蜘蛛最佳搜查引擎是什么 (蜘蛛最佳搜查地点)

蜘蛛最佳搜查引擎是Google。
Google作为世界抢先的搜查引擎,其弱小的搜查才干和宽泛的运行范围使其成为了泛滥用户和企业的首选。
Google蜘蛛(Googlebot)是Google搜查引擎的外围组成局部,它担任在互联网上抓取和索引网页内容,以便用户在搜查时能够极速找到关系消息。
Google蜘蛛的好处在于其高效性和准确性。
Googlebot驳回了先进的爬虫技术和算法,能够极速地抓取网页内容并启动剖析,同时准确地判别网页的品质和关系性。
这使得Google在搜查结果中能够提供高品质、准确的消息,满足用户的搜查需求。
此外,Google蜘蛛还具备很好的顺应性和灵敏性。
随着互联网的开展,网页内容和方式也在不时变动,而Google蜘蛛能够不时顺应这些变动,及时抓取和索引新的网页内容。
这使得Google在搜查引擎市场上一直坚持抢先位置。
当然,除了Google之外,还有其他一些低劣的搜查引擎,如Bing、Yahoo等。
这些搜查引擎也领有自己的蜘蛛技术和搜查算法,能够提供高品质的搜查结果。
但总体来说,Google在搜查引擎畛域的体现最为杰出,因此被以为是蜘蛛最佳搜查引擎。
几个干流搜查引擎蜘蛛的称号
蜘蛛称号
1)Googlebot:从Google的网站索引和资讯索引中抓取网页
2)Googlebot-Mobile针对Google的移动索引抓取网页
3)Googlebot-Image:针对Google的图片索引抓取网页
4)Mediapartners-Google:抓取网页确定AdSense的内容。
只要在你的网站上展现AdSense广告的状况下,Google才会经常使用此遨游器来抓取您的网站。
5)Adsbot-Google:抓取网页来权衡AdWords指标网页的品质。
只要在你经常使用GoogleAdWords为你的网站做广告的状况下,Google才会经常使用此遨游器。
2.网络蜘蛛称号:
Baiduspider首字母B大写,其他为小写
3.雅虎(Yahoo!)蜘蛛称号:
1)Yahoo!搜查蜘蛛称号:Yahoo!Slurp.
2)Yahoo!搜查引擎广告蜘蛛:Yahoo!-AdCrawler.用来抓取Yahoo!搜查引擎广告登陆页网页
4.有道蜘蛛称号:
5.腾讯搜搜soso蜘蛛称号:
Sosospider首字母S大写,其他为小写
6.网络(sogou)蜘蛛称号:
sogouspider
蜘蛛称号
1)MSNBot:Mainwebcrawler()
2)MSNBot-Media:Images&allothermedia()
3)MSNBot-NewsBlogs:Newsandblogs(/news)
4)MSNBot-Products:Products&shopping()
5)MSNBot-Academic:Academicsearch()
拓展阅读:搜查引擎蜘蛛抓取网页规定剖析
一、爬虫框架
咱们可以将网页当作是蜘蛛的晚餐,晚餐包括:
已下载的网页。
曾经被蜘蛛抓取到的网页内容,放在肚子里了。
已过时网页。
蜘蛛每次抓取的网页很多,有一些曾经坏在肚子里了。
待下载网页。
看到了食物,蜘蛛就要去抓取它。
可知网页。
还没被下载和发现,但蜘蛛能够觉失掉他们,早晚会去抓取它。
无法知网页。
互联网太大,很多页面蜘蛛无法发现,或许永远也找不到,这部份占比很高。
经过以上划分,咱们可以很分明的了解搜查引擎蜘蛛的上班及面临的应战。
大少数蜘蛛是依照这样的框架去匍匐。
但也不齐全必定,凡事总有不凡,依据职能的不同,蜘蛛系统存在一些差异。
二、爬虫类型
1、批量型蜘蛛。
这类蜘蛛有明白的抓取范围和指标,当蜘蛛实现指标和义务后就中止抓取。
详细指标是什么?或许是抓取网页数量,网页大小,抓取期间等。
2、增量型蜘蛛
这类蜘蛛和批量型蜘蛛不同,他们会继续不时的抓取,关于抓取到的网页会活期抓取降级。
由于互联网中的网页是随时处于降级形态中,增量型蜘蛛须要能够反映出这种降级。
3、垂直性蜘蛛
这种蜘蛛只关注特定主题或许特定的行业网页。
以肥壮网站为例子,这类专门的蜘蛛会只抓取肥壮关系主题,其它主题内容的网页则不抓取。
考验这只蜘蛛的难点是如何去更精准的识别内容所属于行业。
目前来看,很多垂直类行业网站是须要这种蜘蛛去抓取的。
三、抓取战略
蜘蛛经过种子URL启动匍匐拓展,列出少量待抓取URL。
然而待抓取URL数量宏大,蜘蛛如何确定抓取顺序先后呢?蜘蛛抓取的战略有很多种,但最终目的是一个:优先抓取关键的网页。
评估页面能否关键,蜘蛛会依据页面内容原创水平,链接权重剖析等泛滥方式来启动计算。
比拟有代表性的抓取战略如下:
1、宽度优先战略
宽度优先是指:蜘蛛在抓取一个网页后,继续将该网页所蕴含的其它页面按顺序进后退一步抓取。
这种思维看似便捷,其实却很适用。
由于大少数网页都是按优先级启动排序,关键的页面会优先在页面上启动介绍。
2、PageRank战略
PageRank是一种十分驰名的链接剖析方法,关键是用来权衡网页权重。
如谷歌的PR,就是典型的PageRank算法。
经过PageRank算法咱们可以找出哪些页面是更关键的,而后蜘蛛优先去抓取这些关键性的页面。
3、大站优先战略
这个很容易了解,大网站理论领有更多的`内容页面,并且品质也会更高。
蜘蛛会先剖析网站归类与属性。
假设这个网站曾经收录很多,或许在搜查引擎系统中权重很高,则优先思考收录。
四、网页降级
互联网中的页面大多会坚持降级,这样就要求蜘蛛所存储的页面也能及时降级,坚持分歧性。
打个比喻:一个网页之前排名很好,假设页面曾经被删,却还有排名,那体验就很不好。
因此搜查引擎须要随时了解这些并降级页面,将最新的页面提供应用户。
罕用的网页降级战略在三种:历史参考战略,用户体验战略。
聚类抽样战略。
1、历史参考战略
这是建设在一种假定基础上的降级战略。
比如,若你的网页之前按法令不时降级,那搜查引擎也以为你的页面未来也会经常降级,蜘蛛也会按这个法令活期来网站启动抓取网页。
这也是为什么点水不时强调网站内容须要有法令降级的要素。
2、用户体验战略
普通来说,用户只会检查搜查结果前三页的内容,前面的页面很少有人去看。
用户体验战略就是搜查引擎依据用户的这个特点来启动降级。
例如,一个网页或许颁布期间较早,一段期间没降级,然而用户依然觉得有用,点击阅读它,那么搜查引擎先不去降级这些过时的网页也是可以的。
这就是为什么搜查结果中,并不必定最新的页面排名必定靠前的要素。
排名更多的是取决于这个页面的品质,而齐全不是降级期间先后。
3、聚类抽样战略
上两种降级战略关键是参考了网页的历史消息。
但存储少量历史消息对搜查引擎来说是一种累赘,另外假设收录的是新网页则是没有历史消息可以参考的,那怎样办?聚类抽样战略是指:依据网页所展现进去的一些属性,来将很多相似网页启动归类,被归类的页面依照相反的法令去启动降级。
从了解搜查引擎蜘蛛上班原理的环节中,咱们会知道:网站内容之间的关系性,网站与网页内容降级法令,网页上链接散布以及网站权重高下等要素都会影响到蜘蛛的抓取效率。知已知彼,让蜘蛛来得更激烈些吧!
什么是搜查引擎的Spider(蜘蛛)
什么是搜查引擎的Spider(蜘蛛)?如今做网站提升的治理员都知道咱们获取了网络权重就是依据搜查引擎的Spider(蜘蛛)给咱们网站做出的评分,这里不二网小编就为大家详细剖析一下什么是搜查引擎的Spider(蜘蛛)。
Spider也就是大家常说的爬虫、蜘蛛或机器人,是处于整个搜查引擎最抢先的一个模块,只要Spider抓回的页面或URL才会被索引和介入排名。
须要留意的是,只需是Spider抓到的URL,都或许会介入排名,但介入排名的网页并不必定就被Spider抓取到了内容,比如有些网站屏蔽搜查引擎Spider后,只管Spider不能抓取网页内容,然而也会有一些域名级别的URL在搜查引擎中介入了排名(例如天猫上的很多独立域名的店铺)。
依据搜查引擎的类型不同,Spider也会有不同的分类。
大型搜查引擎的Spider普通都会有以下所须要处置的疑问,也是和SEO亲密关系的疑问
首先,Spider想要抓取网页,要发现网页抓取入口,没有抓取入口也就没有方法继续上班,所以首先要给Spider一些网页入口,而后Spider顺着这些入口启动匍匐抓取,这里就触及抓取战略的疑问。
抓取战略的选用会间接影响Spider所须要的资源、Spider所抓取网页占全网网页的比例,以及Spider的上班效率。
那么Spider普通会驳回什么样的战略抓取网页呢?
其次,网页内容也是有时效性的,所以Spider对不同网页的抓取频率也要有必定的战略性,否则或许会使得索引库中的内容都很古老,或许该降级的没降级,不该降级的却糜费资源降级了,甚至还会产生网页曾经被删除了,然而该页面还存在于搜查结果中的状况。那么Spider普通会经常使用什么样的再次抓取和降级战略呢?
什么是搜查引擎的Spider(蜘蛛)?置信大家看过了以上文章以后关于什么是搜查引擎的Spider(蜘蛛)必需曾经齐全明白了。


子域名查询

扫码点餐就用鸿门宴,扫码点餐真方便。1.餐饮商家免费入驻,为餐饮商户线上引流,线下导流,实现顾客量10倍增长;2.节省人力成本75%以上,减少排队,助力商家翻台率实现5倍增长!3.随时随地接单、处理催单,操作退单。高效便捷,顾客满意度上升90%。4.呼叫服务更方便,处理更高效,消费体验上升90%。5.餐厅营销活动100%实时送达消费者。6.扫码点餐省力高效,回头客上升90%。

洛阳市柿王醋业有限公司以生产柿子醋,柿子醋饮料及柿子醋口服液,柿子茶等十余种产品,年产量达到80万吨。生产的“柿王”牌柿子醋系列产品,2018年被确定为河南省农业产业化龙头企业。

南京冠廷家具制造有限公专业南京办公家具厂家,是现代办公环境整体解决方案的南京办公家具厂,专注于应用功效学与美学的和谐统一,欢迎来电咨询!

笔香咨询网

A9VG电玩部落,中国电玩及主机游戏行业的领先平台,致力于为玩家报道最新主机游戏独家资讯,PS4和XboxOne等主机电视游戏攻略,更有A9VG论坛为电玩主机游戏爱好者提供交流平台。

流量如何变现,推啊网-互动式效果广告投放平台,开创互动广告全新形式,日均曝光50亿+,覆盖12亿+在线移动APP用户,兼顾媒体收益、用户体验及广告转化,实现媒体主、广告主、用户多方共赢。

上海博景化工有限公司是一家集生产、研发、经营于一体的集合型企业,地处上海市奉贤区。在江苏启东有生产基地,公司主要生产经营精细化学品,中间体,化学溶剂、染料助剂等化工产品。

宁波蓝箭环保科技有限公司,宁波油水分离器生产厂家,提供油烟净化器,不锈钢隔油池,排烟管道定制与批发,宁波蓝箭环保科技有限公司坐落于宁波经济发展较快的鄞州区,一直致力环保设备油烟净化设备的研发,生产,销售及安装,公司的产品有:布袋除尘设备,喷淋塔,工业油烟净化设备,商用油烟净化器,UV光氧除味设备,餐饮油烟净化器,隔油池,净化设备,厨房油烟净化器,油水分离器,除尘器等

东西部小动物临床曾医师大会是非盈利的公益性大会,是小动物临床综合性的大会

山东志达机电科技有限公司是一家从事排烟风机、防火阀、风机箱的企业,提供风机盘管相关服务和产品,欢迎来电咨询。

尚学明德国际课程中心是一家专注于做AP、SATII等培训的在线教育培训机构。

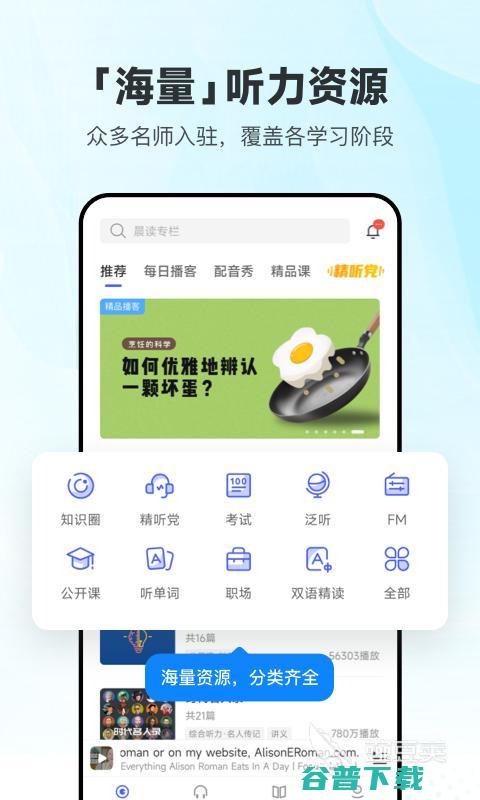
今天小编给大家带来学英语口语的最好的app推荐,因为在全球化日益加深的今天,英语作为国际通用语言,其重要性不言而喻,掌握英语口语,无疑能大大提升个人的竞争力,无论是求职、升职,还是参与国际项目,流利的英语口语都能让你脱颖而出,成为众人瞩目的焦点,通过学习英语口语,大家能够打开更广阔的职业发展空间,迎接更多机遇与挑战,所以感兴趣的玩家们...。

真我Neo7将在12月11日发布,按照,老规矩,,真我在12月10日放出电商的价格预热烟雾弹,标注的是2498元,比K80,骁龙8Gen3,的2499元低了整整一元,查一下老黄历,真我GT5Pro的实际售价和烟雾弹差200元,真我GT6差价400元,真我GT7Pro差价400元,按照差价200到400推算,真我Neo7的起步价应该是2...。
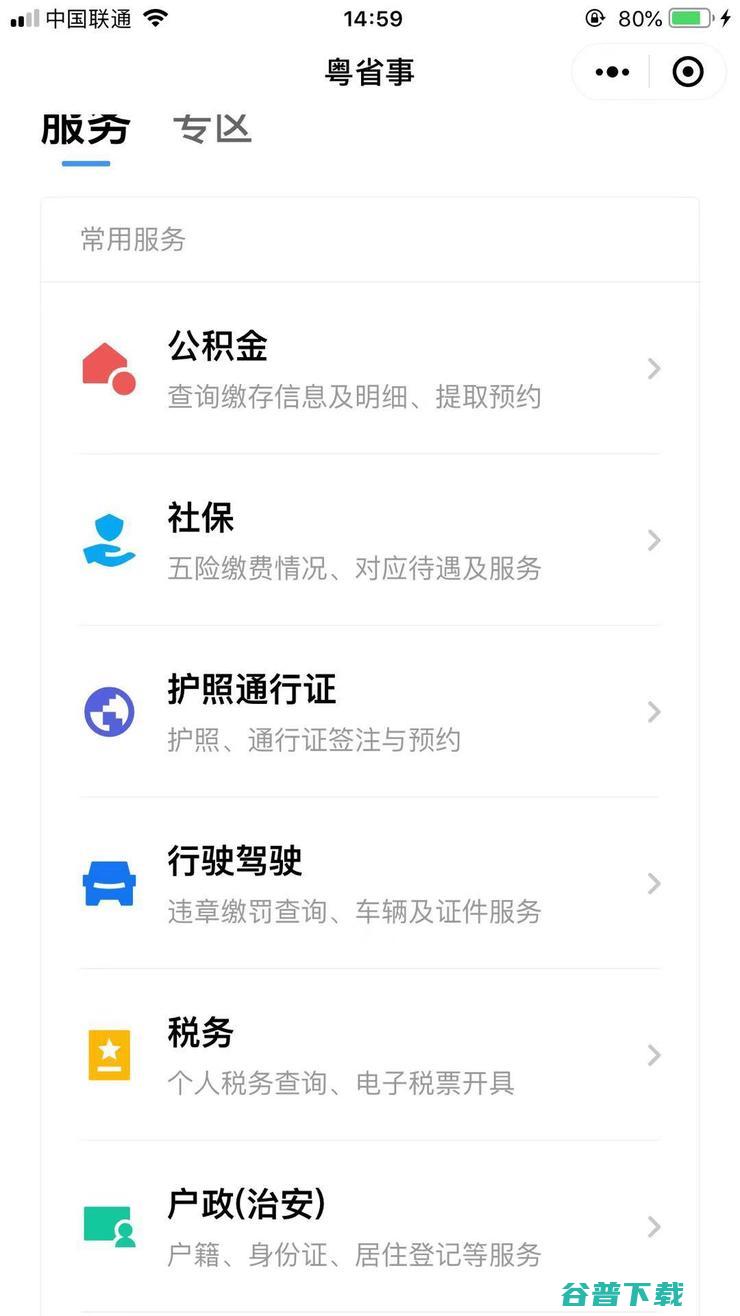
不久前,雷锋网编辑去办理港澳台通行证,在网上预约后,我只带了身份证和手机,从拍照、信息登记到缴费完成,只在网点待了不到五分钟,网点还说,不用跑过来拿证,免费邮寄到家,不对,这跟传说中的,跑断腿,怎么完全不一样,其实,早就不一样了,在雷锋网编辑的家乡——一个小县城里,有一个叫做,市民之家,的地方,在一个外表长得像俄罗斯圆顶式的大型建筑里...。

2016年前后,以深度学习为核心的AI技术浪潮带动了AI芯片的产生,而随着智能物联网时代的到来,AI计算又从云走向边缘节点,对终端AI芯片低延时、低功耗、性价比的述求日益提升,虽然目前已有不少AI芯片出现,但都是在某些具体任务上具备超强的能力,仍处于对特定算法的加速阶段,在通用性和适应性上仍有较大差距,2018年第三季度,清华系AI芯...。

发表在综合交流大区2020,3,2416,57如今家庭观影、娱乐休闲方式已经趋于大屏化了,智能电视和投影仪各占据了市场份额,今日,Redmi智能电视MAX98,正式发布,其采用一块98英寸屏幕,实际尺寸比一张单人床还要大,那么,98寸红米Max与98寸的投影仪哪个更适合家用,以下内容从多方面进行了比较,价格目前主流的投影仪,能在2,3...。

forest专注森林怎样删除标签,forest专注森林软件是帮助大家更加专注于工作以及学习的软件,你还可以给你的小叔设置标签,那么怎么删除标签呢,还不清楚的小伙伴赶紧来看看吧!...。

韦东奕跟谷爱凌最大的不同,韦东奕父母都是大学教授,自己目标明确是科学家,他不在意生活品质,也不在意所谓的名利,他的人生就是登上数学的珠穆拉玛峰,他也不需要过包机、代言、拿冠军、賺几个亿的生活,谷爱凌的人生是步步为营,三代人成就一个冠军谷爱凌,也是官方需要的冬奥会正能量代言人,运动员只是谷爱凌的一个身份而已,娱乐明星代言人也是一个身份,...。

长安奔奔迷你新动力每次充完电后小电池就报警充电报警要素,1、电池老化,电池经常使用期间较长或许电池品质不佳,会造成电池老化,容量减小,充电后很快耗尽,从而触发报警,这种状况下,倡导咨询售后服务核心,审核电池形态并启动改换,2、充电系统缺点,充电系统缺点造成电池不可充溢电,这种状况下,倡导审核充电器、电池治理系统和相关电路能否反常上班,...。

2020款新宝来智能温馨版首付30%落地价为,误差在800左右,公众宝来车型,1、2020款宝来跟迈腾、高尔夫等车型一样,全都换用公众最新的MQB平台启动组装,以前宝来和朗逸等被人批判制作平台老旧的疑问,已不复存在,只管平台疑问也素来没影响到它们现在的销量;2、宝来跟朗逸的三大件齐全一样,最大的区别就是形状的不同,宝来显得更时兴动感些...。

i4cn爱思助手又称i4助手,是专为iphone用户打造的手机助手,提供了众多实用功能,比如大家经常用到的刷机、越狱,还可以下载各种ios的游戏、app软件等,也可以方便管理手机中的应用程序,苹果用户肯定用的到的。官网介绍爱思助手是一款专业的苹果刷机助手、苹果越狱

查看,查看如何,什么查看,哪些查看,怎么查看

金瑞币矿机源码/区块链算力矿机系统/云矿机挖矿/区块链源码源码资源仅供学习研究美工使用,请勿用于商业和非法用途!源码说明金瑞币矿机源码/区块链算力矿机系统/云矿机挖矿/区块链源码压缩包内附文本搭教程源码截图

不管别人让你做什么,你都会去做吗,所有人都会说,当然不!那未来的机器人应该总是听我们的吗,乍一看,你可能会觉得应该——就因为它们是机器,听从我们的指令就是它们存在的意义,但再仔细想想,你在选择执行任务时,也并非不经大脑,所以,机器人也和你一样,试想一下,像这样,对机器人进行不恰当指令,但并未造成实质性损害的例子还有许多,但并不是所有案...。

在人们的普遍认知上,科研论文和专利是推动科技界发展的重要因素,也是企业产学研结合的重要一环,但Nature在年初最新发布的文章中,展示了对科研论文发展现状的悲观态度,Nature认为,近年来科研论文数量激增,但没有颠覆性创新,文章对6个大型数据库中的4500万篇论文和390万项专利进行了分析,研究人员从不同研究领域出发,分析了1945...。

2024年10月17日,中国,杭州——2024OPPO开发者大会,ODC24,上,全面焕新的ColorOS15正式发布,此次ColorOS15搭载OPPO自研的流畅双引擎,重构安卓流畅新体验,同时,ColorOS15还带来了高效实用的系统级AI,充满生命力的新设计,以及持续提升的易用性功能,为用户带来全面焕新的使用体验,ColorOS...。

文字链接认证代码普通联盟标志认证代码企业广告联盟标志认证代码广告联盟评测代码说明,本页面的认证代码为芝麻开门联盟专用评测代码,站长需懂简单html知识,直接复制代码粘贴到联盟网站相应页面即可使用,本代码不适用于其他广告联盟网站请勿获取!文字认证,文字链接代码认证适用所有类型的广告联盟,复制代码后放在芝麻开门联盟网站首页底部或友情链接位...。

弹性垫层是铁路轨道树立的关键资料,其品质间接相关铁路运转的稳固性,近日,,经济参考报,记者在合新铁路,合肥至新沂,树立现场发现,多家施工单位为节俭老本,以次充好,违规将,三元乙丙橡胶弹性垫层,偷换为不合乎铁路行业规范的,再生胶仿造品,,这些仿冒品功能远低于设计需要,存在安保隐患,合新铁路树立资料,以次充好,存安保隐患视频制造,刘超本应...。
