ICML 2019 (icml2024)
雷锋网 AI 科技评论按,本文作者 张拳石 ,上海交通大学副教授,研究方向为机器学习、计算机视觉,本文首发于 知乎 ,雷锋网 AI 科技评论获其授权转载。以下为正文内容。
本来想把题目取为「从炼丹到化学」,但是这样的题目太言过其实,远不是近期可以做到的,学术研究需要严谨。但是,寻找适当的数学工具去建模深度神经网络表达能力和训练能力,将基于经验主义的调参式深度学习,逐渐过渡为基于一些评测指标定量指导的深度学习,是新一代人工智能需要面对的课题,也是在当前深度学习浑浑噩噩的大背景中的一些新的希望。
这篇短文旨在介绍团队近期的 ICML 工作——「Towards a Deep and Unified Understanding of Deep Neural Models in NLP」(这篇先介绍 NLP 领域,以后有时间再介绍类似思想解释 CV 网络的论文)。这是我与微软亚洲研究院合作的一篇论文。其中,微软研究院的王希廷研究员在 NLP 方向有丰富经验,王老师和关超宇同学在这个课题上做出了非常巨大的贡献,这里再三感谢。
大家说神经网络是「黑箱」,其含义至少有以下两个方面:一、神经网络特征或决策逻辑在语义层面难以理解;二、缺少数学工具去诊断与评测网络的特征表达能力(比如,去解释深度模型所建模的知识量、其泛化能力和收敛速度),进而解释目前不同神经网络模型的信息处理特点。
过去我的研究一直关注第一个方面,而这篇 ICML 论文同时关注以上两个方面——针对不同自然语言应用的神经网络,寻找恰当的数学工具去建模其中层特征所建模的信息量,并可视化其中层特征的信息分布,进而解释不同模型的性能差异。
其实,我一直希望去建模神经网络的特征表达能力,但是又一直迟迟不愿意下手去做。究其原因,无非是找不到一套优美的数学建模方法。深度学习研究及其应用很多已经被人诟病为「经验主义」与「拍脑袋」,我不能让其解释性算法也沦为经验主义式的拍脑袋——不然解释性工作还有什么意义。
研究的难点在于对神经网络表达能力的评测指标需要具备「普适性」和「一贯性」。首先,这里「普适性」是指解释性指标需要定义在某种通用的数学概念之上,保证与既有数学体系有尽可能多的连接,而与此同时,解释性指标需要建立在尽可能少的条件假设之上,指标的计算算法尽可能独立于神经网络结构和目标任务的选择。
其次,这里的「一贯性」指评测指标需要客观的反应特征表达能力,并实现广泛的比较,比如
1. 诊断与比较同一神经网络中不同层之间语义信息的继承与遗忘;
2. 诊断与比较针对同一任务的不同神经网络的任意层之间的语义信息分布;
3. 比较针对不同任务的不同神经网络的信息处理特点。
具体来说,在某个 NLP 应用中,当输入某句话 x=[x1,x2,…,xn] 到目标神经网络时,我们可以把神经网络的信息处理过程,看成对输入单词信息的逐层遗忘的过程。即,网络特征每经过一层传递,就会损失一些信息,而神经网络的作用就是尽可能多的遗忘与目标任务无关的信息,而保留与目标任务相关的信息。于是,相对于目标任务的信噪比会逐层上升,保证了目标任务的分类性能。
我们提出一套算法,测量每一中层特征 f 中所包含的输入句子的信息量,即 H(X|F=f)。当假设各单词信息相互独立时,我们可以把句子层面的信息量分解为各个单词的信息量 H(X|F=f) = H(X1=x1|F=f) + H(X2=x2|F=f) + … + H(Xn=xn|F=f). 这评测指标在形式上是不是与信息瓶颈理论相关?但其实两者还是有明显的区别的。信息瓶颈理论关注全部样本上的输入特征与中层特征的互信息,而我们仅针对某一特定输入,细粒度地研究每个单词的信息遗忘程度。
其实,我们可以从两个不同的角度,计算出两组不同的熵 H(X|F=f)。
(1)如果我们只关注真实自然语言的低维流形,那么 p(X=x|F=f) 的计算比较容易,可以将 p 建模为一个 decoder,即用中层特征 f 去重建输入句子 x。(2)在这篇文章中,我们其实选取了第二个角度:我们不关注真实语言的分布,而考虑整个特征空间的分布,即 x 可以取值为噪声。在计算 p(X=x,F=f) = p(X=x) p(F=f|X=x) 时,我们需要考虑「哪些噪声输入也可以生成同样的特征 f」。举个 toy example,当输入句子是「How are you?」时,明显「are」是废话,可以从「How XXX you?」中猜得。这时,如果仅从真实句子分布出发,考虑句子重建,那些话佐料(「are」「is」「an」)将被很好的重建。而真实研究选取了第二个角度,即我们关注的是哪些单词被神经网络遗忘了,发现原来「How XYZ you?」也可以生成与「How are you?」一样的特征。
这时,H(X|F=f) 所体现的是,在中层特征 f 的计算过程中,哪些单词的信息在层间传递的过程中逐渐被神经网络所忽略——将这些单词的信息替换为噪声,也不会影响其中层特征。这种情况下,信息量 H(X|F=f) 不是直接就可以求出来的,如何计算信息量也是这个课题的难点。具体求解的公式推导可以看论文,知乎上只放文字,不谈公式。
首先,从「普适性」的角度来看,中层特征中输入句子的信息量(输入句子的信息的遗忘程度)是信息论中基本定义,它只关注中层特征背后的「知识量」,而不受网络模型参数大小、中层特征值的大小、中层卷积核顺序影响。其次,从「一贯性」的角度来看,「信息量」可以客观反映层间信息快递能力,实现稳定的跨层比较。如下图所示,基于梯度的评测标准,无法为不同中间层给出一贯的稳定的评测。

下图比较了不同可视化方法在分析「reverse sequence」神经网络中层特征关注点的区别。我们基于输入单词信息量的方法,可以更加平滑自然的显示神经网络内部信息处理逻辑。

下图分析比较了不同可视化方法在诊断「情感语义分类」应用的神经网络中层特征关注点的区别。我们基于输入单词信息量的方法,可以更加平滑自然的显示神经网络内部信息处理逻辑。

基于神经网络中层信息量指标,分析不同神经网络模型的处理能力。我们分析比较了四种在 NLP 中常用的深度学习模型,即 BERT, Transformer, LSTM, 和 CNN。在各 NLP 任务中,BERT 模型往往表现最好,Transformer 模型次之。
如下图所示,我们发现相比于 LSTM 和 CNN,基于预训练参数的 BERT 模型和 Transformer 模型往往可以更加精确地找到与任务相关的目标单词,而 CNN 和 LSTM 往往使用大范围的邻接单词去做预测。

进一步,如下图所示,BERT 模型在预测过程中往往使用具有实际意义的单词作为分类依据,而其他模型把更多的注意力放在了 and the is 等缺少实际意义的单词上。
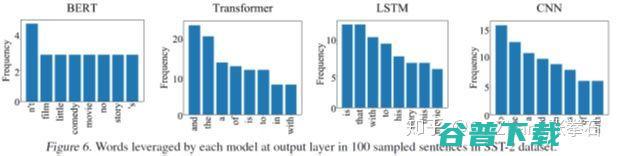
如下图所示,BERT 模型在 L3-L4 层就已经遗忘了 EOS 单词,往往在第 5 到 12 层逐渐遗忘其他与情感语义分析无关的单词。相比于其他模型,BERT 模型在单词选择上更有针对性。

我们的方法可以进一步细粒度地分析,各个单词的信息遗忘。BERT 模型对各种细粒度信息保留的效果最好。

回国以后,身份从博后变成了老师,带的学生增加了不少,工作量也翻倍了,所以一直没有时间写文章与大家分享一些新的工作,如果有时间还会与大家分享更多的研究,包括这篇文章后续的众多算法。信息量在 CV 方向应用的论文,以及基于这些技术衍生出的课题,我稍后有空再写。
顺便做个广告,欢迎有能力的学生来实验室实习,同时也招博后。目前我的团队有 30 余人,其中不少同学是外校全职访问实习生。我一般会安排每三四人为一个团队做一个课题,由于访问实习生往往不用为上课而分心,可以全天候做实验室工作,在经过一定训练之后往往会担任团队领导。
版权文章,未经授权禁止转载。详情见 转载须知 。



智慧职教以知识点/技能点为基本颗粒度,以整个专业的知识/技能树为整体架构,通过系列元数据对素材实现系统化管理,从而使得每个素材都能被便捷地查询和调用。

丰巢于2015年6月6日由顺丰、申通、中通、韵达、普洛斯领航共同投资创建,致力于研发运营最优质的智能快递柜,破解快递最后100米难题,服务于全行业末端快件运营,打造全方位开放共享自助智能平台。作为专业的快递末端服务平台,丰巢已经形成可提供硬件研发、软件服务、网点运力调配的行业解决方案服务商,支持为其他物业、企业、校园服务商提供业务服务接口,提升末端物流行业整体运营效率。未来将不断完善末端物流服务,通过提升硬件设备的使用率、降低人力投入不断优化末端物流成本,以全面电子化流程服务于末端快递网点及消费者。

大哲网-学习成就梦想!大哲网(www.dazhe5.cn)成立于2019年,是国内大型公益性英语学习平台。提供在线英语阅读、英语音标、英语单词查询、英语语法、英语听力、英语口语、少儿英语、高中英语、四六级、雅思托福、高考英语、中考英语等各个阶段的英语学习资源。学习者不仅可以提高自己的语言水平,还可以了解到丰富多彩的英语国家文化和社会知识。

湖北京山锦鸿电器设备有限公司是集设计、科研、制造、销售、售后服务为一体的企业

徐州市水利工程建设有限公司前身是徐州市水利工程建设局,创建于1959年7月,现为国家“水利水电工程施工总承包壹级”施工资质企业,同时具有港口与航道工程、公路工程、市政公用工程、房屋建筑工程、土石方工程等总承包和专业资质。

猎巴巴分类信息网为您提供生活分类信息,囊括房屋出租、二手房,二手车交易、跳蚤市场、招聘求职、交友征婚等与生活息息相关的信息,满足您生活的方方面面,欢迎免费发布查看猎巴巴分类信息,生活分类信息。

陕西威尔量仪是国内专业的圆度仪、圆柱度仪、粗糙度仪、轮廓仪、活塞测量仪的生产厂家,威尔量仪致力成为国内专业的精密测量解决方案提供商,咨询电话:029-81134043,期待您的到来。

青岛路博建业环保科技有限公司(www.qdlubojy.com)是一家专业的烟尘烟气测试仪厂家,有机挥发物检测仪厂家,公司现设立专业的技术服务团队,为客户提供一对一式服务,欢迎来电洽谈。

名一化工有限公司主要经营产品:工业酒精,95﹪乙醇,无水乙醇,异丙醇,乙二醇,甲苯,二甲苯,醋酸乙酯,醋酸丁酯,碳酸二甲酯,醋酸仲丁酯,醋酸甲酯,丙酮,丁酮,环己酮,去渍油,白电油,溶剂油,乙二醇单丁醚,甲缩醛,二氯甲烷,洗网水,洗枪水,开油水,慢干水,稀释剂,异佛尔酮,丙二醇,碳氢清洗剂。本公司以多品种经营特色和薄利多销的原则,赢得了广大客户的信任。我们执着坚持顾客至上,质量保证。

重庆西鹏电力科技有限公司重庆西鹏电力科技有限公司,成立于2010年,是一家专业从事电力工程施工、电气设备运维管理、科技及QC类创新技术开发的电力行业综合服务商。承接220kV及以下各电压等级的输变电工程业务。公司注册资金1119万元,具有电力工程总承包三级资质、建筑工程总承包、承装(修、试)电力设施三级资质、防水防腐保温二级资质、电子与智能化工程专业化二级、建筑装修装饰工程专业承包二级、消防设施工程专业承包二级等。

潍坊恒日电磁设备有限公司创建于一九八六年,是生产磁选设备的专业化制造公司。是集科研开发、工程设计、生产安装、调试服务于一体的国内大型磁选设备制造企业之一。

郑州市法律援助基金会


面对激烈的市场竞争环境,这两年国内智能手机厂商在工业设计、屏幕素质、影像和充电功率等用户容易感知的元素上持续投入资金并屡获创新突破,渐渐拉近与大洋彼岸对手的差距,渐成国人购机的首选,在近日,深圳市商业联合会@全球深商官方发布微博力挺荣耀Magic3系列,同时多家深圳企业也纷纷跟进推荐,从侧面反映出依托技术积累及创新,国产手机正在加速崛...。

雷锋网AI科技评论按,谷歌云机器学习平台,GoogleCloudAI,自从上线以来就以预训练的、可以直接调用的高效机器学习模型吸引了许多企业级用户在其上构建简单的机器学习应用,然而企业总是会有自己专属的需求的,越来越多的企业会不再满足于预定义好的功能,而想要设计和应用更加自定义化的机器学习模型,今天,在谷歌云首席科学家李飞飞和谷歌云研...。

11月22日,雷锋网将于深圳举办,2019全球AIoT产业·智能制造峰会,作为雷锋网精心打造的唯一年度AIoT盛会,峰会聚焦AI、IoT、5G、边缘计算及其场景应用在内的关键技术发展;聚焦智能家居、智能制造、智慧城市为核心的关键产业落地,致力于打造探讨AIoT技术发展及产业落地中关键问题的行业技术峰会,为产学研思想碰撞、融合应用提供...。

近日,国内Wi,Fi芯片公司尊湃通讯宣布超募完成数亿人民币Pre,A轮融资,本轮融资资金将主要用于研发投入、投片测试、市场拓展以及公司运营等,本轮融资由小米集团、湖杉资本、天际资本、嘉御资本、上海科创旗下海望资本、平治信息等知名财务投资机构以及产业投资方组成,此前,尊湃通讯于21年5月已完成由高榕资本领投,江北佳康科技跟投的近亿人民币...。

发表在极米投影仪2024,2,111,14看了极米新品发布会,被电动云台所吸引,咬咬牙入手了极米RS10Ultra,但是实际入手后发现,极米RS10Ultra和我心中所想差别有点大啊!极米RS10Ultra的外观和画质和我想象中完全不一样,唯一变化不大的就是那系统桌面了吧,感觉没有太大的变化,收到极米RS10Ultra之后发现,极米R...。

文字链接认证代码普通联盟标志认证代码企业广告联盟标志认证代码广告联盟评测代码说明,本页面的认证代码为紫云广告联盟专用评测代码,站长需懂简单html知识,直接复制代码粘贴到联盟网站相应页面即可使用,本代码不适用于其他广告联盟网站请勿获取!文字认证,文字链接代码认证适用所有类型的广告联盟,复制代码后放在紫云广告联盟网站首页底部或友情链接位...。

逍客提价的要素重要有两点,首先,市场上的同类车型竞争十分剧烈,生产者在选用车型时有很大的空间,多少钱适合的车型往往是生产者首要思考的要素,其次,逍客作为一款老款车型,无法防止地遭到了期间的影响,车型降级换代的需求越来越大,但未来的新款车型还未知,因此生产者也会担忧购置后车型过于过期,为了激起生产者的购车愿望并优化销量,厂商选用了降落多...。

1、雷克萨斯es300的静音可以,笔较反常;雷克萨斯es300属于中大型级别的车全新一代雷克萨斯es300定位为中大型轿车,其车身尺寸为4975*1866*1447mm,车身轴距为2870mm作为中大型轿车来说,雷克萨斯es300的车身尺寸是比拟大的,车内空间十分宽阔;关于大少数雷克萨斯es300车主来说,刚买的车普通都是保护有加,但...。

2018款迈巴赫S级新车指点价,146.8,309.8万元,1、空间方面挑不出故障,尤其是后排的位置,特意宽阔,毕竟这事老板车,老板普通都是坐在前面,所以后排的空间设计十分大,满足后排需求;2、然而后排大的影响就是汽车的后备箱稍庞大了点,毕竟空间都给后排座椅了,不过能买起这个车,对后备箱的需要也没有多大了;3、油耗方面就不用说了,买...。

番茄畅听电脑版是一款优质的小说阅读软件,软件致力于为用户提供优质的小说阅读服务。在这里用户可以找到海量正版的小说资源

在MySQL中创建买菜系统的支付记录表是购物网站必不可少的功能。这个表主要用于存储用户在购物系统中的支付信息,包括支付金额、支付时间、订单号等。以下是如何在MySQL中创建买菜系统的支付记录表的具体代码示例:CREATETABLE`payment_record`(`id`int(11)NOTNULLAUTO_INCREMENTCOMME

蓝科谷商业管理软件,蓝科谷商业管理软件是一款功能强大,专业实用的商品管理软件,软件能够解决门店百分之九十的管理难题,让管理更轻松。软件支持云端数据备份,无需担心因电脑断电或损坏造成的数据丢失,欢迎下载使用,您可以免费下载。

从昨晚开始,我们看到很多QQ空间和朋友圈的好友都在发淘小铺的邀请码,了解后知道这是淘宝的淘小铺正式上线了,获得邀请码就可以开启自己淘小铺,开始新一轮的个人创业,据了解,淘小铺采用的是一种叫做S2B2C模式进行卖货,简单来讲就是将供货商、分销商和采购商拉在一块去卖东西的一种模式,就是作为淘小铺卖家只需要负责卖东西的责任就可以,发货和售后...。

随着社交媒体的发展,微博、腾讯、头条较早推出信息流广告产品,同时得益于其庞大的用户基数,成为信息流广告收入的主流梯队,百度、爱奇艺、优酷、浏览器等也于去年上线信息流广告产品,增长迅速,预计近两年呈爆发式增长,面对如此之多的信息流渠道,我们应该如何选择?又应该如何投放呢?所以,今天就来聊一聊2017年主流信息流平台的特点和用户数据以及特...。

净水器租赁哪个牌子好,美淳净水器加盟代理,在净水器行业发展,目前还没有相关净水协会制定净水器行业标准体系,那么在这个行业里面,目前没有哪个净水器品牌敢说自己是老大,在2016年各个行业都受影响下,在目前来说净水器在迅速发展的市场化进程中,越来越多的企业由于经营不善的原因,陆续退出了这个行业,而行业规模型和有技术实力支撑的企业此时有了更...。

4D成像毫米波雷达最近又热了起来,今年CES上,4D成像毫米波雷达声势夺人,一众芯片企业诸如恩智浦、TI、Mobileye都陆续推出或更新了自己的成像雷达方案,毫米波雷达系统厂商Arbe、ZadarLabs、Smartmicro等也都带来了各自的成像雷达产品,其中最受到业内人士关注的,莫过于Mobileye首席执行官AmnonShas...。

CVIA流明是中国电子视像行业协会协同当贝等投影品牌制定的新亮度标准,那么CVIA刘明怎么换算ANSI流明呢,下面就通过CVIA流明换算ANSI流明公式来了解,看看1CVIA流明换算下来为多少ANSI流明,1678867368054,11.png一、CVIA流明怎么换算ANSI流明,CVIA流明的测算方式有更为严格的要求,CVIA流明...。
