最有意思的五篇文章 CoRL上 (最有意思的五十音图)
现在的各种学术会议多如牛毛,一个大会质量高不高,除了看大会后的组织者是谁之外,另一个重要因素的是看这个学术会议上出过哪些重要的论文。如伯克利 BAIR Blog 编委会成员、在读博士许华哲就和雷锋网记者开过玩笑,如果要组织一个新的会议,会议组织者不仅需要邀请重量级的演讲嘉宾,另一个任务是盯着自己的学生做出一两篇有影响力的论文来,这样就可以让大家知道这个会不是水会,第二年参加的人就多了。这固然是个玩笑,但对第一届举办的学术会议来说,论文质量一定是非常重要的。
近日在山景城召开的第一届CoLR大会上,雷锋网也重点了解了这届大会论文投递的情况。
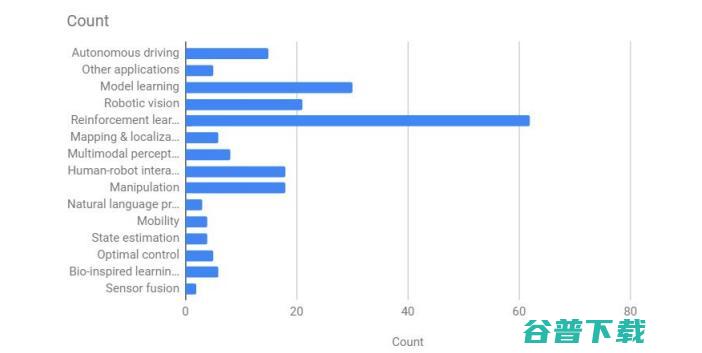
从大会官方统计数据看,本次大会总共收到212篇论文,数量最大的三个论文类别分别为增强学习、模型学习和机器人视觉;
在现场Oral presentation环节,长论文的讲解时间为20分钟,短论文讲解时间为6分钟。
以下是雷锋网在现场发现的若干有意思的论文:
1. 《 One-Shot Visual Imitation Learning via Meta-Learning 》
作者:Chelsea Finn , Tianhe Yu , Tianhao Zhang, Pieter Abbeel, Sergey Levine
摘要:为了让机器人成为可以广泛地执行通用工作,其必须能在复杂的非结构化环境中快速有效地获取各种各样的技能。 像深度神经网络这样的高容量模型可以使机器人展示出复杂的技能,但是从头开始学习每个技能就变得不可行。 在本论文中,我们提出了一种元模拟学习方法,使机器人学习如何更有效地学习,从而使其能够从单个展示中获得新的技能。 与先前的单次模拟方法不同,我们的方法可以扩展到原始像素输入,所需要前期任务数量也大大减少,从而更有效地学习新技能。 我们在模拟机器人和真实机器人平台上进行的实验均证明了从单个视觉展示中学习端到端的新任务的能力。
点评: 这篇论文是雷锋网很早就发现的一篇论文,详见《 BAIR论文:通过“元学习”和“一次性学习”算法,让机器人快速掌握新技能 》
2. 《 image2mass: Estimating the Mass of an Object from Its Image 》
作者:Trevor Standley, Ozan Sener, Dawn Chen, Silvio Savarese
摘要:机器人操纵真实世界中的物体需要理解这些对象的物理属性。 我们提出了一个从物体的图像中估计物体质量的模型, 我们收集了包含图像,大小和重量等信息的大型数据集,并比较了在这个数据集上训练的图像的质量的几个基准模型。同时,我们对比了也在这个问题上人的表现。 最后,我们提出了一个考虑到对象的3D形状的模型, 这个模型比上述基准和与人类的表现相比都要更好。

点评: 斯坦福Copmutational vision & Geometry Lab的Silvio Savarese教授团队的一篇文章,看一张图片,预测物体的重量,这个应用很酷。据第一作者Trevor Standley介绍,他们使用Amazon的API接口获取大量商品信息作为数据集,除了估计体积和密度的两个模块,还有一个专门估计物体3D形状的神经网络模块,从而进一步保证物体估计的准确度。
3.《 Neural Task Programming: Learning to Generalize Across HierarCHIcal Tasks 》
作者:Danfei Xu,Suraj Nair,Yuke Zhu,Julian Gao,Animesh Garg,Li Fei-Fei,Silvio Savarese
摘要:在本论文中,我们提出了一种名为神经任务编程(NTP)的新型机器人学习框架,该方法可以通过较少的示范和神经程序引导进行学习。NTP可将输入的规范性任务(例如任务的视频展示)递归地将其分解成更精细的子任务规范, 这些规范被传递到分级神经程序,通过可调用的底层子程序是与环境进行交互。同时,我们在三个机器人操纵任务中验证了我们的方法,在试验中,NTP展示了在显示分层结构和组合结构的顺序任务的强泛化能力化。 实验结果表明,NTP在学习长度不定、可变拓扑和不断变化的未知任务的学习和拓展有较好的效果。
点评: 虽然李飞飞团队之前的研究更多是在计算机视觉领域,但正是如此,才有可能从机器人领域研究者习惯的视角外去思考问题,这篇论文提出的新思路也值得机器人研究者注意。
Intention-Net: Integrating Planning and Deep Learning for Goal-Directed Autonomous Navigation
作者: Wei Gao, Wee Sun Lee, Shengmei Shen,Karthikk Subramanian
摘要:如何将送货机器人可靠地导航到新办公大楼中的目的地,并提供最少的先验信息? 为了应对这一挑战,本文介绍了一种两层次的分级方法,它集成了无需模型的深度学习和基于模型的路径规划。 在低层次上,一个叫做意图网络的神经网络运动控制器被端对端地训练用于提供鲁棒的本地导航。 意图网络将来自单个单目照相机的图像和“意图”直接映射到机器人控制器。 在高层,路径规划者使用粗略地图(例如二维平面图)来计算从机器人当前位置到目标的路径, 计划的路径向意图网络提供意图。 初步的实验表明,学习的运动控制器是强大的,不受感知的不确定性的影响,并通过与路径规划器的整合,有效地推广到新的环境和目标。

点评: 未来的无人驾驶车辆能否像人类一样,凭借Google Maps就能自动驾驶?这显然是一个让无人驾驶更接近“人”的研究。
5. 《 Emergent Behaviors in Mixed-Autonomy Traffic 》
作者:Cathy Wu,Aboudy Kreidieh, Eugene Vinitsky, Alexandre M. Bayen
摘要:交通动态往往是一个复杂的动力系统建模,传统的分析工具可能难以提供由交通运输机构和规划者使用的易处理的策略。如果将自动车辆引入交通系统,需要了解自动化对交通网络的影响。本文阐述并采用增强学习(RL)的强大框架来处理混合交通控制问题(存在自动驾驶车辆和人类司机)中由此产生的政策和紧急行为,提供了通过混合车队的自动化和人类司机车辆实现交通自动化的潜力。无模式学习方法被证明自然选择之前由模型驱动的方法设计的政策和行为,例如稳定和排队,可以有效提高环路效率甚至超过理论速度极限。值得注意的是,RL通过有效地利用人类驾驶行为的结构来成功地使速度最大化,以形成交叉口网络的有效车辆间距。我们在稳定性分析和混合自治分析的现有控制理论结果的背景下描述我们的结果。
点评: 如果自动驾驶车辆达到5%,对我们的交通会产生什么影响?这一论文的试验中展示了在一个21辆人类司机和1辆无人驾驶车在环形路段的模拟情况,整个运行效率可提高60%。现实交通状况可能更为复杂,但如果无人车的加入可以更好地解决拥堵问题,毫无疑问对无人车是个大利好消息。
原创文章,未经授权禁止转载。详情见 转载须知 。



阜阳职业技术学院-图文信息中心

动漫之家是国内最全最专业的在线漫画、原创漫画、最好看的动漫网站,每周更新各种原创漫画、日本动漫,动画片大全、漫画大全、好看的漫画尽在动漫之家漫画网。

安徽新远大木业有限公司产品全部采用本地优良意杨和进口奥古曼、柳桉、覆膜纸为原材料,经过先进的生产工艺流程,加工而成的室外专用建筑覆膜板、工艺板、高档家私板。

温泉设计装修公司专业为客户提供专业的温泉设计,温泉装修,水疗设计,水疗装修,洗浴中心设计,洗浴中心装修,景区设计,洗浴设备,酒店设计,酒店装修,洗浴设计,洗浴装修,办公楼设计,办公楼装修,温泉洗浴设备,洗浴热回收设备等服务,承接大型洗浴、酒店等商业娱乐空间的装修设计工程。沐色洗浴酒店设计工程公司用心为客户服务,其装修设计案例已覆盖国内各大城市。

本公司专业从事建筑工程、装饰工程、市政工程、公路工程、水利工程预决算项目工作。拥用综合素质专业团队30余人,设有两个土建部、一个安装部、一个抽筋部...

广东简彩纸业科技有限公司热敏纸收银纸主要从事中高端热敏纸的研发、生产

提供大量优质的在线工具服务,含各种类型在线使用工具,生活服务工具,电子商务工具,新闻咨询工具,人工智能工具,腾讯视频会员,优酷视频会员,影视会员充值等类型,平台提供定制功能,可按照用户需求定制专属工具,是一款专业的,优质的免费在线工具服务平台-台州云图电子商务有限责任公司

诸城市博宇环保设备有限公司专业制造污水处理设备:地埋式一体化污水处理设备、含油废水处理设备、污泥深度处理设备、浅层气浮机、污泥二次脱水设备、涡凹气浮机、溶气气浮机、地埋式污水处理设备、曝气机、微孔转鼓过滤机(纤维回收机)。

苍溪县找找网信息技术有限公司专注于网站开发,APP原生编程,快速将网站制作成APP

上海铭控传感技术有限公司是专业的智慧消防消火栓,地下智能消火栓,无线消防压力表供应商,主营产品有:智慧消防消火栓,地下智能消火栓,无线消防压力表等,上海铭控传感技术有限公司不仅具有专业的技术水平,更有良好的售后服务和优质的解决方案,欢迎来电洽谈

威久留学创办于1999年,是教育部认证的出国留学中介服务机构,英国留学领军者;拥有23年出国留学办理经验;有数百名留学顾问、两千余所合作院校和30余家海内外分支机构,始终致力于为客户提供全方位留学咨询服务!详情垂询:400-164-6699
有限公司")
香港港宜商务科技有限公司(深圳市港宜商务咨询有限公司)成立于2009年,专注于全球公司,商标,刊号,开户业务,现已经成功服务全球5000多名客户,收到客户一直的好评。咨询电话:0755-28534690


熊猫直播要正式关站了,这家由王思聪一手创办、,含着金汤匙,出生的泛娱乐直播平台,在唏嘘间结束了三年多的寿命,昨天下午开始,已经有熊猫直播在职员工发朋友圈告别,昨日晚间,熊猫直播创始团队成员兼首席运营官COO张菊元深夜发出一封内部信,称选择关站是,一个无奈却最理智的选择,张菊元表示,在做出遣散员工决定的这一刻,熊猫依然有每天几百万的日...。
做淘宝客和卖家朋友们最关心的是流量从哪里来?流量怎么提升?流量结构该如何?我分析过大丶中丶小淘宝店铺,一般比较合理的流量比例是,自然流量35,50%丶直接点击流量15,20%丶直通车流量35,40%丶淘宝客5,10%,其它少到乎略不计,这里没有包含钻展丶硬广丶活动流量,因为这些使用的不多,也没有固定的频率,暂不统计,大卖家会占到一定的...。

创业哪个项目好,近年来儿童阅读加盟行业持续保持增长状态,主要在于以下几点,·全民阅读、文化自信是大背景,阅读是一个比较好的创业切入口;·9月份新的中小学新教材上线,整本书阅读对孩子的阅读量、阅读能力提出了更高的要求;·AI时代,培养孩子的综合能力成为大趋势,而阅读是其中的重要途径……在这种背景下,以借阅,读书会,研学活动为运营模式的书...。

AppleWatch光鲜亮丽的背后是每晚一充的苦逼日子,你是不是也是如此呢,现在有一款专为AppleWatch设计的移动电源,可以几乎完美地解决第一个问题,Amber充电盒拥有和AppleWatch一样超高的颜值,并能给AppleWatch增加足足8天的续航,此外,在2016年Amber充电盒还获得了IF设计奖,时尚外观设计简洁优雅A...。
智慧城市,,并不是一个新鲜词汇,自1953年IBM用电子订票系统,Sabre,替换了美国航空的纸质系统进而改变了整个行业开始,智慧城市的发展历史便已经变得有迹可循,可以说,过去的六十几年里,智慧城市的更迭就像正余弦曲线一样起起落落,被人们提起又被人们质疑甚至遗忘,而无论第几次,崛起,,它的作用从来没有发生过改变,用认知计算、大数据、...。

近日,基于存算一体技术的大算力计算芯片公司后摩智能宣布完成3亿元人民币Pre,A轮融资,本轮融资由启明创投领投,现有投资方经纬中国追加投资,和玉资本、中关村启航、沃赋资本、华清辰瑞跟投,现有投资方红杉资本中国基金、联想创投、弘毅创投、IMO创投全部继续跟投,本轮募集资金将用于加速芯片产品技术研发、团队拓展,早期市场布局及商业落地,后摩...。

文字链接认证代码普通联盟标志认证代码企业广告联盟标志认证代码广告联盟评测代码说明,本页面的认证代码为华丽广告联盟专用评测代码,站长需懂简单html知识,直接复制代码粘贴到联盟网站相应页面即可使用,本代码不适用于其他广告联盟网站请勿获取!文字认证,文字链接代码认证适用所有类型的广告联盟,复制代码后放在华丽广告联盟网站首页底部或友情链接位...。

发表在综合交流大区2021,7,2414,08导读,2021东京奥运会开幕了,使用智能投影仪或智能电视观看奥运会需要通过newtv极光,newtv极光的标志是腾讯的,且下方有NewTV的标识,那么newtv极光是腾讯视频TV版吗,下面就来告诉大家腾讯视频TV版和NewTV极光的区别,newtv极光是腾讯视频TV版吗newtv极光并不是...。

1、在创维电视A20Pro系列上找到,应用,版块里的,应用搜索,3、在搜索界面输入DBSC,下载创维版的当贝市场,安装好以后打开,找到搜索按钮点击进入,5、在搜索框输入小程序首字母,XCX,,下载安装到6、安装好以后,把U盘接到的USB接口上,然后打开小程序,输入密码,55559510,7、然后点击,U盘安装,,找到拷贝到U盘的安装...。

小约瑟夫·罗比内特·拜登小约瑟夫·罗比内特·拜登,英语,JosephRobinetteBidenJr.,,男,1942年11月20日出世于美国宾夕法尼亚州斯克兰顿,通称,乔·拜登,...拜登的副手候选人究竟有哪些,美国前副总统兼民主党总统候选人候选人拜登宣布,他将在8月第一周的2020年选举中宣布竞选总统,即副总统候选人,并强调,将来...。
经常出现的新动力汽车包含特斯拉Model3、比亚迪秦PLUSDM,i、小鹏P7、现实ONE和蔚来ES6等,详细多少钱范畴为特斯拉Model3约29.9万,46.99万元,比亚迪秦PLUSDM,i约11.18万,17.58万元,小鹏P7约23.99万,34.99万元,现实ONE约33.8万元,蔚来ES6约35.8万,52.6万元,新动力...。

1.R汽车标记是是奇瑞瑞麒,奇瑞个人旗下的上流车品牌车瑞麒,RIICH,;2.重要用于奇瑞裁减国在行业市场;3.两边的,R,字不只抢眼的展现了瑞麒的品牌标记,也展现出聚焦沉稳的视觉好看,瑞麒,RIICH,是奇瑞的中上流轿车品牌,也是裁减国在行业市场的主力军,中国奇瑞有限责任公司于2009年3月19号在安徽芜湖正式的发布了中上流乘用车品...。

日前,国外2家数据调查机构NetMarketShare和StatCounter的最新报告显示,谷歌Chrome浏览器市场份额占比仅60%,将其他浏览器远远甩在身后,根据NetMarketShare的报告显示,截至2017年6月,谷歌Chrome市场份额占比59.49%,相比去年同期增长了10.84%,IE浏览器经营惨淡,2017年6月...。

8月23,24日这两天,首届中国国际智能产业博览会,智博会,在重庆盛大举办,重庆这座山城也借由此次大会在全国大放异彩,先看这届大会的规格,有点高,再看这届大会的主题,似乎直接拥抱智慧城市,整体来看,主题的引导作用还是非常强的,参展企业全部聚焦大数据和智能化,大会持续数天,释放了重磅信息真可谓数不胜数,雷锋网为了让你尽快掌握行业新风...。

文字链接认证代码普通联盟标志认证代码企业广告联盟标志认证代码广告联盟评测代码说明,本页面的认证代码为新力广告联盟专用评测代码,站长需懂简单html知识,直接复制代码粘贴到联盟网站相应页面即可使用,本代码不适用于其他广告联盟网站请勿获取!文字认证,文字链接代码认证适用所有类型的广告联盟,复制代码后放在新力广告联盟网站首页底部或友情链接位...。

阳春白雪的东西变少了,烟火气变重了,这是今年与会者参加世界人工智能大会,WAIC,最直观的感受,阳春白雪,曾是AI最好的代名词,未来、颠覆、革命,烟火气,同样也是AI的最佳归宿,赋能、变现、IPO,人工智能其实自2019年起,就已经进入了停滞期,深度学习触顶,基础研究难突破,变现依赖硬件销售和项目总包……这一切,似乎与早些年创业者...。

在游戏圈谈到,黑神话,,有一个段子相当耐人寻味,2019年初,英雄互娱一行人抵达杭州,作为,天使投资人,,来视察注资一年多的游戏科学,这并不是一次简单的串门,游戏科学的未来,很大程度上将在这次行程上决定——彼时,上线一年多的,战争艺术,赤潮,,营收节节下滑,作为投资方和游戏发行方的英雄,已经将从游科撤资,纳入了议事日程,有知情者向雷峰...。
