回顾Google神经网络机器翻译上线历程 (回顾工作历程经典句子)
雷锋网按:本文作者陈村,剑桥大学自然语言处理(NLP)组, 现为机器学习语义分析工程师。
Google Translate作为久负盛名的机器翻译产品,推出10年以来,支持103种语言,一直作为业界的标杆。
而在前不久,Google官方对翻译进行一次脱胎换骨的升级——将全产品线的翻译算法换成了基于神经网络的机器翻译系统(Nueural Machine Translation, )。从Google官方发表的博文[1]和技术报告[2]中,我们有机会一窥究竟,这个全新的系统到底有什么神奇的地方?笔者借这篇文章,帮大家梳理一下机器翻译的发展历程,以及Google这次新系统的一些亮点。
机器翻译,即把某一种源语言(比如英文)翻译到最恰当的目标语言(比如中文)。
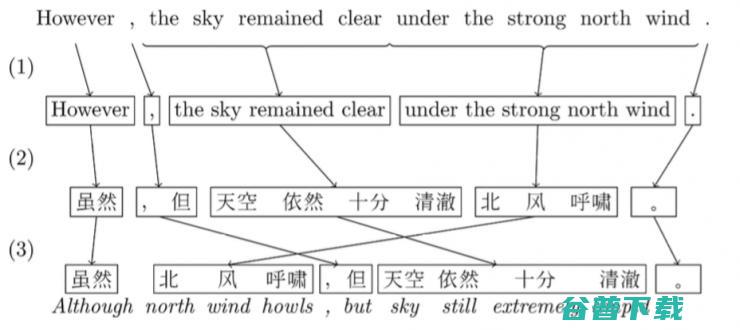
还在几年前,机器翻译界的主流方法都是Phrased-Based Machine Translation (PBMT),Google翻译使用的也是基于这个框架的算法。所谓Phrased-based,即翻译的最小单位由任意连续的词(Word)组合成为的词组(Phrase),比如下图中的“北风呼啸”。
PBMT是怎么把一句英文翻译成中文的呢?
Statistical machine translation. ACM Computing Surveys, 40(3), 1–49.
传统的PBMT的方法,一直被称为NLP(Natural Language Processing,自然语言处理)领域的终极任务之一。 因为整个翻译过程中,需要依次调用其他各种更底层的NLP算法,比如中文分词、词性标注、句法结构等等,最终才能生成正确的翻译。 这样像流水线一样的翻译方法,一环套一环,中间任意一个环节有了错误,这样的错误会一直传播下去(error propagation),导致最终的结果出错。
因此,即使单个系统准确率可以高达95%,但是整个翻译流程走下来,最终累积的错误可能就不可接受了。
深度学习这几年火了之后,机器翻译一直是深度学习在NLP领域里成果最为卓越的方向之一。 深度神经网络提倡的是end-to-end learning ,即跳过中间各种子NLP步骤,用深层的网络结构去直接学习拟合源语言到目标语言的概率。
2014年,Cho et. al [3]和Sutskever et al. [4] 提出了Encoder-Decoder架构的神经网络机器翻译系统。如下图所示:
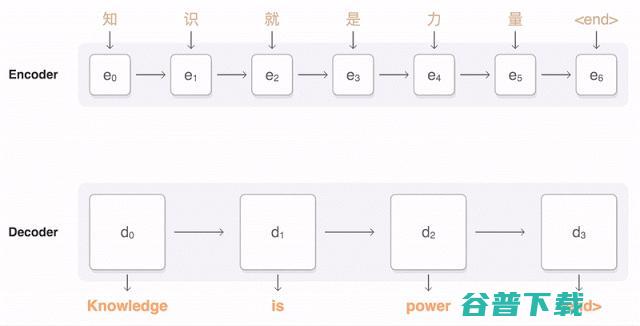
NMT这样的过程直接学习源语言到目标语言,省去了训练一大堆复杂NLP子系统的依赖,依靠大量的训练数据(平行语聊库,比如同一本书的中文和英文版本),直接让深度神经网络去学习拟合。熟悉深度学习的朋友可能会意识到,这样的方法一个极大的优势就是 省去了很多人工特征选择和调参的步骤 。听说前两年,有个做神经网络图像处理的教授,在不太了解NLP的基础上,硬生生地搭建了一套可以匹敌传统PBMT的机器翻译系统,后者可是十几年来多少奋战在第一线的NLP同志一砖一瓦垒起来的啊。而且,相比于传统PBMT一个词组一个词组的独立翻译,NMT这样end-to-end翻译出来的语言更加自然流畅。
2015年,Yoshua Bengio团队进一步,加入了Attention的概念。稍微区别于上面描述的Encoder-Decoder方法,基于Attention的Decoder逻辑在从隐层h中读取信息输出的时候,会根据现在正在翻译的是哪个词,自动调整对隐层的读入权重。即翻译每个词的时候,会更加有侧重点,这样也模拟了传统翻译中词组对词组的对应翻译的过程。Attention模块其实也就是一个小型神经网络,嵌入在Encoder-decoder之间的,跟着整个神经网络训练的时候一起优化训练出来的。
Bengio团队的这个工作也奠定了后序很多NMT商业系统的基础,也包括Google这次发布的GNMT。
Google这次在算法上、尤其是工程上对学术界的NMT方法提出了多项改进,才促成了这次Google NMT系统的上线。
学术上的NMT虽然取得了丰硕的成果,但在实际的产品中NMT的效果却比不上PBMT。究其原因Google在技术报告[2]中总结了三点:
1、训练和预测的速度太慢。
要获得更好的模拟效果,就要用更深层的神经网络来拟合参数(下面会提到,GNMT用了8层的Stack LSTM来做Encoder)。这么复杂的神经网络在预测的时候就要耗费大量的资源,远远慢于PBMT的系统。并且在训练的时候拟合这么大规模的预料,可能要很久很久才能训练一次,这样不利于快速迭代改进调整模型参数。
2、NMT在处理不常见的词语的时候比较薄弱。
比如一些数字、或者专有名词。在传统PBMT系统中,可以简单地把这些词原封不动的copy到翻译句子中;但是在NMT中,这样的操作就无法有效的进行。
3、有时候NMT无法对输入源句子的所有部分进行翻译,这样会造成很奇怪的结果。
Google NMT的主要神经网络架构图如下:
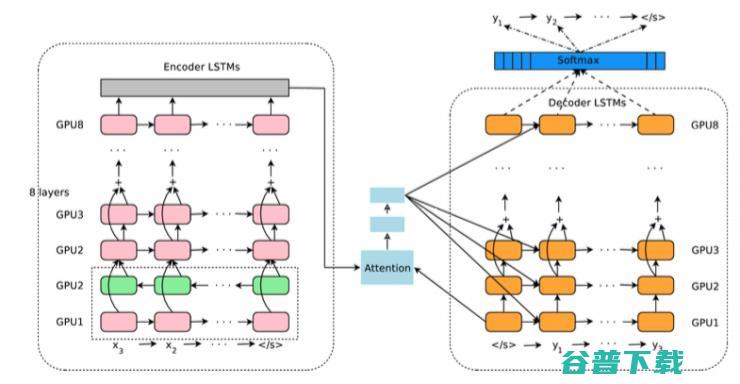
仔细看,其实还是带Attenion的Encoder-Decoder逻辑。Encoder是由8层LSTM组成,最下面两层是一个 双向LSTM ,可以从前到后以及从后往前理解一遍输入的源语言输入。中间的蓝色模块就是 Attention模块 ,负责对Encoder的逻辑进行加权平均输出到Decoder层。 Decoder模块 也是一个8层的LSTM,最终连接到Softmax层,一个词一个词输出最终的目标语言词语的概率分布。
算法上,论文中还提到了一些创新点。包括引入Wordpiece来对单词进行更细粒度的建模,来解决上面提到的不常见词语的问题;以及在Decoding结束之后,搜索最佳输出序列的时候,引入coverage penalty的概念,来鼓励Decoder输出更加完整的翻译句子,以解决有时候NMT有时候无法完整的翻译整句的情况。
工程上,报告里面着重谈到了几个 性能优化 的重点:
8层的LSTM堆叠起来,大大增加了神经网络的表达能力,在海量的数据下可以获得更好的模型效果。不过这样的堆叠会直接导致模型太庞大不可训练,在梯度反向传播的时候,很容易出现梯度弥散或梯度爆炸的问题。过去的研究证明[5],Residual Connection的方式,直接去学习残差可能会带来更好的效果,避免了深度网络中反向传播中出现的梯度反向传播可能会发生的问题。在上面的Google NMT架构图中,从倒数第三层开始都会引入Residual Connection。
与此同时,在工程上Google也进行了非常多的优化,来减少训练和实时翻译时候的延迟问题。比如训练数据的时候,数据会分成n等份,交给不同的GPU去异步训练,然后再汇总到统一的参数服务器;同时,Encoder和Decoder的不同层的LSTM会在不同的GPU上运行,因为更上一层的LSTM不必等到下一层的神经网络完全计算完毕再开始工作;即使对于最后的Softmax输出层,如果最后输出词的维度太大,也会划分到不同的GPU上并行处理。可谓不放过丝毫并行的机会。
底层基础计算平台的支持。 Google NMT采用了自家的Tensorflow深度学习框架,并运行在Google专门为深度学习打造的TPU(Tensor Processing Unit)上,当年的AlphaGo也是由TPU提供支持。在对于模型参数的计算上,也大量应用了Quantized计算的技术:
从软件框架到定制硬件,相互配合,追求最极致的性能。在这篇报告里,有着长长的作者列表,最后赫然列着Google工程架构大神Jeffrey Dean的名字,他是当年一手创造了Map Reduce、Big Table等产品的Google奠基者之一。
Google这次的论文,基本框架仍然是带Attention模块的Encoder-Decoder。而且国内厂商,比如百度和搜狗,也发布了类似的神经网络机器翻译系统。百度早在去年,就发布“工业界第一款NMT系统”。不过,Google毕竟是机器翻译界的标杆,这次披露的论文也揭示了很多他们为了大规模商业化做出的努力,因此在业界引起了不小的震动。
注: [1] A Neural Network for Machine Translation, at Production Scale
[2]Wu, Y., Schuster, M., Chen, Z., Le, Q. V., Norouzi, M., Macherey, W., et al. (2016, September 26). Google's Neural Machine Translation System: Bridging the Gap between Human and Machine Translation.
[3]Cho, K., van Merrienboer, B., Gulcehre, C., Bougares, F., Schwenk, H., and Bengio, Y. (2014a). Learning phrase representations using RNN encoder-decoder for statistical machine translation. In Proceedings of the Empiricial Methods in Natural Language Processing (EMNLP 2014).
[4]Sutskever, I., Vinyals, O., and Le, Q. (2014). Sequence to sequence learning with neural networks. In Advances in Neural Information Processing Systems (NIPS 2014).
[5]He, K., Zhang, X., Ren, S., & Sun, J. (1512). Deep residual learning for image recognition. arXiv preprint (2015).
原创文章,未经授权禁止转载。详情见 转载须知 。



数夫移动运用管理平台具有高扩充性、高集成性、高兼容性特点,通过云端对移动设备的各种应用属性进行自主管控。涵盖移动应用开发、管理、安全、整合等。

江苏爱迪奥智能装备科技有限公司

春秋依托上海春秋航空提供飞机票、国际机票、特价机票查询预订、打折机票查询预订定、预定购买国内国际便宜机票、低价机票、廉价机票、电子机票、航班查询、飞机票查询预订等服务,并提供机票团购及机票秒杀等众多飞机票优惠活动。99元,199元国内最低价机票网,为您提供低价飞机票,安全,温馨,优质的服务,24小时免费咨询热线95524。

广西紫豹木业是一家生产建筑模板厂家,专注建筑模板,覆膜板,清水模板,建筑红板,酚醛面建筑模板,铁红面建筑模板的生产批发,公司引进国际的制胶技术和先进的生产工艺,经过二次成型,板面光滑,胶合力好,远销国内外受到客户的一致好评。

冷藏车价格厂家直销,主营小型冷藏车,药品冷藏车,小型冷藏车价格,4米2冷藏车报价,冷链车,小型冷藏车价格等,欢迎来厂考察。

国创盛世(杭州)文旅发展有限公司

无锡金阳活塞环厂自1998年工厂成立至今,已有十九个年头。现已有完整的活塞环体系。多年来我们以高的质量,优惠的价格,完善的售后服务,获得了国内外的一致好评。电话:0510-83759518

网站建设,网站开发,网站制作,北京网站建设,京华云采对接,央采入驻,齐鲁云采,天津政采,北京网站制作,北京网站开发,北京建站公司,网站搭建,政府采购平台对接,网站设计,网站定制,建站公司,建网站,做网站,网站维护,南北互联

呼噜博士致力打造“最有智慧”的儿童教育平台。提供基于IOS、Android、Win8、IPTV、电信运营商、早教机等多平台的儿童早教应用、在线直播视听应用、图书出版以及增值业务等。

爱聘才-国内专业外贸人才网,为外贸企业及个人提供外贸招聘、外贸人才求职、外贸人才测评、外贸职场资讯等服务,是企业招聘和个人求职的快捷通道。

汇聚教育装备集团旗下聚宝教学设备有限公司始创于1998年,是一家专注于教育信息化装备、智慧教学设备、智慧教学仪器、智能教学家具研发、制造、销售、服务于一体的高新技术企业。

新疆彩钢厂乌鲁木齐望腾彩板钢构有限公司联系人:李经理联系电话:1809968985218099689851主要产品有新疆彩钢板,彩钢瓦,彩钢夹芯板,岩棉夹芯板,聚氨酯夹芯板,玻璃丝棉夹芯板,组合楼板等.新疆彩钢板厂竭诚为您提供优质的服务!经多年的不懈努力,公司有很大的发展,已跻身于新疆彩钢行业前列.


米线筋道爽滑、不同口味的米线小吃更是满足者食客的选择需求,米线与各种食材的搭配,为顾客带来的丰富的味觉体验,同样米线小吃更是成为当下非常火热的智慧之选项目,米线的智慧之选少,经营高、低低难度的创业优势为不少创业者带来了收银,实现了创业梦想,如今不少创业者选择张一碗米线品牌,那么关于开张一碗米线加盟店收银如何,具体可以看如下的分析,张一...。

除了BAT外,乐视是国内人工智能领域布局范围较广的企业,其实也不难理解,乐视自身拥有两大先天优势,乐视生态下的产品可产生大量用户行为数据,为人工智能的发展打好了基础,此外,乐视的硬件终端设备也可为人工智能的落地提供更大的发挥空间,目前乐视还处于人工智能初级阶段,主要发力于语音识别、计算机视觉、VR,AR、无人驾驶等方向,去年是乐视的生...。

市面上各种品牌的服装专卖店比比皆是,服装专卖店是指服装生产企业商自开的服装商店,主要销售自有服装品牌的服装,除了活动本身影响着促销效果之外,还与品牌知名影响度、产品是否对路、销售人员服务等有直接关系,我们切忌,眉毛胡子一把抓,后执行到位才是整个促销活动好的坚实重要确保,服装专卖店加盟项目为什么被那么多人所青睐,原因在于,中国服装市场...。

我从中国移动转网中国电信到现在已有三年零三个月了,使用体验非常好,原先在中国移动的卡,每个月都要接到非10086官方客服打来的外包座机骚扰电话至少十几次,并且变相扣费,各种欺诈行径,以前使用中国移动的卡,在接到数次外包座机骚扰电话,变相要求用户更改套餐并数次投诉之后,10086客服给我打来电话,可笑的是,那个客服告诉我,需要下载拦截软...。

怎么样把一件事情做成功呢?传统的方法可能会告诉你,你首先要有一个目标,目标要明确,可量化,要遵循SMART原则,然后再把目标拆成一个个小目标,先实现一个小目标,再实现一个小目标,就这样拾级往上……比如,我想读书,那么,先设立一个目标,一年读50本书,再对它进行拆解,大约就是每周读一本书,接下来,就是每周努力去完成这个目标,就可以了,这...。

寡妇制作者,保时捷CarreraGT耗资百万换新,寡妇制作者,——保时捷930Turbo,把那些驾驶技术尚未娴熟的司机带入了驾驶的天堂!911Turbo的速度令人瞠目,而它的电子系统能够有效地纠正驾驶失误,随着中置发起机的CarreraGT的降生,它很快成为了妇孺皆知的顶级跑车,只管它的底盘调校倾向温馨,使它成为了日常代步的工具之一...。

您要问的是板桥中学和栖霞中学哪个好,栖霞中学好,依据查问中学消息网显示,1、占低空积大,设备完全,栖霞中学占低空积平方米,校园修建规划正当、设备完全,而板桥中学学校占低空积为平方米,2、星级高,教学品质高,栖霞中学是附属于南京市栖霞区教育局的一所全日制个别初级中学,江苏省四星级个别初级中学,而板桥中学于2005年被评为江苏省二星级高中...。

你知道ufo是什么意思吗?在咱们的日常生存中,经常会听到这样的词,详细是什么含意呢,上方就和康网小编一同来了解一下ufo是什么意思吧,ufo是什么意思,不明飞行物,体,或称未确认飞行物,体,Unidentifiedflyingobject,缩写,UFO,,是指不明来历、不明性质,沉没及飞行在天空的物体,意指是只需在目击者眼中看不清或...。

对于长城M2二手车的报价,普通在3到5万左右,二手车的收买估价方法是依照10年为限,虽然如今汽车的经常使用寿命和国度规则的期间曾经超越了这个年限,在二手车的收买潜规则中,前三年每年递减裸车多少钱的15%,两边四年每年递减10%,后三年每年递减5%,车况和爱护切当会加分,而爱护失调、隐患缺点、意内挫伤等则会减分,要求留意的是,自行装置、...。

外地期间2日,国度主席习近平达到阿斯塔纳,缺席上海协作组织成员国元首理事会第二十四次会议并对哈萨克斯坦启动国事访问,...。

Java萝卜影视4.0.5源码【完美修复完整版】源码资源仅供学习研究美工使用,请勿用于商业和非法用途!源码说明1、修复支持https打包功能2、修复使用中长时间切换出去再进入不会卡死3、播放器客户端修复,与PC使用一个解...

隶书体字体合集,隶书体字体合集打包下载,隶书体字体是什么?隶书又名佐书、分书、八分,盛行于汉代,所以又叫汉隶。用隶书体书写的文章非常秀气,具有古典风范,一般在书籍封面上都能见到隶书体,PS用户不容错过,您可以免费下载。
从2年前开始做权重站到现在,起码也做了大几百个权重站,出手了大几百个权重站,仅以此篇文章对权重站进行总结、希望可以帮助正在做权重站的兄弟,1、权重站难度无论是自己做项目、还是说通过做权重站出手变现、亦或是说做流量站,随着时间的推移,做权重站难度随着时间的变化,难度系数是不断上涨的,难度上涨几年前、通过新域名,采集,再搞点外链,就能轻松...。

在法律的严密审视下,陕西历史上的一段黑暗时期被重新揭开,最高法的决定再次将王书金案发回重审,这个上诉背后的动机,或许是为了质疑未被计入犯罪记录的女性受害者,这背后,是最高法对公正判决的深刻考量,他们对每个细节的谨慎态度,无不透露出对社会正义的坚守,1993年的西安,两起震惊女性失踪案——刘瑞萍与张辉莉的悲剧,犯罪手法残忍,让整个城市陷...。

发表在当贝投影仪2022,10,2420,01当贝投影是坑吗,答案是否定的,当贝投影并不坑,当贝投影自上市发布一来,一直推出高配投影设备,在当贝激光投影X3发布以来,当贝投影更是成为了国内行业第二,那这么一款受到大众认可的投影仪怎么可能会坑呢,那么由此也可以知道,当贝投影质量肯定不会有问题的,为什么有人会说当贝投影坑呢,其中从当贝投影...。

动漫、二次元、手办……一系列词汇,不知何时开始就成了席卷现代年轻人的新的、独特文化,由此衍生出来的以动漫城、动漫实体店为代表的动漫产业,也成为行业重要产业之一,对创业者而言,关注的往往是行业动态,比如说开动漫城要多少钱,开个动漫实体店好吗,关于这类问题的答案,我们来细细叙说,有关动漫城的定义动漫,即动画、漫画的合称,指动画与漫画的集合...。
1、首先在手机上装置手机版的迅雷,依据手机装置相应的版本的迅雷安卓或苹果手机迅雷怎样下载电影quotdatasrc=quotimgsogoucdnv2thumb,appid=url=%3A%2F%2%2Fexp%2Fw%3D500%2Fsign%3D3ef,2、1从新新建下载义务2把文件名改掉,比如改成,下载文件,,,视频,等等,只需...。
