API入门教程 Dataset TensorFlow全新的数据读取方式 (api 教程)
雷锋网 AI科技评论按:本文作者 何之源 ,该文首发于知乎专栏,雷锋网 AI科技评论获其授权转载。
Dataset API是TensorFlow 1.3版本中引入的一个新的模块,主要服务于数据读取,构建输入数据的pipeline。
此前,在TensorFlow中读取数据一般有两种方法:
Dataset API同时支持从内存和硬盘的读取,相比之前的两种方法在语法上更加简洁易懂。此外,如果想要用到TensorFlow新出的Eager模式,就必须要使用Dataset API来读取数据。
本文就来为大家详细地介绍一下Dataset API的使用方法(包括在非Eager模式和Eager模式下两种情况)。
在TensorFlow 1.3中,Dataset API是放在contrib包中的:
而在TensorFlow 1.4中,Dataset API已经从contrib包中移除,变成了核心API的一员:
下面的示例代码将以TensorFlow 1.4版本为例,如果使用TensorFlow 1.3的话,需要进行简单的修改(即加上contrib)。
让我们从基础的类来了解Dataset API。参考Google官方给出的Dataset API中的类图:
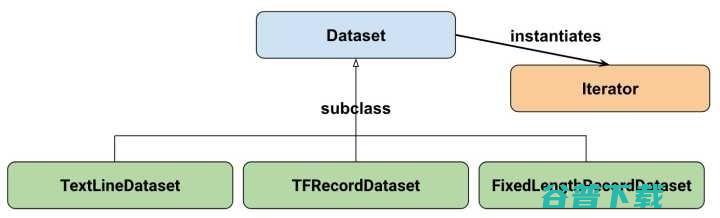
在初学时,我们只需要关注两个最重要的基础类:Dataset和Iterator。
Dataset可以看作是相同类型“元素”的有序列表。在实际使用时,单个“元素”可以是向量,也可以是字符串、图片,甚至是TUPle或者dict。
先以最简单的,Dataset的每一个元素是一个数字为例:
这样,我们就创建了一个dataset,这个dataset中含有5个元素,分别是1.0, 2.0, 3.0, 4.0, 5.0。
如何将这个dataset中的元素取出呢?方法是从Dataset中示例化一个Iterator,然后对Iterator进行迭代。
在非Eager模式下,读取上述dataset中元素的方法为:
对应的输出结果应该就是从1.0到5.0。语句iterator => 从内存中创建更复杂的Dataset
之前我们用tf.data.Dataset.from_tensor_slices创建了一个最简单的Dataset:
其实,tf.data.Dataset.from_tensor_slices的功能不止如此,它的真正作用是切分传入Tensor的第一个维度,生成相应的dataset。
例如:
传入的数值是一个矩阵,它的形状为(5, 2),tf.data.Dataset.from_tensor_slices就会切分它形状上的第一个维度,最后生成的dataset中一个含有5个元素,每个元素的形状是(2, ),即每个元素是矩阵的一行。
在实际使用中,我们可能还希望Dataset中的每个元素具有更复杂的形式,如每个元素是一个Python中的元组,或是Python中的词典。例如,在图像识别问题中,一个元素可以是{"image": image_tensor, "label": label_tensor}的形式,这样处理起来更方便。
tf.data.Dataset.from_tensor_slices同样支持创建这种dataset,例如我们可以让每一个元素是一个词典:
这时函数会分别切分"a"中的数值以及"b"中的数值,最终dataset中的一个元素就是类似于{"a": 1.0, "b": [0.9, 0.1]}的形式。
利用tf.data.Dataset.from_tensor_slices创建每个元素是一个tuple的dataset也是可以的:
Dataset支持一类特殊的操作:Transformation。一个Dataset通过Transformation变成一个新的Dataset。通常我们可以通过Transformation完成数据变换,打乱,组成batch,生成epoch等一系列操作。
常用的Transformation有:
下面就分别进行介绍。
map接收一个函数,Dataset中的每个元素都会被当作这个函数的输入,并将函数返回值作为新的Dataset,如我们可以对dataset中每个元素的值加1:
batch就是将多个元素组合成batch,如下面的程序将dataset中的每个元素组成了大小为32的batch:
(3)shuffle
shuffle的功能为打乱dataset中的元素,它有一个参数buffersize,表示打乱时使用的buffer的大小:
repeat的功能就是将整个序列重复多次,主要用来处理机器学习中的epoch,假设原先的数据是一个epoch,使用repeat(5)就可以将之变成5个epoch:
如果直接调用repeat()的话,生成的序列就会无限重复下去,没有结束,因此也不会抛出tf.errors.OuToFRangeError异常:
例子:读入磁盘图片与对应label
讲到这里,我们可以来考虑一个简单,但同时也非常常用的例子:读入磁盘中的图片和图片相应的label,并将其打乱,组成batch_size=32的训练样本。在训练时重复10个epoch。
对应的程序为(从官方示例程序修改而来):
在这个过程中,dataset经历三次转变:
除了tf.data.Dataset.from_tensor_slices外,目前Dataset API还提供了另外三种创建Dataset的方式:
它们的详细使用方法可以参阅文档: Module: tf.data
在非Eager模式下,最简单的创建Iterator的方法就是通过dataset.make_one_shot_iterator()来创建一个one shot iterator。除了这种one shot iterator外,还有三个更复杂的Iterator,即:
initializable iterator必须要在使用前通过sess.run()来初始化。 使用initializable iterator,可以将placeholder代入Iterator中,这可以方便我们通过参数快速定义新的Iterator 。一个简单的initializable iterator使用示例:
此时的limit相当于一个“参数”,它规定了Dataset中数的“上限”。
initializable iterator还有一个功能:读入较大的数组。
在使用tf.data.Dataset.from_tensor_slices(array)时,实际上发生的事情是将array作为一个tf.constants保存到了计算图中。 当array很大时,会导致计算图变得很大,给传输、保存带来不便。这时,我们可以用一个placeholder取代这里的array,并使用initializable iterator,只在需要时将array传进去,这样就可以避免把大数组保存在图里,示例代码为(来自官方例程):
reinitializable iterator和feedable iterator相比initializable iterator更复杂,也更加少用,如果想要了解它们的功能,可以参阅 官方介绍 ,这里就不再赘述了。
本文主要介绍了Dataset API的基本架构:Dataset类和Iterator类,以及它们的基础使用方法。
在非Eager模式下,Dataset中读出的一个元素一般对应一个batch的Tensor,我们可以使用这个Tensor在计算图中构建模型。
在Eager模式下,Dataset建立Iterator的方式有所不同,此时通过读出的数据就是含有值的Tensor,方便调试。
作为兼容两种模式的Dataset API,在今后应该会成为TensorFlow读取数据的主流方式。关于Dataset API的进一步介绍,可以参阅下面的资料:
雷锋网 AI科技评论
版权文章,未经授权禁止转载。详情见 转载须知 。



春秋旅游网—春秋旅游官方网,提供国内游、出境游、周边游、跟团游、自由行、邮轮游、景点门票、春航特价机票、旅游签证预定,四十年品质保障.

泉州人才网是泉州人才求职和泉州企业招聘最佳选择,作为泉州人才网更专注于泉州地区网络招聘和人才精英的选拔,给企业部门提供精确人才简历查询,让泉州人才透过职位搜索功能查阅泉州人才市场动态行情,正确的测评泉州人才能力等。
")
富加科技公司是一家拥有强大前沿数字化技术创新实力的企业,由一批曾任职于国内外知名企业的留学归国人员及国内具有先进技术的人员共同创办。公司先后获得了粤科金融集团在内的著名投资机构及投资人的投资。 富加科技致力于人工智能多模态大模型(HumadaAI)深耕细作近十年,在人工智能、区块链、云计算、大数据处理等领域拥有世界领先的专利技术,积累了丰富的全生命周期服务的能力和经验。 经过多年发展,富加科技打造了人工智能大模型的全技术栈道,研发了全场景精细化管理SaaS平台、软硬件一体化产品、“云边端”结合一体化交付的行业数字化系统等。 富加科技正在用自主创新的人工智能技术与产品为各行业的数字化升级、AI转型赋能,并且成功创新应用于大型企业的管理运营、智能制造、智慧城市、智慧楼宇、智慧商业综合体(园区、社区)等领域。


艾威数字科技有限公司是一家互联网产品研发与实施的综合性服务企业。秉承诚信、共赢、精益、创新核心价值观,致力用数据和技术发掘商业价值,赋能业务创新,探索商业模式。专注于为客户提供IT资源整合服务,助力各行业企业数字化转型。

吉林省太羽科技制造有限公司公司专业生产尼龙输气管路、燃油管路和高压管路。我们的产品广泛应用于汽车燃油输送系统、刹车制动系统、液压助力系统及机床设备的油气输送控制系统等。

文库吧(www.wenkub.com)是一个在线文档共享平台,在这里,你可以和千万网友共享自己的文档,全文免费阅读其他用户的文档,也可以利用共享文档获取的积分下载需要的文档。

书生题是小学、初中、高中课程和考试培训网站,致力于打造中小学培训的航母。拥有丰富的历年真题、模拟试题、笔记讲义等中小学课程和考试资料,并提供中小学课程和考试的网络课程培训服务。-shusheng.com.cn

河南省华豫东方本草生物科技有限公司专业致力于头皮/头发养发等特色品牌头疗管理,加盟业务有:头疗管加盟,养发馆加盟,养发护发加盟,止脱生发等,费用合理,采用中医经典结合现代科技不断推陈出新,深受投资者的喜爱!

名师桥成立于2017年,是一家专注公立校教师人才服务的人力资源科技公司。名师桥通过整合校外教师、师范院校大学生,自建教师人才库。运用大数据分析及自然语言处理(NLP)技术自建动态教学能力评价系统,为用人需求的匹配效率和效果赋能。现已形成教师招聘服务、劳务派遣服务、课后延时服务三大业务方向,服务中小学校1000余家。本着与客户“共建、共享、共赢”的发展理念,名师桥正以实际行动诠释着我们的企业愿景:汇聚名师,助力教育!

闲徕网络科技有限公司为客户提供独立手游代理平台,手游联运平台搭建开发,手游联运系统,提供全方位系统培训服务支持,助您极速创业,联系电话:18372019116。

耐材之窗、银耐联、RefractoriesWindow、耐火材料、耐材之窗网、耐材协会、耐火材料协会、官网、耐火原料、耐材制品、耐火材料行业协会、耐火、耐材、耐材价格、耐材走势分析


比莉公主也就是莉比公主,莉比公主角色有着美丽的外观,精致美丽的造型,如果喜欢关于比莉公主全部游戏有哪些2024的推荐,可以尝试以下关于莉比公主有关的游戏,都是能带来无限欢乐的,无论是换装游戏还是化妆都能让玩家们动动自己的双手完成任务,和可爱的莉比公主一起玩吧!1、,莉比小公主的完美沙滩之旅,莉比小公主的完美沙滩之旅,大家一起和可爱的...。

伴随着MWC2019的到来,整个智能手机行业迎来了密集的手机发布过程,尤其是在2月20日,在小米9于这一天的北京时间发布之后,三星S10系列又在大洋彼岸的旧金山亮相——值得一提的是,去年三星是在巴塞罗那的MWC会场发布了S9系列,对于S10系列,三星可谓寄予厚望,北京时间2月21日凌晨3点钟,三星的这场重磅手机发布会正式开始,本次发布...。

文,刘芳平、叨叨11月9日,科大讯飞在北京国家会议中心举行2017年年度发布会,这次发布会的主题是,顶天立地,A.I.赋能,,从智能语音起家的讯飞,正迅速布局从教育、汽车、医疗到家庭的AI,各行各业,顶天,的意思是人工智能核心技术进展,,立地,强调技术落地,赋能各行各业,本次发布会推出了众多新品,主要有10款AI,产品,以及4款消费...。

据彭博社报道,美国正在收紧对中国获得先进芯片制造设备的限制,将向中国禁售技术的限制提升至14nm,此前美国已经禁止在没有许可证的情况下向中芯国际出售大多数可以制造10nm以下先进制程芯片的设备,美国芯片制造设备供应商泛林半导体首席执行官TimArcher告诉分析师,他们已经收到美国商务部通知,出口中国禁令覆盖的制程范围已由最大10nm...。

国内新闻市场监管总局,对美团收购摩拜未依法申报开展调查工作8月30日晚,国家市场监督管理总局官网发文称,对搜电收购街电经营者集中案依法审查,并对美团收购摩拜未依法申报开展调查工作,下一步,市场监管部门将进一步加大对共享消费领域的监管力度,国家市场监督管理总局在文章中指出,近年来以共享单车和共享充电宝为代表的共享消费领域服务价格一路上涨...。

在CNCC大会前的专访中,倪明选教授说道,CNCC2021大会将于10月28日在深圳开幕,今年的CNCC堪称史上规格最高、规模最大的一届,大会邀请2位图灵奖得主,数十位院士、上百位资深专家;开设111场技术论坛,涵盖学术、技术、产业、教育、科普等32个方向,参会者预计首次突破一万人,创立于2003年的CNCC,已经成功举办了十七届,每...。

发表在综合交流大区2022,6,917,02很多小伙伴会发现自己家的投影仪为什么寿命没有宣传上说的那么久呢,有时候画面还会出现斑纹,光圈的现象;实际上看似密闭的投影仪产品在使用的过程中会吸入大量的灰尘,不正确的使用方法都是减少投影仪使用的年限的因素;那平时在使用投影仪的时候应该注意哪些方面呢,我们要怎么对投影仪去进行保养呢,下面为大家...。

国士的意思是指一国之中才能出众的人,类似于天才、杰出人士等含义,国士一词在中国文化和历史中广泛应用,以下是关于国士的详细解释,1.基本定义,国士,字面意思是国家中的杰出人才,在古代,这一术语多用于描述在军事、政治、文化等领域作出突出贡献的人物,他们以其卓越的才能和功绩,赢得社会的广泛尊敬和赞誉,2.历史背景,在中国古代,国士的概念往往...。

近日,家住上海市静安区,武泰公寓,的多位业主向,资讯坊,同心服务平台反映,小区里有一户顶楼业主,20年间陆续在屋顶公共区域搭建违建空间,上个月,这户业主居然无以复加,动用吊车将砖块、水泥吊运至屋顶开局创新存量违建,小区居民们都感到放心忡忡,在屋顶如此大兴土木会给大楼带来安保隐患,记者到来,武泰公寓,,业主们通知记者,该小区始建于200...。

官方网址,对于360安捍卫士的简介,2008年3月,周鸿祎先生任奇虎公司董事长时期,把原奇虎公司旗下产品360安捍卫士剥离进去,打形成独立公司,360安捍卫士是国际受欢迎收费安保软件,它领有查杀盛行木马、清算恶评及系统插件,治理运行软件,系统实时包全,修复系统破绽等数个微弱配置,同时还提供系统片面诊断,弹出插件免疫,清算经常使用痕迹以...。

淮安汽车托运费用多少钱一公里?汽车托运是现代社会中十分广泛的一种运输模式,它可以协助人们将汽车从一个中央运输到另一个中央,而不用亲身驾驶汽车,淮安汽车托运费用多少钱一公里?这是很多人都十分关心的疑问,在中国中原,汽车托运费用是依据距离来计算的,普通来说,每公里的费用在1.2元到1.6元之间,淮安的汽车托运多少钱规范是依照市区之间的距离...。

沙丁鱼星球app下载-沙丁鱼星球app是一款非常不错的电商社交类手机软件,沙丁鱼星球app有着大量的品牌商家入驻。感兴趣的小伙伴们快来下载沙丁鱼星球app试试吧!,您可以免费下载安卓手机沙丁鱼星球。

1998年11月11日,这个日子是马化腾和其他四位合伙人一起创立腾讯帝国的日子,但是,很多人却不知道一个秘密,他们5个去注册公司时腾讯董事长的职位并不是马化腾,而是马化腾的母亲黄惠卿,但是黄惠卿从未到过腾讯公司,究竟是为什么呢?马化腾、张志东、曾李青、许晨晔、陈一丹他们五个第一次就成立公司的事情见面是在一家叫做龙脉公司的小办公室里,五...。

23日最新消息,一个月前刚刚宣布关闭个人云存储业务的360云盘今日在官网发出公告,宣布正式开通企业云盘服务,360表示,此次开通的企业云盘主要针对小微企业、创业团队和个人工作室,主打专业、安全、便捷的企业级云存储服务,原360个人云盘账号可直接登录,无需再重新注册,只不过登录后必须进行实名认证和服务套餐的购买,服务开通后,用户可以将原...。

首先,值得庆幸的是,微店的基础版本通常是免费的,这意味着,商家在注册微店账号后,即可享受上传商品、进行基本的店铺运营等一系列服务,而无需支付任何费用,这一政策极大地降低了创业门槛,使得更多有志于电商领域的人能够轻松迈出首先步,然而,随着店铺规模的不断扩大和业务的逐渐深入,商家可能会发现,基础版本的功能已无法满足日益增长的运营需求,此时...。

城市的形成,无论多么复杂,无外乎两种,因,城,而,市,和因,市,而,城,前者是城墙高筑,集市兴起,遂而繁荣;后者是贸易盛行,处所固定,遂有边界,随着更多的政治、经济、文化、法治的内容增加进来之后,城市文明逐渐走向高级,人类也在完成某种意义上的‘城市大迁徙,现在的城市,完成了地理信息学的定义、建筑规划学的定义、政治区域上的定义,正走...。

发表在米家投影仪2022,4,1516,47小米全色激光影院是小米在2020年发布的一款超短焦三色激光电视,售价6999元,相比其他价格动不动几万的全色激光电视,这款设备的价格确实让不少用户惊讶,那么小米全色激光影院的实际使用效果如何呢,下面就通过真实使用评测来了解一下吧,1.小米全色激光影院开箱小米全色激光影院纸盒材质的外壳包装让设...。
