AI 不止 MIT 黑科技让图像秒变小视频 照片欲静而 (爱不止玫瑰)
你有想过吗?给你展示任何一张照片的时候,你看到的也许不仅仅是静止的图像,而是一段灵动的“小视频”。如今,在机器学习的帮助下,可以根据静止的照片,预测到接下来的一连串动作,准确率还相当的高。
无论是美女骑车、狗接飞盘,还是有人突然的跌倒等等,想象出这些连续的动作是我们最基本的技能之一,我们无需考虑用于预测的大量信息,比如重力、惯性和跌倒的本能反应等。那么,要让电脑学会这种预判的能力无疑是机器视觉中的一个关键挑战。
来自麻省理工学院的研究人员正在努力解决这个难题,他们已经展示出了一系列非常令人印象深刻的结果。通过使用专门训练过的神经网络,将图像转化为视频,并由计算机预测接下来会发生什么。但是,他们的模型仍然有很多局限性,视频通常只有几秒钟长,文件很小,而且图像经常很混乱。但这仍然是机器想象力方面一次令人印象深刻的创举,计算机在像人一样理解世界的道路上又前进了一步。
训练这个神经网络使用了超过 200 万个从 Flickr下载的视频片段。所有场景被分为四种类型:高尔夫球场、海滩、火车站和医院。这组连续镜头的画面很稳定,消除了相机抖动。通过这些数据,团队的神经网络不仅能够产生类似这些场景的短视频,也能根据一个静止图像产生连续的画面。这实质上是预判了接下来会发生的动作,但目前的效果还很有限,只能推测像素的变化,而不是基于整个场景的理解。
下面是效果图:

这里,我们可以看到实现后的效果,例如在海滩上,你可以看到波浪的起伏;在火车站,预测模型会预判火车行驶。然而,当要求预测某人如何穿过高尔夫球场时,结果看起来有些失真,图像也很模糊。
研究人员提到计算机的预测往往并不符合正常逻辑,但至少其对运动轨迹的判断是合理的。
机器学习系统在相关领域已经取得了许多进展,包括预测握手和拥抱等行为,甚至能够生成匹配视频的音频。facebook 的 AI 部门负责人yann LeCun在去年的一次采访中提到了这个话题,表示预判运动轨迹是开发预测计算机的重要一环。但是,要做到真正理解视频或图像,及其接下来可能发生的动作,还需要花费研究人员更多的精力。
“假如你正在看希区柯克的电影,这时我问,‘从现在开始的15分钟后,电影情节会发展成什么样子呢?’你此时就必须设法预判出凶手是谁。”
LeCun说:“要完全解决这个问题,就需要了解这个世界和人性,这才是真正的乐趣所在。”
人工智能在预测方面的能力已经越来越强,但要想做到更加准确、自然、符合实际的效果,还需要更加完善的模型。研究人员也许需要考虑更多的因素,建立更加复杂的神经网络,利用更多的数据集训练模型。只有这样,才有可能通过机器学习技术,真正实现对图像中的连续动作进行提前预判。
推荐阅读:
困境中的英特尔,拿什么在AI领域找回昔日尊严
在微软亚洲研究院工作是种什么体验? | 硬创公开课
原创文章,未经授权禁止转载。详情见 转载须知 。


佳吉快运

大可如意作为您的专属文书库,提供海量实用范文和常用文书,供丰富的范文和常用文书供您随时查阅、下载。帮助您快速解决各种文书写作难题。轻松找到所需文档,提高工作效率,让您的写作更出色。

中腾信金融信息服务(上海)有限公司(简称“中腾信”),专注于消费金融领域科技服务.公司拥有营销获客、个人信用评估、风控技术辅助、智能销售管理等成熟产品与解决方案。

蜗牛市政是一个一级建造师培训、二级建造师培训平台,并提供市政建造师高清免费视频教程,整理一建市政及二建市政的历年真题及答案、施工图片及视频、证书挂靠、考试教材以及考试报名相关信息

福多多福利,企业一站式弹性福利平台,包含电影通兑、生日礼券、年节礼包、娱乐演出、企业团建、优选商城等多种福利产品,为企业优化福利方案,满足员工差异化需求

智语面试是国内使用量第一的AI面试辅助软件,AI实时转录面试官问题,快速为求职者提供实参考回答,助力你拿到心仪的大厂offer!

梭猫云,梭猫云资源网,梭猫云解析,资源网,娱乐网,资源站,资讯网,活动资讯,软件下载,网站源码,小程序源码

大众网北京新闻中心是大众网服务北京的多媒体新闻宣传平台,是北京及周边地区拥有合法新闻资质、最具影响力的网络媒体。大众网依托海报新闻、北京论坛、齐鲁手机报、齐鲁手机杂志等资源为建设创新北京、文化北京、生态北京和幸福北京提供媒体助力。

欢迎致电:18915561593.批头批发价格美丽,保证批头质量,规格齐全:十字,六角,梅花,电动,螺丝批头,支持定制,交货及时,你很需要苏州市固德电子工具有限公司。

【井盖厂家-建联建材】主营球墨铸铁井盖、树脂复合井盖、不锈钢井盖、树脂复合箅子、雨水篦子、球墨铸铁箅子、不锈钢箅子、镀锌格栅、玻璃钢格栅、球墨铸铁爬梯、塑钢爬梯、雨水斗等,找井盖、雨水篦子、铸铁篦子,就选建联建材。

伏锂码云平台是捷瑞数字自主研发的面向数字孪生与工业互联网领域的软件研发平台,为智能制造业客户提供精准数字孪生解决方案,引领带动中小企业实现数字化转型.

凉山网是由四川两只青蛙科技有限责任公司打造的凉山地区一家综合性的电商交易平台,致力于为当地居民提供便捷的购物,生活服务和旅游体验;我们涵盖了凉山特产,凉山美食,凉山旅游等各个方面,为广大用户提供了丰富多样的商品和服务选择,咨询电话:13550107709


英语作为当前的世界通用语言,除了单词学习背诵之外,最重要的就是口语能力,那么英语口语免费学app推荐下载2022都有哪些,想要强化口语,就要从肯开口开始,在这里你能得到最权威的练习,海量名师在线为你指导,1、,流利说英语,人气最高以及口碑最好的一款英语学习app,主要针对的就是用户口语发音练习,学习更多的单词,让发音和口型变得更加标准...。

7月20号法制网消息,为了统一司法实践中互联网电子证据举证、认定标准,广东省广州市南沙区人民法院于7月18日出台,互联网电子数据证据举证、认证规程,下称规程,,今后,微信、QQ聊天记录等电子数据都可以作为有效证据使用,具体的互联网电子数据证据限定为短信、电子邮件、QQ、微信、支付宝或其他具备通讯、支付功能的互联网软件所产生的,能够有...。
80岁的老人平常会做什么?除了天天打打麻将、看看电视之外,再者就是任性地狂买保健药??但今天文章中的这位80岁主角,可能会颠覆你对老人的看法,如果你对错综复杂的游戏圈亚文化比较了解的话,或许你已经猜到我是在说谁了,她是一位经历过世界大战、玩过最早的街机游戏,乓,、并且见证了互联网诞生的一位女性,现如今的世界已经是她刚出生时那个年代的人...。

各家智能手机OEM厂商所生产的旗舰机型,在设计语言上通常都代表了其最高的技术水准,同时也代表着整个智能手机行业的发展趋势,这些旗舰机型多年以来已经在尺寸、做工、规格和功能上都有了显著的进步,可以说,如今在智能手机业已经没有多少领域还存有较大的发展空间了,可以肯定的是,虽然Android手机制造商们在将来仍会想尽办法来为自己的产品寻找卖...。

发表在极米投影仪2021,2,2018,41极米H系列的机皇极米H3上市已经有一年多了,今天来做一个极米H3评测,希望可以给到还想入手这款投影仪的网友们一些帮助,一、极简的外观首先我们能看到极米H3的外包装上面有实物图片,置于一个非常居家的场景中,打开包装,里面有极米H3、电源线、适配器、遥控器和说明书,还是熟悉的套餐,包装的保护措施...。

烧烤是人们意识中,十分诱人的美食,具有麻辣劲爽的口感,男女老少都爱吃,近年来,餐饮行业发展速度加快,也推动的烧烤行业的发展速度,很多品牌不断的出现,其中串意十足烧烤店非常的受欢迎,因为店内的产品种类齐全,而且味道很好,所以受到无数消费者的追捧,也提升品牌的发展速度,很多创业者看到这个项目的市场前景,所以想要在加盟之前,清楚的了解串意十...。

受市场影响,有人纠结阅读加盟还能不能行,其实不论处于何种发展时期,都存在消费需求,关键是要找准风口,比如2023年文旅行业就实现了逆势增长,年初持续到夏季爆火的淄博烧烤,还有冬季走红的哈尔滨旅游,那2024年的创业风口是什么,是面向3,14岁孩子,提供借阅、阅读指导、研学等服务的儿童阅读馆加盟项目,为什么这么说,以下是几点分析,1.政...。

[全球网报道记者索炎琦]北约峰会外地时期9日在美国首都华盛顿特区举办,据路透社、美联社等媒体报道,美国及其盟友在峰会时期宣布联结申明,宣布将向乌克兰再交付5套防空系统,包含,爱国者,导弹发射装置和其余部件,外地时期9日,拜登在北约峰会上宣布美国及其盟友将向乌克兰提供新援助图源,英国,卫报,视频截图报道称,拜登9日在北约峰会上宣布了上述...。

为穿梭前线7周年推出的金牛座—典藏版,相关于金牛座愈加罕见,具备十分高的收藏价值,这是穿梭前线首款星座武器,在M14EBR的基础上启动了提升,经过购置取得可以取得终身,初次预售是在2015年4月,预售多少钱为258QB,游戏降级后商城多少钱为CF点,小编查了一下资料,这把武器如同有两个版本,1个叫做M14EBR—金牛座,一个叫做金牛座...。

哪些,哪些如何,什么哪些,哪些哪些,怎么哪些

社交是训练!你有什么建议?下面我整理了社交Skills训练Methods供大家参考。社交Skill训练每个人都渴望拥有优秀的社交能力,但在现实生活中,很多人并不擅长社交,甚至害怕社交,这就大大,掌握一些技巧社交心理和谐社交技巧训练方法01社交所谓的“缺钙”。1、怎么锻炼自己的社交技巧?如何提高沟通能力?刚踏上社会的年轻人,面对纷繁复杂的社会,往往会感到迷茫和不安。有些人可能觉得自己的位置真的很小,有些人可能觉得自己的能力真的很有限,对如何在这个社会立足没有信心。其实社会是由人组成的。掌握社交心理学和社交的

捷途旅行者将26日上市或14万起越野配置曝光,旅行者,捷途,越野,旅行,座舱
音频娱乐是人们非常关注的焦点,可以覆盖众多使用场景和文字,这样的信息传播方式相比较起来拥有足够的感染力,音频有多种不同的类型,比如音乐、文字朗读等等,那么免费音频软件有哪些,通过音频拥有一种沉浸式休闲体验音频,音频和视频相比较起来,可轻松保护眼睛,接下来推荐几款免费音频app,非常治愈的平台,其中有很多情感主播可在线免费一对一倾诉,包...。
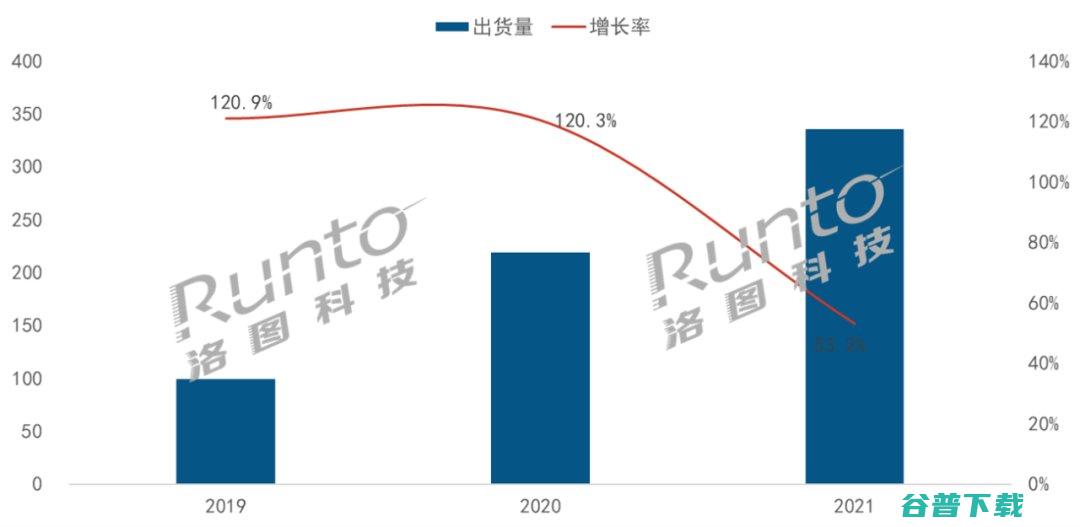
导读,2020年,尽管中国电视市场整体低迷,但大于75英寸的超大尺寸,不含75英寸,液晶电视市场保持强劲的增长势头,中国电视市场仍然有很多细分领域需要大力开发,领先的品牌也将在细分市场中受益,根据洛图科技,RUNTO,发布的,中国电视品牌市场出货月度追踪,报告中显示,2020年中国大陆超大尺寸液晶电视市场出货量达到21.9万台,同比增...。

话说一位科员因为长期得不到提拔,怨恨太深,索性破罐子破摔,天天迟到早退,有时有事就是找不到他人,科长找他谈了两次,都是不欢而散,毫无效果,屡教不改,只得向局长汇报,局长说,让他过来,我来找他谈,局长,知道我为什么找你吗?科员,科长做不了的事局长继续做呗,局长,你好像还有理了?科员,别人和我讲理我就讲理,别人不和我讲理,我也没办法讲理,...。

上古时期,凡人出生的时候命运就已经被定格了,你是贵族就永远都是贵族,你是奴隶就永远都是奴隶,后来,陈胜吴广揭竿而起,大喊一声,王侯将相宁有种乎,项羽一句,彼可取而代之,刘邦一句,大丈夫生当如此,此后,凡人开始不甘沉沦,在历史的巨轮下寻找逆天改命的机缘,全世界每个可以流传下来的文明,在古代都有过一段非常惨的历史,印度的萨蒂制,最早可以追...。

发表在当贝投影仪2020,6,411,06现在用U盘听音乐的人是少数,但是也有很多音质发烧友,有用户需求询问当贝投影仪怎么播放U盘音乐,这次我们就使用当贝投影播放下载音乐的教程分享给网友们,此方法也适用于其他的投影仪产品,当贝投影播放U盘音乐教程,1.将音乐文件下载到U盘,最好是mp4的文件,2.将U盘接入到当贝投影仪的USB接口中;...。
