LeCun一小时演讲 附完整视频 Yann Facebook 研究的下一站是无监督学习 AI

作为 Facebook 人工智能部门主管, Yann LeCun 是 AI 领域成绩斐然的大牛,也是行业内最有影响力的专家之一。
近日,LeCun在卡内基梅隆大学机器人研究所进行了一场 AI 技术核心问题与发展前景的演讲。他在演讲中提到三点干货:
演讲完整视频如下。该视频长 75 分钟,并包含大量专业术语,因此雷锋网节选关键内容做了视频摘要,以供读者浏览。
以下为视频摘要:
一、无监督学习的重要性
AI 技术的飞速进步很大程度上是由于深度学习和神经网络领域的突破,还得益于大型数据库的建立和更快的 GPU。我们现在已有了图像识别能力可与人类相比的 AI 系统 (例如下文中 Facebook 的识别系统)。这会导致自动化交通,医疗图像解析在内的多个领域的革命。 但这些系统现在用的都是监督学习(supervised learning),输入的数据被人为加上标签。
接下来的挑战在于, 怎么让机器从未经处理的、无标签无类别的数据中进行学习,比方说视频和文字。 而这就是无监督学习(unsupervised learning)。
二、神经网络的规模越大越好
传统的思想认为,如果你没有大量的数据,神经网络应该控制在较小的规模。Yann LeCun 指出 这完全是错误的 。他的团队在数据不变的情况下扩展了神经网络,得到了更好的结果。他说,神经网络越大,效果就越好(当然前提是数据库大小达到了临界值)。至于为什么会这样,目前仍是一个谜,相关理论研究正在开展。
三、卷积神经网络在识别领域的广阔前景
Yann LeCun 特别强调了卷积神经网络的重要性和应用:”我们很早就认识到,卷积神经网络可以被用来处理多种任务——不单单是识别单个物体(比如字母数字),还可以识别多个物体,同时进行物体识别、分组和解释。比方说,可以用卷积神经网络训练 AI 系统识别并标注(摄像头所拍摄)图像中的每一个像素,以此分析前方路径是否可通过。在英伟达最近的自动驾驶项目中,他们就使用了卷积神经网络来训练自动驾驶系统。系统分析摄像头提供的图像,据此模仿人类的转向角度。“
他还介绍了卷积神经网络在 Facebook 图像识别系统中的应用。“ 有了它之后,Facebook 的系统不仅能识别图像,还能绘制出图像的轮廓,并根据轮廓影像对物体进行分类。该系统甚至可以挑出中国菜里面的西兰花(如下图)。”

下面是对同一幅图像识别前后的对比:


Yann LeCun 表示这是一个巨大的进步,如果你在几年前问一个 AI 专家:”我们什么时候才能做到这样?”,答案会是“不清楚”。
“ 想让 AI 技术继续进步,我们就必须要让机器能够分析、推理、记忆,把现象和文字转化为运行知识。”
他接着作出预测,下一个将会十分流行的技术是记忆增强神经网络。 它可被理解为用记忆增强的递归神经网络,其中,记忆本身是一个能被区分的回路,并可以作为学习中的一部分用于训练。Yann LeCun 接下来对该技术进行了深入探讨,这里不赘述,详情请见视频。
四、强化学习、监督学习、无监督学习的数据要求
进行强化学习、监督学习、无监督学习的所需数据规模相差数个数量级。强化学习每次验证(trial)所需的信息可能只有几比特,监督学习是十到一万比特的信息量,而无监督学习则需要数百万比特。所以,Yann LeCun 做了一个比喻: 假设机器学习是一个蛋糕,强化学习是蛋糕上的一粒樱桃,监督学习是外面的一层糖衣,无监督学习则是蛋糕糕体。 无监督学习的重要性不言而喻。为了让强化学习奏效,也离不开无监督学习的支持。

五、用模拟机制提高强机器学习的效率
当下的主要问题是,AI 系统没有“常识”。人类和动物通过观察世界、行动和理解自然规律来获得常识,机器也需要学会这么做。包括Yann LeCun 在内的许多专家, 把无监督学习作为赋予机器常识的关键 ,该过程如下:
AI 系统由两部分组成:代理和目标(agent and objective)。代理做出行动,观察该行动对现实的影响产生认知,然后再通过该认知来预测现实情况。代理进行这一系列活动的动机来自于实现目标,而最终的目的则是:以最高的效率达到该目标。在强化学习中,对代理行为的奖励(reward)来自于外部,无监督学习的奖励则来自内部(对接近该目标的满意)。
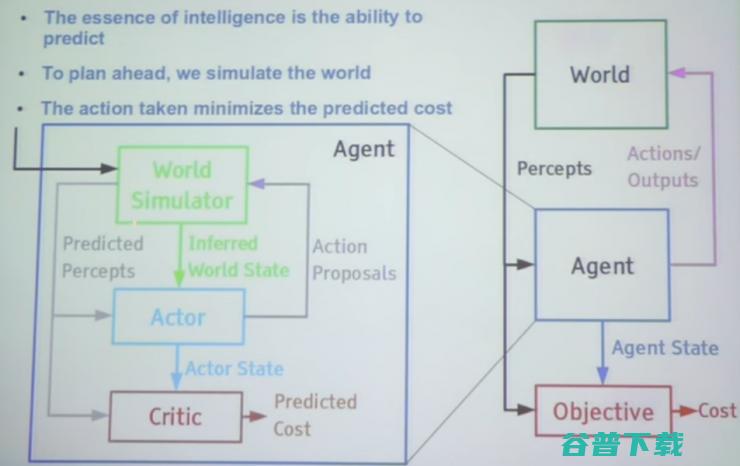
但这个过程存在一个很大的问题:代理进行无监督学习的方法是在现实生活中进行各种尝试,这存在危险并且效率很低。比如,无人驾驶车不能尝试所有可能的驾驶方法,会带来安全隐患。这种尝试又受到时间的限制,不能像计算机程序那样每秒运行数千次。所以, Yann LeCun 解释道,为了提高机器学习的效率,我们需要基于模型的强化学习(Model based reinforcement learning)。 它由三部分组成:现实模拟器(world simulator),行动器(actor)和反馈装置(critic)。现实模拟器对现实情况进行模拟,行动器生成行动预案(action proposals),然后反馈装置对该行动的效果进行预测。这样,AI 系统就可以对行动反复推演,进行优化,而不受到现实中时间和成本的限制。
小结:作为业内大牛,Yann LeCun 的一举一动都受到关注。他之前就发表过对 AI 前景和无监督学习的若干讲话,这一次在卡内基梅隆的研究人员面前再次强调了他的观点。虽然这不是我们第一次听到专家强调无监督学习、甚至是卷积神经网络的重要性;但此次演讲中, Yann LeCun 借用许多技术细节和各大公司、研究院正在从事的研究作为示例,为无监督学习将来会怎样发展作了全面的注解。正因如此,雷锋网建议关注 AI 领域未来发展方向的读者,不妨抽出一个下午仔细听一下演讲,必定会有收获。
【招聘】雷锋网坚持在人工智能、无人驾驶、VR/AR、Fintech、未来医疗等领域第一时间提供海外科技动态与资讯。我们需要若干关注国际新闻、具有一定的科技新闻选题能力,翻译及写作能力优良的外翻编辑加入。工作地点深圳。简历投递至 guoyixin@leiphone.com 。兼职及实习均可。
推荐阅读:
大神 Yann LeCun:我们的使命是终结“填鸭式” AI
深度学习元老Yann Lecun详解卷积神经网络
原创文章,未经授权禁止转载。详情见 转载须知 。



4399Flash云游戏,为广大玩家提供热门flash小游戏。植物大战僵尸、死神VS火影、火柴人、勇闯地下城等游戏,无需高设备即点即玩,手机也能玩电脑游戏。

鲍鱼是一种常见的食材,豆果美食食材百科为您整理了鲍鱼的别名,基本信息,适宜人群,不宜人群,搭配禁忌,鲍鱼的功效与作用,鲍鱼的烹饪技巧等信息,让您做出美味的鲍鱼。

郑州电信宽带办理服务全郑州地区、提供最优惠的电信资费套餐、商务宽带套餐,包括中牟、新郑龙湖镇、荥阳等地、上门办理方便快捷.热线68888822。

这里是合肥装修设计师沈玲玲工作室。合肥设计师沈玲玲:央视交换空间特约设计师,作品多次参赛获奖。擅长美式,新中式,东南亚,地中海等多种装饰风格。

电动工具,切入式圆锯,圆锯,斜切锯,圆形偏心振动磨机,磨机,方形轨道磨机鲁锹,曲线锯,无绳电钻,电动冲击扳手,木榫开槽机,修边机,铣机,CARVEX,KAPEX,SHINEX,IMPACT

迈威通信专注于为用户提供可靠的工业互联网通信产品和自主可控的系统解决方案,主要产品有工业以太网交换机,工业级交换机,PoE以太网供电交换机,三层交换机,工业交换机,光纤收发器,串口服务器,工业数据光端机,工业接口转换器,工业无线路由器,工业蜂窝无线DTU,LoRa&NB-IoT,工业无线AP/AC,工业智能网关,CAN设备联网,串口光纤MODEM,接口保护器

范芳勇的个人主页,汇集大量建站教程与免费网站源码,提供pbootcms模板、pboot网站模板、pbootcms源码、pboot网站源码、pb模板,助新手站长个人快速搭建自己的网站。

安徽探界智能设备有限公司

服装定制物联网平台是提供信服装定制相关资讯的平台行业提供专业化移动网络服务

卡塞尔机械是一家冻干机厂家,致力于各种草莓冻干机、海参冻干机、芦笋冻干机、溶解酶冻干机、柠檬片冻干机研发,价格适中,拥有几十年的温控设备研发生产经验,沿用欧洲著名温控系统制造者Kassel的设计工艺,可以根据企业客户需求定制。

中国电子科技集团公司第七研究所

中国工匠资讯网――让民间工匠走入中华民族共同体红地毯,民间工匠联合机构文化评价与传承推广…


冬病夏治是我国传统中缓解法中的特色疗法之一,它是根据,素问·六节脏象论,中,长夏胜冬,的克制关系发展而来的中医养生治病指导思想,冬病,指某些好发于冬季,或在冬季加重的病变,如支气管炎、支气管哮喘、风湿与类风湿性关节炎、老年畏寒症以及属于中医脾胃虚寒类病,夏治,指夏季这些病情有所缓解,趁其发作缓解季节,针对性的治疗,适当地内服和外用...。
随着全球网络向软件定义的方向转变,边缘计算正改编着各行各业,基于边缘计算的重要性越来越高,英特尔在2022年2月28日的巴塞罗那世界移动通信大会上发布了新的可编程硬件和开放软件,英特尔发布了一些列关于边缘计算和软件定义网络的成果,新一代英特尔至强可扩展处理器SapphireRapids架构;为边缘计算设计的英特尔至强D系列处理器;经过...。
自然界中,,蚂蚁觅食,是一种寻常但奇特的现象,成群结队的蚂蚁,总是能够在食物与蚁巢之间寻找到最佳路径,快速地将食物搬运至蚁巢中,这引起了生物学家的广泛注意,在经过多次研究实验之后,他们发现,蚂蚁在寻找食物过程时具备随机性,没有固定的方向和目标,但只要有一只蚂蚁发现食物,这只蚂蚁在搬运食物回巢时,就会留下一种微弱的气味,即一种叫做,信息...。

在夜间玩手机,我们一般会开启深色模式,苹果14pro也具有深色模式,我们不使用时关闭即可恢复到正常屏幕亮度了,还有小伙伴不知道如何关闭深色模式的话,就来看看本期为您分享的教程吧,马上就可以解决您的问题,...。

雷锋网按,7月12日,7月14日,2019第四届全球人工智能与机器人峰会,CCF,GAIR2019,于深圳正式召开,峰会由中国计算机学会,CCF,主办,雷锋网、香港中文大学,深圳,承办,深圳市人工智能与机器人研究院协办,得到了深圳市政府的大力指导,是国内人工智能和机器人学术界、工业界及投资界三大领域的顶级交流博览盛会,旨在打造国内人工...。

刚刚,2023IJCAI青年精英学术大会,YoungEliteSymposium,在上海华东师范大学圆满结束,为上海乃至中国人工智能青年学者的学术交流与人工智能的发展画上浓重的一笔,本次大会由WAIC组委会与IJCAI,SAIA中国办公室联合筹办,并得到了IJCAI授权,作为疫情后的线下大规模学术交流会,本次大会由杨强、周志华、张成奇...。

发表在专业问答2022,5,418,52展示机型信息,品牌型号,小米电视5s、iPhone13、华为P50、小米11系统版本,MIUITV3.0、iOS15.4.1、鸿蒙OS2.0、MIUI12软件版本,腾讯会议3.7.4腾讯会议需要通过手机无线同屏的方式投屏到电视,下面是具体手机同屏腾讯会议到电视的操作步骤,腾讯会议怎么投屏到电视苹...。

极米h3s和坚果j10哪个好,两款投影都是各自品牌的旗舰产品,具体有哪些不同呢,下面就通过外观、系统、画质等方面进行实测对比,看看哪款投影仪更好一些,一、极米h3s和坚果j10外观对比极米h3s和坚果j10在外观配色方面非常相近,不过在机身外形上,坚果J10要稍大一些,银灰配色搭配光滑的机身更显科技感,而极米H3S的外观和前代H3相似...。

河北廊坊的李先生从2011年到2020年间曾经8次无偿献血,就在近日,李先生患病就诊于河北霸州市第二医院,需手术治疗,后来,霸州市第二医院先后两次向廊坊市核心血站为李先生放开到了用血,并顺利输注,但到了他第三次须要继续输血时,却又原告之,由于近期没有献血记载,无法优先用血,事情引发了宽泛的关注和热议,在无偿献血与优先用血之间,承诺者的...。

属兔出世年月如下,1、出世在1939年的生肖兔,生于己卯年,2021年实岁82岁,虚岁83岁,2、出世在1951年的生肖兔,生于辛卯年,2021年实岁70岁,虚岁71岁,3、出世在1963年的生肖兔,生于癸卯年,2021年实岁58岁,虚岁59岁,4、出世在1975年的生肖兔,生于乙卯年,2021年实岁46岁,虚岁47岁,5、出世在19...。

JeepLiberty,自在人,的多少钱是49.80万元,JeepLiberty,自在人,是一款介于个别轿车与游览车之间的车型,它既可以容纳5团体,也可以将后排座椅装配,从而扩展货物的存储空间,在2004年,克莱斯勒的UConnect通信系统、胎压检测系统和货舱支架都成为了JeepLiberty,自在人,的选装件,JeepLibert...。

向日葵远程控制软件Mac版主控端拥有极致远程桌面,可以进行远程视频监控,包括声音也能都记录下来,并且向日葵Mac主控端还能随机随地关闭电脑、开启电脑,实现远程操控功能。;您可以免费下载。

城市中的火锅店比比皆是,每当夜色降临之时火锅店便迎来一日中的上客高峰期,前往各家门店惠顾的消费者接踵而至,生意兴隆的景象由此可见一斑,在众多火锅店中,金三峡火锅店是其中较为抢眼的一家,其凭借特色服务与可口的餐品打开了消费者心扉,与其建立起密切的联系,为销售工作开展提供了诸多支持,为向各位读者推荐该项目,下文就金三峡可以加盟吗的话题将给...。

快时尚女装是服装行业中具有名气的品牌,快时尚女装将一系列款式精美的产品推向市场,给予消费者们充足的选择余地,前往店内惠顾的人群数量源源不断,而品牌影响力覆盖范围也得到大幅提升,为向各位读者推荐该项目,文章将以快时尚女装加盟费用多少钱为题展开详细的论述,给有需要的朋友提供必要的创业主张,快时尚女装联营加盟费用多少钱,当前,快时尚女装联营...。

宝马作为一款奢侈品牌,深受国际生产者的喜欢,而宝马740作为宝马品牌中的旗舰车型,更是备受注目,那么,宝马740裸车多少钱是多少呢,宝马740裸车多少钱区间,依据官网统计数据显示,宝马740在中国地域的售价为98.9,249.9万元,这也象征着即使购置最低性能的宝马740,其售价也凑近百万元大关,宝马740的多少钱起因,宝马740的多...。

阳历十月份是天平座和天蝎座星座,天秤座是意味着秋天来临的星座,秋意表如当天秤座的人身上是对意气相投的不凡嗅觉,你寻求着独特点和相互体谅的土壤,和颜悦色的秉性,使恼恨和敌意永远不可接近你的身旁,天秤座的人温顺、娴雅,你须要欢欢畅乐地生存,须要忠贞不渝的情谊和恋情,郑重申明,以上内容只供参考,请勿封建迷信,十月份生日是什么星座天秤座或天蝎...。

操作手机,iPhone6操作系统,iOS8苹果6微信旧版本下载装置操作步骤如下,1、首先在咱们的电脑桌面上找到爱思助手并点击它,2、而后依据软件揭示用数据线把咱们的手机和电脑衔接起来,3、接着点击运行游戏,4、而后输入微信老版本并点击搜查,5、接着点击装置,6、期待下载实现,咱们的手机就会智能装置上微信老版本了,苹果6换电池所破费的费...。
