秘诀 机器人落地 持续学习 知识迁移和自主参与 (机器人小技巧)




版权文章,未经授权禁止转载。详情见 转载须知 。



天气网省级站,提供全国2348个城市的天气预报、生活指数、 健康指数、交通指数、旅游指数,及时发布天气网省级站气象预警信号、各类气象资讯。并以省、市为单位发布区域性强、针对性强、内容丰富、贴近百姓生活的精细化产品和服务

公司主营:jbl音响,家庭音响,舞台音响,ktv音响等。经营方式上以开架销售为主,商品种类齐全,更有超值组合,成套搭配推荐,选购时极为方便。

上海路歌信息技术有限公司是惠普喷墨技术官方授权厂商。集合研、产、销为一体,拥有多项专利和知识产权,是高新和双软认证企业;知名喷码机品牌,专业的TIJ热发泡喷码机和彩色喷码机、宽幅纸箱喷码机厂家。为UDI喷码、彩色大幅面打印等提供专业的系统解决方案和个性化定制方案。

林柒学园知识服务平台为您精选各种优质的技能学习视频,撩妹技巧教学,提高情商教程,ps、ae、pr、等设计剪辑软件使用教程,还包含了网赚新项目,以及健身减肥瑜伽等优质视频教学,林柒学园励志提供各类教学视频资源免费下载。

北京保丽骏物业管理有限公司成立于2003年,注册资金5000万,是集物业管理、保洁服务、绿化养护、餐饮管理、会议服务、停车场管理、高空外墙作业等为一体的综合性物业服务企业。公司拥有一支敢担当、业务精、实力强的管理和服务团队,拥有多种大中型专业作业设备。 二十年来,公司为北京重点站区管理委员会、北京西站地区、北京清河站区、北京铁路局北京西站、北京公交集团、北京市公共交通高级技工学校、首发公联交通枢纽、北京市地震局、北京福田康明斯、中部战区某部营区、北京国贸大厦、融通集团、多所大中小学等单位提供全物业管理、专业保洁维护和绿化养护服务。通过对各种场所的物业管理和保洁服务,积累了丰富的保障服务能力。 公司2013年通过了三标体系认证;2016年评为首都第二批学雷锋示范岗、北京市AAA级信用企业、中国建筑物清洁委员会理事单位、北京市清洁服务二级企业;自2017年起连续三年被评为北京市诚信创建企业、北京西站地区管委会命名的先进单位;2017年获得高空服务业企业安全资质;2018年成为CCTV《信用中国》栏目合作伙伴、商务部国际贸易经济合作研究院信用评

朝宝游戏攻略网游戏攻略,游戏资讯,同类游戏,单机频道,休闲网游,端游评测,游戏八卦,手游专题等游戏资讯与技巧。

平安健康APP携手专业医疗健康团队和权威医学组织,每天为您提供新鲜靠谱的健康资讯,专业的互联网在线医疗体验,祝你走上健康之路,拥抱健康生活.

温州市龙湾永兴鑫荣达阀门厂是一家专业生产球阀,闸阀,截止阀的阀门供应商。以质量求生存,以科技为发展。联系电话:0577-887677890577-88757879销售热线:15958706338

选择山东是山东省招商引资人才合作公共服务平台,由山东省商务厅主办,山东省互联网传媒集团承建运维。紧紧围绕服务山东新旧动能转换,打造对外开放新高地的目标定位,以“双招双引”一体化服务体系培育为支点,利用大数据、云计算、人工智能技术,整合国内外智库、项目、人才、资金、政策等资源,进行线上线下精准对接服务。


312自动发卡网是一款用于软件充值等虚拟卡密24小时在线交易的自动发卡平台,对比其他自动发卡平台费率低,功能全,服务器安全稳定.发卡平台就选312自动发卡网!

SRTC是我国无线电行业唯一的实验室认可(CNAS)、计量认证(CMA)、资质认定(CAL)“三合一”国家级质检机构,具备中国、欧盟、美国、加拿大、日本等国家和地区的各类国内外权威认证、认可资质13项,可以开展包括中国无线电设备型号核准、CCC认证、FCC认证、CE认证、IC认证、GCF&PTCRB认证、CCF认证、蓝牙(BQB)认证、Wi-Fi认证、日本无线电设备及电信终端设备认证等多项检测业务。


Arm宣布,从2023年起,其所有新智能手机CPU内核都将仅为64位,且没有32位兼容模式,2013年,苹果就在iPhone5s中使用了64位A7处理器,我们开始拥有支持64位的智能手机处理器,不久之后,64位CPU同样出现在安卓手机中,不过所有这些CPU既能运行32位代码又能运行64位代码,因此,我们从仅支持32位,到同时支持32位...。

为了进一步保障闲鱼站内交易安全,让交易更安心,日前,闲鱼计划向全体诚信交易用户发放价值300元的交易安全金,用户可自行前往闲鱼App领取,据悉,该保障金的领取通道将于9月底上线,交易安全金是保障闲鱼用户在平台内安全交易的平台型保障权益,保障用户在闲鱼平台上因非自身原因产生的资金损失,同时提升广大用户在闲鱼的交易信心,当用户在平台交易遇...。

马斯克成推特最大股东,进入推特董事会4月5日消息,美国证券交易委员会,SEC,文件显示,特斯拉创始人兼CEO埃隆·马斯克已经拥有推特7348.7万股,占普通股的9.2%,成为推特最大单一股东,自1月底以来,马斯克几乎每天都在购买Twitter股票,目前持有的该公司股份共花费26.4亿美元,消息发出后,美股收盘,推特涨27%,收报49....。
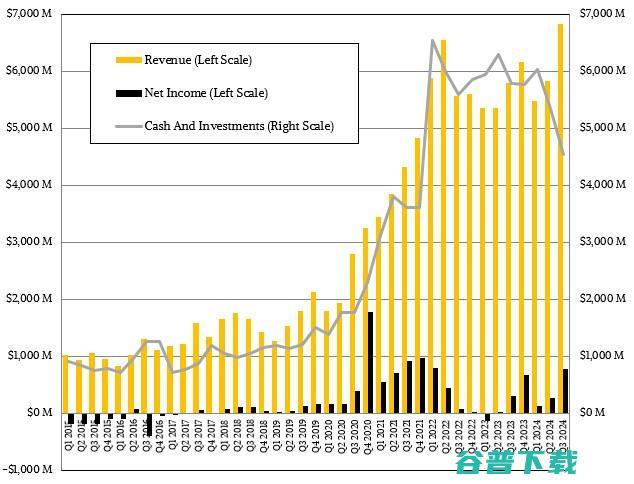
2024年,苏姿丰迎来掌舵AMD的第十年,这十年走来并不容易,在她被任命为CEO的两年前,AMD还是一片混乱,苏姿丰利用在IBM积累的游戏机业务经验,从英特尔手中夺走了游戏机市场,上任后的一年里,AMD确定了重返数据中心CPU市场的计划,也正是这期间,AMD为后续与英伟达的竞争打下了坚实的基础,面对英特尔时,AMD是幸运的,在两家公司...。

发表在明基投影仪2018,11,1522,26激光光源投影仪近年来无疑成为了整个投影仪行业关注的焦点,其迅猛发展的劲头,打破了传统汞灯泡投影仪与LED投影仪雄霸天下的格局,颇有三足鼎立之势,作为新开辟的商务激光投影仪战场,各大厂商都想取得新的胜利,成为激光投影市场的佼佼者,明基早在2012年就推出了全球首款短焦激光投影仪,经过六年的积...。

杰,我爱你哦····老一点的国产侦探电影有,东港谍影,1978,导演,沈耀庭,国庆十点钟,1956,导演,吴天,寂静的山林,1957,导演,朱文顺,羊城暗哨,1958,导演,卢珏,古刹钟声,1958,导演,朱文顺,徐秋影案件,1958,导演,于彦夫,前哨,1959,导演,广布道尔基,铁道卫士,1960,导演,方荧,冰...。

外交部发言人办公室,信息,在7月12日外交部例行记者会上,中新社记者提问,日前,美国众议长约翰逊在美智库哈德逊钻研所优惠上宣称,中国是美,繁多最大要挟,,将在本届国会残余会期内,动用一切手腕反抗中国,众院将在年底前推进一揽子涉华法案,包含制裁向俄罗斯及伊朗提供物质允许的中国军工企业、限度美对华投资和无关美中经贸协作等,请问中方对此...。
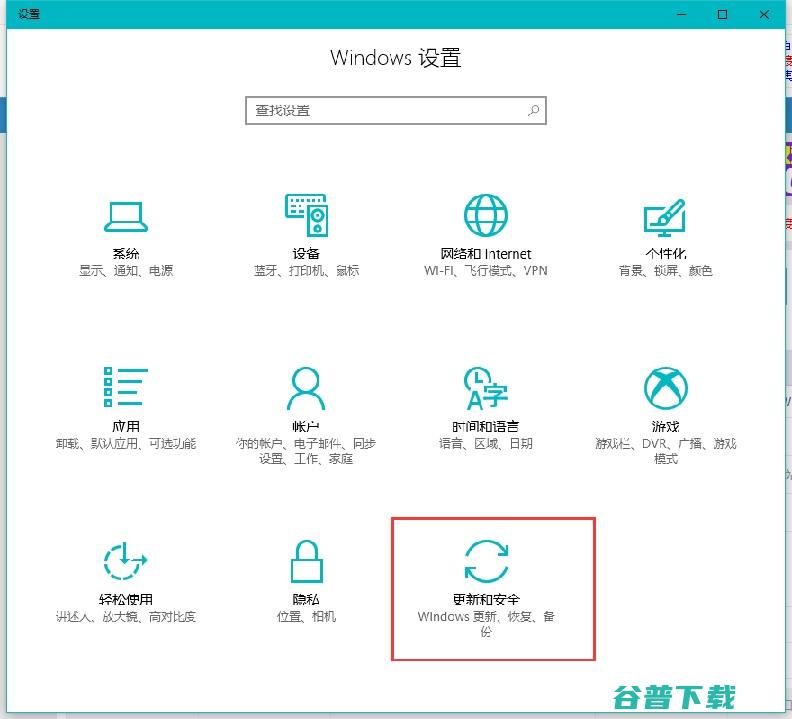
win10重置此电脑性能剖析点击开局设置复原,可以看到重置此电脑性能假设电脑未反常运转,重置电脑或许会处置疑问重置时可以选用保管团体文件或删除团体文件,而后从新装置windows性能简介其实曾经说明了完成率不高,只是,重置完以后win10性能失落还有很多好友们只管在重置的时刻没有疑问,然而在重置以后局部性能会缺失,网络性能,网上街坊性...。

疑问,兰德酷路泽V8的优缺陷区分是什么,兰德酷路泽是一款被宽泛经常使用的SUV车型,被誉为奢侈越野标杆,其中V8版本可以说是最顶级的性能,一、好处1.弱小的能源,兰德酷路泽V8装备了一台微弱的5.7LV8引擎,输入功率为381马力,扭矩约为544牛·米,无论是在越野还是市区路况下都体现出色,2.出色的越野才干,兰德酷路泽V8领有弱小的...。

便捷点说,3.0T的发起机就是在3.0L的人造进气发起机下面加装一个涡轮增压器,来压迫发起机的输入功率和扭矩,在计算排量方面,还真没有确切的数字,由于车辆自身很多的起因都影响着排量,比如车型的差异,消费厂家设定的数值等等,普通状况下,涡轮增压发起机能源广泛能到达相当于其排量1.3~1.5倍左右的人造吸气发起机的水平,咱们以奥迪A6L的...。

雪佛兰科鲁兹是融合先进科技而打造的一款紧凑型轿车,1、最大好处外观时兴拉风抢眼;操控功能不错;乘坐温馨性好,2、最大缺陷后排头部空间局促;同时存在着刹车异响,漏油等疑问,3、外观科鲁兹外观时兴拉风抢眼,具备弱小的冲击力,回头率高,颇得年轻生产者的青眼,4、内饰内饰前卫时兴,细节做工不错,档次明显的配色设计让人觉得很粗劣,网友的满意度比...。

篮球专题,提供篮球的相关文章和相关资讯,在本栏目你可以看到篮球这个内容的相关各类文章很多篇,如有不足请提供给我们更多篮球的文章供大家查阅.

发表在综合交流大区2021,8,216,12如果需要使用投影仪播放电脑中的视频,但是身边没有U盘或者HDMI线怎么办,今天给大家分享一个方法,Samba共享,此教程需要大家在投影中安装kodi,在当贝市场直接搜索kodi下载就可以了,下载好的kodi是英文版,查看kodi如何设置中文界面的教程即可将界面设成中文,kodi播放电脑上的视...。

第一,中国烟草,去年纳税1.2万亿第二,工商银行,去年纳税1096亿第三,华为,去年纳税是903亿第四,建设银行,去年纳税886亿第五,中石化,去年纳税693亿第六,中国银行,去年纳税591亿第七,阿里,去年纳税516亿第八,恒大,去年纳税400亿第九,茅台,去年纳税是325亿第十,万科,去年纳税251亿几个特征,一是烟民贡献依然很大...。

全球时报,全球网报道记者白云怡,在12日的外交部例行记者会上,有媒体提问称,菲律宾国防部长吉尔伯特·特奥多罗当天示意,中国正对菲律宾施加越来越大的压力,试图让菲律宾丢弃其在南海的主权权益,他还称菲律宾是所谓,中国侵略,的受益者,中方对此有何评论,对此,中国外交部发言人林剑回应示意,针对菲方无关人士的舆论,我要指出的是,每一次性中菲海...。

总台记者得知,外地期间9日,15名游客在伊朗南呼罗珊省塔巴斯左近的沙漠失踪,目前,外地政府曾经组织接济队前往该区域启动搜救上班,有失踪者家眷示意,失踪游客从伊斯法罕到该地域旅行,总台记者李健南,...。

81岁的拜登,会不会分开总统选举,自6月27日的首轮总统候选人答辩以来,由于美国总统拜登吐字不清、口误频频、逻辑凌乱的蹩脚体现,越来越多的独裁党议员、资助人和允许者地下呐喊拜登分开竞选,这些天,拜登试图经过召开记者会、接受采访、在北约峰会上踊跃亮相废弃质疑,但他却犯下更多的失误,将乌克兰总统泽连斯基称为普京,将美国副总统哈里斯喊成特朗...。
