这里是排名前三的论文解读 2017 NeurIPS 论文 2018 年引用量排名揭晓 (这里是排名前几的英文)
雷锋网 AI 科技评论按,12 月上旬,NeurIPS 2018 在加拿大蒙特利尔会展中心(Palais des Congrès de Montréal)成功举办,雷锋网对此进行了报道。今年的会议在主题活动、投稿论文数量和参会人数上,相比往年都上了一个新台阶。NeurIPS 2018 吸引了近九千人参加,最终 1010 篇论文被接收,其中,有四篇论文被评为最佳论文,接收的覆盖了十大研究领域。
看完新论文,别忘旧论文。日前,学术头条对入选 NeurIPS 2017 的论文在 2017.12 至 2018.12 之间的引用量进行了统计,引用量超过 100 的论文有 19 篇,论文名单如下:


可以看到,引用量排名前三的论文分别是 Attention Is All You Need、ImProved Training ofWasserstein GANs 和 Dynamic Routing BetweenCapsules。此前,雷锋网对这几篇论文也有过解读,今天,就和大家一起再复习下吧。
这是谷歌与多伦多大学等高校合作发表的一篇论文,他们提出了一种新的网络框架——Transformer。Transformer 是完全基于注意力机制(attentionmechanism)的网络框架,放弃了 RNN 和 CNN 模型。
众所周知,在编码-解码框架中,主流的序列传导模型都是基于 RNN 或者 CNN,其中能完美连接编码器和解码器的是注意力机制。而谷歌提出的这一新框架 Transformer,则是完全基于注意力机制。
Transformer 用于执行翻译任务,实验表明,这一模型表现极好,可并行化,并且大大减少了训练时间。Transformer 在 WMT 2014 英德翻译任务上实现了 28.4 BLEU,改善了现有的最佳成绩(包括超过 2 个 BLEU 的集合模型),在 WMT2014 英法翻译任务中,建立了一个新的单一模式,在八个 GPU 上训练了 3.5 天后,最好的 BLEU 得分为41.0,这在训练成本最小的情况下达到了最佳性能。由 Transformer 泛化的模型成功应用于其他任务,例如在大量数据集和有限数据集中训练英语成分句法解析的任务。
注意力机制是序列模型和传导模型的结合,在不考虑输入输出序列距离的前提下允许模型相互依赖,有时(但是很少的情况),注意力机制会和 RNN 结合。
模型结构如下:
编码器:编码器由 6 个完全的层堆栈而成,每一层都有两个子层。第一个子层是多头的 self-attention 机制,第二层是一层简单的前馈网络全连接层。在每一层子层都有 residual 和归一化。
注意(attention):功能是将 Query 和一组键-值对映射到输出,那么包括 query、键、值及输出就都成为了向量。输出是值的权重加和,而权重则是由值对应的 query 和键计算而得。
在该论文中,蒙特利尔大学的研究者对 WGAN 进行改进,提出了一种替代 WGAN 判别器中权重剪枝的方法。
论文摘要
生成对抗网络(GAN)将生成问题当作两个对抗网络的博弈:生成网络从给定噪声中产生合成数据,判别网络分辨生成器的的输出和真实数据。GAN 可以生成视觉上吸引人的图片,但是网络通常很难训练。前段时间,Arjovsky 等研究者对 GAN 值函数的收敛性进行了深入的分析,并提出了 WassersteinGAN(WGAN),利用 Wasserstein 距离产生一个比 Jensen-Shannon 发散值函数有更好的理论上的性质的值函数。但是仍然没能完全解决 GAN 训练稳定性的问题。
所做工作 :
通过小数据集上的实验,概述了判别器中的权重剪枝是如何导致影响稳定性和性能的病态行为的。
提出具有梯度惩罚的 WGAN(WGAN with gradient penalty),从而避免同样的问题。
展示该方法相比标准 WGAN 拥有更快的收敛速度,并能生成更高质量的样本。
展示该方法如何提供稳定的 GAN 训练:几乎不需要超参数调参,成功训练多种针对图片生成和语言模型的 GAN 架构。
WGAN 的 critic 函数对输入的梯度相比于 GAN 的更好,因此对生成器的优化更简单。另外,WGAN 的值函数是与生成样本的质量相关的,这个性质是 GAN 所没有的。WGAN 的一个问题是如何高效地在 critic 上应用 Lipschitz 约束,Arjovsky 提出了权重剪枝的方法。但权重剪枝会导致最优化困难。在权重剪枝约束下,大多数神经网络架构只有在学习极其简单地函数时才能达到 k 地最大梯度范数。因此,通过权重剪枝来实现 k-Lipschitz 约束将会导致 critic 偏向更简单的函数。如下图所示,在小型数据集上,权重剪枝不能捕捉到数据分布的高阶矩。
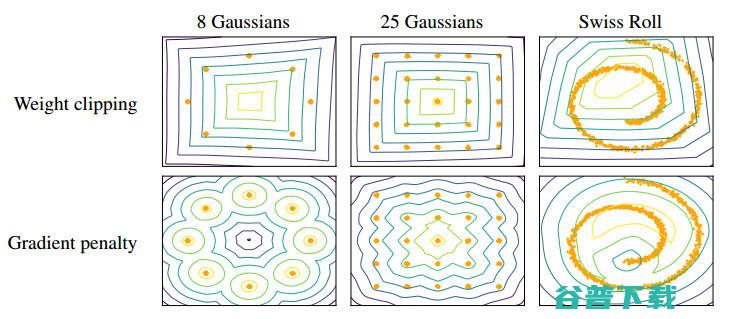
由于在 WGAN 中使用权重剪枝可能会导致不良结果,研究者考虑在训练目标上使用 Lipschitz 约束的一种替代方法:一个可微的函数是 1-Lipschitz,当且仅当它的梯度具有小于或等于 1 的范数时。因此,可以直接约束 critic 函数对其输入的梯度范数。新的 critic 函数为:
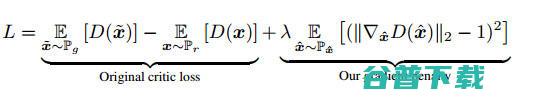
使用 GAN 构建语言模型是一项富有挑战的任务,很大程度上是因为生成器中离散的输入输出序列很难进行反向传播。先前的 GAN 语言模型通常凭借预训练或者与监督最大似然方法联合训练。相比之下,使用该论文的方法,不需采用复杂的通过离散变量反向传播的方法,也不需要最大似然训练或 fine-tune 结构。该方法在 Google Billion Word 数据集上训练了一个字符级的 GAN 语言模型。生成器是一个简单的 CNN 架构,通过 1D 卷积将 latentvector 转换为 32 个 one-hot 字符向量的序列。
该文提供了一种训练 GAN 的稳定的算法,能够更好的探索哪种架构能够得到最好的生成模型性能。该方法也打开了使用大规模图像或语言数据集训练以得到更强的模型性能的大门。
本论文在Github上开源了代码:
本论文同时也提供了详细的数学证明,以及更多的示例,进一步了解请阅读原论文: Improved Training of Wasserstein GANs
为了避免网络结构的杂乱无章,Hinton 提出把关注同一个类别或者同一个属性的神经元打包集合在一起,好像胶囊一样。在神经网络工作时,这些胶囊间的通路形成稀疏激活的树状结构(整个树中只有部分路径上的胶囊被激活),从而形成了他的 Capsule 理论。Capsule 也就具有更好的解释性。
Capsule 这样的网络结构在符合人们「一次认知多个属性」的直观感受的同时,也会带来另一个直观的问题,那就是不同的胶囊应该如何训练、又如何让网络自己决定胶囊间的激活关系。Hinton 这篇论文解决的重点问题就是不同胶囊间连接权重(路由)的学习。
解决路由问题
首先,每个层中的神经元分组形成不同的胶囊,每个胶囊有一个「活动向量」activity vector,它是这个胶囊对于它关注的类别或者属性的表征。树结构中的每个节点就对应着一个活动的胶囊。通过一个迭代路由的过程,每个活动的胶囊都会从高一层网络中的胶囊中选择一个,让它成为自己的母节点。对于高阶的视觉系统来说,这样的迭代过程就很有潜力解决一个物体的部分如何层层组合成整体的问题。
对于实体在网络中的表征,众多属性中有一个属性比较特殊,那就是它出现的概率(网络检测到某一类物体出现的置信度)。一般典型的方式是用一个单独的、输出 0 到 1 之间的回归单元来表示,0 就是没出现,1 就是出现了。在这篇论文中,Hinton 想用活动向量同时表示一个实体是否出现以及这个实体的属性。他的做法是用向量不同维度上的值分别表示不同的属性,然后用整个向量的模表示这个实体出现的概率。为了保证向量的长度,也就是实体出现的概率不超过 1,向量会通过一个非线性计算进行标准化,这样实体的不同属性也就实际上体现为了这个向量在高维空间中的方向。
采用这样的活动向量有一个很大的好处,就是可以帮助低层级的胶囊选择自己连接到哪个高层级的胶囊。具体做法是,一开始低层级的胶囊会给所有高层级的胶囊提供输入;然后这个低层级的胶囊会把自己的输出和一个权重矩阵相乘,得到一个预测向量。如果预测向量和某个高层级胶囊的输出向量的标量积更大,就可以形成从上而下的反馈,提高这两个胶囊间的耦合系数,降低低层级胶囊和其它高层级胶囊间的耦合系数。进行几次迭代后,贡献更大的低层级胶囊和接收它的贡献的高层级胶囊之间的连接就会占越来越重要的位置。
在论文作者们看来,这种「一致性路由」(routing-by-agreement)的方法要比之前最大池化之类只保留了唯一一个最活跃的特征的路由方法有效得多。
网络构建
作者们构建了一个简单的 CapsNet。除最后一层外,网络的各层都是卷积层,但它们现在都是「胶囊」的层,其中用向量输出代替了 CNN 的标量特征输出、用一致性路由代替了最大池化。与 CNN 类似,更高层的网络观察了图像中更大的范围,不过由于不再是最大池化,所以位置信息一直都得到了保留。对于较低的层,空间位置的判断也只需要看是哪些胶囊被激活了。
这个网络中最底层的多维度胶囊结构就展现出了不同的特性,它们起到的作用就像传统计算机图形渲染中的不同元素一样,每一个胶囊关注自己的一部分特征。这和目前的计算机视觉任务中,把图像中不同空间位置的元素组合起来形成整体理解(或者说图像中的每个区域都会首先激活整个网络然后再进行组合)具有截然不同的计算特性。在底层的胶囊之后连接了 PrimaryCaps 层和 DigitCaps 层。
胶囊效果的讨论
在论文最后,作者们对胶囊的表现进行了讨论。他们认为,由于胶囊具有分别处理不同属性的能力,相比于 CNN 可以提高对图像变换的健壮性,在图像分割中也会有出色的表现。胶囊基于的「图像中同一位置至多只有某个类别的一个实体」的假设也使得胶囊得以使用活动向量这样的分离式表征方式来记录某个类别实例的各方面属性,还可以通过矩阵乘法建模的方式更好地利用空间信息。不过胶囊的研究也才刚刚开始,他们觉得现在的胶囊至于图像识别,就像二十一世纪初的 RNN 之于语音识别——研究现在只是刚刚起步,日后定会大放异彩。
论文全文参见:
谷歌推出基于注意机制的全新翻译框架,Attention is All You Need!
蒙特利尔大学研究者改进Wasserstein GAN,极大提高GAN训练稳定性
终于盼来了Hinton的Capsule新论文,它能开启深度神经网络的新时代吗?
版权文章,未经授权禁止转载。详情见 转载须知 。



司法拍卖,阿里司法拍卖是全国知名的网上拍卖平台,让人民法院可以自主在互联网上开展司法拍卖,确保了司法拍卖的公开、公平、公正!全国已有99%的法院入驻阿里拍卖进行司法拍卖、95%的司法拍卖也都在阿里拍卖平台成交。

作为数据驱动的内容产业服务,新榜发挥行业枢纽作用,连接线上线下资源,提供内容营销、电商导购、用户运营、版权分发等产品服务,服务于内容产业,以内容服务产业。

天津市宏冠宇金属制品有限公司

陕西省黄龙县人民法院

沧州恒运管道装备制造有限公司

星空云AI财税机器是是面向中小型企业和财税代理公司的专业、简单、智能的全自动财税一体化软件:可以精准高效自动采集发票、银行账单等,能够自动生成凭证、账表,同时自动批量一键申报;无需专业会计知识也能轻松做账报税,真正为企业降本增效提升利润。

国通网企是一家专业从网站建设,网站制作,网站设计,网页设计,手机网站建设等综合型的网络公司,团队网站建设经验丰富,做网站就找国通网企,我们为您真诚服务。服务热线:0755-84810325

意林乐器意林乐器经过过去和世界知名品牌日本YAMAHA公司、德国B&S公司、法国BUFFET公司以及台湾KHS集团等的直接合作,在四川及西南区域建立了完善的销售服务体系,并同YAMAHA合作建立了西南唯一的一家雅马哈管乐CUSTOM专家售后服务中心。

7723游戏盒是国内知名的安卓手游分享社区,这里有海量好玩安卓游戏,热情的游戏互动氛围,最有创意和技术的UP主,在7723游戏盒和全球玩家共享游戏乐趣。

成语大全(成语词典在线查询)收录四字成语等4万多条,提供成语解释、成语用法、成语出处、成语歇后语、成语谜语、成语故事大全、成语接龙、近义词、反义词等查询。

uao提供了一套综合的企业全集成云数据库应用与平台服务,实现企业数字营销,营销自动化助力提升企业营销.

九五收录(www.95sl.com)是一个一站式自动秒收录平台,流量互增的自动发布外链和友情链接交换收录平台,自动友情链接收录,可以给你网站提高百度权重,网址收录网站收录交换链接增加反向链接加快百度收录,网站自动收录,永久免费的自动收录网站!

第一次听说,轻应用,这个词是在去年的8月某天,那时候观看一个百度在2013年百度世界大会视频记住了两样东西,皇太吉说未来移动互联网是服务经济时代,其次是百度宣布推出,轻应用,,可实现无需下载,即搜即用和通过移动搜索智能分发,当听到这样的消息时候不难发现这其中的商机,那就是移动互联网应用开发者经历了微博开放、微信时代的崛起等机会,几乎每...。

雷锋网消息,平头哥刚刚在乌镇互联网大会上宣布开源MCU芯片设计平台,这是国内首家开源芯片设计平台的公司,也是平头哥继玄铁910、无剑SoC、含光800之后的又一款新品,开源MCU芯片设计平台的目标群体包括芯片开发者、IP供应商、高校及科研院所等,开发者可以基于该平台设计面向细分领域的定制化芯片,IP供应商能够研发原生于该平台的核心IP...。

雷锋网讯,据外媒Theinformation报道,知情人士称,阿里巴巴正商议向智联招聘投资数亿美元,此次新的投资可能存在将阿里的技术与庞大的客户基础与智联招聘上所积累的公司和岗位信息数据产生协作,知情人士还表示,阿里正寻求成为智联招聘的大股东之一,并获得该公司少量股权,除阿里之外,还有其他潜在投资者也在关注投资智联招聘,智联招聘成立于...。

民生银行曾经的标签是,小微之王,,但现在它更想做银行科技的,先行者,2015年后,民生银行放弃了小微战略,转头向科技迈进,首家互联网直销银行、首家试水生物识别支付应用的股份制银行、首家实现GPI方式汇款的股份制银行、首家成功上线分布式核心帐户系统的银行、首家5G手机银行......民生银行越来越希望以一个银行科技开拓者的全新形象站在...。

瓶装水有着便携性强、口感怡人、定价合理的特点,其爱市场中受到消费者的青睐,产品销量一直保持在较高的位置,得益于有利的市场形势,许多业界品牌的市场份额得到持续拓展,既然项目有着鲜明的优势,那么创业者适时开家店经营是切实可行的,下文将对1元瓶装纯净水招商代理给出清晰说明,给读者朋友提供帮助,1元瓶装纯净水招商代理巴马矿泉水拥有自建的生产工...。

代码说明,本页面的认证代码为牛联盟专用评测代码,站长需懂简单html知识,直接复制代码粘贴到联盟网站相应页面即可使用,本代码不适用于其他广告联盟网站请勿获取!文字认证,文字链接代码认证适用所有类型的广告联盟,复制代码后放在牛联盟网站首页底部或友情链接位置处,普通认证,普通联盟认证标志适用所有类型的广告联盟,能有效提升牛联盟的可信度,复...。

23日,16兆瓦海上风电机组在福建三峡海上风电产业园下线,该机组是目前全球单机容量最大、叶片最长的海上风电机组,其发电机、叶片、数字化控制系统等主要部件完全实现国产化,基本解决了关键部件国外垄断,卡脖子,问题,16兆瓦海上风电机组下线仪式现场本次下线的海上风电机组由中国三峡集团、金风科技联合研发,单机容量16兆瓦海上风电机组,叶轮直径...。

在国内SUV车型市场中,10万元出头价位的车型竞争尤其激烈,以往自主品牌对这个细分市场格外看重,几乎每个自主品牌都有几款这个价位的SUV产品,近年来,随着合资品牌也开始对这个细分市场加以重视,有越来越多的合资品牌入门SUV车型加入进来,使这个细分市场更加火爆,10万元出头价位的SUV车型,自主品牌产品普遍尺寸更大,而对于对于空间方面没...。
手机自带的运行商店是自动全权的,用户不可修正权限,这样就须要卸载掉运行商店的更新,,360手机助手,,而后到网络从新下载装置包,在装置的环节中产生权限设置,此时设置不准许自启动就可以了,或许就是间接肃清运行商店的数据,也可以临时的喧扰一会儿,天天农场360版安卓游戏如何下载要下载天天农场360版安卓游戏,你可以经过访问360手机助手或...。

以色列国防军发言人19日地下示意,巴勒斯坦伊斯兰抵制静止,哈马斯,无法能被,覆灭,这番话与总理本雅明·内塔尼亚胡在最新一轮巴以抵触中的最终指标相悖,造成总理办公室发申明反驳,媒体解读,此事再次泄露以色列政府与军方就推进加沙地带军事执行的一致,这张以色列国防军5月18日颁布的照片显示,以军在加沙地带南部市区拉法东部开展军事执行,新华社...。

支付宝蚂蚁新村2022年03月11日题目是:我国是全球最大的油料生产国,对吗?答对即可获得3个村民作为奖励。问题:我国是全球最大的油料生产国,对吗?A、错误B、正确正确答案:正确答案解析:我国是全球最大的油料生产国,油料总产量世界第一。目前我国国产八大食用植物油有菜籽油、花生油、大豆油、棉籽油、茶籽油、葵花籽油、芝麻油和亚麻籽油。

如何将html文件变成wordpress中的一个page 1、将xx.html修改为page-xx.php上传到你当前使用的主题目录中;在WordPress后台创建别名为xx的页面后发布,大功告成。2、第一种比较简单。就是在编写

许多小伙伴们就喜欢自己一个人沉浸在一款手游为大家塑造的世界中,那么本期小编就为大家解答2025年有哪些好玩的单机游戏呢这个问题,小编从豌豆荚平台精选了五款适合大家的单机手游,希望小伙伴们能在小编推荐的这些单机手游中体会游戏的细节、发掘游戏带给大家的乐趣,1、,植物大战僵尸2,作为一款经典游戏系列的第二部,这款手游保留了以往守卫后花园,...。

雷锋网最新消息,今日晚间,中兴通讯发布公告称公司已经与美国政府就美国政府出口管制调查案件达成和解,与此同时,中兴通讯将支付约8.9亿美元的刑事和民事罚金,此外,还有给美国商务部工业与安全局3亿美元罚金被暂缓,是否支付,取决于未来七年公司对协议的遵守并继续接受独立的合规监管和审计,事实上,中兴通讯和美国政府之间的暗斗还要追溯到去年3月,...。

雷锋网消息,自2012年以来,全球PC整体出货量在6年多的时间里始终处于下滑中,然而正当今年第三季度即将迎来好转的时候,Intel这边14nm,的产能却跟不上了,在决定将10nm处理器的发布推迟到2019年下半年之后,Intel刚刚发布了两款新的14nm,处理器,代号为WhiskeyLake的第八代CoreU低功耗移动处理器和用于...。

2D和3D是机器视觉领域两个重要的概念,一个维度之差,带来的是从平面信息到空间信息的质的飞跃,3D视觉诞生之初以人眼作为参照,目的是让机器能够更清晰地认知人类所处的三维世界,这个赛道的企业无不以,3D视觉,自居,然而,在这场从2D到3D的技术接力赛中,也潜藏着一个不被外界所知的维度——2.5D,一大半宣称3D视觉的公司,其实都是2....。

发表在坚果投影仪2022,7,2610,41坚果O1S是坚果官方最新推出的家用超短焦LED投影仪,整机外观和前代O1相似,那么坚果O1S相比O1得到了哪些提升呢,下面就通过详细的参数对比分析了解这款投影仪的不同点,看看坚果O1S是否值得入手,坚果O1S和O1区别,1.光学参数在亮度方面,坚果O1S对比O1,拥有更高的亮度,实际亮度从8...。
