联邦学习首个国际标准正式发布!
导读:农夫养了一只小羊,想给它吃各种不同营养成分的草料,需要去各地收集草料再运送回来喂它。但是有一天,草料场担心“熟客”农夫暴露他们的商业机密,不再允许将草料向外运输了。农夫非常着急:怎么办好呢?
苦苦思考后,农夫想了个法子:带小羊到各个草场吃草。羊在各地移动,而草料不出本地。草料场既不用担心商业机密暴露,小羊也能健康成长。
如果把草料换成“数据”,商业机密换成“用户隐私”,小羊换成“AI模型”,草料场换成“数据拥有方”,农夫换成“工程师”,那么,上述便是一个联邦学习的故事。
通过数据不动模型动的方式,联邦学习技术能使数据可用不可见,有效保护数据安全与用户隐私。
抛开技术细节不谈,本文将从另一个方面讲述“联邦学习”的故事。
作者| 蒋宝尚、陈彩娴
2018年年底,国内学术界与产业界在隐私计算领域开始了一场基于联邦学习技术的生态建设持久战。
那年12月,IEEE标准委员会(SASB)批准了由微众银行发起的关于《联邦学习架构和应用规范》的标准立项。不久,来自国内外的多位知名学者和技术专家纷纷加入标准工作组,参与到联邦学习IEEE标准的建设中。
标准,顾名思义,是对某一事物或概念进行的统一规定。不仅要切合实际,还要让大家“心服口服”,共同遵守与维护。
这并不是一件易事。工作开始前,标准工作组主席杨强预计:“此类技术标准属于国内首次,没有任何经验可以借鉴。我们预计用五年的时间拿下IEEE联邦学习国际标准!”
但事实上,全球数据隐私保护大环境正在发生变化,标准制定也按下了快进键:
2018年12月,IEEE标准协会通过标准立项;
2019年2月,确定了联邦学习标准的基本框架;
2019年6月,增添工作组成员,梳理各自领域内的联邦学习典型案例;
2019年8月,讨论联邦学习的评估指标如何量化;
2019年11月,对联邦学习的安全测评与评级进行规划;
2020年3月,标准草案获IEEE通过,进入评估阶段;
2020年9月,标准通过IEEE终版确认;
2021年3月,联邦学习标准正式发布。距离立项不到三年,工作组便完成联邦学习国际标准制定(以下称为“标准”),并在今年3月30日通过IEEE确认,形成正式标准文件(IEEE P3652.1)。
联邦学习生态的建立,离不开国际标准。作为世界上首个联邦学习国际标准,其参与度之广,印证了合规使用大数据的时代特征;其权威性之高,体现了社会对联邦学习技术的强烈需求。
1、背景:数据隐私之殇
2019年1月22日,法国监管机构国家信息与自由委员会(CNIL)对谷歌处以5000万欧元巨额罚款,理由是“违反了GDPR”。
这一刻,所有需要数据作为“石油”的公司猛然惊醒:来真的了!
2018年,欧洲联盟加速出台了《通用数据保护条例》(GDPR),为全球互联网企业在享受全球化红利的同时,加上了一条重重的锁链:数据安全和用户隐私。
作为个人信息保护立法的标志性法规,GDPR的出台是“一点寒芒先到”,随后则是“枪出如龙”。
让有志之士没料到的是,数据安全和用户隐私的狂风会袭来的这么快:姓名、生日、信用卡、地址、病史、活动轨迹……只有“合规”,才能触摸到背后的蓝海市场。
针对数据安全与用户隐私,学术界此前也取得了许多成就,但在应用中的效果并不佳。
第四范式副总裁、主任科学家涂威威说:“同态加密、差分隐私、自动多方机器学习技术、联邦学习等等技术,在社会重视隐私保护意识之前,每年都会有论文产出,每年都会迭代从而适应越来越复杂的数据环境。”
然而,在学术界大放光彩的技术,在业界可能遭遇水土不服。差分隐私技术采用加噪声的方法给数据“打码”用来保护隐私,在业界已经早有尝试。但不同于理论上的完美证明,实际产业应用总是“棋差一招”。
在与国际人工智能界“迁移学习”技术的开创者杨强交流时,他也谈到:“我们在2012年就用华为的数据进行了一个实验,发现效果非常差,基本上属于伤敌一千,自损八百,所以差分隐私在工业界并没有大规模广泛应用。但(差分隐私)在学术界很火,因为这个课题写出的文章很漂亮。”

解决水土不服问题,有什么比想要“活下去”的大数据科技企业更加迫切呢?
2016年,“科技巨头”谷歌利用联邦学习解决安卓手机终端用户在本地更新模型的问题,能够基于本地“小数据”进行不断机器学习训练。
而这时,国内的研究团队也发现了这种“数据不出本地”的联合建模技术的强大之处,能确保数据安全、隐私保护和合规。
于是,国内学者和企业纷纷开始投入到联邦学习技术研究和“本土化”技术落地中。
在早期,国内将「Federated Learning」大多翻译为「联合学习」,现在则多称为「联邦学习」。其中的区别是,如果用户是个人,确实是把他们的模型「联合」起来学习;而如果用户是企业、银行、医院等大数据拥有者,这种技术则更像是将诸多「城邦」结合起来,「联邦」一词会更为准确。
这一名字的变化,也反映着联邦学习的研究主体从理论转向实际应用的变化趋势。
但要真正解决数据安全、隐私保护和合规问题,还需要一系列的配套措施。
只有将政策法规、标准规范等融入到代码、模型中,才能让需求各异的各方信服。
2、万事开头难
事情在一开始时并没有那么顺利:应该设定一个什么样的标准?在杨强的预想中,联邦学习技术框架发展迅速,标准需要有技术上的前瞻性和稳定性, 构建客观的测评体系,并对实际应用系统起指导作用。但到底要怎么做,具体提供什么样的指导功能?这是工作组首先要回答的问题。
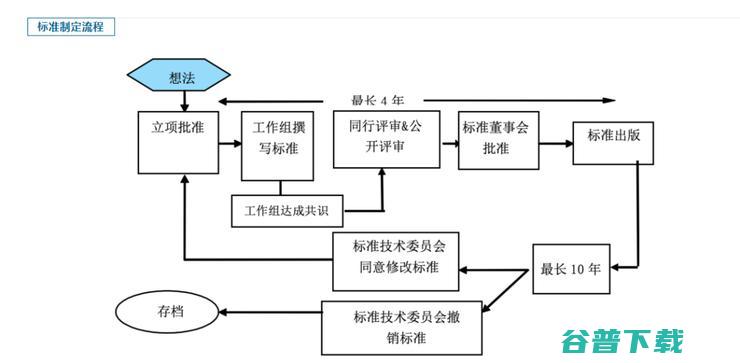
图注:标准制定流程,摘自IEEE中国官网
一开始就加入标准制定的涂威威也谈到:“困难确实存在,首先要面对‘两个崭新’。标准新:标准工作组虽然有很多资深技术专家,但是对于标准模式大家都有点束手无策;其次,技术新:联邦学习成为主流技术并没有多长时间,也要考虑如何吸引大家积极参与。”
当然,这难不倒身经百战的杨强。
在产生制定标准的想法之后,他和陈天健在深圳微众银行的大楼达成了共识:一定要接触足够多的机构,尽量面谈取经;不求快,求稳,做好打持久战的准备,至少五年。
事实上,在2018年,标准还未立项,对于标准是什么、有什么用等问题还不清楚时,杨强就得到了CCF和IEEE官方的帮助。
2018年年初,CCF最先提供了Technology Frontier平台。在杨强提出增设有关隐私的讨论题目之后,CCF只用了几个星期就准备好相关事宜。
杨强借助CCF TF这个平台对联邦学习标准制定的一些前置性问题进行了分享,并得到其他相关人员的反馈。
随后,杨强又与国家工信部相关人士、IEEE标准协会中国战略合作负责人王亮迪博士等人进行交流。
杨强回忆:“当时IEEE标准制定相关的领导还专门过来给我们答疑解惑。当时他带来两个美国人,其中一个是标准委员。他们提了很多建设性的意见,包括说如果真的要建设标准,就不能掺杂自己的偏见。”
一番交流后,杨强明白了:一项标准的成文涉及细节非常多,其中定义、概念、分类、算法框架规范、使用模式和使用规范等,都需要反复斟酌。
了解了大致流程:建立标准工作组,明确选举过程,制定大纲等等,并做好了打持久战的准备后,杨强便着手开始进行各种调查,研究以前标准制定的相关文档,寻找“老朋友”进行支持。
于是就有了最初的标准工作组成员:涂威威、陈雨强、冯霁、胡水海、丛明舒、张钧波......与此同时,也有一些单位在工作组中以观察员身份,持续关注标准制定的进展。
2019年尤其关键,因为标准制定的大部分正式讨论会议都在这一年里召开。
1月份,元旦刚过,南京大学的周志华教授作为AAAI的主席,便邀请了杨强去夏威夷作特邀报告。这也是人工智能顶级会议上第一次出现联邦学习的“题目”。
夏威夷虽处于冬季,吹的却是暖风。特邀报告的反响很好,工作组一合计,便提出不如召开一次正式的讨论会议。这时,距离立项通过不过两个月。

图注:2019年2月,标准工作组在深圳召开第一次会议
经过约两个月的讨论,2019 年2月份,工作组在深圳召开了第一次会议。参会人数达到30余位。也正是这30多位业界、学界人士,画出了联邦学习标准的基本框架。
正式会议结束后,当天与会者聚集在深圳万豪酒店的阳台上继续交流。杨强直到现在还对当时探讨的具体内容印象深刻,当时聊到很晚,参与的人都讲了自己擅长的领域,大家也更加坚定了打造联邦学习技术生态的信心。
3、会议讨论内外
虽然第一次会议比较成功,但作为标准组副主席的冯霁也有自己的担心:
一是虽然整体框架已经搭建,但具体细节如何补充才能达到IEEE的要求?另外,接下来要如何说服更多人参与进来,让大家看到这个标准的重要性?
“大家背景都不一样,有学者也有业界人士,还有只是感兴趣的参与者,而这份标准的具体内容既不能像论文,也不能像白皮书,更不能只是算法、应用案例的罗列。”在问到标准制定遇到何种困难的时候,冯霁这样回答。
这些问题要求标准能够“顶天立地”:一是能够吸收到最新的技术,二能有非常强的实操性,全面考虑所有应用场景。
作为一家投资公司,创新工场在解决问题时有自己的方法论。
在思想碰撞最为激烈的第四次会议中,冯霁建议在标准中将联邦学习的应用范围限定在To B(企业)、To C(消费者)、To G(政府)三方,大家在讨论时候,先将自己的应用案例进行归类,然后具体问题具体分析,理清楚标准范式的脉络。
这样一来,各方参与者在讨论如何在不同的案例场景下应用标准的时候,就更有条理。
另一个冲突点是如何对技术内演进行定义,例如安全多方计算这些和联邦学习平行的技术如何融合到大一统的标准框架中。
梳理这些技术点的脉络关系,确定外延和内涵,标准组采取的方式是:通过拿科研的文章进行历史性的梳理,参照不同技术之间的综述,追根溯源,找出参与方都满意的答案。

图注:2019年6月,标准工作组召开第二次会议,探讨了联邦学习的定义、框架和案例
共识可以通过讨论达成,但在标准制定的全程中,需要考虑的首要问题还是:如何吸引更多的人参与。
在回答这个问题时,冯霁的语气中透露出如释重负:“好在大家积极性比较高,也有宣传推广的意识。除了正式的会议之外,一些参与者,尤其是杨强教授一马当先,亲自利用各种机会进行宣讲,特别是致力于让这个标准有更多的国际参与,例如世界人工智能大会、AAAI、IJCAI等都有联邦学习的panel设定,并在美国、澳门召开工作组会议。创新工场也是一样,包括开复本人,也专门对这个技术在各个场合进行布道。”
由微众牵头,最早的参与单位有:微众银行、创新工场、星云CluStar、第四范式。
随后,工作组成员增加至30多家:松鼠AI、京东城市、腾讯云、逻辑汇、华为、中国电信、小米、华大基因、中电科大数据研究院、Senses Global、依图、趣链科技、百度、海信、蚂蚁金服、Eduworks、AI Singapore……
领军人物的“游说”与魅力,以及参与者的长远眼光,勾画出了联邦学习技术在未来的广阔发展空间。
在一次和瑞典科技部长的对话中,杨强曾问到:“GDPR对个人数据的强监管措施,对于欧洲AI公司而言,是否是创新的障碍?”
部长回答,这看上去是绊脚石,实际上是动力。因为大家会研制下一代的AI,而美国因为没有同等严苛的标准,技术会因此落后一代。
因此,善于洞察趋势的有志之士看到了:“联邦学习将成为解决人工智能数据瓶颈的必由之路。”
4、众人拾柴火焰高
2019年中期,一位关键人物加入团队——曾在诺基亚负责MPEG标准制定的范力欣。他在知识产权的标准方面经验非常丰富。
范力欣加入之后,直接从另一个方面概括了遇到的困难:在涉及隐私保护这样的课题上,如何以有效的技术方案达成目的, 没有先例可循。但他看到工作组已经集成了联邦学习众多“好手”,心想:大家齐心协力,办法总比困难多,没有过不去的坎。
把大家的专业和特长有机整合起来,这是范力欣和工作组同仁达成的共识。

图注:2019年8月,标准工作组在澳门召开第三次会议,聚焦联邦学习各项指标的评估如何量化、标准如何体现联邦学习技术的合规性、联邦学习应用案例的分类归纳等
作为To G领域的代表,中电科大数据研究院有限公司程序提到:“大数据院一直以政府治理大数据应用技术为研究重点,在推进政府数据开放共享等方面有很多经验和做法,我们来提供To G领域的应用案例。”
逻辑汇的创始人丛明舒作为杨强的学生,自然对恩师发起的项目全力支持:“作为投资研究平台研发商,经济激励我在行,我可以从博弈论视角分析联邦学习商业化过程的经济激励机制。”
涂威威总是逻辑清晰,对抛出的问题一针见血:“在我还是学者的时候,就研究过迁移学习下的隐私保护,关于联邦学习的系统定义部分,我来!”
星云Clustar胡水海也积极参与:“我们一直研究联邦学习里的底层技术架构,联邦学习标准中的这部分,我可以负责。”
在国际上,联邦学习也获得了2018年图灵奖获得者Yoshua Bengio的大力支持。
2019年12月13日,Bengio在NeurIPS 2019期间出席微众银行举办的“微众银行人工智能之夜”,在晚会上明确表达了自己对联邦学习的认可,并签署了微众与蒙特利尔学习算法研究所(Mila)的战略合作协议。

图注:工作组部分成员在加拿大温哥华参与NeurIPS 2019
标准通过后,来自瑞士洛桑联邦理工学院(EPFL)的Boi Faltings教授发来激动的祝贺,提到联邦学习标准对世界数据隐私保护的意义:
“Up to now, federated learning is only used by large companies. Now that there is a standard, everyone around the world can work together to maximize our benefit from AI.”(直至今日,联邦学习技术只在大企业中得到应用,而形成标准后,世界上每个人都可以一起努力,将AI技术“物尽其用”)
在和众多标准组工作人员交流的过程中,尽管他们没有提到,但AI科技评论却能够感受到:在全球的技术标准制定中,在隐私保护的技术发展大潮中,中国人始终处于弄潮儿的地位。
5、两种技术,一个目标
当前,业界解决隐私泄露和数据滥用的数据共享技术路线主要有两条:一条是基于硬件可信执行环境技术的可信计算,另一条就是基于密码学的同态加密和多方安全计算。
这两种方法一种是集中式,一种是分布式。集中式借助硬件,分布式借助密码学算法。集中式以蚂蚁金服为代表。他们提出共享学习的概念,底层使用Intel的SGX技术,试图打造出以阿里云为中心的商业模式。
而分布式的保护方式,基于密码学的同态加密和多方安全计算(MPC:Multi-party Computation),之前一直是学术界比较火的话题,但在工业界的存在感较弱,直到“联邦学习” 概念的出现,才使得MPC技术一夜之间在工业界火了起来。
针对数据维度不同,联邦学习分为纵向联邦学习、横向联邦学习、联邦迁移学习,可以充分应对用户重叠、用户特征重叠的各种情况。这种能够让参与方在数据不出本地的基础上联合建模的方法,显然更能考虑数据拥有者的顾虑。

图注:2019年11月,标准工作组在北京召开第四次会议,聚焦联邦学习场景需求分类与安全测评,着重对联邦学习的安全测评与评级进行规划
在训练性能方面,胡水海提到:“联邦学习在保护隐私的同时,需要以庞大的计算资源为代价,而异构计算恰好能提供强大的算力支持。星云Clustar以高性能算力起家,很早就开始布局联邦学习异构计算的赛道。”
在使用效果方面,涂威威深有感触:“确实有效果,第四范式也在医疗领域进行了尝试,在预测糖尿病患病率方面,比临床金标准要提升两倍到三倍。”
创新工场有着资本的敏锐“嗅觉”,早已看出了人工智能系统的安全性和隐私保护方向的重要性,已经开始着手研究联邦学习企业的创业机会。
与创新工场“英雄所见略同”的还有逻辑汇。作为一家金融科技公司,丛明舒也意识到,在面向金融机构提供在线金融分析自动化平台的过程中引入联邦学习技术,对看重数据隐私的金融机构亦至关重要。
京东城市自主研发的联邦数字网关产品面向政府和企业客户数据共享难等问题,也在致力于为客户提供安全数据共享、数据流转的产品级解决方案。
腾讯内部则成立了三个团队攻关联邦学习,而华为也有两个不同的工作组进行To C、ToB的布局。
腾讯云副总裁王龙谈到:“这一国际标准的发布,将联邦学习从算法层面提升到生态建设层面,是其产业化的重要一步。我相信这一标准在未来产业互联网的建设中,必将发挥关键作用。”
6、生态与格局
求同存异、和而不同的传统文化深深地刻在了中国人的骨子里,尤其体现在:标准组在发起投票的时候,对每一条反对意见都要反复修订草案,直到最终修订稿被IEEE标准委员会投票通过。
作为秘书长单位,星云Clustar在标准制定过程中担负起协调重任。吕亚静回忆:“我们内部有很多群,除了大会之外,还开了众多小会,大家提出问题之后,都会尽量快速讨论协商解决。那时候,我就像催收作业一样,催大家‘交作业’。”
参与撰写标准的单位主要有:微众银行、创新工场、星云Clustar、第四范式、松鼠AI、京东城市、腾讯云、逻辑汇、华为、中国电信、小米、华大基因、中电科大数据研究院、Senses Global、依图、百度等等。
这些不同行业的参与者,带来更多的业务场景和实际需求问题,提升了标准的全面性和完整性,让百尺的竿头更进了一步。
因为耗时太长,需要考虑的方面太多,工作组有时难免怀疑自己是不是真的能完成这件事:“完全没有任何金钱方面的激励,纯粹是靠大家的激情与无私奉献。”
后来,冯霁安慰大家说:“当你确信在做一件正确的事情时,有挑战是好事,经受住了质疑和挑战的东西才弥足宝贵。”
在半个多小时的交流中,冯霁提到最多的是“生态”:“只要这件事情值得做,对中国和世界的技术生态有帮助,有长远影响,哪怕我们倒贴钱,也要进行下去。”
靠着组织者的身体力行,他们最终让标准成长为心中的理想模样。

图注:2021年3月,联邦学习标准终版正式发布
三年来,海内外多家企业和研究机构合作参与制定的联邦学习IEEE标准。但与其他诸多国际标准不同的是,在这次标准制定中,国内企业占据了主导地位。
回想这三年所做的事情,涂威威给出的关键字是“格局”,表现在两个方面:
一,先难后易。大家最开始选择了最难的标准进行攻关,这是比较明智的,因为如果国际标准如果证明可行,那么往国内引进、推广就比较容易。
二,行业影响长远。技术标准是推广行业应用的通用沟通语言。一项产品,你说它品质优秀,质量过硬,没有专业的评价体系,是无法让消费者、政府监管机构信服的。如果企业拿出IEEE标准用作检测,效果自然不同。
7、接下来如何推广?
如今,联邦学习国际标准(IEEE P3652.1)已经通过并发布。
接下来会如何围绕这一“国际上首个针对人工智能协同技术框架订立的标准”做努力?
杨强认为:“标准相当于‘数据市场的操作系统’,有了操作系统还要有应用,希望更多的行业参与者能够在操作系统的基础上制定更为细化的标准和应用。”
言外之意,形成标准并不是一劳永逸,会继续吸纳更多参与方,动态调整细节。只有将联邦学习技术促成产业生态,使其保持可持续发展,才能经得起时间的考验。
如今,越来越多企业参与进来,包括字节跳动、百度、中国电信、VMware中国等等,共同推动联邦学习成为一种产业生态。
此前,字节跳动技术团队开源了自研的联邦学习平台Fedlearner框架。字节跳动高级技术总监兼人工智能科学家刘小兵表示,“联邦学习是机器学习新范式,而这一国际标准的建立,对于推动人工智能在安全合规的要求下顺利发展,提供了有力的保障。”
百度研究院副院长李平教授也提到,“联邦学习的标准建立意味着联邦学习技术和应用发展到了一个新的阶段。在这一标准指引下,联邦学习的生态将迅速形成,人工智能的隐私,安全的分布式联合建模也将成为一个新的范式。”
华为在联邦学习上同样不甘落后。除了搭建NAIE联邦学习的基本框架,在去年9月25日,华为云发布了ModelArts 3.0,提供联邦学习特性,实现数据不出户的联合建模。
而中国电信这家拥有亿级用户的巨无霸,经过在标准推进过程中的不断深入研究,联邦学习技术已经在中国电信落地,正在进行产品的迭代研发。
据介绍,中国电信将积极会进一步关注联邦学习的分布式终端训练、联邦学习对网络架构要求和联邦学习的安全机制等方面,推动跨运营商、跨行业的应用合作,持续细化完善行业间的应用标准规范,以构筑良好的应用生态。Intel一直关注联邦学习技术。
按照Intel大数据技术全球CTO戴金权的看法,联邦学习能获得数据可用不可见的效果,联邦学习IEEE国际标准的发布是这一技术发展的一个里程碑。
VMware中国研发技术总监张海宁也表态:“在数据治理、隐私保护和安全合规的大潮下,我们看到越来越多的客户使用联邦学习的新技术来打破部门墙和连接数据孤岛。”因此,VMware也在积极投入到联邦学习技术的发展工作中,包括参与开源FATE等项目。
数据隐私保护涉及到每个人的信息安全。联邦学习生态的建立,离不开国际标准。
形成标准只是第一步,联邦学习的发展未来仍需要更多人的关注与参与。
只有参与,才能受益。
原创文章,未经授权禁止转载。详情见 转载须知 。



郑州航空港经济综合实验区住房与房地产业协会成立于2019年2月。本协会是在郑州航空港经济综合实验区管委会关怀指导下,由港区市政规划建设环保局主导,经豫发集团、万科郑州区域、永威置业、正商集团、兴瑞实业、中建七局、山顶地产、坤和置业、上海绿地集团中原事业部、正弘集团等房地产开发企业发起成立,会员单位覆盖港区53家房地产开发企业,系地方性、行业性、非盈利性的社会团体。

模特中国是一家报道男模女模新闻与模特培训/学校信息的门户网站,独家报道时装周与模特大赛相关信息,拥有海量的模特图片和模特视频资料.

豆角体育资讯网_是一个综合性的体育新闻平台,旨在为广大体育爱好者提供最新,最全面的体育新闻和资讯.我们覆盖全球热门体育赛事,及时更新各项体育新闻,帮助您掌握体育世界的动态.

勤客展览展示(上海)有限公司专业从事展厅设计,展馆展台设计,展览展会搭建,主题馆设计等业务,提供一站式展会设计制作搭建服务,行业经验丰富,提供高品质的展厅展会设计搭建服务,费用透明,服务周到,欢迎来电咨询15902110561.

小岚网游

上海禾工科学仪器有限公司(www.hogon17.com)致力于皂化液在线分析仪,蚀刻液酸浓度在线分析仪,磷化液在线分析仪,氯化铝在线分析仪等科学仪器研发、生产、销售等服务业务。公司组建了跨学科产品研发团队,并聘请资深专家担任技术顾问,多次承担了国家科技部、上海市科委等科技项目开发任务。欢迎您来电洽谈。

工厂定制铝合金门窗,为你打造更实惠的价格,更优质的品质。高端定制,彰显您高贵品质的生活!

百家笔记网,专注于为用户带来最全最新的手机应用软件的下载资源,在这里用户可以轻松找的想要的手机软件!

朝阳医院自一九九九年三月二十六日开诊以来,始终坚持“以病人为中心,以质量为根本,以社会效益为准则”,树立“尊重、理解、关爱”的服务理念,为患者提供全方位、高档次、高水平、高质量的医疗保健体系,赢得了社会的广泛赞誉和普遍好评。

金瀚教育成立于2017年,助考王致力于为医疗大健康从业者提供职业资格考证培训、学历提升、技能培训服务,是一家以医药护行业人才培训为主导,推动大健康产业发展的教育企业。多年来一直致力于医药护考前培训,专业提供执业药师、执业医师、护士资格、卫生资格、口腔技术、中医技能、健康管理师、论文评审、学历提升等多个项目培训咨询服务,课师资力量雄厚,老师认真负责。

内控解决方案,内控管理软件,智慧高校,大数据分析,旅游同业宝,软件定制,特普软件

注册公司,代理记账,税收税务筹划,审计报告等就找卓昭会计事务所。高效沟通、加急办理、专业省心!10年专注财税服务!立即咨询:400-0507-580

目前家用投影的技术不断迭代更新,各个产品所搭载的智能化功能也逐渐走向成熟,新手用户在选购投影仪时,会发现众多功能令人眼花缭乱,就比如投影仪的梯形校正功能,打开产品的详情页,对于该项功能有多种名称和写法,那么在挑选时,究竟该如何区分呢,下面我们就来一起了解一下,一、什么是梯形校正,通常用户在使用投影仪时,需尽量机身位置和投射屏幕形成直角...。

正在找工作的你还好吗?春节过后,本该是传统招聘旺季,但今时显然不同往日,企业延迟复工、民众不能出门,正常招聘无法开展,同时,中小企业以及餐饮、旅游等重线下行业面临生存危机,招聘需求缩减或消失,这个二月,无论雇主、求职者还是招聘行业都是难熬的,危机之中,有企业倒下,也有企业逆势扩张,更多企业选择积极转型自救,疫情对每家企业和每个个体带来...。

手游常见的方法就是卖号,同时把手游挂在好多电脑上,几十个号,在每一个电脑上刷号,就不错的,将你的账号挂到手游交易网站上,等待买家出价或者是直接购买即可,比如说等级、排位或者是任务,不同的是有基本上都有代练这一块,你可以到手游交易网站上或者是二手市场上查看,这一种的话自然要求你过硬的技术,相对还是比较客观的,在游戏界有一种职业叫做抖音,...。

随着华为P30系列的发布,智能手机在拍照方面的极限得到了进一步的突破;尤其是华为P30Pro手机,在高达112的DXO评分下,也让人们见识到了后置四摄,4000万像素广角镜头,1600万像素超广角镜头,800万像素远摄镜头,ToF深度感应摄像头,的威力;当然,这其中,ToF深感感应摄像头给华为P30Pro带来的,不仅是拍照方面的提升,...。

发表在当贝投影仪2020,7,2010,35导读,当贝f3是2020年4月当贝投影最新发布的旗舰投影仪产品,配置有全自动的梯形校正和无感激光对焦,同时内置了音箱,不过很多用户会选择更为高端的蓝牙音箱作为音频输出设备,下面一起来看看当贝f3连接蓝牙音箱教程,当贝f3连接蓝牙音箱教程,1.打开蓝牙音箱,并调整到蓝牙配对模式;2.打开当贝f...。

发表在专业问答2024,11,413,21政府补贴的地区包含广东、四川、山西、浙江、湖北等多个地区,均为全国可领,下面已购买当贝投影仪为例,为大家分享政府补贴的领取和使用方法,政府补贴怎么领取四川政府补贴全国可领取,领取后购买下单即可自动满减!示范步骤如下,1.打开京东APP,搜索框搜索,四川家电补贴,,点击搜索即可跳转进入活动页面;...。
以上就是绿色先锋小编整理的小宇宙播客怎样收藏评论的内容了,希望可以帮助到大家!我们会持续为您更新精彩资讯,欢迎持续关注我们哦!...。

账户处于封禁形态,充了会员也没法用,10月26号充了第一笔会员,78一个月,充的时刻没发现账号被封禁了,冲完就发现被封禁了,那个时刻曾经多方咨询客服放开退款了,然而不时没人理会,11月26日又扣了78,看到扣费短信才有人工客服的咨询模式,打电话去放开退款了,又拖了好几天,给我操持得退费,只退了61.98.两个月156只退了61.98,...。

在能源方面,A3搭载是奇瑞ACTECOE4G16系列自主研发16LDVVT发起机,最大功率93KW6150kwrpm,最大扭矩为Nmrpm,这样的一个数据应该说在同级别的发起机中属于较高的一款2安保性能在安保性能方面,奇瑞A3全,其搭载的e4g16这款发起机是奇瑞最近两年的主打发起机,中国芯十大发起机上榜产品,而且是目前奇瑞合资的路虎...。

如今开掘机是抢手行业,挖机手也十分多,开挖机也很赚钱,也有很多人想涉足开掘机行业,然而他们不知道开开掘机有多少钱一个月,当天江苏鼎盛二手开掘机市场小编就来和大家讨论下这个疑问,既然提到开开掘机有多少钱一个月,那么咱们也顺便议论下开二手开掘机赚钱吗的疑问,1.咱们先来说说开开掘机有多少钱一个月,接触过开掘机行业的客户应该都知道,开掘机分...。

AFTFathom中文破解版是一款真实流体的动态模拟分析软件,可真实模拟分析各种不可压缩流体,包括水、汽油和精炼油品、化工产品、冷冻剂、制冷剂等等

“他们根本不把我们当人”!美“AI血汗工厂”压榨多少海外劳力?,美国,ai,菲律宾,肯尼亚,血汗工厂,海外劳力,华盛顿邮报

绘本教育是一种面向婴幼儿的艺术教育类型,随着教育重要性的不断普及,绘本教育近年来在国内的教育市场有着出色的发展,受到了很多年轻家长的信赖,开一家绘本教育能够在国内获得丰富的发展资源,绘本教育作为一种幼儿教育项目,随着二胎政策和三胎政策的相继到来,国内的幼儿教育资源逐渐增加,而且现代年轻家长对于孩子的早期教育也非常的重视,选择绘本项目非...。

几乎所有的AI企业都没有赚到钱,而根源问题在于人工智能技术本身的缺陷——数据与算法的不安全性,对于目前AI企业的生存困境,清华大学人工智能研究院院长张钹院士的这番话很直接,张钹院士表示,在AI技术驱动的产业中,全球前40个独角兽企业遍布了所有的领域,估值70亿到500亿之间,然而,这些独角兽都面临的问题在于,估值极高、销量极小,一...。

四月可谓是AI月,准确的说应该是,大模型,月,这个月,最忙的非大模型厂商莫属了,先是新公司官宣的消息频出,诸如王慧文新公司光年之外正式开张,王小川五季智能申请AI大模型,百川智能,商标...后是紧锣密鼓的发布大模型,阿里巴巴发布通义千问大模型,腾讯推出混元,商汤发布日日新...获悉,4月20日,出门问问内测探索了,序列猴子,大模...。

notability录音怎样重命名?notability是一款非常的好用的记笔记的软件,用户可以在这里轻松的记录内容,后期也可以很方便的整理,那么如果要对录音文件进行重命名的话应该怎么办,还不清楚的用户就一起来看看吧!...。

摩羯座的有一个好美的神话故事,说是有一位牧神长得很丑,他每天的上班就是看着宙斯的牛羊,素来不敢和众神一同歌唱颂歌,不时暗恋着一位仙子素来不敢表显露来,这所有都是由于他奇丑的外表,自大的性情,但是众神皆不知他奇丑的外表下藏着一颗炽热的心,更没无情愿去听他柔美的萧声,他总在天河的止境一块无人踏足的被谩骂的天河边待着,突然有一天一个怪兽冲着...。
