GPT-4终结人工标注!AI标注比人类标注效率高100倍,成本仅1/7|ai|示例|置信度|gpt-4|软件安装包
用微信扫码二维码
分享至好友和朋友圈
【新智元导读】
 这个开源工具,居然能用GPT-4代替人类去标注数据,效率比人类高了100倍,但成本只有1/7。
这个开源工具,居然能用GPT-4代替人类去标注数据,效率比人类高了100倍,但成本只有1/7。
大模型满天飞的时代,AI行业最缺的是什么?毫无疑问一定是算(xian)力(ka)。
老黄作为AI掘金者唯一的「铲子供应商」,早已赚得盆满钵满。
除了GPU,还有什么是训练一个高效的大模型必不可少且同样难以获取的资源?
高质量的数据。OpenAI正是借助基于人类标注的数据,才一举从众多大模型企业中脱颖而出,让ChatGPT成为了大模型竞争中阶段性的胜利者。
但同时,OpenAI也因为使用非洲廉价的人工进行数据标注,被各种媒体口诛笔伐。
时代周刊报道OpenAI雇佣肯尼亚廉价劳动力标注
而那些参与数据标注的工人们,也因为长期暴露在有毒内容中,受到了不可逆的心理创伤。
卫报报道肯尼亚劳工指责数据标注工作给自己带来了不可逆的心理创伤
总之,对于数据标注,一定需要找到一个新的方法,才能避免大量使用人工标注带来的包括道德风险在内的其他潜在麻烦。
所以,包括谷歌,Anthropic在内的AI巨头和大型独角兽,都在进行数据标注自动化的探索。
谷歌最近的研究,开发了一个和人类标注能力相近的AI标注工具
Anthropic采用了ConstitutionalAI来处理数据,也获得了很好的对齐效果
除了巨头们的尝试之外,最近,一家初创公司refuel,也上线了一个AI标注数据的开源处理工具:Autolabel。
Autolabel:用AI标注数据,效率最高提升100倍
这个工具可以让有数据处理需求的用户,使用市面上主流的LLM(ChatGPT,Claude等)来对自己的数据集进行标注。
refuel称,用自动化的方式标注数据,相比于人工标注,效率最高可以提高100倍,而成本只有人工成本的1/7!
就算按照使用成本最高的GPT-4来算,采用Autolabel标注的成本只有使用人工标注的1/7,而如果使用其他更便宜的模型,成本还能进一步降低
采用AutolabelLLM的标注方式之后,标注效率更是大幅提升
对于LLM标注质量的评估,Autolabel的开发者创立了一个基准测试,通过将不同的LLM的标注结果和基准测试中不同数据集中收纳的标准答案向比对,就能评估各个模型标注数据的质量。
当Autolabel采用GPT-4进行标注时,获得了最高的准确率——88.4%,超过了人类标注结果的准确率86.2%。
而且其他比GPT-4便宜得多的模型的标注准确率,相比GPT-4来说也不算低。
开发者称,在比较简单的标注任务中采用便宜的模型,在困难的任务中采用GPT-4,将可以大大节省标注成本,同时几乎不影响标注的准确率。
Autolabel支持对自然语言处理项目进行分类,命名实体识别,实体匹配和问答。
支持主流的所有LLM提供商:OpenAI、Anthropic和GooglePalm等,并通过HuggingFace为开源和私有模型提供支持。
Autolabel免除了编写复杂的指南,无尽地等待外部团队来提供数据支持的麻烦,用户能够在几分钟内开始标注数据。
可以支持使用本地部署的私有模型在本地处理数据,所以对于数据隐私敏感度很高的用户来说,Autolabel提供了成本和门槛都很低的数据标注途径。
所以,不论是律所想要通过GPT-4来对法律文档进行分类,还是保险公司想要用私有模型对敏感的客户医疗数据进行分类或者筛查,都可以使用Autolabel进行高效地处理。
如果没有Autolabel,用户需要首先收集几千个示例,并由一组人工注释者对它们进行标注,可能需要几周的时间——熟悉标注方针,从小数据集到大数据集进行几次迭代,等等。
而如果使用Autolabe可以在分钟内就对这个数据集进行标注。
首先安装所有必要的库:
现在,将OpenAI密钥设置为环境变量。
下载和查看数据集
将使用一个名为CivilComments的数据集,该数据集可通过Autolabel获得。你可以在本地下载它,只需运行:
接下来,通过运行agent.plan,使用config中指定的LLM对的数据集进行一次标注
定义下面的配置文件:
如果要创建自定义配置,可以使用CLI或编写自己的配置。
最后,进行数据标注:
输出结果为54%的准确率不是很好,进一步改进的具体方法可以访问以下链接查看:
技术细节:标注质量Benchmark介绍
在对Autolabel的基准测试中,包含了以下数据集:
表1:Autolabel标注的数据集列表
表2:用于评估的LLM提供者与模型列表
本研究在三个标准上对LLM和人工标注进行评估:
对于每个数据集,研究人员都将其拆分为种子集和测试集两部分。
种子集包含200个示例,是从训练分区中随机采样构建的,用于置信度校准和一些少量的提示任务中。
测试集包含2000个示例,采用了与种子集相同的构建方法,用于运行评估和报告所有基准测试的结果。
在人工标注方面,研究团队从常用的数据标注第三方平台聘请了数据标注员,每个数据集都配有多个数据标注员。
此过程分为三个阶段:
研究人员为数据标注员提供了标注指南,要求他们对种子集进行标注。
然后对标注过的种子集进行评估,为数据标注员提供该数据集的基准真相作为参考,并要求他们检查自己的错误。
可以看到,与熟练的人工数据标注员相比,最先进的LLM已经可以在相同甚至更好的水平上标注文本数据集,并且做到开箱即用,大大简化了繁琐的数据标注流程。
但由于LLM是在大量数据集上训练出来的,所以在评估LLM的过程中存在着数据泄露的可能。
研究人员对此进行了例如集合的额外改进,可以将表现最好的的LLM(GPT-4、PaLM-2)与基准真相的一致性从89%提高到95%以上。
对于提供对数概率的LLM(text-davinci-003),研究人员使用这些概率来估计置信度。
对于其他LLM,则使用FLANT5XXL模型进行置信度估计。
例如,上图显示,在95%的质量阈值下,我们可以使用GPT-4标注约77%的数据集。
添加这一步的原因是token级日志概率在校准方面的效果不佳,如GPT-4技术报告中所强调的那样:
GPT-4模型的校准图:比较预训练和后RLHF版本的置信度和准确性
95%与基准真相一致的完成率
相比之下,人类标注者与基准真相的一致性为86.6%。
从上图可以看到在所有数据集中,GPT-4的平均完成率最高,在8个数据集中,有3个数据集的标注质量超过了这一质量阈值。
而其他多个模型(如text-bison@001、gpt-3.5-turbo、claude-v1和flan-t5-xxl)也实现了很好的性能:
平均至少成功自动标注了50%的数据,但价格却只有GPT-4API成本的1/10以下。
在接下来的几个月中,开发者承诺将向Autolabel添加大量新功能:
支持更多LLM进行数据标注。
支持更多标注任务,例如总结等。
支持更多的输入数据类型和更高的LLM输出稳健性。
让用户能够试验多个LLM和不同提示的工作流程。
我是一万米高的搞笑女2023-09-1719:21:36


Powerfulcodingtrainingsystem.LintCodehasthemostinterviewproblemscoveringGoogle,Facebook,Linkedin,Amazon,Microsoftandsoon.WeprovideChineseandEnglishversionsforcodersaroundtheworld.

360AI人工智能商店,精选互联网资源最全的ai人工智能网,搜集并整理人工智能工具的网站、教程、资源,让您能够快速找到适合的工具和内容。收录AI工具网站、公众号、自媒体、书籍、电影等,分类包括AI趣站、AI开放平台、AI资讯、有趣网站、开源项目、AI学习平台等内容,涵盖了AI绘画,AI游戏,AI视频,AI网址大全,AI工具软件,AI搜索、AI写作、AI剪辑、AI动画、AI3D、AI游戏、AI营销等等

4399无敌版小游戏大全收录了国内外无敌版小游戏,双人小游戏无敌版,变态版小游戏,冒险王无敌版小游戏,无敌版小游戏全集,dnf2.7无敌版小游戏,无敌版小游戏最新版。好玩就拉朋友们一起来玩吧!

硫回收|有机废气处理-江苏恒新能源是一家集新材料新技术的研发、工程工艺设计、产品加工制造、工程总承包、合同能源管理运营、股权投资于一体的综合型高新技术企业。公司专业致力于化工、环保领域的酸性气体治理及资源化利用、硫回收、有机废水处理等技术研发和工程化应用,服务于工业生产的安全环保与节能降耗。

八神智能天下是国内最大的安卓/鸿蒙/Android/Harmony游戏、软件发布网站。这里提供安卓/鸿蒙软件、游戏、主题、电影、BT游戏的下载

北京通联天地科技有限公司成立于2002年10月,注册资本1000万,是一家专业的移动通信增值服务提供商,也是中国首家专注于向普通百姓提供医疗卫生信息咨询服务的专业公司,是工信部下进行大众中高端医疗服务咨询的公司,拥有强势运营商的优势资源。

四川斯坦福电力设备有限公司专业从事发电机的销售,租赁和维修,咨询电话:028-81463192,欢迎大家来电咨询有关四川柴油发电机组,四川发电机,,四川厂用大功率发电机,绵阳附近发电机四川发电机组的相关详情.

山东裕发食品有限公司山东裕发食品有限公司是一家生产鸡肉泥、鸡肉制品、鹅制品、海鲜制品、调理食品的专业厂家。

分享各行业用户推荐的各类优质文章,丰富你的生活,同时学习到你所需要的知识。

居居侠APP是隶属于湖南居居时代数字科技有限公司一家以信息智能动态交付技术为核心的口碑自装交付平台公司以工匠服务驱动研发,攻克家装行业最难以解决的施工批量交付难题,同时打通F2C家装全案供应链,结合公司智能可视化预算系统以及DIY选款系统,并通过12年互联网技术沉淀,砍掉90%订单运营成本,为业主打造设计、施工、材料一体化的超高信价比的新型自装模式。

威海华恩橡塑新材料有限公司专业生产塑料抗铜剂,橡胶抗铜剂,电缆抗铜剂,线缆抗铜剂,橡胶电缆抗铜剂

我们提供:探矿权,采矿权,金矿,铅锌矿,铜矿,锰矿,矿权拍卖,矿权转让,矿权交易,矿权网,有色金属矿,磷矿,地热矿,国有产权,公司股权,土地,林地,房屋,酒店,水电站,项目转让,产权转让,股权转让。详情请访问http://www.88cc88.cn


10月23日,英方软件举办以,D,新起点·数未来,为主题的,2020英方软件产品发布会,除了发布,大数据管理、数据副本管理、智能运维、多地办公数据跟随,等新领域成果,英方软件在过去10年数据复制核心技术和产品的基础上,提出围绕不同行业用户的数据保护、管理和业务需求,以>,一、Data,赋能行业,为用户打造个性化服务英方软件董事长...。

雷锋网按,随着百度Robotaxi在北京的全面开放,一如6月份,滴滴自动驾驶车辆出现在上海街头,,自动驾驶,再次成为破圈话题,不可否认的是,随着自动驾驶企业在各个城市的落地,一场原本在企业之间的角逐之战,已然扩散到以城市为中心,今年2月,国家11个部委联合出台了,智能汽车创新发展战略,,将智能网联汽车的发展视为汽车行业的头等大事,这一...。

近几年,随着人工智能领域的快速发展,无论是研究开发领域,还是应用落地领域,各个环节对人才的需求有增无减,而人才短缺已成为我国人工智能发展中的最大短板,然而人工智能人才培养的周期很长,AI人才稀缺的问题长期困扰着行业,根据教育部印发的,高等学校人工智能创新行动计划,,中国人工智能人才缺口超过500万,如此庞大的需求,短时间内肯定无法得到...。

在音频设备飞速发展的今天,消费者对声音的期待已经不再满足于,能听清,,而是追求更细腻、更震撼、更沉浸的听觉体验,然而,行业却始终面临两大痛点,一方面,设备的功能堆叠多于体验提升,高品质音频常被局限于特定场景;另一方面,技术与用户感知之间存在隔阂,音频表现往往难以触及用户情感,在这样的背景之下,华为提出了,破局,方案,于11月26日推出...。

发表在极米投影仪2022,7,2117,51据消息称,极米将在国内上新一款吸顶灯,极米吸顶灯投影L1,这款极米神灯之前在海外日本发布过,国内暂时对于吸顶灯投影仪产品少之又少,相信发布后会带来一片惊叹,对于这款极米吸顶灯投影L1虽然是灯,但本质还是一个投影仪,其内部又拥有怎么样的配置呢,极米吸顶灯投影L1参数又如何,我们往下看,极米吸顶...。

发表在专业问答2020,11,1011,30展示机型信息,品牌型号,坚果微果i6系统版本,JMGO4.0按下遥控器的设置键,打开微果投影仪的设置界面;,在设置界面中,通过方向键选中投影设置并点击进入;,选择光源亮度并打开,更改投影亮度模式来更改画面亮度,微果投影仪怎么调亮度1.按下遥控器的设置键,打开微果投影仪的设置界面;2.在设...。

发表在综合交流大区2023,5,920,15CVIA流明是由中国电子视像行业协会协同当贝等知名投影品牌所制定的新亮度标准,那么和传统的ANSI流明对比有什么不同呢,下面就来详细了解一下,看看CVIA流明和ANSI流明有什么区别,CVIA流明和ANSI流明怎么换算,一、CVIA流明和ANSI流明有什么区别,CVIA流明和ANSI流明都是...。

早教是幼儿的启蒙之旅,先进的早教可以激发孩子对学习的兴趣,多方面培养的孩子能力,故早教已成为当下较为先进的产业项目,与早教相关的品牌企业在市场中更是屡见不鲜,这当中以在早教早教中心更为知名,在早教早教中心拥有完善的教育理念体系,它在教学较具以及校区的环境方面亦是进行了专业的设计,在早教早教中心也因此成为早教项目中的一把好手,创业者对此...。

文章开始前,先普及一下o20的定义,O2O即OnlineToOffline,是指将线下的商务机会与互联网结合,让互联网成为线下交易的前台,这个概念最早来源于美国,O2O的概念非常广泛,只要产业链中既可涉及到线上,又可涉及到线下,就可通称为O2O,这是百度百科对o2o比较宏观笼统的解释,要细分种类,可以分成很多种,在这里不展开,很多朋友...。

申明,1.以上内容仅代表揭发者自己,不代表黑猫揭发立场,2.未经授权,本平台案例制止任何转载,违者将被清查法律责任,3.黑猫揭发处置揭发不收取任何费用,凡以黑猫揭发名义不要钱的均为混充、诈骗行为,请及时报警并与黑猫官网反应,揭发邮箱heimaotousu@vip.sina.com,4.请大家选用官网渠道处置生产纠纷,不要轻信第三方机构...。

飞驰E300L是专为中国市场设计的中大型轿车,其外观和空间尺寸都十分适宜小家庭,值得一提的是,新一代飞驰E300L的车身长度和轴距尺寸都有所参与,那么,2021年新款飞驰E300L的报价是多少呢,让咱们一同来看看这辆豪车,2021款E300L时兴版的指点价为46.78万元,而021E300L遥控时兴版的指点价也是46.78万元,021...。

如何在Laravel中使用中间件进行数据缓存缓存是提高网站性能的重要手段之一。Laravel框架提供了丰富的缓存功能,可以使用中间件来实现数据缓存。本文将介绍如何在Laravel中使用中间件进行数据缓存,并给出具体的代码示例。一、使用中间件进行数据缓存的原理1.1缓存的作用和好处在Web开发中,许多请求需要从数据库或其他数据源中获取数据,这会占用大量的网络

2008年,长春一名交警在执行任务时,意外被公交车撞飞五米远,送去医院时,整个人已经陷入昏迷,颅脑内粉碎性骨折,稀缺的熊猫血更让他命悬一线,医生甚至都让家属备好寿衣,已经没有抢救的意义了,就算救回来也是一个永远不会醒来的植物人,就在所有人都要放弃的时候,其母亲跪在地上苦苦哀求,只要有一口气就要救,结果如何她都接受,几场手术后,他的大脑...。
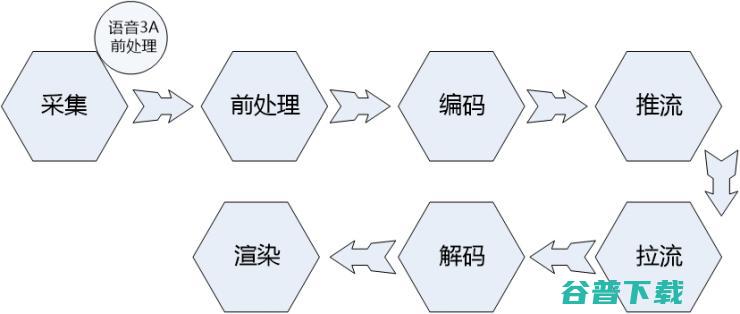
雷锋网按,本文作者冼牛,即构科技市场运营总监,香港大学MBA,十年研发经验,音视频云服务技术专家,专注连麦互动直播技术应用研究,有好多次视频社交行业的开发者提到,某厂商的视频交友SDK测试的时候性能效果还可以,可是接入过程中和接入后就遇到各种各样的坑,因此,视频交友SDK的开发策略也要重点考量,数据流动视频交友SDK选择在数据流动的各...。

很多人都知道和孩子相关的项目比较好做,因此大家在选择创业项目的时候,首先会想到的就是儿童乐园,因为很多人在经营过这个项目之后,都过上了富足的生活,从而也引起了加盟商的关注,机灵小匠之所以能够在众多项目中脱颖而出,是因为它的综合实力比较强大,可以为开店者带来更多的财富,那么,机灵小匠适合多大的孩子,6岁的可以吗,机灵小匠适合多大的孩子,...。

文字链接认证代码普通联盟标志认证代码企业广告联盟标志认证代码广告联盟评测代码说明,本页面的认证代码为美百广告联盟专用评测代码,站长需懂简单html知识,直接复制代码粘贴到联盟网站相应页面即可使用,本代码不适用于其他广告联盟网站请勿获取!文字认证,文字链接代码认证适用所有类型的广告联盟,复制代码后放在美百广告联盟网站首页底部或友情链接位...。

海尔洗衣机门不太好关上,6月8日第一次性上门培修加荡涤,不要钱450元,团体收款,修的今天门好关上了,然而修过之后荡涤的时刻也能关上了,徒弟不专业,不时在电话摇人,家里有小孩,出于安保思考,叫徒弟处置,他说太晚了得换别的硬件,说硬件到了再来,过了几天敦促,6月16日来了修好了,说要150,讨价120,用了2天,零件坏了,报错,他还百度...。
