大数据系统软件助力工业数字化转型 清华大学王建民 (大数据系统软件国家工程中心)
AIoT 融合落地方兴未艾,工业制造智能转型迫在眉睫。
为了构建行业对 AIoT 产业的全新认知,解析 AIoT 泛产业的 “云、管、边、端” 及智能制造产业的发展,探讨当下 AIoT 行业落地困境及工业互联网发展思路,2019 年 11 月 22 日,全球 AIoT 产业· 智能制造峰会在深圳隆重举行,本次会议由雷锋网主办,由深圳市软件行业协会、深圳市大数据产业协会、深圳市人工智能学会、深圳市人工智能行业协会作为支持单位。
在下午的工业数字化转型论坛,清华大学软件学院院长、信息学院副院长、大数据研究中心执行主任王建民首先带来《大数据系统软件助力工业数字化转型》的学术报告。他从工业数字化转型、大数据系统软件工程、制造业大数据应用三部分进行报告,在第一部分,王建民院长介绍了工业制造的发展必由之路,并指出工业数字化转型核心目标是人和装备之间的有机融合。接下来他在第二部分介绍了大数据软件技术,目标是能够挖掘大数据的四个内涵。第三部分分享了一些工业大数据的实际应用。

清华大学软件学院院长、信息学院副院长、大数据研究中心执行主任王建民
以下为演讲实录:
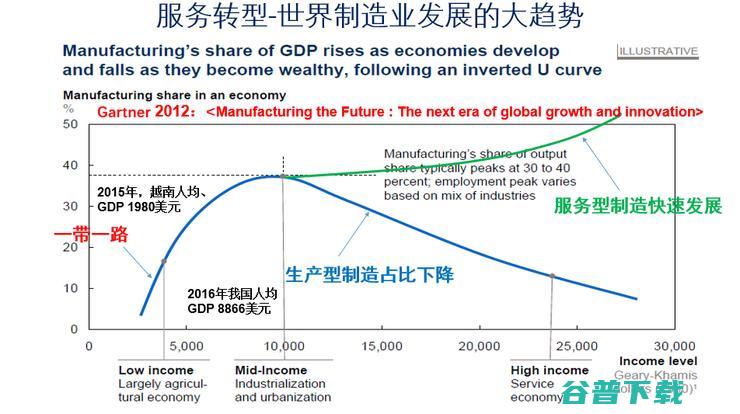
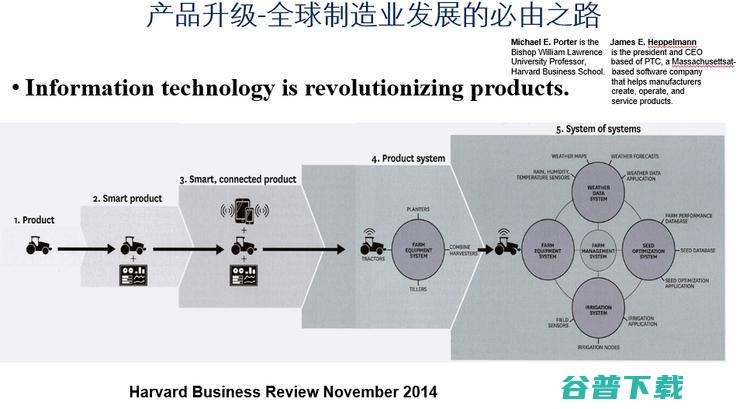
总地来说,世界变了,制造业变了。这是哈佛大学2014年非常著名的一个论断,就是信息技带来了产品的革命,产品升级是全球制造业发展的必由之路。制造不仅仅看一个产品,要看整个产品的运营的生态,并且是跨界的,开始就是一个拖拉机,后来带上天线,最后要和天气的数据、种子的数据、农业灌溉的数据联系起来,这才是现代农业、也是现代的工业,也是现代的服务业,现代工业革命已经模糊了第一、二、三产业。
这个时候制造业出现一个剪刀的曲线,物质产品的市场容量一定是有限的。出路在哪?创新,我做新的产品别人没有做过。另外一件事是把老的产品用好,做服务,做服务的过程当中再去创新,就是这样的一个过程。
今天我们讲工业互联网,其中一个是升级,5G、AloT都是要把产品进行升级,另外我们要更多的产业形态,就像雷锋网这样的做知识的传播、做知识的分享,这也是在助力制造业,也是在做制造业服务。
工业数字化转型核心目标是人和机器之间的有效融合,我觉得刚才讲的升级和转型当中有一个要素是被忽略了——人。真正讲的是人和社会、人和机器和谐的共存。这里人有时要被客体化,是一个很悲惨的事。
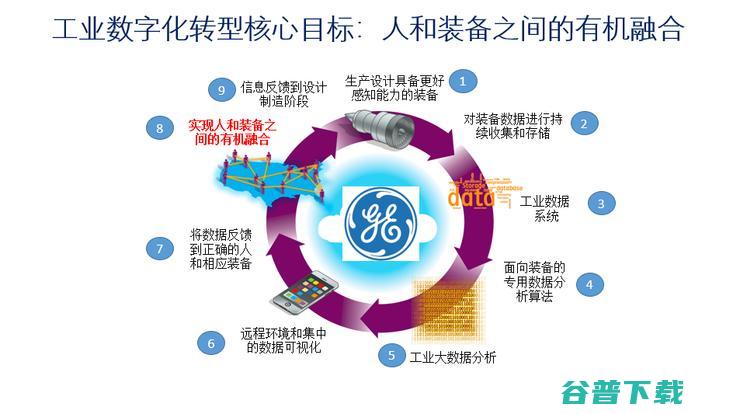
这里一方面装备要拟人化,另一方面人会被客体化为装备,都在工业生产发展的进程中。这是好还是坏呢?我认为不可阻挡,没有选择。这个过程当中最高境界还是人机融合,操作机器的时候让机器懂我,被机器服务的时候也希望机器懂我,真正的AloT里有机器AI,还有“人的AI”在里面。
今天我讲的主题是大数据,四中全会说大数据可以作为生产资料来进行投资、分成,同样数据也是整个工业数字化转型的一个关键。一会儿有西门子的分享,西门子无疑是工业4.0转型升级的一个领导者。
不过,大家一直在问,工业大数据和别的大数据有什么区别?下面这句话也许不能代表全部,但是他代表一种观点。工业大数据一定要和物理的对象结合,这个是工业里最核心要素。工业里有巨大的学问,这种学问很多是领域知识,所以近200年工业文明发展造就了现代社会,如果离开了这个,我们老说是“互联网的上半场,产业物联网的下半场”,就没有太大的区别了。
我是做软件的,回来再看大数据的软件技术,用下图稍微厘清一下我讲的内容,今天大家都在讲大数据,我个人把它分成了四个方面的含义。
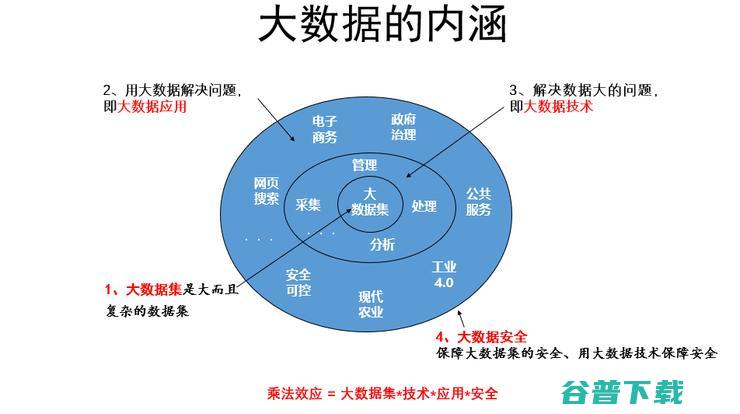
大数据一个含义是大数据集,这是我们采集下来的物化出来的0和1的资产。另外一个是用大数据解决问题,就是大数据应用,数据解决各行各业的问题并创造价值。有一个报道说中国的数字经济达到了GDP的1/3,规模达到30万亿人民币。但是2009年谷歌对整个美国的贡献是5400亿美元,我们还是要做很多的功课。我所服务的国家信息安全标准化委员会下设的大数据大数据安全标准化特别工作组,还包括人工智能、区块链,云计算等安全标准化工作。
我们现在看看大数据的软件,这是2016年的不完全统计,大数据开源软件供给侧很丰富。问题是这么多的东西无非解决这么简单的问题,就是说把大象关在冰箱里分五步,采集;然后抽取清洗、标注;再集成聚合;关键是分析建模,最后把结果解释应用。

这五个步骤里面挑战是什么,有异构的挑战、规模的挑战、处理时效性的挑战、隐私方面的挑战,还有人机互动协同的挑战。如果经过这五步就把问题解决了就太幸运了,大数据就变得太简单了。

实际情况不是这样的,而是循环的,有时很难走出这个循环,要解决问题要去找现有数据,对数据进行一些理解。在这个时候可能就是好多个循环,常常是能够用来解决业务问题的数据非常匮乏,企业有很多数据,但是缺乏能够用来解决问题的数据集。其实在企业做大数据项目的时候,特别是工业企业选题就是个难题,好的选题是成功的一半,往往你找不到好的选题。当然好多人可能没有做业务理解和数据理解这个循环就直接下去了,那结果风险就很大。
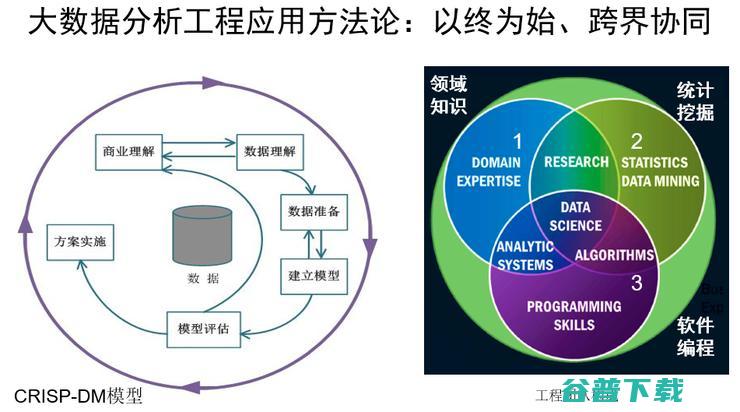
选题大概差不多靠谱后,就做数据的建模。现在我们所谓的机器学习有一个很强的假设是,你的训练集和应用场景是匹配的,也就是独立同分布的,但如果这个假设不成立,那模型预测就是不可信的。因为大数据面对未来的事情做预测,未来的数据是不是符合独立同分布的要求?所以要做模型的评估,如果你的运气很好,老板不太苛刻的情况下,分析模型很幸运地上线了,那是最好的方案,恭喜你就走出这个泥潭。往往你学习出来的结果和工业现场要求不相符的,比如我想看看计算机主板焊点的质量,人工检测都已经达到99.99%了,如果你的AI方案达到99.98%,虽然已经到小数点后的第三位了,但是这个不行,因此工业应用场景要求远远大于互联网的精度要求。
我一直在想为什么谷歌推荐能够赚那么多的钱,PV转化率据我所知只有千分之二十,但是这在行业里就很牛了,很厉害了。但是如果你在工业应用中准确率只有千分之二十的话,老板不会买账。为什么说工业场景的数据质量很重要,因为工业场景对数据分析的结果要求高。
怎么样构建一个数据系统?大数据的应用系统本质特征是个性化,打个比方就是每个大数据应用都是在不断装修改造的别墅。BAT在消费互联网领域很牛了,这个东西要推到产业里头是不是什么东西都迎刃而解了?大家看看这几年实现了多少,有多少产业落地了,在你们家用的别墅给别人家用就不适合了,所以这件事情,个性化是核心,怎么样个性化,这是我们要在方法论层面讨论的问题。
比如伯克利在想能不能研发一个大数据的软件栈给大家都能够用,亚马逊也在想这个问题。亚马逊从云计算开始到现在大数据和物联网,非常牛,亚马逊在问一个什么问题,就是是否存在一个参考架构?这个参考架构在各行各业能用遵循。这么多的工具,刚才我们看了好几百个主流的工具,有现在的也有原来的,在解决大数据问题的时候,我用什么工具是合适的?我应该怎么样使用这些工具?然后再问为什么我们要用这些工具?
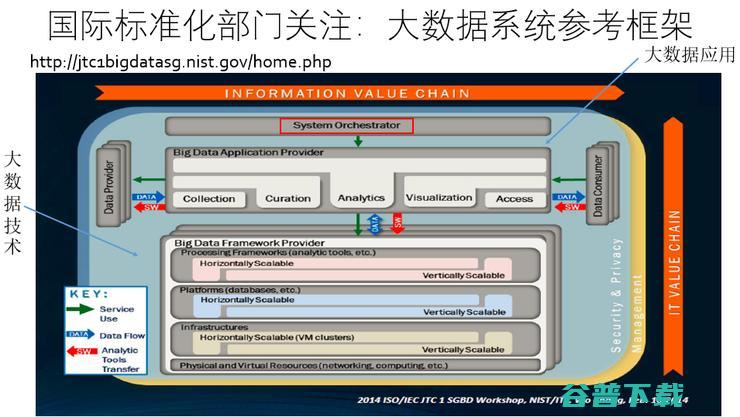
NIST有一个标准,认为大数据系统应该长成这样,下面是一个技术栈,上面是数据的生命周期,但是我觉得重要的在于上面有一个System Orchestrator,如果大家对云计算有了解的话Orchestrator太普通了,但是他在大数据里面有新的含义。
在这种背景下我们大数据系统软件国家工程实验室聚焦在以下问题:有没有一个大数据软件科学理论,有没有一个大数据系统开发的软件工程方法,是否有开发运行平台与工具支撑,核心是提高大数据软件构造的生产效率。
今天的制造业发生着工艺与工具的革命,将来的软件生产一定不是我们今天的“码农”,一部分用java、C或其他的开发语言,另一方面低代码开发等未来的软件生成逻辑,将改变大数据系统构造方式。
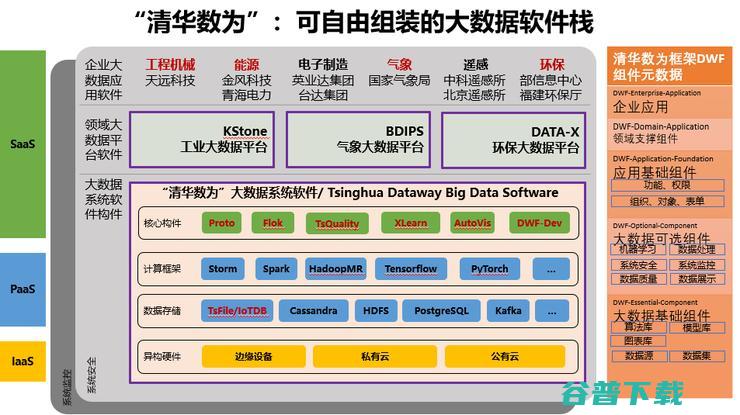
所以我们设计了一个清华数为的可自由组装的大数据软件栈。这里面有我们自己核心的功能,核心的构件,这里IoTDB、XLearn、DQuality等都是我们自己研发的。再一个是右边这个清华数为框架(DWF)非常重要,就是一个大数据系统构造软件框架,一方面它是低代码信息化开发环境,另一方面它是大数据软构件集成的交互总线、控制总线和数据总线。
如果大数据软件生态里头就是老虎、狮子、大象,需要一个训兽师,每一个节目需要有一个人去协调它,这就是清华数为框架。
工业大数据其实要处理好三个关系,一个是数据的泉,一个是数据的库,再加上数据的湖。你要把“泉”这件事情搞清楚了,数据泉就是我们今天讲的AloT,或者把A去掉也行就是IoT,就是物联网产生的数据是一个数据泉,今天是一个爆发的产生数据的水龙头,如果接不住水就跑了。所以今天讲IoT得把他连进来,然后还得留下来,所以数据的泉是一个重要的鲜活的数据来源,是一个实时的、在线的东西。数据的库是信息化重要技术,把人产生的数据放在库里头,结构化的数据放在库里头。
今天我们讲数据的湖,好多企业说现在我在建数据湖,我认为错了,数据湖不是你建的,这是自然形成的。这些泉、库都在你企业里头了,也许当时你也不知道如何组织这些数据,然后形成了数据的湖了,数据的湖是需要治理的,才能够把有用的数据“钓”出来。
“泉、库、湖”,中间有一个数据中台的东西,一会儿再讲数据中台是什么。这个过程当中DWF清华数为框架,一个作为大数据系统的协调器,把各个组件协调起来,另外一个是支持信息化应用的低号码量开发,让更多的业务人员可以用他来做数据的处理。还有一个解决数据泉的问题,要把物联网的应用变成一个组态的软件,把这些采集的数据给收回来。
低代码做的就是软件定制部署,特别是大数据的软件不是一成不变的,总有新的需求,我们能不能有一个低代码量的软件开发的这样一种形式,前天我们在清华做第一期的培训,来了人不多大概50个左右的企业的人员,我们就在检验我们低代码开发的这样一个交互环境,能不能让非软件专业的人也能用,以适应企业业务的频繁变化。
数据的湖不是我们期望的,它是指根本没有组织或者没有被良好组织起来的一组数据集,是一种缺少秩序的东西,在这里面人只能像钓鱼一样“钓”出有用的数据,这些里面有些地方是营养不太好的,甚至有些地方的数据是有毒的,怎么鉴别出来?怎么治理?
现在看数据中台,大家一定要想清楚什么是数据后台,否则中台和后台的关系不厘清,数据治理就是乱的。现在数据中台很热,大家要小心,可能变成一个陷阱。首先要把数据后台能够发挥出来的能力发挥到极致,实在不能满足需要的时候,你按需建数据中台,今天千万别上来就建一个很厚的、很重的中台,将来可能需要去交学费的。在这里面我们要理清楚这些基本的概念,然后企业把他的数据治理在清华数为框架下得以实现。
这里面我们有一个案例,这是一个头盔,为什么要做头盔,就是要把人集成在互联网里面。这是一个维修工,戴着这个头盔之后老板就知道他在怎么样做维修,后面还有一个具体的,透过这个我们就知道我们在工业大数据里头,要把传统的信息化的数据拿进来,要把现在的物联网的数据拿进来,还要把很多你跨界的数据拿进来,然后用人工智能的办法去理解它,这个头盔上面就有行为识别。这是介绍了数据湖的一个框架。
下面我讲数据泉的治理框架。清华大学开发了一个物联网数据库,Apache IoTDB,其实叫数据库这个名字并不确切,因为他可以把传感器等端上的数据形成一种持续的格式文件TsFile—CLI,进入到上位机的数据库,然后还是这个数据文件格式进到云AI处理环境,支持物联网数据的全生命周期使用。
IoTDB 这个代码为什么要开源?现在到了一个共享的时代,大学也不例外,我们在前年做了国际学科评估,大家觉得一所有影响大学的软件学科要看你的软件制品,老百姓能不能看得见、用得上。IoTDB是可以放在端上面,可以放在工控机、场控机上面,也可以放到云上面,TsFile一个文件格式打通从端到云的文件。
2018年11月份我们正式贡献给Apache社区。这次开源经历给了我们非常大的鼓励,真正开放的环境下面有创新,不是我们一个团队在战斗,大家会看到深圳的深信服给了我们非常好的深度的测试,包括联想、海尔,像一些大学,包括德国创业的企业,深圳是一个特别好的地方,深圳是一个创新活力特别强的地方,我们大家一起把IoTDB开源项目共创起来,是非常有意义的。
有了物联网,然后有了前面的数据治理,然后就是Al了,怎么样把它处理起来,我们有一个机器学习的平台叫做Xlearn,不过名字重了,我们准备要把它改名。它是服务整个生命周期的,从打标注开始。当前机器学习核心问题之一,是希望具有能够举一反三有迁移学习的能力,我们在国际上提前布局了相关工作。在数据可视化交互探索上面我们也有工具AutoVis。
今天的AloT我认为就是这五个阶段的融合,一个是物联网阶段的数据采集,另外一个是信息化阶段的全类型数据的管理,然后到原来称为BI的报表,然后到当前AI当中的机器学习,今天我们讲的AloT就是把这些技术的一个综合的应用。

现在分享几个案例:第一个就是在装备制造服务方面,我们跟河北天远合作,他服务于小松、康明斯这样世界500强企业。举个例子,通过发动机里采集的数据,精准分析油耗。会看到两个司机,他的经济性是不一样的,深绿的是差的,浅黄的是好的,通过油耗经济型分析,你就知道这两个司机每个司机应该给他多少钱。
第二个,很多的工程机械要做租赁,这个人到底挖了多少斗的土,有多少的土方,原来是很难计量的。操作手戴上智能安全帽以后,就知道结帐的时候他今天应该领多少钱。
第三个,很多的工程装备都在荒郊野外,维护人员是不是很负责任地做了维修保养,老板原来只能听汇报,今天不一样了,戴上智能头盔,老板就知道他怎么打的黄油,这个黄油枪在挖掘机的A、B、C、D这几个关键的部位有没有保养到位,你就知道了,数据就创造了价值。
还有台湾英业达生产线大数据分析,这个回流焊里面有很多的数据。请大家看这里面的场景,有时候电子器件要偏移,有时候要立碑,有的爬锡,这些缺欠的检测靠的就是工业大数据和工业的AI。
最后我们看看跨界大数据应用的情形,大家知道风电、太阳能都是靠天吃饭的,看风力多大,看今天的太阳多大,这些来源于自然,所以要靠气象预报。为了做这件事情,我们和中央气象台做了一个云的外推的方法,取得了国际一流的成果,并完成了业务化。
最后,再次强调我们团队的使命,是让产业界可以非常低成本地构建大数据的应用软件,让工业界有效地搜集存储并且分析工业物联网的数据,并有效降低大数据分析处理的门槛。
我的分享就到这儿,谢谢大家!
加「雷锋网」公众号,发关键词「2019 AIoT峰会—清华大学」,获取本文精彩演讲PPT。
原创文章,未经授权禁止转载。详情见 转载须知 。


深麦咨询(DeepMedAmalytics)是一家“知识应用设计”公司,可以简单理解为提供医学信息学和知识工程的成果转化及产品设计咨询服务。其核心能力是基于医学知识工程方法、新技术成果、产品化设计模式三者的融合,利用领先的设计思维和设计工具,帮助客户提升产品,尤其是产品中知识应用的实际落地和优化,让知识驱动成为产品亮点,让最终用户(医务人员、患者、大众)成为真正受益者。

OK助眠是一个致力于探索助眠视频和助眠音频的论坛,网站专注于吃播、掏耳朵和口腔音等asmr音疗哄睡觉耳搔直播资源分享。

新会柑普茶网是专门介绍新会陈皮、新会柑普茶十大品牌(牌子)、小青柑十大品牌(牌子)的专业网站。主要介绍新会陈皮柑普茶(小青柑、二红柑、大红柑)十大品牌(牌子)的正宗来源、制作工艺、冲泡方法、柑普茶价格、柑普茶金柑普的功效与作用、新会陈皮的功效作用、新会陈皮储存正确方法、新会小青柑的加工、批发、零售行业资讯。

上海桌椅租赁公司,联系电话13818073616,专业提供家具租赁,桌椅租赁,会展家具租赁,沙发,桌子,椅子租赁,会议桌椅,办公家具出租,凳子,折叠桌,折叠椅租借,上海灯光音响租赁一站式服务配套体系。。

山东一诺织品有限公司-山东一诺织品有限公司,专注高端羊毛织物,专业生产羊毛地毯、汽车坐垫,欢迎致电:13475501788

中国非洲总商会,中非总商会,Caga,Agc,民间外交

气候网(www.qihou.com)准确提供24小时,今天,明天,未来一周7天,10天,15天,30天,40天,天气预报查询服务,可以查询全国城区四十天天气预报!并且为用户提供生活指数、健康指数、旅游攻略、交通出行、空气质量指数,及各类天气预报和生活资讯

电脑店u盘启动盘制作工具,随时随地自制引导盘和光驱,随心所欲更新系统,电脑店u盘pe用户无需经验就可以自己用u盘重装系统,方便快捷,一键安装

南通木材,板材,加松,铁杉,落叶松,建筑模板,竹胶板,覆模板,多层板批发,欢迎新老客户来电光临周山木业。

佛山市鑫晨照五金制品有限公司佛山五金加工生产设备,发挥外发五金加工的优势,实现可持续发展。

安徽省墙体屋面材料工业协会(原安徽省砖瓦工业协会)于2007年2月经安徽省民政厅登记注册并批准成立,是具有法人地位的全省性、行业性、非营利性的社会团体。于2011年7月经安徽省民政厅同意更名为:安徽省墙体屋面材料工业协会。
官网")
爱益森益生菌4.0时代来袭,aunulife牵手中国台湾丰华研发团队及食品工业发展研究所,成功破解健康密码,找到蕴藏在益生菌中的有益物质-滢养元,从而创启益生菌4.0时代。


不知何时起非对称对抗游戏成为了主流的游戏,游戏中有两种不同的玩家群体,每个群体的玩家都有着特殊的使命,那么好玩的非对称对抗游戏有哪些?非对称对抗游戏是超级流行的,这样的游戏可以锻炼玩家的神经反应速度,没玩过非对称对抗游戏的小伙伴快来看看下文吧,1、,躲猫猫,这款角色可爱的动物类游戏有个非对称的玩法,就是一对三十九的生存类模式,这个生存...。

2022有一个游戏叫什么小镇的是什么,大家都喜欢小镇类型的手游,可能是因为想从这嘈杂的城市中找回一点宁静,下面挑选了一款非常好玩的小镇手游,大家一起来享受快来的小镇时光吧!1、,梦幻小镇,这是一款画风清新的模拟经营类手游,可以躲乳这个充满宁静的如世外桃源般的梦幻小镇,还可以在小镇中随心所欲的经营自己喜欢的事情,农场种田、角色换装、商场...。

2020年,放眼今年中国市场上的智能手机,AI已经成为标准配置,其中,尤其令人瞩目的,是众多Android厂商们推出的旗舰智能手机——无论是出自于OPPO、vivo、小米等大厂,还是由专注于游戏细分领域的黑鲨、红魔出品,它们都将AI的能力发挥到了极致,拍照、语音、游戏、翻译……在这些最常用的场景中,AI可以说是无孔不入,也体现出了强大...。

苹果14promax怎样开启微距镜头,苹果14promax手机的拍照功能不断地升级,你可以在这里设置好微距控制模式,这样就可以拍出微距照片,那么怎么开启微距镜头呢,一起来看看吧!...。

2020年10月23日至25日,第78届中国教育装备展示会在山城重庆召开,教育行业的这一盛会已经连续举办了77届,今年受疫情的影响,在线教育规模突飞猛进,不管是公立学校还是校外培训机构,都经历了线上教学的洗礼,教育信息化迎来了前所未有的发展,为今年的教育装备展赋予了特别的意义,教育智能设备悉数亮相,5G、AI、大数据等技术与教育的深度...。

发表在极米投影仪2024,1,1014,15极米RS10mini和坚果N1是价格接近的投影仪,都配备有一体式的云台支架,具体极米RS10mini和坚果N1区别有哪些呢,下面就通过详细的参数配置进行对比分析,看看极米RS10mini和坚果N1区别哪款好,哪款性价比更高,更值得用户入手,一、极米RS10mini和坚果N1区别,1.光学参数...。

1.了解目标受众在选择广告联盟之前,首先需要了解你的目标受众,不同的广告联盟可能在特定领域或行业中表现优异,例如,如果你运营的是一个与旅游相关的网站,那么选择专注于旅游行业的广告联盟将会更有效,以某个旅游博客为例,该博客的运营者选择了一个专注于旅游和酒店行业的广告联盟,通过分析用户访问行为,他们发现用户更倾向于点击与酒店预订相关的广告...。

1.中国作为世界第二大经济体和全球最大的货物贸易国,同时也是众多国家的关键贸易伙伴,一直为世界经济增长提供稳定动力,2.中国不仅是全球经济治理体系变革的关键推动者,而且还在其中扮演着多重角色,新价值理念的引领者、国际制度的建设者、全球方案的贡献者和集体行动的参与者,3.中国倡导的人类命运共同体理念,反映出新的历史条件下的价值取向,并成...。

1、科鲁兹车优缺陷如下1隔音很宁静,同价位属于中上偏上水平,通用系的隔音都要比竞品要好很多,后排要偏向2底盘有初级感,上了高速底盘真的稳妥3滤震过沟沟坎坎解决的很好,悬挂行程偏长,路况好的话反倒,2、1质量牢靠性饱受质疑缺点基本出当初刹车传动发起机等内围系统,也有车身外部车身外部及内饰等,可见雪佛兰科鲁兹的缺陷确实是不少2变速机构体现...。

拼多多百亿补贴活动给消费者带来了一系列的优惠。首先,百亿补贴意味着拼多多将向消费者发放巨额的购物补贴,使得消费者在购物时可以享受到高额的优惠折扣。这意味着,在拼多多的平台上,每个消费者都可以获得额外的

如何使用Java编写一个简单的学生请假管理系统?随着社会的不断发展和教育水平的提高,学校的管理工作也变得越来越复杂。其中,学生请假管理是学校管理的重要一环。为了提高学生请假管理的效率和准确性,我们可以使用Java语言来编写一个简单的学生请假管理系统。这个学生请假管理系统主要包括以下几个功能模块:学生管理、请假管理、请假审批、请假查询等。首先,我们需要建立一个

适用版本:wordpress4.0.x语言编码:UTF8简体模板颜色:红色黑白适用站点:企业政府设计创意 THEKEN是一个多用途创意作品企业主题,极简时...theken多用途创意作品企业wordpress主题+安装教程,源码屋论坛

导读,苹果,可伸展环设备,专利近日获授权,该设备被称为,智能戒指,,将其戴在指关节上可用于控制电子设备,据了解,亚马逊此前也推出过类似智能指环,近日,据国家知识产权局官网显示,苹果公司,可伸展环设备,专利获得授权,专利摘要显示,这一环设备佩戴于用户的手指上,早在2015年,苹果就已提交了类似,环状计算设备,的专利,被外界视为比苹果手表...。

首都网警来科普,故意发布虚假信息违法吗,戳视频,@首都网警蜀黍带你一起学法懂法!首都网警的微博视频来源,松松科技QQ,微信,lusongsong7本文地址,https,down.lusongsong.com,info,11499.html9000本电子书免费下载价值百万,现在仅需0元联系客服还有惊喜立即下载...。
文字链接认证代码普通联盟标志认证代码企业广告联盟标志认证代码广告联盟评测代码说明,本页面的认证代码为我发广告联盟专用评测代码,站长需懂简单html知识,直接复制代码粘贴到联盟网站相应页面即可使用,本代码不适用于其他广告联盟网站请勿获取!文字认证,文字链接代码认证适用所有类型的广告联盟,复制代码后放在我发广告联盟网站首页底部或友情链接位...。

今晚8点,2023天猫双11预售正式开启,恰逢24节气霜降,今年双11也为消费者带来,双降,的快乐,在跨店满300减50的基础上,增加了官方立减直降商品,双重降价,满足凑单党和一键下单党的不同需求,预计有超8000万热销商品达到全年最低价,首艘国产大型邮轮爱达·魔都号也赶在双11上架淘宝,今晚将在淘宝直播间亮相,还参与官方直降立减,预...。

发表在专业问答2021,3,115,27展示机型信息,品牌型号,坚果J10系统版本,JMGO4.0投影镜头需要用拭镜纸、棉棒和专用清洁剂清洗,其中清洁剂可以使用纯水或高纯度酒精代替,在清洗时用拭镜纸擦拭镜头前的清洁剂,然后用棉棒去除残留的清洁剂,投影镜头用什么东西清洗投影镜头需要用拭镜纸、棉棒和专用清洁剂清洗,其中清洁剂可以使用纯水或...。
