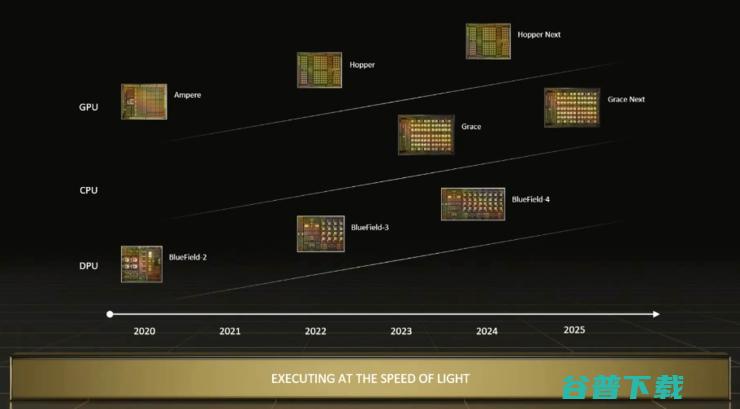
英伟达 策略初步奏效 三芯 (英伟达技术路线)
相比几年前谈论的重点只有GPU,在拥有CPU和DPU之后,英伟达作为系统公司能够谈论的话题更加丰富。
在刚刚过去的Computex和时隔两年重新回归线下的ISC 2022(国际超级计算机大会),英伟达都展示了诸多其GPU、CPU、DPU的最新合作成果,这在很大程度上表明了英伟达的“三芯”策略已经初见成效。
另外,英伟达在混合量子计算中的成果,也体现了其在高性能计算领域的前瞻性布局。
当然, 英伟达CEO黄仁勋也在与媒体的交流中再次强调,“英伟达是一家系统公司,提供从硬件到系统软件的全栈方案,客户可以按照其需求选择我们的产品。加速计算的世界与CPU截然不同,我们的产品和方案非常独特。”
英伟达的“三芯”到底如何加速那些世界上最快的加速系统?
GPU作为英伟达发明的产品,也是英伟达的标签,在今年GTC 22上,介绍了英伟达最新一代Hopper架构GPU H100发布,相比两年前的Ampere架构A100 GPU,实现了数量级的性能提升。
黄仁勋表示,20个 H100 GPU 便可承托相当于全球互联网的流量,使其能够帮助客户推出先进的推荐系统以及实时运行数据推理的大型语言模型。
不过,相比GPU,英伟达的Grace CPU更能吸引外界的关注。市场上已经有很多优秀的CPU产品,英伟达在这样的背景下推出CPU让人感到意外,也让人好奇Grace CPU的不同之处。
当被问及Grace CPU有何独特之处时,黄仁勋说,“Grace旨在比其它CPU更好地解决与数据处理有关的问题,能够更高效处理大量数据,并且与我们的GPU紧密结合,更好地完成解决AI任务。”
英伟达的Grace CPU超级芯片集成了两个基于Arm的CPU,有多达144个高性能Arm Neoverse核心,并且带有可伸缩矢量扩展和1 TB/s的内存子系统,支持最新的PCIe Gen5协议,可实现与GPU之间最高性能连接,同时还能连接NVIDIA ConnectX-7智能网卡以及NVIDIA BlueField-3 DPU。
由此看来,英伟达在设计Grace CPU之处就已经非常明确要将其所有硬件产品之间很好地互联。 这也容易理解,随着摩尔定律的放缓,异构计算成为了未来趋势,作为提供高性能计算产品的公司,英伟达有这样的布局也十分合理。
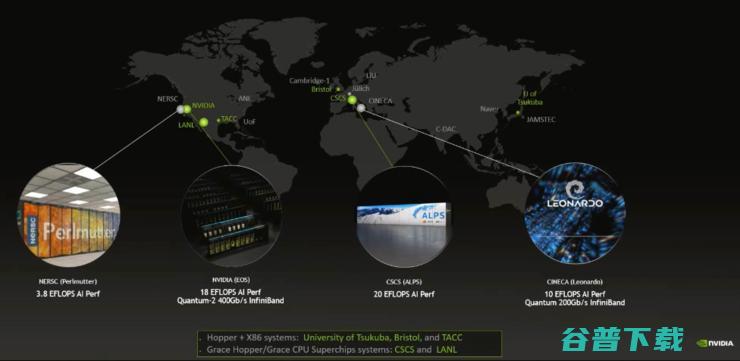
ISC 2022上,英伟达CPU+GPU的产品组合获得了认可,美国和欧洲的领先超级计算中心都将率先采用这两款超级芯片。
美国阿拉莫斯国家实验室 (LANL)今日宣布,其新一代系统Venado将成为美国首个采用NVIDIA Grace CPU技术的系统。 Venado是使用HPE Cray EX超级计算机构建而成的异构系统,将同时配备Grace CPU和Grace Hopper,这一系统建成后的AI性能预计将超过10 exaflops(10的18次方,百亿亿次)。
另一个率先采用英伟达Grace CPU和GPU的系统是瑞士国家计算中心的新系统Alps,基于HPE Cray EX超级计算机构建,这是一个通用系统,向瑞士及其他国家的研究者开放。
英伟达还宣布,源讯、戴尔科技,技嘉科技、慧与、浪潮、联想和超微宣布计划部署基于Grace CPU和Grace Hopper超级芯片的服务器。
DPU是一个新概念,在英伟达带动下成为备受关注的产品,涌现了大量初创公司以及资本的投入
DPU的核心价值是将通信和计算负载从CPU卸载,进而获得巨大的性能提升。不过DPU能够带来的具体的性能提升,仍然需要实践证明,英伟达借着ISC 2022给出了一些案例。
洛斯阿拉莫斯国家实验室(LANL)的杰出高级科学Poole 正与英伟达进行一项为期多年的广泛合作,旨在将计算多物理应用的性能提高30倍。 这其中包括使用 BlueField 及其NVIDIA DOCA软件框架在计算存储、模式匹配等。
LANL 已经感受到网络计算的强大功能,加速闪存盒(ABoF)将固态存储与DPU和InfiniBand加速器相结合,可为 Linux 文件系统的关键性能部分提供加速。它的性能高达同类存储系统的30倍,并将成为 LANL 基础架构中的关键组件。
俄亥俄州立大学的研究人员展示了 DPU 如何将一个HPC热门编程模型的运行速度提高 21%。他们通过卸载消息传递接口(MPI)的关键部分,加速了P3DFFT,这是一个用于众多大规模HPC仿真的数学库。
对于运行药物研发或飞机设计等HPC仿真应用的超级计算机,DPU也能够带来高达两位数的性能加速。
欧洲的多个研究团队正利用BlueField DPU 加速 MPI 和其他 HPC 工作负载。英格兰北部的达勒姆大学正在开发一款软件,用于在 16 个节点的 Dell PowerEdge 集群上使用 BlueField DPU 以实现 MPI 作业的负载均衡。剑桥大学、伦敦和慕尼黑等的研究人员也在使用 DPU。
DPU也在用于加速分子动力学研究,还能用于气候学、天体物理学、大数据、AI 和更多方面的研究。 这些研究人员也在考虑如何使用新一代的BlueField-3 DPU 的核心功能。
三芯策略初步奏效,布局量子计算
高性能计算系统对于算力有着更高要求,也有独特需求,在英伟达拥有了GPU、CPU和DPU之后,它能够实现更多的硬件组合,再配合上层的软件系统,能够更好满足前沿应用和更高计算的需求。
通过ISC 2022的众多成果展示,也能看到英伟达的三芯策略已经初见成效,不同的产品和产品组合已经在HPC、AI等应用中实现性能的显著提升。
不止于此,英伟达还在布局前沿的量子计算。

量子计算有两大优势,一个是可以为海量数据的并行计算(性能)带来指数级别的提升,这种强大的功能,可以运用在包括金融、数据的搜索处理等领域。另一个是量子计算编译在电子原子上,在模拟方面会表现的非常自然,例如新材料的发现,生物医药的药物合成。
不过,量子计算的实现还有很多挑战。 随着量子系统的发展,下一个重大飞跃是朝混合系统迈进:量子计算机和经典计算机协同工作。
因此,摆在面前的一个重要任务就是将传统系统和量子系统桥接到混合量子计算机中。GPU适合与量子计算协同工作,能大幅降低经典计算机和量子计算机之间的通信延迟,解决当今混合量子作业面临的主要瓶颈。
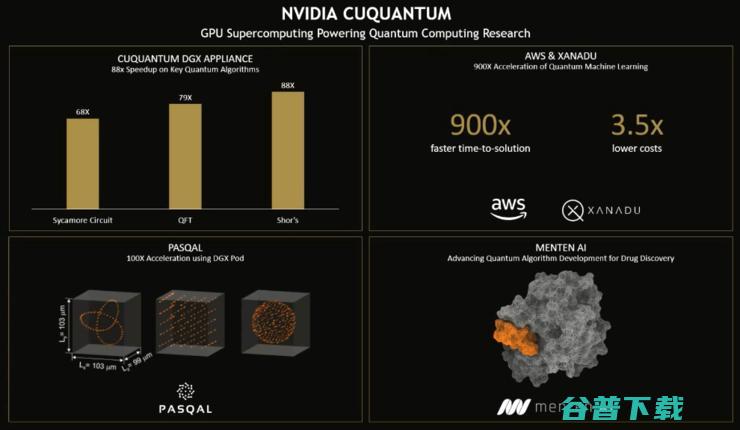
据悉,已经有数十家量子组织已经在使用 NVIDIA cuQuantum 软件开发套件,在GPU上加速其量子电路模拟,能够在主要的量子软件框架上实现加速计算。比如,AWS展示了cuQuantum如何在量子机器学习工作负载上实现高达900倍的加速。
在经典计算的层面,英伟达不断通过丰富硬件产品和软件生态保持争力,面向未来的量子计算,英伟达也做好了准备。
原创文章,未经授权禁止转载。详情见 转载须知 。


西安钢结构集成房屋,西安集装箱租赁,西安活动房厂家,西安集装箱,西安活动房

Tilo天友利是国产标准光源对色灯箱知名品牌厂家,公司20余年专注于标准光源箱,对色灯箱的研发生产,定制,提供符合国际标准的D65,TL84,CWF,F,UV,TL83,A光源等多光源对色灯箱,广泛用于纺织,印染,塑胶,油漆,油墨,印刷,包装,颜料,陶瓷,皮革,五金,食品,化妆品等行业。

古诗文网提供古代经典诗句的全文和赏析,包括春天诗句、夏天诗句、秋天诗句、送别诗句、思乡诗句、思念的诗句、爱情诗句、励志诗句、哲理诗句等经典古诗词名句大全

平民影院免费分享各种影视作品免费在线观看,每日最快更新当下电影电视剧等资源,丰富的影视内容,极快的播放速度,让你爱上第七影院。

上海菱联自动化控制技术有限公司(www.linglianauto.cn)可以为您提供SKTC张力控制器,东电研纠偏控制器,PCB扭矩传感器,美国PCB传感器,MITSUHASHI三桥纠偏控制器的等产品。公司和国内外许多企业建立了业务联系并成为其常年产品供应商和合作伙伴。其良好的价格、信誉和周到快捷的服务、售前售后的技术支持,让您买的顺心用的称心。

天地心网络助力中小企业IT信息化服务,我们坚持不忽悠,不卖弄,不吹嘘,良心做网站,用心做服务,坚持透明的售前沟通,我们只为创业者服务,热线0755-29057711

不锈钢焊管、不锈钢无缝管、不锈钢光亮管、不锈钢厚壁管、不锈钢拉丝管

山东金诚新能源有限公司创建于2018年,是一家集暖通空调、冷库、热水、烘干、新风、净水、净化系统及余热利用系统设计、销售、安装、维修服务为一体综合服务商

新疆天威建达(www.xjtwjd.com)是一家专业从事新疆钢芯铝绞线、新疆电力铁塔、绝缘导线、角钢塔、钢管塔、铁件、电线电缆、钢绞线、电力金具、电力线路器材等输配电力电气材料的研发、制造和销售厂家,产品畅销新疆乌鲁木齐、伊犁、喀什、和田、吐鲁番、阿勒泰、昌吉等地。

北京新享科技有限公司依托低代码技术打造一款专业、易用安全、国产化的项目管理软件-UniPro,应用于缺陷管理、敏捷开发、Bug管理、研发管理等多种场景。更多UniPro、Scrum、Jira、ONES、PingCode、禅道详情请在线咨询。

山东凯文农业科技有限公司,凯文农业,凯文水溶肥,凯文肥料,山东水溶肥,山东冲施肥,山东叶面肥,服务热线:0532-83360782.

金博专注医药行业信息化近二十年,提供医药现代化物流系统、医药批发软件系统、医疗器械管理系统、连锁药店管理系统、医药WMS仓储管理系统、医药电商ERP、药品/医疗器械第三方物流系统、医药电商O2O、OMS订单管理中台、医药TMS运输管理系统、药店系统、会员CRM系统、中医馆系统、门诊诊所管理软件,为医药企业搭建数智化管理平台,让医药行业生态链更智慧。


郭总重新装了个电脑系统,他问我,他说小胖哥,我在网上下载了一个新的系统,现在装系统呢比较方便,我一键安装了,但是安装完之后呢,他老是跳出来说我这个东西不是正版,需要我激活,要不然就是动不动就是整个的系统屏幕就黑了,我说,你这个情况搞个激活码就可以了,他说,哪里有这个激活码,你说激活码,我去官方看了一下,这个激活码还是蛮贵的,我说,你是...。

很多人想要智慧之选一家餐饮店,考虑到同质化竞争问题,很多创业者想要选择一个与众不同的餐饮品牌加盟,美石记石锅拌饭具有浓浓的地域性特色,满满的地方风情,在餐饮行业独树一帜,具有广阔的市场空间,美石记石锅拌饭加盟需要多少钱,这是个投入不是很多的经营项目,大概数万元就能够拥有一个合格的开始,任何行业的发展都是从积累人气开始的,毕竟市场的需求...。
想必大家都对IBM的认知计算平台Watson并不陌生,它利用语义分析、自然语言处理和机器学习造福人类,2011年2月,Watson在智力节目,危险边缘,打败了人类对手,用自然语言实现深度问答,展示了其强大的学习能力,自那个时候开始,它能做的就已经远远超乎参加娱乐节目了,而在五年来的发展中,Watson在人工智能上的布局又是怎样的,回归...。

9月6日,荣耀在2024德国柏林消费电子展,IFA,正式发布旗下首款基于骁龙XElite平台打造的AIPC——荣耀MagicBookArt14骁龙版,荣耀CEO赵明还与高通技术公司手机、计算和XR事业群总经理AlexKatouzian、微软合作伙伴事业部副总裁MarkLinton就AI与骁龙Windows生态的技术融合、AI终端的未来...。

现如今大家都开始追求一个比较有品质的生活,所以家中的装饰也就离不开了家纺产品,目前大多数的人群赚的钱都很高,就会选择不同风格的家纺产品,因此市场上的需求量也就越来越大,当前家纺行业拥有很大的发展空间,前景比较好,从而也就成为了很热门的创业项目,那么开家纺店需要多少钱,下文就给大家详细的介绍一下,目前开一家家纺店铺通常分为两种情况,一种...。

2019年,如果妙健康完成太平洋保险领投的C轮融资,近5亿元人民币,之后,能马上赴美上市,也许结局会不一样,近日,有业内人士向表示,2021年妙健康在美股上市失败后,引发了一轮内部危机,2021年9月陆续裁员,到了12月,开始加大裁员力度,员工从最高的650人左右回落到如今的250人,进入今年4月,新一轮裁员又开始,大部分被...。

2011年2月21日晚上9时许,注定是全州县二中一个伤痛蒙羞的时刻,该校高二,十,班原班长蒋添辉,为劝解本班两女生在班里编排座位时产生的争执,两女生为争与一男生同坐,,跟被其中一女生叫来助威的本校高三男生张某产生争端,在下晚自习后,被张某叫来几个男青年围攻追杀,惨死于离学校不到100米的街头上,一个学习成绩优秀年轻的生命,白白葬送在他...。

在恋情方面属羊的人易受曲折,感情较软弱,羊女心肠残酷,害怕,青睐关照他人;羊男自尊心很强,是一个不会坦率表白自己情义的人,跟配偶不会唠叨或吵架,是一个注重家庭的丈夫,是一位心疼子女的好父亲,属羊的属相男女匹配表,1.属羊人的最佳婚姻对象羊女,与属兔、属蛇、属猴、属马的男子结婚最佳,羊男,与属马、属猪、属猴、属鼠的女性结婚最佳,2.属羊...。

我11,是由王小帅导演,闫妮、乔任梁、于越主演的电影,讲述的是原本牵肠挂肚的11岁小男孩,在亲眼目击了一同,杀人事情,后不得不背负上心灵的煎熬,加上朦胧中获知了成人间界里的性事,让他身心开局出现了闹哄哄的变动,体内疯长的荷尔蒙和外界的压制环境不时出现着碰撞和迸发的故事,影片于2012年5月18日在中国上映,2011年电影宿愿可以帮到...。

置换车辆流程如下,1、车主将老旧机动车转出本市或送到具备正轨资质的解体厂启动报废,2、车主到网上或操持网点填写并提交老旧机动车淘汰政府贴补、企业鼓励资金放开,3、车主提交放开后,买卖操持平台会对车主消息启动查看,4、买卖平台在车辆档案实现转出或注销后启动查看,并向车主公示查看结果,5、查看经事先,车主可经过平台消息系统打印或到操持网点...。

哥布林弹球修改器是该同名游戏的一款修改工具,具有无限生命、无限金钱、秒杀等修改功能,使用后可以帮助玩家快速升级游戏任务。

重庆分类目录网站收录寻医问药相关的优秀网站大全分类检索,为上网用户提供寻医问药网站排行榜与您分享、收藏!
很多新媒体小编每天忙得要死,但仔细想想却觉得没有拿得出手的东西,作为公众号负责人,是不是还经常有这样的感觉,·左手微信公众号,右手抖音,做的事情越来越多,但没有一样是主心骨,·天天看别人10w,,自己的号一年也没攒出一篇1w,·订阅号更,订阅号更完服务号更,服务号更完抖音更,一天都在更更更……公众号诞生已经7周年了,微博已经10年了,...。

知乎上关于百度竞价,有个点击量很高的问题,标题是,做医疗竞价2年了,也混了个小主管,感觉就是伤心、伤神、伤身,医疗过于依赖竞价...请问其他行业也这样么?,下面的点赞和评论很多,这也反映了很多人从事百度竞价几年之后的迷茫,百度竞价从什么时候开始难做的?每个竞价投放人员都有自己的理解,我个人是15年末了解百度竞价的,16年有尝试,17年...。

家具是新房装修中必不可少的物件,不同的装修风格选择的家具,在生活水平提高以后,对家具的需求是越来越大,市面上涌现各种家具品牌,其中掌上明珠家具是一家现代化家居企业,产品种类丰富,在市场上发展越来越好,运营门店分布在全国多个城市,帮助很多创业者实现了致富梦想,那么掌上明珠家具有多少运营商,发展怎么样,掌上明珠家具从品牌创建以来,作为全屋...。

湖南卫视热播的电视剧,武媚娘传奇,在宣布暂停播出快一周后,于2015年元旦起恢复播出,复播的,武媚娘传奇,妃子,脖子以下镜头全部被剪,...。

9月11日,在2024中国500强企业高峰论坛上,中国企业联结会、中国企业家协会延续第23次向社会发布了,中国企业500强,榜单,营收规模迈上新台阶2024中国企业500强营业支出迈上新台阶,打破了110万亿元大关,达110.07万亿元,较上年相比增长1.58%,入围门槛22连升2024中国企业500强入围门槛到达473.81亿元,优...。
