无人驾驶 如何使用立体视觉实现距离估计 (无人驾驶如何改变未来出行)
双语原文链接: Pseudo-LiDAR — Stereo Vision for Self-Driving Cars
 在自动化系统中,和计算机视觉已经疯狂地流行起来,无处不在。计算机视觉领域在过去十年中发展迅速,尤其是是障碍物检测方面。
在自动化系统中,和计算机视觉已经疯狂地流行起来,无处不在。计算机视觉领域在过去十年中发展迅速,尤其是是障碍物检测方面。
障碍物检测,如YOLO或RetinaNet,提供2D的标注框,该标注框指明了障碍物在图像中的位置。
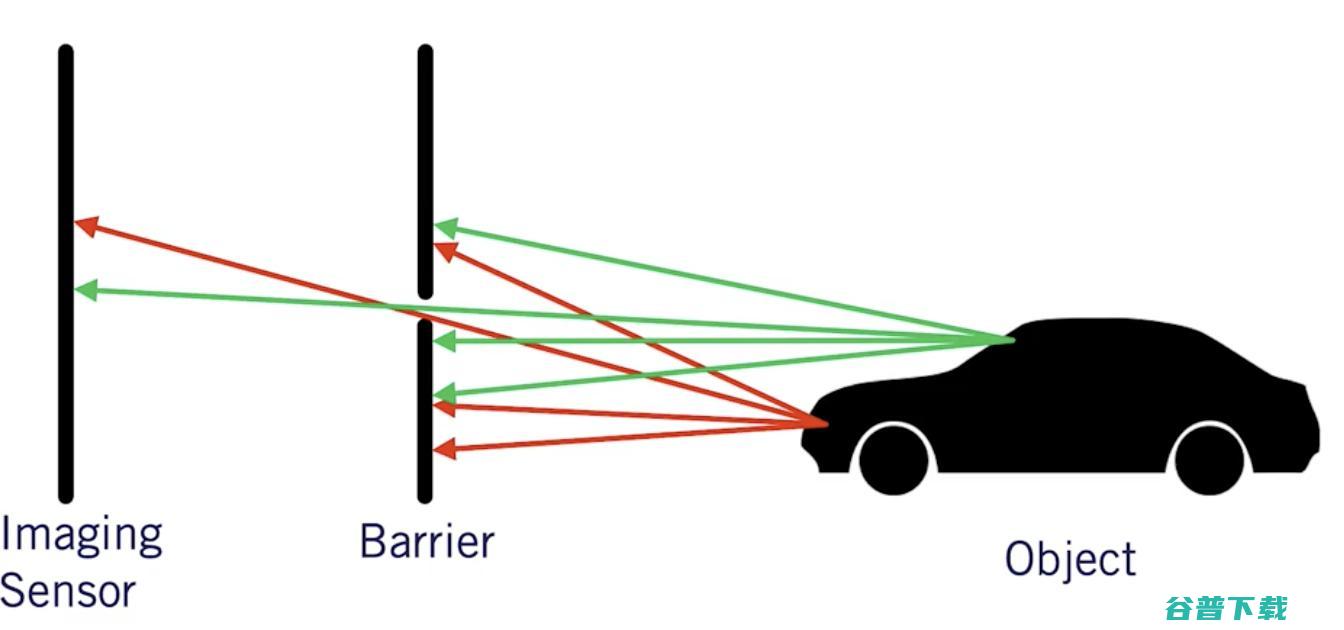
为了获取每个障碍物的距离,工程师将相机与激光雷达(光探测和测距)传感器融合,使用激光返回深度信息。利用传感器融合技术将计算机视觉和激光雷达的输出融合在一起。
使用激光雷达这种方式存在价格昂贵的问题。而对此,工程师使用的一个有用的技巧是:对齐两个像机,并使用几何原理来计算每个障碍物的距离。我们称这种新设置为 伪激光雷达。

伪激光雷达利用几何原理构造深度图,并将其与物体探测相结合,以获得三维的距离。
如何利用立体视觉实现距离估计?
以下5步伪代码用于获取距离:
1.校准2台照相机(内部和外部校准)
先建立视差图,再建立深度图
然后,深度图将与障碍检测结合在一起,我们将估算边界框像素的深度。本文结尾处有更多内容。
开始吧!
1.内部和外部校准
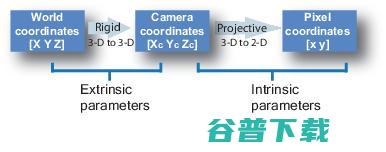
每个摄像机都需要校准。校准意味着将具有[X,Y,Z]坐标的3D点(世界上)转换为具有[X,Y]坐标的2D像素。
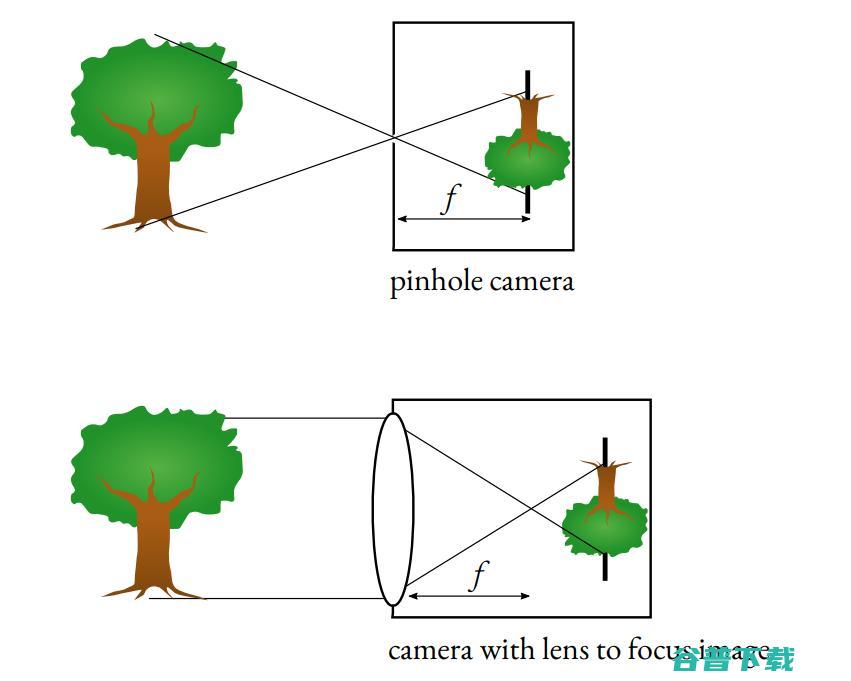
当今的相机使用针孔相机模型。这个想法是使用针孔让少量光线穿过相机,从而获得清晰的图像。
如果图像中间没有障碍物,那么每条光线都会通过,图像会变得模糊。它还使我们能够确定用于变焦和更好清晰度的焦距f。
要校准相机,我们需要将世界坐标转换为通过相机坐标的像素坐标。
固有参数是我们称为K的矩阵。
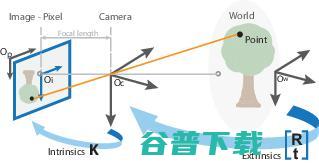
过相机校准可以找到K矩阵。
通常,我们使用棋盘格和自动来执行它。 当我们这样做时,我们告诉算法棋盘上的一个点(例如:0,0,0)对应于图像中的一个像素(例如:545、343)。

为此,我们必须使用相机拍摄棋盘格的图像,并且在经过一些图像和某些点之后,校准算法将通过最小化最小二乘方损失来确定相机的校准矩阵。
通常,必须进行校准才能消除图像失真。 针孔摄像头模型包括变形,即“ GoPro效果”。 为了获得校正的图像,必须进行校准。 变形可以是径向的或切向的。 校准有助于使图像不失真。

以下是相机校准返回的矩阵:

每一个计算机视觉工程师都必须了解和掌握摄像机的标定。这是最基本、最重要的要求。我们习惯于在线处理图像,从不接触硬件,这是个错误。
-尝试运行OpenCV进行摄像机校准。
在相机校准过程中,我们有两个公式可以将世界上的点O设为像素空间:
world到相机的转换
当您进行数学运算时,您将得出以下等式:
如果您查看矩阵尺寸,则不匹配。
因此,我们需要将O_world从[X Y Z]修改为[X Y Z 1]。
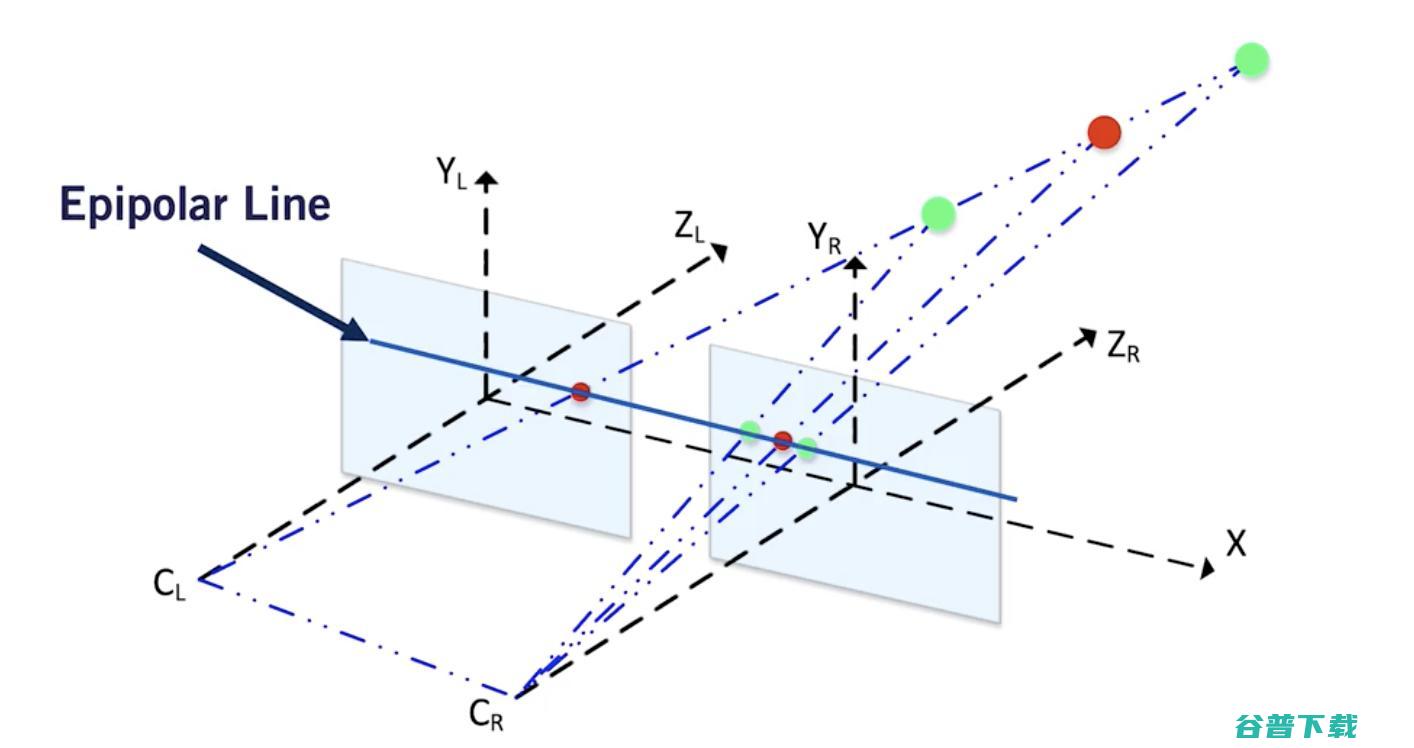
2.极线几何--立体视觉
我们的眼睛就像两个相机。因为它们从不同的角度看同一幅图像,它们可以比对两种视角之间的差异,并计算出距离估计。
下面是立体相机设置的示例。你会在大多数自动驾驶汽车上发现类似的东西。

立体相机如何估算深度
假设你有两个相机,一左一右。这两个相机在相同的Y轴和Z轴上对齐。基本上,唯一的区别就是它们X值不一样。
现在,看看下面的描述。
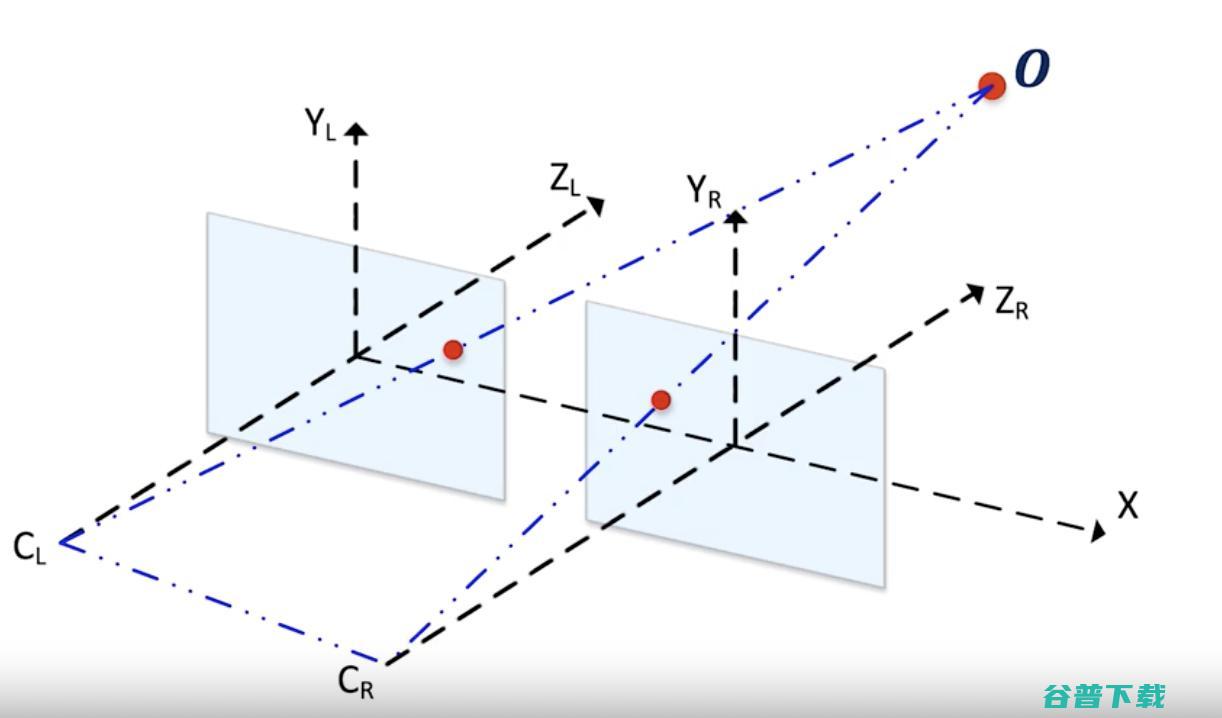
我们的目标是估算出O点(代表图像中的任何像素)的Z值,即深度距离。
现在从鸟瞰的角度来考虑这个问题。
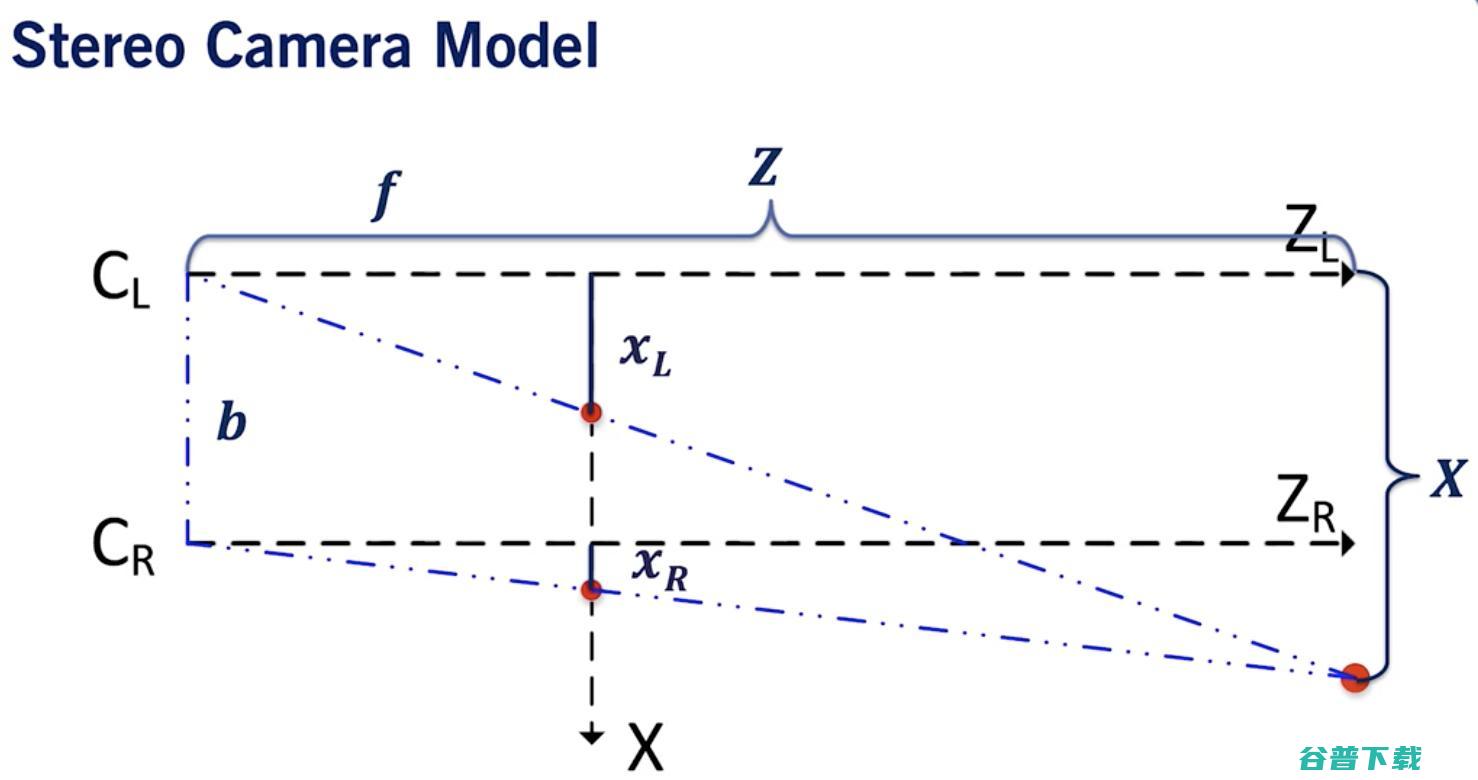
立体相机鸟瞰图说明:
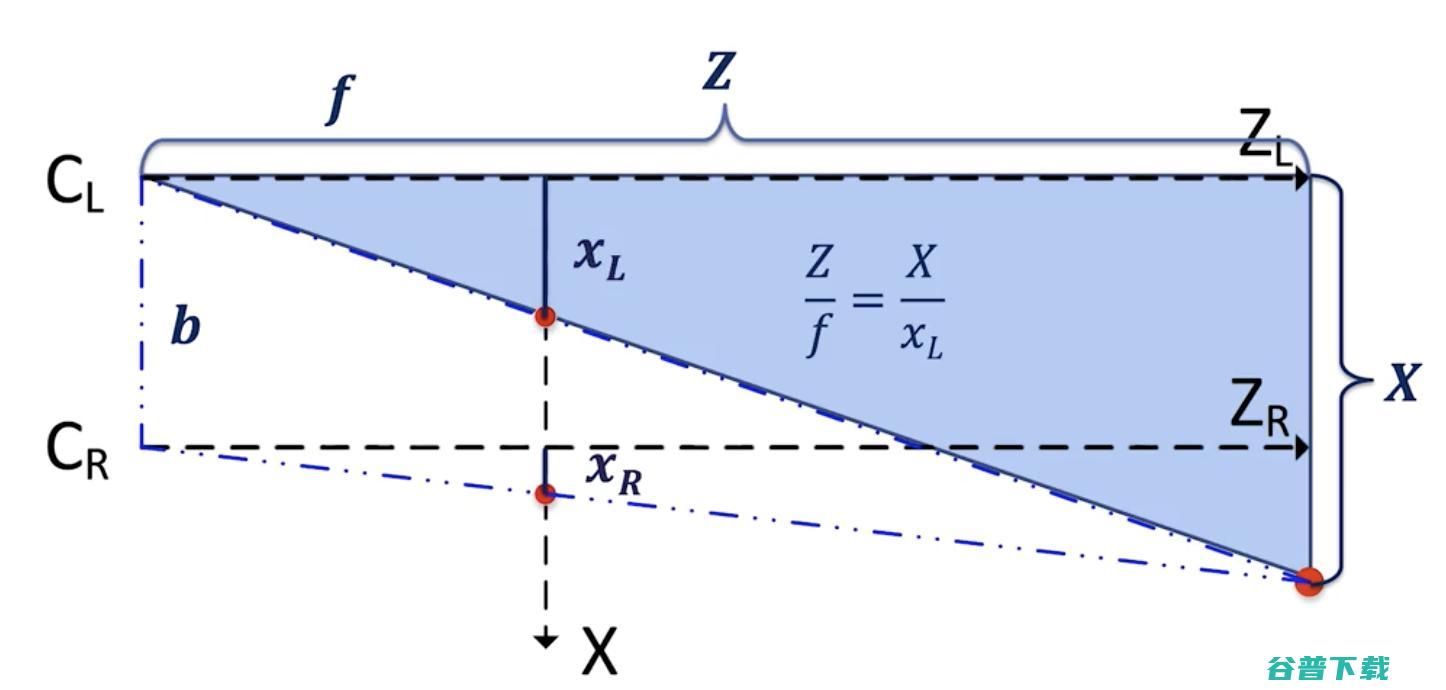
? 我们得到 Z = X*f / xL.
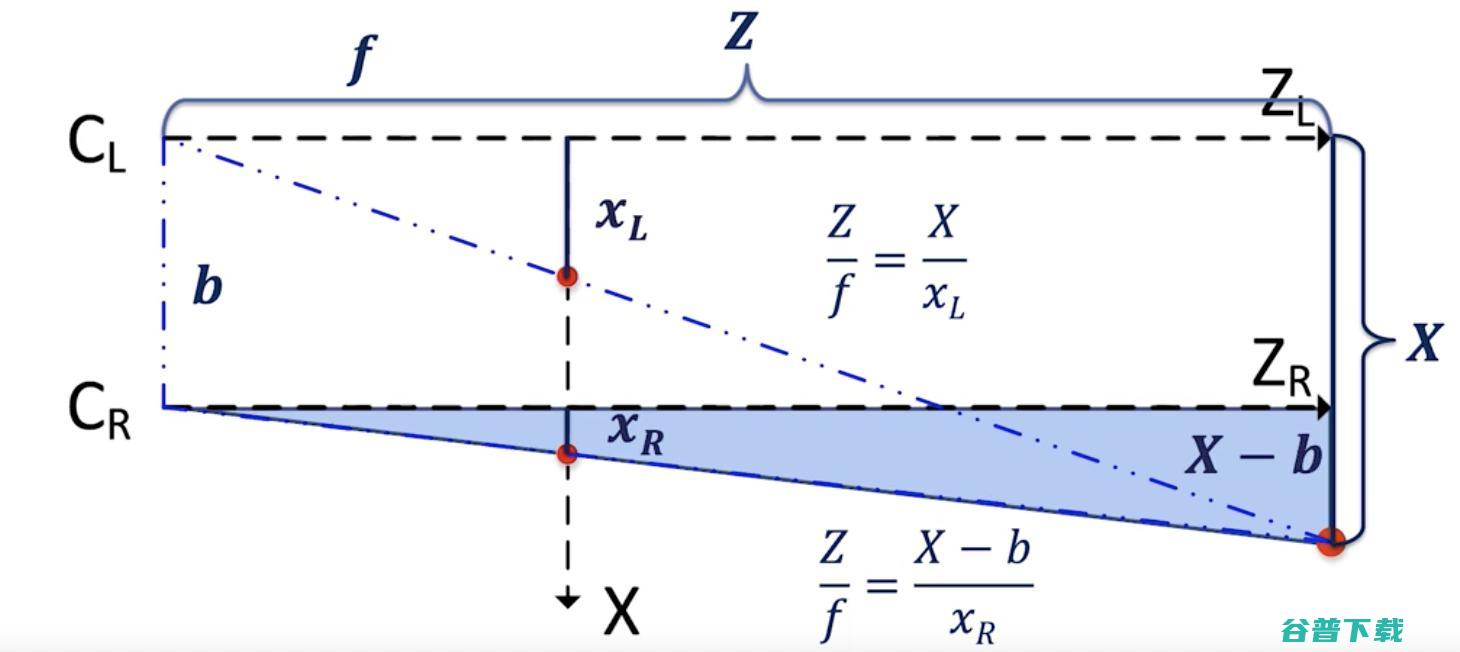
右相机方程:
? 我们获得 Z = (X — b)*f/xR.
放在一起,我们可以找到正确的视差 d =xL -- xR和目标正确的 XYZ 坐标。
3. 视差与深度图
视差是什么?视差是一个三维点从两个不同的相机角度在图像中位置的差异。
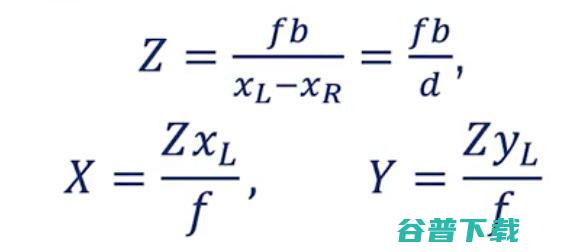
? 由立体视觉我们可以估计任何物体的深度。假设我们做了正确的矩阵校准。它甚至能够计算一个深度映射或者视差映射。

为什么是“基线几何”?要计算视差,我们必须从左图像中找到每个像素,并将其与右图像中的每个像素进行匹配。 这称为立体对应问题。
为了解决这个问题--
这是因为两个相机是沿着同一轴对齐的。
以下是基线搜索的工作原理:
 基线搜索
基线搜索
应用:建立伪激光雷达
现在,是时候将这些应用到真实世界的场景中,看看我们如何用立体视觉来估计物体的深度。
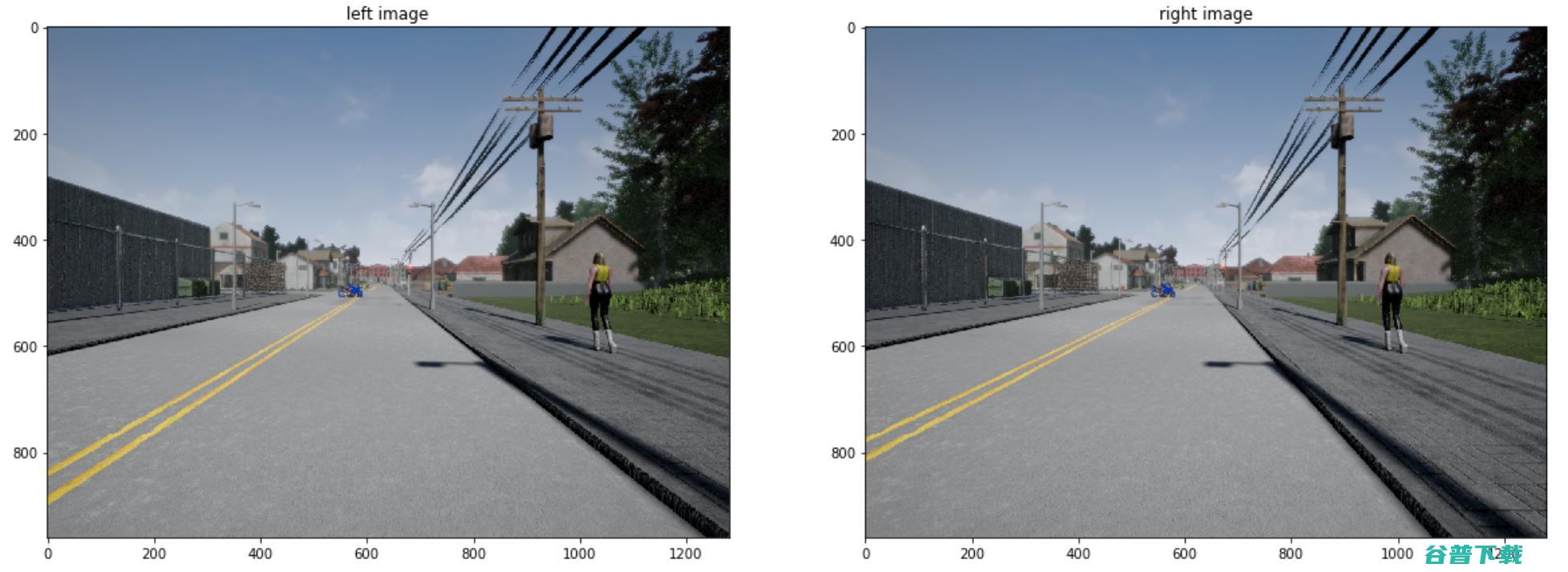
每一幅图像都有外部参数 R 和 t,事先通过校准确定(步骤1)。
视差
对于每一幅图像,我们可以计算相对于另一幅图像的视差图。我们将做如下操作:
我们将获得左右图像的视差图。
为了帮助您更好地理解差异的含义, 我在 Stack Overflow 上找到了一个很棒的解释 。

从视差到深度图
? 我们有两个视差图,这基本上告诉我们,两幅图像之间的像素位移是多少。
对于每个摄像机,都有一个投影矩阵 P_left 和 P_right。为了估计深度,我们需要估计K, R 和 t。

世界坐标系到相机坐标系的转换
cv2.decomposeProjectionMatrix()的OpenCV函数可以做到这一点,并从 P 中得到 K、R 和 t;对于每个相机,现在是时候生成深度图了。深度图将使用其他图像和视差图告诉我们图像中每个像素的距离。
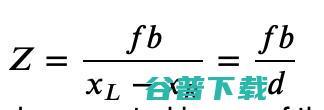
我们对每个像素进行计算。
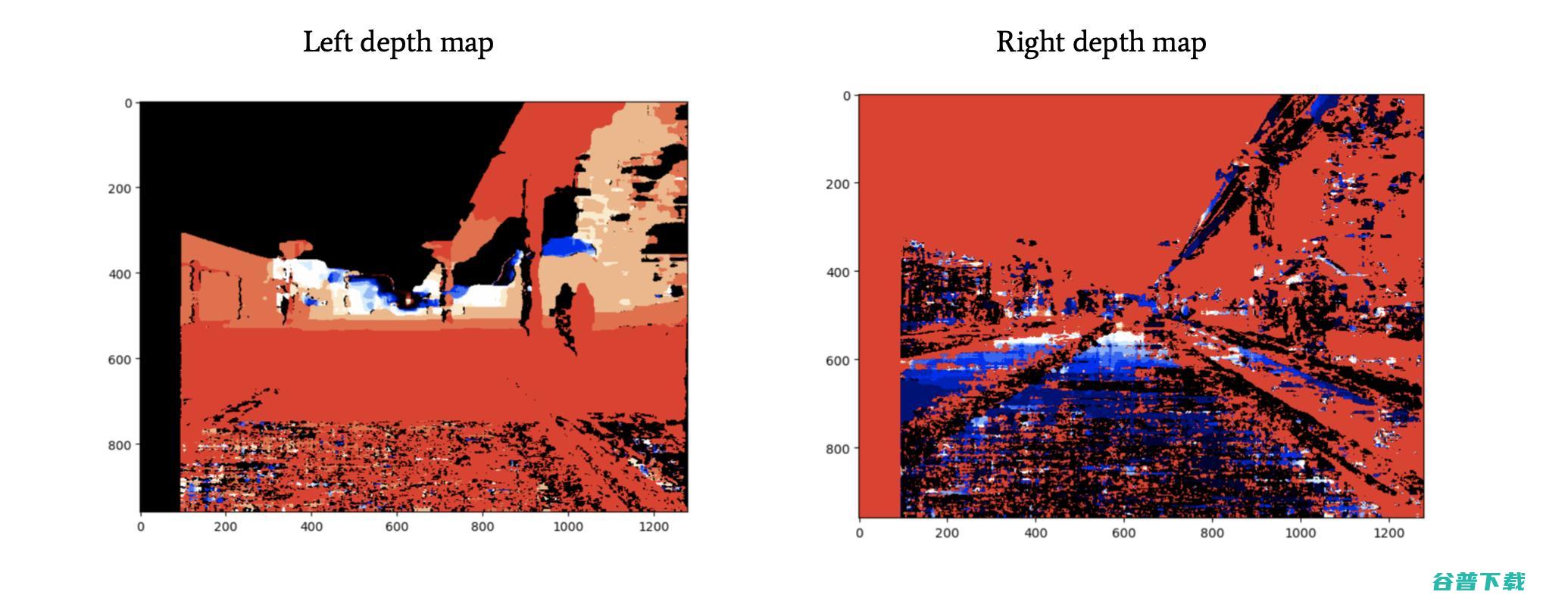
估计障碍物的深度
针对每个相机,我们都有一个深度图! 现在,假设我们将其与障碍检测(例如YOLO)结合在一起。 对于每个障碍,这种算法都会返回带有4个数字的边界框:[x1; y1; x2; y2]。 这些数字表示框的左上角和右下角的坐标。
例如,我们可以在左边的图像上运行这个算法,然后使用左边的深度图。

真不可思议!我们刚刚构建了伪激光雷达!
借助立体视觉,我们不仅知道图像中的障碍物,而且知道它们与我们的距离! 这个障碍距离我们28.927米!
立体视觉是一种使用简单的几何图形和一个额外的摄像机将2D障碍物检测转换为3D障碍物检测的技术。如今,大多数新兴的edge平台都考虑了立体视觉,比如新的OpenCV AI Kit或对Raspberry和Nvidia Jetson卡的集成。
在成本方面,与使用LiDAR相比,它保持相对便宜,并且仍具有出色的性能。我们称它为伪激光雷达,因为它可以取代激光雷达的功能。检测障碍物,对障碍物进行分类,并在3D中进行定位。

AI研习社是AI学术青年和AI开发者技术交流的在线社区。我们与高校、学术机构和产业界合作,通过提供学习、实战和求职服务,为AI学术青年和开发者的交流互助和职业发展打造一站式平台,致力成为中国最大的科技创新人才聚集地。
如果,你也是位热爱分享的AI爱好者。欢迎与译站一起,学习新知,分享成长。

版权文章,未经授权禁止转载。详情见 转载须知 。



whois反查功能,可以通过域名注册人反查whois信息。

LOL网址导航网是专业的上网导航网站,精心收录各类优质热门网站信息,同时提供天气、快递、违章等各种生活便民查询工具网址,为您提供安全便捷的上网导航服务,现已被众多网友设为上网主页,网址导航大全首选LOL网址导航.

青岛同泰永磁节能科技有限公司,电话微信:13954288362负责ABB西门子WEG电机SEW减速机同泰泵业的销售和售后服务、维修检修保养工作。专业从事各种国产电机维修(包括湘潭电机厂、上海电机厂、哈尔滨电机厂、兰州电机厂、重庆电机厂、西安电机厂、佳木斯电机厂、南阳防爆电机厂、沈阳电机厂等数十家国产电机厂家产品)、进口电机维修(瑞士ABB电机、美国GE电机、日本三菱电机TMEIC、德国西门子电机、法那科电机)、发电机维修、发电机改造、电机增容改造、电机节能改造和结构改造、变压器维修、大中型交直流电动机维修、大中型高压电机维修、马达维修、大中型防爆电机修理、风力发电机运行维护、电机线圈制造,各种大中小型电机配件销售、各种二手电机销售等。
河间金鹏模具有限公司地处河北省河间市北石槽乡张庄工业区,交通便利。产品包括:拉丝模具,硬质合金拉丝模具,圆型模具,异型模具等拉丝模具。

江苏探感物联(www.etagrfid.com.cn)作为RFID厂家,专注于RFID电子耳标,抗金属rfid标签,超高频rfid标签,超高频rfid读写器,工业rfid读写器等rfid设备。主要应用有RFID资产管理系统,RFID仓储管理系统等一站式RFID服务。

北京秋山问道公关顾问有限公司致力于为企业提供量身定制的公关咨询、策略指定、整合营销解决方案和大数据新媒体服务,让企业没有难做的营销。

广州景弘汽车租赁有限公司是广州市工商局正式批准的汽车租赁公司。公司经营租赁车辆种类齐全。可满足广州租车不同客户的需求,拥有适合平均需求的多款车型:林肯、奔驰、宝马、奥迪A6L、别克、凯美瑞、广本、帕萨特、伊兰特、瑞风、捷达、深港两地直通车、中巴及大巴车等一系列豪华车辆。所有车辆性能良好,运营全保险。全新的服务理念:根据顾客的实际需要订做各种“租车套餐”包括公务、商务、旅游等;当车辆出现故障时,同级车辆替换,保证满足顾客的租车需求;送车上门服务,顾客在家里就可以租到满意的车辆。

AIDNM新媒体(Artisticinnovationdesignfornewmedia)为品牌赋能.让世界发现,艺术创新设计与策划,专注国内外文化企业、艺术机构、原创品牌等新媒体运营,提供品牌数字创意与视觉传媒一站式协创策划服务。

南京仁康体检中心是一家专业的职业、健康体检机构,为您的健康保驾护航

泉州老蔡原味膳饮食有限公司,老蔡鸭肉面线,鸭肉面线,老蔡原味膳

盐池县九道农业科技有限公司,成立于2008年,注册资本800万元,是一家集滩羊养殖、收购、加工、储备、销售、推广、综合服务为一体化的农业企业。2021年8月在盐池县花马池镇北塘新村建设可存栏量5000只以上的盐池滩羊可视化生态智慧养殖牧场1座,现有滩羊存栏量1万只;公司计划筹建可储存1万吨盐池滩羊饲草料加工厂1座;可存栏量5000只以上的盐池滩羊可视化生态智慧养殖牧场7座;可日加工20吨盐池滩羊精深加工厂1座,截止到2021年10月,公司总资产3500万,销售收入9100余万元,其中信息化建设资金投入约1050万元。
临沂商标注册|临沂注册商标|临沂商标注册代理公司-临沂市明信知识产权代理有限公司


但凡在电商平台浏览过智能电视的用户,对,护眼,这一功能都不会陌生,毫不夸张地说,护眼电视的噱头确实让大部分做家长的用户动了心,毕竟近视已经成为危害青少年健康的首要敌人,我们都不希望自己的孩子小小年纪就戴上了近视眼镜,世卫组织爱眼协会和国内知名眼科医院研究表明,蓝光可以穿透晶状体到达视网膜,对其造成光学损害,且加速黄斑区细胞的氧化,直视...。

最近不少用户在选购投影仪的时候,纠结于当贝家的几款明星产品,型号主要有当贝X5、当贝F6和当贝X3Pro,这三款其实各有所长,那么究竟哪款更值得入手,当贝X5和F6、X3Pro详细参数配置对比一览,以上表格中标红的为产品突出优势,用户可以结合自身使用时的实际需求对照挑选,三款投影仪的主要区别在以下几点,一、光源亮度当贝X5和当贝X3P...。

一个品牌只有拥有独特的品牌特色,才能为人铭记,餐饮行业也是如此,别看现在火锅项目十分火热,但是想要从激烈的竞争中脱颖而出也是一件难度颇高的事情,不过火锅老火锅却做到了,还因此成为众多智慧之选者青睐的对象,到底火锅老火锅加盟怎么样,火锅老火锅加盟费多少钱呢,火锅老火锅加盟怎么样,火锅老火锅加盟之所以被看好,一方面是因为火锅老火锅的管理模...。

互联网搜索巨头谷歌已经放弃了在中国以代号为ProjectDragonfly创建搜索引擎的努力,此前几个月面临广泛的强烈反对和批评,据媒体报道,谷歌公共政策副总裁卡兰巴蒂亚在7月16日参议院司法委员会听证会上称,谷歌,终止了项目蜻蜓,该评论是为了回应共和党参议员约什霍利的问题,他希望了解更多信息,关于谷歌与中国打交道的高管,虽然这是一...。
一群人憧憬着对年终奖的期待,甚至开始规划自己的支配方式,然而最终的结局却是‘今年无年终奖,这是小成本电影,年终奖,的主要情节,而类似此种情节,在现实生活中总能找到映射,让人感怀的是,生活并没有因梦想破灭而发生改变,电影中的那群人在落寞之余,仍然对生活充满无限希望,临近年关,年会和年终奖与企业的,人文关怀,划上了等号,不过在互联网寒...。

想象一下,如果你能够画出或写出世界上任何一种颜色,而不是仅仅是钢笔里的墨水颜色,是不是多了一些,神笔马良,的气质,现在,这支神奇的钢笔终于诞生了,它就是ScribblePen,这支智能钢笔配备了一种特殊墨水盒和扫描器,让你能够复制任何颜色,如果用他们的宣传语来形容这款智能钢笔的话,ScribblePen应该算是,你应该购买的最后一支笔...。

时尚的网络用语以及多变的皮肤,第三方输入法往往成为替代手机自带输入法的最佳选择,但如果这些虚拟键盘会泄露你的数据……最近,据外媒报道,第三方键盘应用AI.type因储存信息的服务器未加密保护而泄露了超过3100万用户的个人数据,而储存在服务器上超过577GB的用户敏感数据,包括用户的完整名字、电子邮件地址,以及应用安装的时长,甚至每条...。

AlphaFold近年来展现给世人的惊喜层出不穷,使得向来被称为生物学圣杯的蛋白质折叠问题有了新的解决方法,为整个计算生物领域带来了更大的关注量,其中,AI蛋白质预测与设计赛道不断吸引着创业者与Meta、腾讯等大厂的加入,各种算法、模型互相比拼,不断刷新准确度、运行速度与数据库数量,在AI的赋能下,蛋白质结构数据大大增加,使得AI蛋白...。

外地时期11月12日,西班牙首相桑切斯在缺席第29届联结国气象变动大会时期宣布演讲,他示意,近日在西班牙巴伦西亚自治区出现的严重洪水患祸已造成超越220人死亡,而这是气象变动造成的结果,仅去年一年,气象变动就形成了环球30万人死亡,桑切斯同时在演讲中示意,目前最关键的事就是防止相似人造灾祸再次出现和进一步扩展,必定放慢翻新和,脱碳,的...。

CIMExplorer是一款功能非常全面的数据库管理工具,同时是下一代Windows数据库的管理工具,其中就包括了服务器和客户端计算机上大量的信息

Retouch4meAI11合1套装是一款专为PS软件所推出的AI智能修人像插件,包含独立程序+PS中文滤镜名+LR插件

美团外卖怎么使用花呗付款?很多小伙伴在使用美团点外卖时想用花呗进行支付,却不知道这么选择,今天小编就给大家介绍一下具体的操作方法,希望本篇可以帮助到大家。方

今天拆解的大号是,一禅小和尚,,一个,知人间冷暖,的情感号,表面上来看,人人都有情绪,自然也能做出情感内容,活了这么多年,谁还没有一点情感积累呢?但是,情感不是轻易就能积累起来的,一个人的情感存货毕竟有限,当存货输出耗尽,想要短时间内增加,就很难,输入,因此,门槛低不代表好做,想要持续做好情感类媒体号比你想象中更难,这篇文章非常适合...。

法律解决人们各种困难,还有各种纠纷,也解决人们之间的矛盾,所以法律的出现,就受到广大消费者的青睐,易法通法律是一家连锁品牌店,主打经营法律咨询和服务,专业的团队,利用专业的知识,给顾客带去专业的服务,所以受到很多人的喜爱和追捧,看到人们十分的好奇,想要知道,易法通法律服务专业吗,收费高吗,易法通法律服务专业吗易法通法律已经专注企业法律...。

12月5日,,2024中国生成式AI大会,在上海开幕,全球AI领域的顶尖专家、行业领袖与技术创新者汇聚一堂,会上,枫清科技,Fabarta,创始人兼CEO高雪峰深入探讨了人工智能在企业智能化转型中的关键作用,高雪峰指出,随着AI技术的不断进步,企业转型已经进入一个全新阶段,过去,企业的信息化与数字化转型主要集中于加速业务流以及提升业务...。

近日,2021年医学人工智能大会,CMAI2021,暨第一届,中国医学学术期刊发展,高端论坛在北京举办,本次大会邀请了数十位顶尖医院的放射科主任及人工智能技术的权威专家,本次大会由中国生物医学工程学会医学人工智能分会、中国医学影像AI产学研用创新联盟、中国研究型医院学会感染与炎症分会、国家卫健委全国卫生健康传承项目放射专业委员会、北京...。

太阳底下无新事,谁能想到,双击666的快手,竟然做起了教育,这事要从,种草莓,说起,两年前,快手发现一个有意思的现象,每天都有众多老铁们在快手上教授和传播农业种植知识,而且点击量还不错,有个一直在快手教,草莓种植术,的人提出,快手能不能做一个付费功能,可以让大家在上面卖课,这个建议引起了快手高级副总裁马宏彬的注意,并让快手萌生了做教育...。
