中国科学技术大学副教授凌震华 基于表征解耦的非平行语料话者转换 (中国科学技术大学)
雷锋网按:2020 年 8 月 7 日至 9 日,全球人工智能和机器人峰会(CCF-GAIR 2020)在深圳圆满举行。CCF-GAIR 2020 峰会由中国计算机学会(CCF)主办,雷锋网、香港中文大学(深圳)联合承办,鹏城实验室、深圳市人工智能与机器人研究院协办。
从 2016 年的学产结合,2017 年的产业落地,2018 年的垂直细分,2019 年的人工智能 40 周年,峰会一直致力于打造国内人工智能和机器人领域规模最大、规格最高、跨界最广的学术、工业和投资平台。
8 月 8 日,在由深圳市人工智能学会、CCF 语音对话与听觉专业组协办的「前沿语音技术」专场上,中国科学技术大学电子工程与信息科学系副教授凌震华做了题为《基于表征解耦的非平行语料话者转换》的主题演讲。

凌震华副教授
凌震华副教授主要研究领域包括语音信号处理和自然语言处理。主持与参与多项国家自然科学基金、国家重点研发计划、安徽省语音专项等科研项目,已发表论文 100 余篇,论文累计被引 4000 余次,获国家科技进步奖二等奖和 Ieee 信号处理学会最佳青年作者论文奖。在 Blizzard Challenge 国际语音合成技术评测、Voice Conversion Challenge 国际语音转换技术评测等活动中多次获得测试指标第一名。
凌震华副教授现为电气电子工程师学会(IEEE)高级会员、中国计算机学会语音听觉与对话专业组委员、中国语言学会语音学分会学术委员会委员、全国人机语音通讯学术会议常设机构委员会委员。2014-2018 年曾任 IEEE/ACM TASLP 期刊副编辑。
在演讲中,凌震华副教授主要从语音转换所基于的语料类型出发,介绍了平行语料下实现语音转换的技术演变过程,并由此延伸到非平行语料下的语音转换。
其中在平行语料条件下,传统语音转换基于 GMM (高斯混合模型)实现。 2013 年后深度学习技术被引入语音转换任务,基于产生式训练的深度神经网络(Generative Trained Deep Neural Network, GTDNN)等模型相继被提出。不过无论是 GMM 还是 DNN,都面临源与目标语音帧对齐过程中出现的误差和不合理问题。近年来提出的序列到序列(seq2seq)语音转换方法可以有效改善这一问题,提升转换语音的自然度与相似度。
进一步,凌震华副教授谈到了在非平行语料条件下的语音转换,并表示这种场景普遍存在于实际应用中,也更有难度。基于非平行数据构造平行数据,以及分离语音中的文本与话者表征,是实现非平行语音转换的两条主要技术途径。
随后,凌震华副教授重点介绍了所提出的基于特征解耦的序列到序列语音转换方法,该方法在序列到序列建模框架下实现语音中文本相关内容和话者相关内容的分离,取得了优于传统逐帧处理方法的非平行语音转换质量,接近使用同等规模平行数据的序列到序列语音转换效果。
最后,凌震华副教授表示:
以下是凌震华副教授在 CCF-GAIR 2020「前沿语音技术」专场中的演讲内容全文,雷锋网对其进行了不改变原意的编辑整理:
谢谢大家,今天我的报告题目是《基于表征解耦的非平行语料话者转换》。
之前各位老师已经介绍了语音技术领域的若干研究任务,如声纹识别、语音分离与增强等。话者转换是一种语音生成的任务,同时这个任务也和说话人的身份信息相关——之前介绍的声纹识别是从语音中识别身份,而话者转换是对语音中身份信息的控制和调整。

我的报告会围绕三个部分进行:
话者转换,又称语音转换,英文名为 Voice Conversion,指的是对源说话人的语音进行处理,使它听起来接近目标发音人,同时保持语音内容不变。

类比于计算机视觉领域的人脸替换工作,如 Deepfake 等,话者转换是对语音信号中的说话人身份信息进行处理,其应用领域包括娱乐化应用和个性化的语音合成等。同时,身份的匿名化、一致化也会使用到话者转换技术。
话者转换技术经过了从规则方法到统计建模的发展历程。现阶段的基于统计建模的话者转换方法,其转换过程通常包括三个主要步骤:

今天我们介绍的内容主要围绕中间的统计声学模型展开。在对于话者转换任务的背景介绍后,下面着重介绍平行语料和非平行语料条件话者转换任务的区别、主要方法,以及我们做过的一些相关工作。
那么什么是平行语料?
在训练阶段,如果源和目标两个说话人朗读过同样的文本,就可以得到他们之间的平行语料。基于平行语料,可以直接建立转换模型描述两个说话人声学特征之间的映射关系。在转换阶段,输入新的源说话人声音,就可以通过转换模型进行目标说话人声学特征的预测。

在深度学习出现之前,在平行语料语音转换中,最经典的方法是基于高斯混合模型(GMM)的方法。
其基本的策略是,两个说话人录制了平行语料后,考虑到两个人的语速、停顿等不一致带来的声学特征序列长度差异,需要先利用动态时间规整(DTW)算法进行序列的对齐,得到等长的 X 序列和 Y 序列。接着,将每个时刻的源说话人声学特征与目标说话人声学特征进行拼接,进一步训练得到两个发音人声学特征的联合概率模型P(X,Y)。

进一步,我们由 P(X,Y) 可以推导出 P(Y|X)。在转换的时候我们就可以把源说话人的声学特征X 送到模型中,将目标发音人声学特征Y预测出来。使用的预测准则包括最小均方误差(MMSE)和最大似然估计(MLE)等。
不过,基于 GMM声学建模的语音转换质量还是不尽如人意。一方面转换的音质不够高,声音听起来有机械感;二是和目标人的相似度不够好。这些都和声学模型的精度不足有关系。
针对以上问题,自2013年开始,深度学习被广泛应用与语音转换的各个技术环节,如特征表示、声学建模、声码器等。今天重点关注的是声学模型,即如何更好的建模P(Y|X)。

现在来介绍我们早期所研究的一种基于深度神经网络(DNN)的语音转换方法,该方法使用的是逐帧转换的DNN声学模型。由于将DNN模型直接用于源说话人声学特征到目标说话人声学特征的映射,并基于传统MMSE准则进行模型参数更新,所取得的性能提升有限。因此,我们设计了一种产生式训练方法,用于训练语音转换DNN 模型参数。其思路是,先训练两个受限玻尔兹曼机(RBM)模型,将 X 和Y分别映射到相对紧凑、高效的二值表征;然后再建立一个双向联想记忆(BAM)模型,描述两个发音人二值表征间的联合概率;最后组合RBM和BAM,形成 DNN 模型,该模型参数不再需要基于MMSE准则的参数更新。实验结果表明,该模型对比 GMM在主观质量上具有明显优势。

不管是前面说到的 GMM 模型还是 DNN 模型,描述的都是帧到帧的映射关系,在模型训练阶段都离不开帧对齐步骤。对齐的过程难免产生一些对齐的误差与不合理的地方,这会影响语音转换的效果。
另外,这样的帧到帧映射模型不能转换时长。而实际情况是有的人说话比较快,有的人说话比较慢,怎么把说话人的语速特点体现出来呢?

后来,我们受到序列到序列神经网络在机器翻译、语音识别、语音合成等领域的应用启发,将序列到序列建模引入话者转换,以改善以上问题。我们的策略是利用结合注意力机制的编码器-解码器模型,直接建立输入源说话人声学特征序列与目标发音人声学特征序列之间的转换关系,中间不需要对齐操作,可以实现对于时长的控制和调整。将序列到序列建模用于话者转换任务,面临序列长度较长、数据量有限等困难。因此我们在模型结构设计上也做了一些针对性的考虑。
这是我们设计的模型结构。模型输入除了从源说话人语音中提取的声学特征序列外,还拼接了利用语音识别声学模型提取的文本相关特征,以协助序列对齐。模型输出就是从目标说话人平行语句中提取的声学特征序列。其中输出与输入序列长度并不一致。

模型采用结合注意力机制的编码器-解码器结构。为了降低序列长度过长对于建模的影响,我们在编码器中使用了金字塔结构的递归神经网络,以保证对齐效果。
以下是实验结果。图中横坐标是真实目标说话人语音的时长,纵坐标是转换后的语音时长。如果语音转换模型有比较好的时长调整效果,那么数据点应该落在对角线上。图中绿色点所示的是传统逐帧转换方法的结果,从中可以看出源与目标发音人之间显著的语速差异。红色点对应的是所提出的序列到序列语音转换方法,可以看出其取得了良好的时长转换效果。

进一步,我们来探讨非平行语料条件下的语音转换。这是一个更有挑战性的任务。由于很多时候我们需要使用已有数据构建话者转换系统,因此非平行数据条件在实际应用中普遍存在。
已有的非平行语料语音转换大体上有两个思路:

以Voice Conversion Challenge 2018 (VCC2018) 国际话者转换评测为例。其包括两个任务,主任务是平行数据条件,辅任务是非平行数据条件。我们针对此次评测,设计实现了基于PPG的语音转换方法。该方法利用语音识别模型从源话者语音中提取瓶颈特征作为话者无关的文本内容表征,同时利用目标说话人数据建立文本内容表征到声学特征的映射模型。由于该映射模型针对每个目标说话人分别建立,因此不需要平行语料就可以实现。


在VCC2018评测结果中,我们提交的参测系统在两个任务上均取得了转换语音自然度与相似度指标的第一名,其中自然度平均意见分(MOS)达到 4 分,相似度达到 80% 以上。
最后我再介绍一下我们近期开展的基于序列到序列模型框架的非平行语音转换方法的研究工作。虽然前面介绍的VCC2018方法可以取得较好的非平行语音转换效果,但是其仍存在一些不足。例如,基于语音识别器提取的文本内容表征中难以保证不含有说话人相关信息、语音识别模型和转换生成模型没有联合训练、仍采用帧到帧映射的模型框架等。
因此,我们提出了一种基于表征解耦的序列到序列非平行语音转换方法。该方法在序列到序列建模框架下,可以实现对于语音中文本相关内容和话者相关内容的有效分离。其核心思想如图所示。在训练阶段,利用识别编码器和话者编码器分别提取语音中的文本和话者相关表征。同时我们通过训练准则的设计保证这两种表征相互独立,不会纠缠。在训练过程中,我们也会利用语音对应的转写文本。从转写文本中提取的信息可以为从语音中提取文本表征提供有效参考。在合成阶段,通过组合从源说话人语音中提取的文本表征,以及目标说话人的话者表征,可以实现从源说话人语音到目标说话人语音的转换。

整个的模型结构如下图所示,由文本编码器、识别编码器、话者编码器、辅助分类器、解码器共5个主要模块构成。其中识别编码器和解码器类似与语音识别与语音合成模型,均采用结合注意力机制的编码器-解码器结构。文本编码器用于从转写文本中提取文本表征。解码器可以接收来自识别编码器或者文本编码器的输出,结合话者编码器给出的话者表征,进行声学特征的重构。辅助分类器用于实现与识别编码器的对抗学习,以保证识别编码器提取的文本表征中不含有说话人相关信息。由于时间原因,各模块具体的模型结构不再一一展开介绍。

以上各模块在训练阶段联合优化。为了实现有效的表征解耦,我们共设计了7种损失函数用于指导模型参数更新,包括音素分类损失、话者表征损失、对比损失、对抗训练损失、重构损失等。

以下是一些实验结果。从客观评测结果中可以看出,对比CycleGAN和VCC2018两种非平行语音转换方法,我们提出的方法可以取得最优的梅尔倒谱失真(MCD)以及清浊判决错误(VUV)。在转换时长误差(DDUR)上,所提方法由于采用了序列到序列建模框架,也显著优于其他两种方法。在主观评测中,我们所提出的非平行语音转换方法,也取得了接近序列到序列平行语音转换的性能。

总结报告内容,序列到序列话者转换方法在时长调整、长时相关性建模等方面有其优势,但是将该方法从平行数据条件推广到非平行数据条件存在挑战。特征解耦是解决这一问题的有效途径,通过序列到序列框架下的模型结构与损失函数设计可以获取相对独立的文本与话者表征,进一步实现非平行数据条件下的高质量语音转换。

另一方面,现阶段的话者转换技术还面临一些挑战,包括跨语种转换、低质数据场景、可控转换、实时转换等,这些都是后续值得进一步深入研究的内容。
以上是我的介绍,谢谢大家!
原创文章,未经授权禁止转载。详情见 转载须知 。


江苏科梦水影文化水秀水景公司深耕城市光影文化、景区夜游、夜游、文旅、水景、水秀、迪士尼喷泉的大型实体企业,将成为民营综合性专业光影水秀产业基地。

深圳市泰成五金有限公司

达昂轴承(上海)有限公司经销各品牌原装进口轴承,包括skf轴承、fag轴承、nsk轴承、ina轴承等,充足的库存,完美解决您购买进口轴承的后顾之忧。
")

萤石,智慧生活守护者。以安全为核心,以萤石云为中心,构建“1+4+N”智能家居生态,搭载四大自研硬件包含智能家居摄像机,智能入户,智能控制,智能服务机器人,开放接入环境控制、智能影音等子系统,实现家居及类家居场景的全屋智能化,更有智能门锁,智能猫眼,指纹锁等智能化家居产品,利用萤石云开放平台,与合作伙伴共同打造互联互通的物联网云生态。

江苏姜恒膨胀节厂家生产定做非金属膨胀节,圆形非金属膨胀节,矩形非金属膨胀节,非金属膨胀节蒙皮,金属膨胀节、四氟,橡胶,管道膨胀节,电站风门等,质优价实:13921724829石经理

东风李尔汽车座椅有限公司_公司成立于2004年3月,主要从事汽车座椅及其零部件的研发、制造、销售和服务,是国内综合实力当先的汽车座椅供应商。

安徽丰辰网络信息技术有限公司成立于2015年,致力于为广大企业及个人用户提供优秀互联网建设及推广服务,多年来累计服务客户超过2500家。公司主要服务项目包括但不限于网站建设、微信公众号、小程序开发、服务器空间、网络推广、400电话、企业邮箱等,以帮助客户轻松、快速、高效的应用互联网,提高企业竞争能力。

消防主机维修网是由经验丰富消防工程师与消防设备厂家主导维修海湾、利达、陆和、松江、狮岛、北大青鸟、核中警等各种品牌消防主机、设备维修以及故障解决技术指导。热线电话4000-346-119

四川华东亿尚网络科技有限公司,网站建设,软件开发,APP开发,网站维护,小程序开发,四川APP开发,四川小程序开发,四川网站建设,绵阳网页设计,绵阳网络推广

无锡市建华电器厂专业生产无极灯,低频无极灯,隧道灯,led无极灯,具有高效、节能、环保、无电极、长寿命、无频闪的特性,为太阳光的补充,是目前理想的光源.

深圳市科陆精密仪器有限公司隶属于深圳市科陆电子科技股份有限公司(股票代码:002121),是一家为电表检测、终端捡测、气体探测、电池测试、充电桩检测以及其他电工仪表检测提供专业解决方案的高新技术企业。


日前,中国航天科工二院25所在北京完成国内首次太赫兹轨道角动量的实时无线传输通信实验,利用高精度螺旋相位板天线在110GHz频段实现4种不同波束模态,通过4模态合成在10GHz的传输带宽上完成100Gbps无线实时传输,眼下,全球6G研发已全面启动,通过通信、感知、计算、智能、安全等多方面的创新,满足公众对于新一代信息通信服务的需求,...。

醒图怎样制作渐变色图片,醒图软件里有很多的图片制作功能,用户可以在这里轻松的生成不错的图片,制作渐变色的背景图,那么怎么制作渐变色图片呢,还不清楚的小伙伴就赶紧来看看吧!...。

肥牛之家火锅成立于2008年,公司创立至今,以服务大众为己任,在行业内获得了非常多的好评,很多人都想知道肥牛之家火锅加盟费,接下来就告诉大家,肥牛之家火锅加盟费肥牛之家火锅主打的就是肥牛火锅,味道非常鲜美,对菜品食材的选择有十分严格的要求,所选用的食材都是无公害的,只为能够提供给消费者们更好的美食,与此同时,为了能够让消费者们有更好的...。

焖锅是自火锅以来又一崛起并且兴起的食物,它算是吃货界的又一霸,而且经久不衰,它比火锅吃起来更加的方便,而且制作的也并不是很复杂,但是它还有火锅的优点,那就是可以随意的往里面放自己喜欢的东西,这几点加起来,足以看出这小小的焖锅其实潜力很大,那么焖锅加盟店哪个比较好呢,我在这里可以推荐一下,唇动小焖锅是一个新崛起来的品牌,但是你不要小瞧它...。

发表在明基投影仪2024,1,2513,05明基E585是明基E582的升级版本,是一款画质性能更强的商务投影仪,那么明基E585投影仪的实际参数配置如何呢,下面就为大家分享,看看明基E585投影仪怎么样,各方面有什么特点,是否可以满足商务办公需求,明基E585投影仪怎么样,1.画质方面在亮度方面,明基E585的实际亮度达到3800I...。

发表在精选问答2020,12,1419,39将极米投影仪连接HDMI高清线;,HDMI高清线的另一端连接到电脑的HDMI接口;,极米无屏电视切换信号为HDMI,电脑选择拓展屏幕或复制屏幕即可,极米无屏电视怎么连接电脑1.将极米投影仪连接HDMI高清线;2.HDMI高清线的另一端连接到电脑的HDMI接口;3.极米无屏电视切换信号为H...。

据外交部网站,9月18日,外交部发言人林剑掌管例行记者会,以下为局部问答实录,独特社记者,据日本政府发布的信息,18日上午深圳日自己学校的一名在校生遭逢一名男性袭击被刺伤住院,请问发言人能否引见该事情的更多细节,另外这曾经是往年第二次针对在华日本在校生的袭击,中方如何看待这类事情,能否以为这类事情还是偶发事情,林剑,9月18日上午,深...。

2020年清明节是2020年04月04日星期六,庚子年,鼠年,三月十二,距离2021年清明还有144天,春分后15天是清明节,又叫,踏青节,中国传统节日,也是最关键的祭奠节日之一,是祭祖和扫墓的日子,2020年清明是哪天1.2020年的清明节是在4月4日,这一天是星期六,2.国度规则,2020年的清明节假期为4月4日至4月6日,合计...。

羚羊底盘高度为155mm,羚羊作为一款小型车,底盘高度为155mm,经过性好,然而,当高速转弯时,底盘越高,车身越不稳固,车辆底盘越低,越稳固,但经过性会更差,底盘高度是多少,底盘高度也可称为最小离地间隙,是指车辆底部到低空的垂直距离,底盘越高,经过性越好,但稳固性越差,底盘越低,经过性越差,但稳固性越好,底盘高度适合汽车的底盘高度在...。

58同城是中国生存分类消息网站,提供找房子、找上班、二手东西交易、二手车、58团购、商家黄页、宠物票务、旅行、交友等多种生存消息,58同城成立于2005年,总部设在北京,2007年在天津、上海、广州、深圳成立分公司,目前曾经在全国320个重要市区申请分站,58同城同城网定位于本地社区及收费分类消息服务,协助人们处置生存和上班所遇到的难...。

有以下步骤,依据查问九游网,1、点击,商店,按钮,在商店页面,点击,植物,选项卡,2、选用须要购置的植物,例如,豌豆射手,,而后点击该植物,3、.在弹出的购置窗口中,点击,购置,按钮,方法,下载,植物大战僵尸2苹果国内版,方法在中国地域的AppStore是不可下载,植物大战僵尸2国内版,的,上方引见如何下载官网正版,点击主界面的,A...。

VinFast股价两日“腰斩”市值暴跌7000亿元,股价,期权,股票,查诺斯,每日优鲜公司解散

小程序和小游戏俨然成了微信新的金矿,前途不可限量,根据官方数据,微信用户已经突破10亿,小程序已达58万个,日活跃账户超过1.7亿个,春节期间小游戏同时在线人数最高达到了2800万人,小时,如今更是上线了广告,都是千万元级别的,现在,微信正式开放了小程序游戏类目的测试,开发者可开发、调试小游戏,同时对小游戏开放微信社交关系链、虚拟支付...。
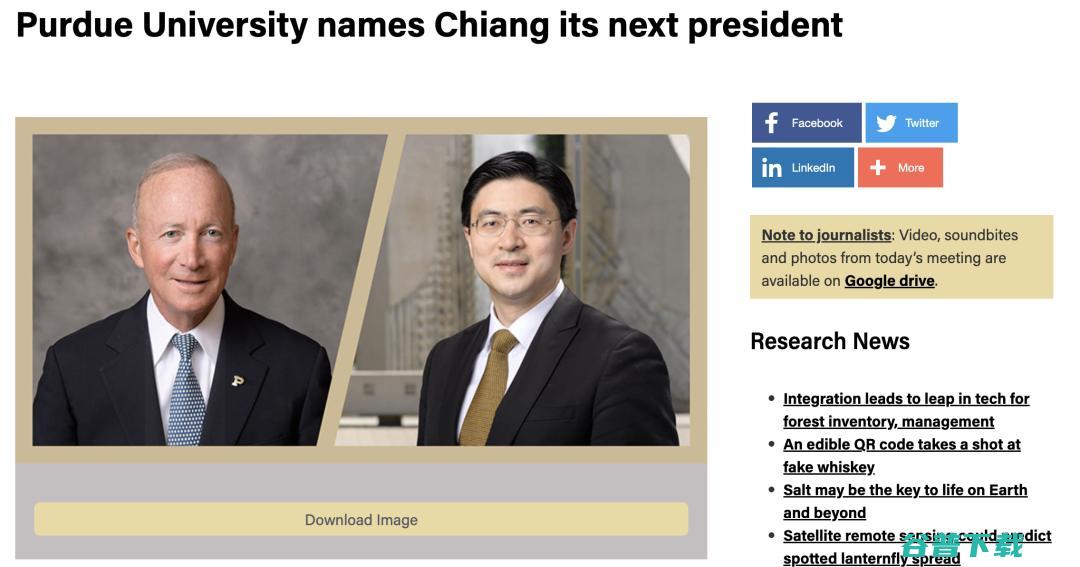
0日,普渡大学董事会宣布,一致选举现任JohnA.Edwardson工程学院院长兼战略计划执行副校长蒋濛博士为该大学的下一任校长,他将于2023年1月1日起,接替现任校长MitchDanielseffectiveJan,他也将是普渡大学历史上第一位华裔校长,蒋濛,1977年出生于中国天津,美国工程研究员,教育家、技术企业家、大学领导和...。

平静了一段时间的即时零售赛道,最近颇为热闹,拉满话题的是各种,仓,山姆的前置仓业务超过了总收入的一半,并实现了盈利,开始反哺线下店,这也正是很多零售商需要的,名创优品在盈利模型跑通后开始规模化,开仓,,目前已经开了500多个,闪电仓,为什么有线下成熟渠道布局的零售商纷纷以,仓业态,加码即时零售,仓,对于它们的意义是什么,为实体店...。

发表在哈趣投影仪2024,10,1422,542024双十一活动来的很早,不过哈趣作为千元LCD投影仪头部品牌,依然销量惊人,新品哈趣NEWK2更是强势登顶销量榜!哈趣不愧是LCD投影仪的黑马,一黑到底,销量惊人!在双十一活动中,哈趣NEWK2在3000价位段内单品实时销量第一!双11首日投影类目销售额第三名!今年双十一哈趣热卖产品是...。

10月14日,外交部发言人毛宁掌管例行记者会,日本广播协会记者提问,关于中方在中国台湾周边海域的军事演习,美国国务院发言人表白严重关切,请问发言人对此有何评论,毛宁示意,台湾是中国的一局部,台湾疑问是中国外交,不容任何外来干预,假设美方真的在乎台海的和颠簸固和地域的兴盛,就应当遵守一个中国准则和中美三个联结公报,实际将美国指导人不允许...。
