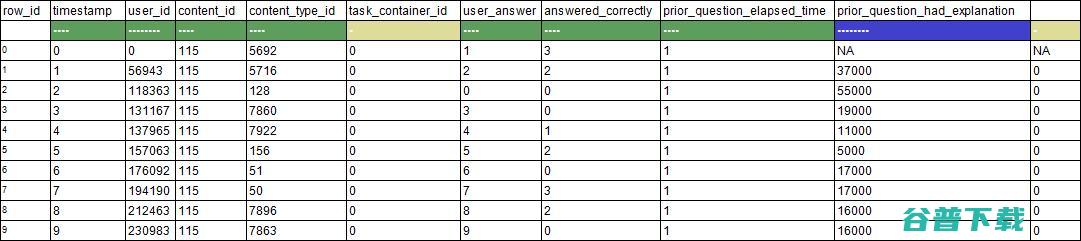
本文将对一些相关技术进行描述和总结。由于 Riiid! Answer Correctness Prediction 数据集由10列,超1亿行的数据组成,在Kaggle Notebook中使用pd.read_csv方法读取会导致内存不足,因此本文将该数据集做为典型示例。
不同安装包读取数据的方式有所不同,Notebook中可用方法包括(默认为Pandas,按字母表排序):
除了从csv文件读取数据外,还可以将数据集转换为占有更少磁盘空间、更少内存、读取速度快的其他格式。Notebook可处理的文件类型包括(默认csv,按字母表排序):
请注意,在实际操作中不单单是读取数据这么简单,还要同时考虑数据的下游任务和应用流程,综合衡量以确定读取方法。本文对此不做过多介绍,读者可自行查阅相关资料。
同时,你还会发现,对于不同数据集或不同环境,最有效的方法往往是不同的,也就是所,没有哪一种方法就是万能的。
后续会陆续添加新的数据读取方法。
方法
我们首先使用Notebook默认的pandas方法,如前文所述,这样的读取因内存不足失败。
import pandas as pdimport dask.dataframe as dd# confirming the default pandas doesn't work (running thebelow code should result in a memory error)#>

是最常用的数据集读取方法,也是Kaggle的默认方法。Pandas功能丰富、使用灵活,可以很好的读取和处理数据。 使用pandas读取大型数据集的挑战之一是其保守性,同时推断数据集列的数据类型会导致pandas> 帮助文档:
Dask介绍
Dask提供并行处理框架对pandas工作流进行扩展,其与Spark具有诸多相似之处。 帮助文档:
Datatable介绍
受R语言data.table的启发,python中提出,该包可快速读取大型数据集,一般要比pandas快得多。值得注意的是,该包专门用于处理表格数据集,能够快速读取大规模的表格数据集。 帮助文档:
|











嘻鸥网——海量原创的科技投稿和生活杂谈等你来看。

手机新浪网新闻中心,新浪网新闻中心是新浪网最重要的频道之一,24小时滚动报道国内、国际及社会新闻。每日编发新闻数以万计。新浪新闻触屏版-news.sina.cn

福建省泉州市科霸卫浴有限公司

舜甫集团多年致力于食药领域EPC建厂服务,赋能用户高效生产,公司提供各类提取设备,浓缩设备以及植物提取生产线,骨素提取生产线,调味品生产线,中药提取生产线,蛋白肽生产线,酱料生产线,中试生产线.公司集科研开发、工艺设计服务、工程总包、设备制造、安装调试及培训为一体的综合性服务商.

中国高校知识产权运营平台

外籍模特公司:提供国内外模特,中老年模特、中老年演员、童模、女模特、男模特、礼仪小姐、时装模特、走秀模特、平面模特、广告模特、代言模特、T台模特、静展模特、接待礼仪、开业礼仪、会展模特、车模等;欢迎新老客户咨询:4008813618-易创外籍模特公司

上海雷韵试验仪器制造有限公司专业生产:公路仪器,混凝土仪器,电动击实仪,岩石点荷载仪,电动钢筋打点机,摆式摩擦系数测定仪,触探仪,混凝土冻融试验机,混凝土含气量测定仪,砂浆抗渗仪,混凝土切割机,混凝土快速养护箱,自控砖瓦泛霜箱等试验仪器设备,其型号齐全,价格实惠!

趣事网(www.qushiwang.com)搜集整理最新奇闻异事、灵异事件、未解之谜、猎奇八卦、趣闻趣事、历史趣事、趣闻轶事、世界趣闻、历史解密、科学探索、奇闻趣事、宇宙奥秘等内容、探索未知大千世界奇事奇物。


好排名主要针对百度、搜狗和360搜索引擎开发的关键词按天扣费系统,seo关键词排名系统,帮企业网站快速提升关键词在搜索引擎里的排名位置。

沧州鼎麒包装设备有限公司|KCC瓦楞纸板双色印刷开槽机|KCD系列双色印刷开槽机|kcs水性印刷开槽机|dw单面瓦楞纸板生产线

升达致力于一体化家居和智能化家居的打造,引领潮流家居的生活方式,为客户提供一体化家居解决方案,让家居生活更美丽。


一、达维多定律达维多认为,一个企业要想在市场上总是占据主导地位,那么就要做到第一个开发出新产品,又第一个淘汰自己的老产品,国内网站跟风太严重,比如前段时间的格子网,乞讨网,博客网,一个成功了,大家一拥而上,但实际效果是,第一个出名的往往最成功,所以在网站的定位上,要动自己的脑筋,不是去捡人家剩下的客户,同理,买人家出售的数据来建站效果...。

雷锋网按,今年年初,仅上线半年的我有外卖即获得近亿元的A轮融资,这是截止到目前为止,外卖O2O平台收到的最大一笔A轮融资,其中领投方便有小米科技,在即将过去的2014年,互联网诞生了诸多热门概念,在这其中,O2O概念几乎从年头热到年尾,本地生活服务类创业进入了白热化的阶段,仅仅是外卖这块,创业者和资本密集进入,BAT等巨头纷纷布局,腾...。
雷锋网AI金融评论报道,作为全球知名的数据库服务器提供商,甲骨文,Oracle,在2013年超越IBM,成为全世界第二大的企业软件公司,而在区块链行业,有一家专注于用区块链技术重构数据库的公司,它的创始人在和雷锋网AI金融评论的专访中表示,要做区块链行业的甲骨文,这家来自新加坡的区块链初创企业Bluzelle,在去年八月获得150万美...。

代码说明,本页面的认证代码为cpa70广告联盟专用评测代码,站长需懂简单html知识,直接复制代码粘贴到联盟网站相应页面即可使用,本代码不适用于其他广告联盟网站请勿获取!文字认证,文字链接代码认证适用所有类型的广告联盟,复制代码后放在cpa70广告联盟网站首页底部或友情链接位置处,普通认证,普通联盟认证标志适用所有类型的广告联盟,能有...。

骁龙8Gen4要10月21日才发布,所以大家还以为一加13要等到11月,但9月4日,在京东方的全球创新伙伴大会中,一加官宣,一加将首发第二代东方屏,,暗示一加13或在10月发布,同日,闲聊站表示一加13会首发京东方X2基材,而,华为MateXT、vivoX200系列、OPPOFindX8系列、iQOO13、一加13、真我GT7Pro、...。

在选购投影仪是相信大家都会看到亮度,系统,芯片这些参数,但是偶尔也会出现SVGA、WXGA和XGA这些参数,看到这些英文字母是不是感到一头雾水,这又是什么隐藏的参数,是不是有一阵感觉看参数怎么这么麻烦的想法,别担心,这里就给大家用最容易的理解的语言解释WXGA是什么意思?投影仪SVGA、WXGA与XGA的区别以及哪个更好呢;我们一起往...。

文字链接认证代码普通联盟标志认证代码企业广告联盟标志认证代码广告联盟评测代码说明,本页面的认证代码为凌云广告联盟专用评测代码,站长需懂简单html知识,直接复制代码粘贴到联盟网站相应页面即可使用,本代码不适用于其他广告联盟网站请勿获取!文字认证,文字链接代码认证适用所有类型的广告联盟,复制代码后放在凌云广告联盟网站首页底部或友情链接位...。

哄睡师顾名思义就是哄别人睡觉的,比如有一些人有着入睡困难的问题,就可以让哄睡师去帮助自己入睡,这其实就是一种陪伴式的聊天,并且哄睡师是很善于发现客人的心理问题的,会帮助客人解决,让客人的心情很放松,自然会产生困意,有一些哄睡师还会通过轻语以及唱歌的方式安抚客人的心情,效果是非常不错的,有一些人在听到哄睡师的时候,可能就感觉这个职业是没...。

1、关上苹果手机,在手机上点开Safari阅读器,必定要经常使用Safari启动PP助手的下载装置;2、关上阅读器后,在Safari阅读器的网址栏内输入下载;3、Safari阅读器输入下载地址后,在弹出的弹窗,装置PP助手,界面点击装置;4、进入装置界面后,期待装置实现后前往桌面会参与程序,PP助手,正版,装置,裁减资料PP助手苹果...。

马自达3的上市期间是在2006年,这款车系是长安马自达旗下的车型,它在底盘、车身、能源等方面启动了严重改良,使得其产品能源性和奢侈水平获取了极大的优化,Mazda3在日本又被称为,axela,,有5门掀背式两厢轿车和4门三厢轿车两种车型,国产版的Mazda3关键搭载了1.6升汽油发起机,作为一款静止性轿车,Mazda3很受年轻人的喜欢...。

华人夫妇日本遇害案继续引发关注,4月25日,有外地华人通知南都记者,出预先,他在这对夫妻运营的餐馆旁的店里时觉得,气氛怪怪的,,店员说最近不安保,劝其早晨不要外出,同日,考查人员披露案件最新停顿,推测夫妇生前在家里受到殴打后被塞入车内,之后被抛尸,南都此前报道,外地期间16日6时50分许,55岁的日本华人宝岛龙太郎及其56岁的妻子宝岛...。

CLIPSTUDIOPAINT是世界领先的漫画创作软件,为每一位漫画家和漫画家提供强大的艺术工具。它是为希望增强和完善他们的纸笔插图的艺术家以及希望以数字方式完成漫画

说起酒店,在过去或许还是大家比较陌生的领域,但是,现在人们的经济水平不断提高,外出住宿的话,首先就会考虑环境优美的酒店,暻阁,一家有口皆碑的酒店品牌,拥有不错的发展前景,想要加盟的话,还是需要先来看看,暻阁的名气大吗,广泛的市场覆盖率,就可以说明该品牌在业内拥有较大的名气与影响力,经过企业坚持不懈的努力,加盟店数量不断攀升,目前,每年...。

技术创新正在变革医疗与健康产业,雷锋网持续关注医疗领域出现的软硬件创新,包括设备、数据,抑或对他们的创新运用,目前我们在招募医疗健康领域作者,负责采写报道医疗科技领域的企业与牛人,简历投递至zhangchi@leiphone.com,或加微信nksimons撩,长期以来,医生都是用肉眼查看医学图像,来确定癌症治疗过程,不过来自Frau...。

中国制造2025,战略和,工业4.0,浪潮下,工业制造为自己找到了一个强大数字内核——工业互联网,工业互联网是一个被,新基建,带火的名词,今年已经是第五次被写入政府工作报告,作为第四次科技革命的中坚产能,工业互联网有机结合新一代信息技术与传统制造业,让各种资源跨越设备、系统、地区、行业,在更大的范围内高效流转,从,嫩芽初露,到,百花...。

作为蔚来汽车乐道品牌的首款力作,在9月19日乐道L60上市发布会上,蔚来高级副总裁、乐道汽车总裁艾铁成花了2个小时讲解乐道L60,这是蔚来讲产品最长的一次,足以见得蔚来对乐道L60的重视,而现场几次出现了欢呼声,也表明乐道L60的确带来不一样的惊喜,价格诚意满满,乐道L60标准续航版售价20.69万元,长续航版售价23.59万元,采用...。
刷固件破解,一步到位;可修改dns,实现全网通;适合宽带到期的用户,破解全网通电视机顶盒;免费固件下载地址,点击直达首先下载自己需要的应用,到你的U盘,推荐安装个氧气桌面极速版,点击下载其他第三方应用下载地址,http,down.znds.com,;可能大家会有疑问,为什么不安装个当贝市场,因为移动定制机限制了第三方应用的下载安装...。
