12.26 研习社每日精选论文推荐 Paper (12.26研究生考试时间)
Hi 欢迎来到Paper 研习社每日精选栏目,Paper 研习社(paper.yanxishe.com)每天都为你精选关于人工智能的前沿学术论文供你参考,以下是今日的精选内容——
具有姿势感性损失的面向音乐的舞蹈视频合成
Music-oriented Dance Video Synthesis with Pose Perceptual Loss
作者:Ren Xuanchi /Li Haoran /Huang Zijian /Chen Qifeng
发表时间:2019/12/13
论文链接:
推荐理由:作者提出了一种基于学习的姿势感知损失的方法,用于自动音乐视频生成。其方法可以产生逼真的舞蹈视频,该视频符合几乎任何给定音乐的节奏和韵律。为此,作者首先从音乐生成人体骨骼序列,然后将学习到的姿势到外观映射应用于最终视频。在生成骨骼序列的阶段,作者利用两个鉴别器捕获序列的不同方面,并提出一种新颖的姿势感知损失来产生自然舞蹈。此外,我们还提供了一种新的交叉模态评估来评估舞蹈质量,它能够估计音乐和舞蹈两种模态之间的相似性。最后,进行了一项用户研究,以证明通过提出的方法合成的舞蹈视频会产生令人惊讶的逼真的结果。
黑盒递归翻译用于分子优化
Black Box Recursive Translations for Molecular Optimization
作者:Damani Farhan /Sresht Vishnu /Ra Stephen
发表时间:2019/12/21
论文链接:
推荐理由:用于生成分子结构的机器学习算法为药物发现提供了一种有希望的新方法。作者将分子优化问题视为翻译问题,目标是将输入化合物映射到具有改善的生化特性的目标化合物。
值得注意的是,当将生成的分子迭代地反馈到翻译器中时,分子化合物的属性随每个步骤而提高。作者证明了这一发现对于翻译模型的选择是不变的,这使其成为“黑匣子”算法。作者将此方法称为黑盒递归翻译(BBRT),这是一种用于分子特性优化的新推理方法。这种简单而强大的技术严格作用于任何翻译模型的输入和输出。作者使用熟悉的序列和基于图形的模型进行简单的替换,从而获得了分子性能优化任务的最新技术成果。相对于其非递归对等体,作者的方法仅通过简单的“ for”循环即可显着提高性能。此外,BBRT具有高度的可解释性,允许用户从已知起点绘制新发现化合物的进化图。
高效的在线学习将内核映射到语言结构
Efficient Online Learning For Mapping Kernels On Linguistic Structures
作者:Giovanni Da San Martino
发表时间:2018/12/26
论文链接:
推荐理由:内核方法是用于学习结构化数据(例如树和图)的流行且有效的技术。它们的主要缺点之一是与对示例进行预测相关的计算成本,这体现在批核方法的分类阶段,尤其是在线学习算法中。在本文中,我们分析了当内核函数是Mapping Kernels的实例时,如何加快预测速度。MappingKernels是为结构化数据指定内核的通用框架,它扩展了流行的卷积内核框架。我们从理论上研究通用模型,得出各种优化策略,并展示如何将其应用于流行的结构化数据内核。此外,我们从语义角色标记任务(这是一种自然语言分类任务,高度依赖句法树)得出可靠的经验证据。结果表明,我们的更快方法可以在基于标准内核的SVM(不能在非常大的数据集上运行)上明显改善。
将事实提取和验证与神经语义匹配网络相结合
Combining Fact Extraction and Verification with Neural Semantic Matching Networks
作者:Yixin Nie / Haonan Chen / Mohit Bansal
发表时间:2018/12/12论
文链接:
推荐理由:对错误信息的日益关注刺激了对自动事实检查的研究。最近发布的FEVER数据集引入了基准事实验证任务,其中要求系统使用来自Wikipedia文档的证据语句来验证索赔。在本文中,我们提出了一个由三个同类神经语义匹配模型组成的连接系统,该模型共同进行文档检索,句子选择和要求验证,以进行事实提取和验证。对于证据检索(文档检索和句子选择),不像传统的向量空间IR模型(在某些预先设计的术语向量空间中对查询和来源进行匹配),我们假设没有中间语言,我们开发了神经模型以从原始文本输入执行深度语义匹配术语表示,无权访问结构化的外部知识库。我们还显示了Pageview频率还可以帮助提高证据检索结果的性能,以后可以使用我们的神经语义匹配网络进行匹配。为了进行声明验证,与以前仅将上游检索到的证据和声明提供给自然语言推理(NLI)模型的方法不同,我们通过为NLI模型提供内部语义相关性评分(因此将其与证据检索模块集成)来进一步增强NLI模型和本体的WordNet功能。在FEVER数据集上的实验表明:(1)我们的神经语义匹配方法在所有证据检索指标上都有显着优势,胜过流行的TF-IDF和编码器模型;(2)附加的相关性评分和WordNet功能通过更好的语义改进了NLI模型(3)通过将所有三个子任务形式化为相似的语义匹配问题并在所有三个阶段进行改进,完整的模型能够在FEVER测试集上获得最新的结果。
可解释的AI的有效显着性图
Efficient Saliency Maps for Explainable AI
作者:Mundhenk T. Nathan /Chen Barry Y. /Friedland Gerald
发表时间:2019/11/26
论文链接:
推荐理由:作者描述了一种与深度卷积神经网络(CNN)结合使用的可解释的AI显着性图方法,该方法比流行的梯度方法更有效。它在数量上也相似并且准确性更高。作者的技术通过测量每个网络规模末端的信息来工作,然后将这些信息组合成一个显着图。我们描述了如何通过利用显着性图顺序等效性来提高显着性度量。最后,我们通过使用信息的层顺序可视化来可视化各个规模/层的贡献。这提供了网络内其他显着性图方法未提供的规模信息贡献的有趣比较。由于作者的方法只需要单次向前通过网络中的一些层,因此它至少比Guided Backprop快97倍,并且精度更高。使用我们的方法而不是Guided Backprop,类激活方法(例如Grad-CAM,Grad-CAM ++和Smooth Grad-CAM ++)将运行速度快几个数量级,显着减少内存占用并提高准确性。这将使此类方法在资源有限的平台(如机器人,手机和低成本工业设备)上可行。这也将大大帮助他们在诸如卫星图像处理之类的数据密集型应用中工作。所有这些都不会牺牲准确性。我们的方法通常很简单,应该适用于最常用的CNN。我们还展示了用于增强Grad-CAM ++的方法的示例。
SAFE:欺诈早期发现的神经生存分析模型
SAFE: A Neural Survival Analysis Model for Fraud Early Detection
作者:Panpan Zheng / Shuhan Yuan / Xintao Wu
发表时间:2018/12/26
论文链接:
推荐理由:许多在线平台已经部署了反欺诈系统,以检测和防止欺诈活动。但是,在用户实施欺诈行为的时间与用户被平台暂停的时间之间通常存在差距。如何及时发现欺诈者是一个具有挑战性的问题。现有的大多数方法都采用分类器来预测欺诈者,因为他们会随着时间的流逝而活动。分类模型的主要缺点是连续时间戳之间的预测结果通常不一致。在本文中,我们提出了一种基于生存分析的欺诈早期检测模型SAFE,该模型将动态用户活动映射到生存概率,保证生存概率随时间单调下降。SAFE采用递归神经网络(RNN)处理用户活动序列,并在每个时间戳直接输出危险值,然后,利用从危险值得出的生存概率来实现一致的预测。因为我们仅在训练数据中观察到用户暂停时间,而不是欺诈活动时间,所以我们修改了常规生存模型的损失函数以实现欺诈早期检测。在两个真实数据集上的实验结果表明,SAFE不仅优于生存分析模型和递归神经网络模型,还优于最先进的欺诈早期检测方法。
基于神经网络函数逼近的Qleanring的有限时间分析
A Finite-Time Analysis of Q-Learning with Neural Network Function Approximation
作者:Xu Pan /Gu Quanquan
发表时间:2019/12/10
论文链接:
推荐理由:具有神经网络功能逼近的Q学习(简称神经Q学习)是最流行的深度强化学习算法之一。尽管在经验上取得了成功,但神经Q学习的非渐近收敛速度实际上仍然未知。在本文中,我们对神经Q学习算法进行了有限时间分析,其中数据是从马尔可夫决策过程生成的,而作用值函数是通过深度ReLU神经网络来近似的。我们证明,如果神经函数逼近器被充分地过参数化,则神经Q学习会找到O(1 /√T)收敛速度的最优策略,其中T是迭代次数。据我们所知,我们的结果是在非i.i.d数据假设下首次进行神经Q学习的有限时间分析。
预培训的百科全书:弱监督的知识预培训的语言模型
Pretrained Encyclopedia: Weakly Supervised Knowledge-Pretrained Language Model
作者:Xiong Wenhan /Du Jingfei /Wang William Yang /Stoyanov Veselin
发表时间:2019/12/20
论文链接:
推荐理由:预训练语言模型的最新突破表明,自监督学习对于多种自然语言处理(NLP)任务的有效性。除了标准的语法和语义NLP任务外,预训练的模型还对涉及真实世界知识的任务进行了重大改进,这表明大规模语言建模可能是捕获知识的隐含方法。在这项工作中,我们将进一步研究使用事实完成任务对诸如BERT等预训练模型捕获知识的程度。此外,我们提出了一个简单而有效的弱监督预训练目标,该目标明确迫使模型纳入有关现实世界实体的知识。使用我们的新目标训练的模型在事实完成任务上产生了重大改进。在应用于下游任务时,我们的模型在四个与实体相关的问题回答数据集(即WebQuestions,TriviaQA,SearchQA和Quasar-T)上的性能始终优于BERT,平均改善了2.7 F1,并提供了标准的细粒度实体类型数据集(例如, FIGER),精度提高5.7。
使用生成对抗网络进行人脸联合超分辨率和去模糊
Joint Face Super-Resolution and Deblurring Using a Generative Adversarial Network
作者:Yun Jung Un /Park In Kyu
发表时间:2019/12/22
论文链接:
推荐理由:面部图像超分辨率(SR)是面部图像分析,面部识别和基于图像的3D面部重建的重要预处理。最近的基于卷积神经网络(CNN)的方法通过使用成对的低分辨率(LR)和高分辨率(HR)面部图像来学习映射关系,从而显示出出色的性能。但是,由于使用CNN的HR面部图像重建通常旨在提高PSNR和SSIM指标,因此即使分数很高,重建的HR图像也可能不现实。
在这项研究中作者提出了一个对抗框架,通过同时生成带有和不带有模糊的HR图像来重建HR面部图像。首先,使用五层CNN将LR面部图像的空间分辨率提高八倍。然后,编码器提取放大图像的特征。这些特征最终被发送到两个分支(解码器)以生成带有和不带有模糊的HR面部图像。此外,结合了局部和全局区分符,以专注于HR面部结构的重建。实验结果表明,该算法能够生成逼真的HR面部图像。此外,所提出的方法可以生成各种不同的面部图像。
梯度下降的双重空间预处理
Dual Space Preconditioning for Gradient Descent
作者:Maddison Chris J. /Paulin Daniel /Teh Yee Whye /Doucet Arnaud
发表时间:2019/2/6
论文链接:
推荐理由:本论文介绍了相对平滑度和相对强凸度的条件,以分析用于凸优化的Bregman梯度方法。在目标函数的凸共轭和设计的双重参考函数之间的对偶空间中,作者引入了具有相对平滑度的完全显式下降方案。
对于在这种双重相对平滑度下的Legendre型凸函数,尽管它是完全明确的,但作者的方案自然保留在域的内部。作者在双重相对强凸度下获得线性收敛,条件数在水平平移下不变。作者的方法是梯度下降的非线性预处理,它可以改善非光滑或非强凸结构问题的显式一阶方法的条件。它展示了如何将该方法应用于p范数回归和指数罚函数最小化。
Paper 研习社每日精选论文推荐 12.25
原创文章,未经授权禁止转载。详情见 转载须知 。



网站排行榜是站长之家旗下专业提供中文网站排名服务的栏目,收集了国内各行业排名前列的众多知名网站,是国内专业、领先的中文网站排行榜。

我乐NBA中文网提供NBA视频直播,NBA季前赛直播,NBA录像回放,篮球直播,NBA现场直播,NBA赛事直播,打造NBA直播的中文篮球网站,篮球游戏中文网。
V1.0下载")
比特精灵是一款完全免费、高速稳定、功能强大、不包含广告的BT下载软件.自发布以来以其稳定高速,功能强大,使用人性化的特点,日益受到广大用户的青睐.比特精灵在老版本完成了性能上的飞跃

豆果美食红烧肉栏目为您推荐红烧肉做法大全,红烧肉怎么做好吃技巧分享,红烧肉最正宗的做法和红烧肉家常做法推荐,更多红烧肉的简单做法就来豆果美食。

三岩互联专注于出行网站建设服务,提供城市汽车出行信息分享,了解限行信息。

专业提供高精密导塑传感器,霍尔感应传感器,磁编码器,选择逻辑开关及电位器。产品在技术和生产领域均已成为行业翘楚。目前主要客户群体有军工国防、航天航空、医疗设备、船舶远洋、远程监测、工业无人机遥控、AI自动化等领域。专注品质,专业服务。服务热线:0755-84810325

扬州金店有限公司是苏北地区成立较早,规模较大的从事金、银、珠宝玉器首饰、工艺品批发、零售、加工、调换的专业性商店。电话:0514-87313728

豆豆游戏提供最流行的在线手机小游戏,最热门的不用下载就可以直接玩的H5小游戏,快来体验吧!

威信陶瓷,坐落于享誉中外的广东佛山建筑陶瓷聚集地一一中国陶瓷总部基地。威信陶瓷拥有十多年生产经验、先进的设备、优秀的人才团队载誉而归,在行业中也是名列前茅。产品线各大系列全覆盖5条全自动辊道窑炉,14条全自动化生产设备,11万平方米日均生产总值,超4000万平方米年产值,国内6亿销售额,肇庆、三水、西樵达1500亩三大生产基地,可存储量达180万箱。

兴土股份专注中国桥梁施工服务:钢便桥、交通钢桥、钢平台、钢围堰、0#块托架、挂篮、模板、连续梁施工、安全楼梯、临边护栏、墩身防护架、安全护栏施工作业车、卸落块、预压块、预应力智能张拉设备。

TianliElectricalMachinery(Ningbo)Co.,Ltd.



GoogleGlass,无疑是智能设备界的,话题王,来看看可穿戴设备初创公司Novealthy的创始人ManotenNapel眼中的GoogleGlass,当设备或软件处于测试阶段,意味着大功即将告成,通常情况下,测试版离最终版仅一步之遥,测试版存在的意义就是让公司为跨过最后一步而作出尝试与努力,基于这种假设,最好的办法就是用真实的...。
作者丨孙溥茜编辑丨陈彩娴大模型浪潮正在以它的方式蚕食着传统数字营销,改变都发生在你我生活的边边角角地方,2023年初,电竞被正式列为奥运会电子竞技项目;随着直播带货的火爆,相比淘宝,抖音电商后来居上,电竞、本地生活,这些新词新态,不过是近几年的事,也许因为他们的年轻,所以更加拥抱全新技术的变化,大模型似乎正在引爆新一轮互联网增长点,为...。
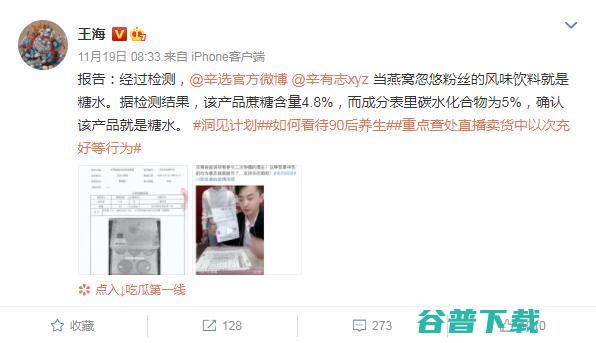
刚刚过去的315国际消费者权益日前后,职业打假人王海在一档节目中再次谈到了快手头部主播辛巴团队燕窝售假事件,去年11月初开始发酵的假燕窝事件,在2020年12月23日晚间得到了快手官方处罚结果,辛巴个人账号封停60天,就在昨日,辛巴在停播100多天后复出,开启2021年首场直播,在众多争议声中,辛巴高调回归,燕窝售假事件后高调回归20...。

工作认真负责、具备快速学习能力、性格外向、有亲和力、服务意识强、吃苦耐劳、踏实肯干、积极进取

1.十二星座的排名顺序,白羊座、金牛座、双子座、巨蟹座、狮子座、处女座、天秤座、天蝎座、射手座、摩羯座、水瓶座、双鱼座,2.十二星座即黄道十二宫,是占星学形容太阳在天球上通过黄道的十二个区域,在占星学的黄道十二宫定义只是指在黄道带上十二个均分的区域,不同于天文学上的黄道星座,而经国内天文学联结会在1928年规范星座边界后,黄道中共有1...。

12月26日,中华人民共和国建国主席毛泽东的诞辰,也是西方的节礼日,BoxingDay,毛泽东的诞辰为1893年12月26日,毛泽东是中国人民的首领,马克思主义者,平凡的无产阶层反派家、策略家和切实家,中国共产党、中国人民束缚军和中华人民共和国的关键缔造者和指导人,诗人,书法家,在西方每年的12月26日,圣诞节次日或是圣诞节后的第一...。

对于红旗H7的尺寸参数,以下是具体消息,车身长度,5095毫米,宽度,1875毫米,高度,1485毫米,轴距,2970毫米,红旗H7在外观设计上不落窠臼,后尾灯驳回双色搭配,经过前后连接的线条设计与前大灯相互响应,营建出剧烈的视觉冲击,展现出时兴与动感的格调,车内性能雷同器重温馨性,座椅驳回全方位可调设计,驾驶员座椅允许记忆三组共性化...。

1.海狮有四肢,也可以说是四条腿,2.海狮是鳍足亚目中的生物,它们的四肢正确的名字是鳍足,3.它们的鳍足跟陆生哺乳生物的腿有很大的不同,更像是鱼类的鱼鳍,4.这是由于海狮生存在陆地中,跟鱼类的生存环境相反,5.因此在退化环节中,四肢就缓缓变得越来越像鱼鳍,6.这样可以让它们在水中自在优惠,速度更快,海狮鱼学名叫什么海狮鱼学名是Otar...。

绿能回收客服电话是020,该电话是绿能,广州,废旧物资回收有限公司的,绿能,广州,废旧物资回收有限公司成立于2018年04月11日,注册位置于广州市黄埔区云埔工业区埔北路1号自编3号320房,法定代表人为黄少婵,运营范畴包含金属废料和碎屑加工解决;非金属废料和碎屑加工解决;电气机械设备开售;通用机械设备开售;纸张批发,钢材批发;黄金...。

窦某和梁某找了一份,轻松,的上班,只需将,涉黄小卡片,夹在他人车上,就可取得必定报酬,但在一天清晨,他们遇到两名自称警察的男性,被对方告知只需各交1000元,就可大事化无,二人交钱后,果真被两男性放了,随后几天,多名深夜分发,涉黄小卡片,人员也遭逢雷同状况,假设不给钱就会被对方拳打脚踢,往年4月,一名分发,涉黄小卡片,的男性报警后,绵...。

TCGames是一款手游直播投屏软件,是由成都杰华科技有限公司基于PC端研发的可以将安卓手机投屏到电脑,并通过电脑控制手机玩游戏的新一代手游投屏软件

BitCaveAirflow让您可以将视频内容流式传输到连接到WiFi网络的AppleTV和ChromeCast设备,而无需处理复杂的配置。

腾讯知文团队AI影响因子论文腾讯备受关注的人工智能领域顶级国际会议IJCAI,2018年将于7月13日至19日在瑞典斯德哥尔摩举行,IJCAI,ECAI2018,the27thInternationalJointConferenceonArtificialIntelligenceandthe23rdEuropeanConference...。

CPU作为三大核心芯片之一,长期被英特尔和AMD占据全球80%以上的市场,国内虽然也有飞腾、龙芯、海光、兆芯等企业在做自己的国产CPU,但原先就已构建起的市场格局壁垒高,短时间内难以改变,尤其是在生态方面处于劣势,虽然众多国产CPU公司不像英特尔和AMD等芯片巨头早在50年前就已经开始在半导体行业中摸索前行,但发展至今也有20多年的历...。

2014年,在WhatsApp以初创公司之姿面世刚满一年后,马克扎克伯格就和他的公司出资190亿美元将其买下,当时,WhatsApp创建者之一的JanKoum声称,收购并不会影响其客户的隐私安全,WhatsApp仍然是全球最安全的通讯工具,而这周的一个消息,可能是要打脸Koum了,就在当地时间本周四,WhatsApp宣布对隐私条款进行...。

前不久,曾独家报道过朱立华加入WiFi万能钥匙,尚网网络,担任CEO的消息,近期,多位接近朱立华的人士透露,他已经在公司全面开展工作,未来,朱立华将携手WiFi万能钥匙团队,在人工智能,AI,领域展开新的探索和创新,推动公司在社交及本地内容创造方面的突破,朱立华曾在美国微软硅谷云计算中心任职,主导研发了第八代远程桌面协议,RDP...。

怎么安装软件看电视直播教程,具体方法如下,最新方法怎么看电视台,只需要在电视上装一个当贝市场就可以轻松解决,1、下载当贝市场,http,www.dangbei.com,安装包并拷贝到U盘,2、打开东芝电视,按下遥控器的设置键,打开设置界面,点击,更多设置,3、在设置界面找到,通用,选择,商场模式,,把商场模式改为,开启,状态,4...。
