2017最佳论文 ICML 模型预测率突然提高了 为什么你改了一个参数 (2017最佳新秀是谁)
雷锋网 AI 科技评论按:正在进行的2017 机器学习国际大会(ICML 2017)早早地就在其官网公布了本次会议的最佳论文评选结果( 重磅 | ICML 2017最佳论文公布!机器学习的可解释性成热点 ),其中最佳论文奖为《Understanding Black-box Predictions via Influence functions》,其主题为如何利用影响函数理解黑箱预测。两位作者分别为Pang Wei Koh 和 Percy Liang。
Pang WeiKoh是来自新加坡的斯坦福大学在读博士生。他此前在斯坦福获得了计算机科学学士与硕士学位,并在斯坦福的AI实验室与吴恩达一同工作过。在2012年,他加入了吴恩达联合创立的在线教育平台Coursera,成为其第三位员工。在2016年他开始在斯坦福攻读博士学位。
Percy Liang是斯坦福大学的助理教授,此前曾在MIT和UCB学习及做研究。他的研究大方向是机器学习与NLP,目前的研究重点是可信任的代理,这些代理能与人类进行有效沟通,并通过互动逐步改善。
在8月7日下午,最佳论文奖得主Pang Wei Koh(来自新加坡的斯坦福大学在读博士生)就他们的工作做了一场报告。雷锋网 AI科技评论在大会现场记录了这场报告,下面为雷锋网AI科技评论对现场Pang Wei Koh的报告进行整理,与大家共同分享。
图文分享总结
大家下午好,感谢大家来聆听这个报告。
动机
下面我将讲述如何用一种被称为影响函数的统计工具来研究神经网络的预测问题。

在过去几年,机器学习在许多领域中的模型做出的预测准确度越来越高,但是这些模型本身却也变得越来越复杂。然而一个经常会被问到的问题——系统为什么会做出这样的预测?——却难以回答。

例如我们通过图中左侧的训练数据来训练一个网络,当输入一张图片时它会做出一个预测。为什么这个模型做出这样的预测呢?我们知道模型学习的所有信息和“知识”都是从训练实例中得出的,所以应该可以查询特定预测受到各种数据点的影响有多大。

如果一个特定的训练点不存在或被微弱扰动,例如这里对经验风险函数进行微调后,预测的置信水平就会由79%提升到82%。那么两次预测的损失函数的差就可以代表某个训练点改变后对整个训练的影响。
影响函数

在这里我们的目标就是测量如果我们增加经验风险函数的值,损失函数的改变。这里结构风险函数是由具体的训练数据决定的。在函数取光滑条件时,那么这个测量值就是这个函数I,也即影响函数。这个公式第二行中的H是Hessian矩阵。从这里我们可以看出,影响函数是依赖于具体的模型和训练数据的。

例如我们看两个例子。右侧两列中第一列是用像素数据训练的RBF SVM,第二列是逻辑回归模型。用这两个模型分别对左侧的测试图形进行预测,我们得到的影响函数,RBF SVM模型的影响函数随着距离测试物越远会迅速减下,而逻辑回归模型的影响函数则与距离无关。所以我们可以利用影响函数来更好地理解模型。在我们看影响函数的应用之前,我们要先讨论一下这种方法中潜在的问题。
第一,计算效率低

要想实用影响函数,我们必须构建经验风险函数的Hessian矩阵以及求矩阵的逆。这对有几百万个参数的神经网络模型来说是难以接受的,尤其是求逆过程将会非常缓慢。

最好的办法就是我们不明确地求出Hessian矩阵的逆,而是通过Hessian-vector products近似。
第二,非光滑损失
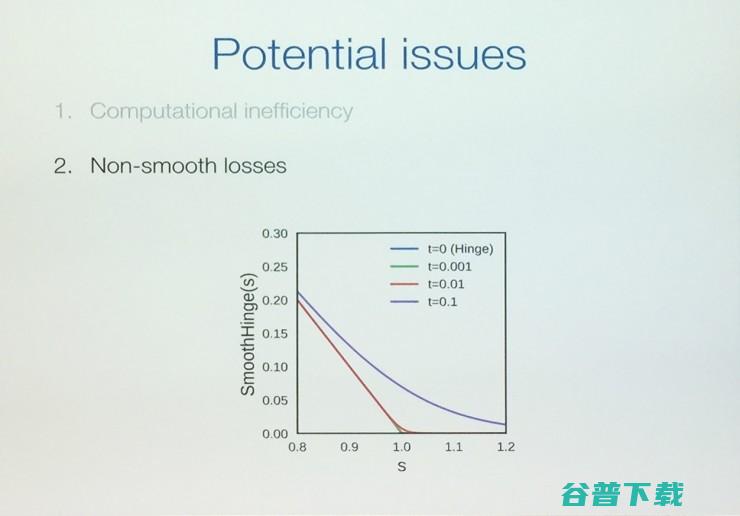
当损失函数的一阶、二阶导数不存在时,我们可以通过剔除这些非光滑的点,我们发现仍然能够很好地预测。例如这里的smoothHinge模型,当t=0.001的时候能够更好地符合实际的改变。
第三,很难找到全局极小值

在前面我们假设了为全局极小值,但是有时我们可能只是得到一个次极小值。这种情况下可能会导致Hessian出现负的本征值。
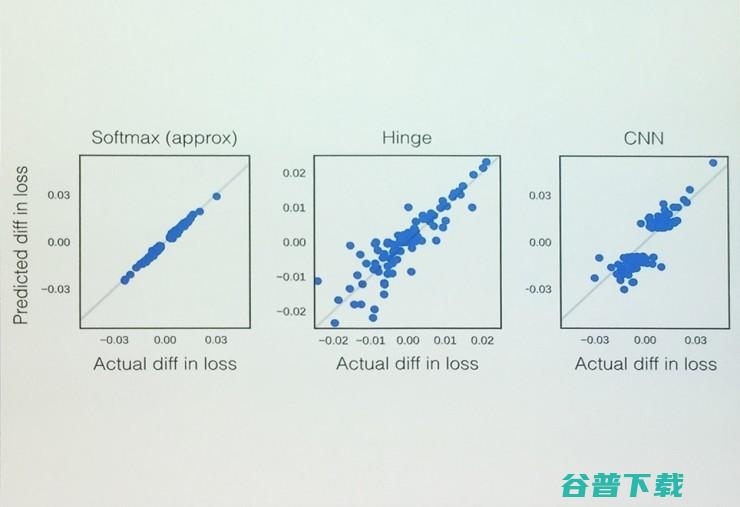
我们通过凸二次近似方法对损失函数构建一个软极大值来取近似。这样可以在很大程度上降低因为是非全局极小值造成的问题。
应用
好了,最后我们讲一下影响函数的应用。
1、调试模型错误

当模型出现错误的时候我们能否帮助开发者找出哪地方出了问题呢?我们用一个例子来说明,我们用逻辑回归模型来预测一个病人是否应当重新入院。训练模型有20k的病人,127个特征。

为了说明情况,我们把训练模型中3(24)个孩子需要重新入院改成3(4)个,也即去掉20个健康孩子的训练样本。当用一个健康孩子来做预测时,模型就会出错预测为需要重新入院。

我们计算每一个训练点的影响函数。这个图很清楚显示了4个训练孩子的影响值是其他样本的30-40倍,其中一个孩子为正,其他3个为负。
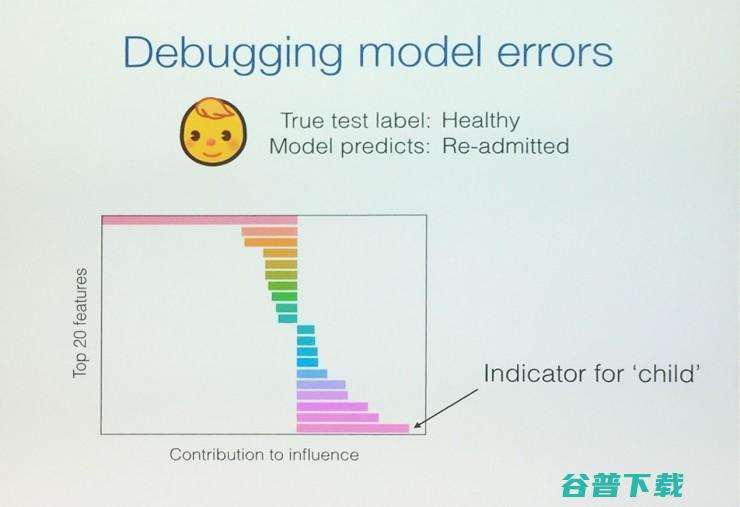
仔细考察4个孩子的127个特征,发现表示为“孩子”的特征起主要贡献。
2、对抗训练

最近的工作已经产生了与实际测试图像无法区分的对抗测试图像,以致完全可以愚弄分类器。实际上,Ian Goodfellow在内的一些研究者已经表明了高准确率的神经网络也是可以被欺骗的,用来欺骗它的样本是精心选择过的,人眼看起来正常。这样的样本就叫做“对抗性测试样本”。
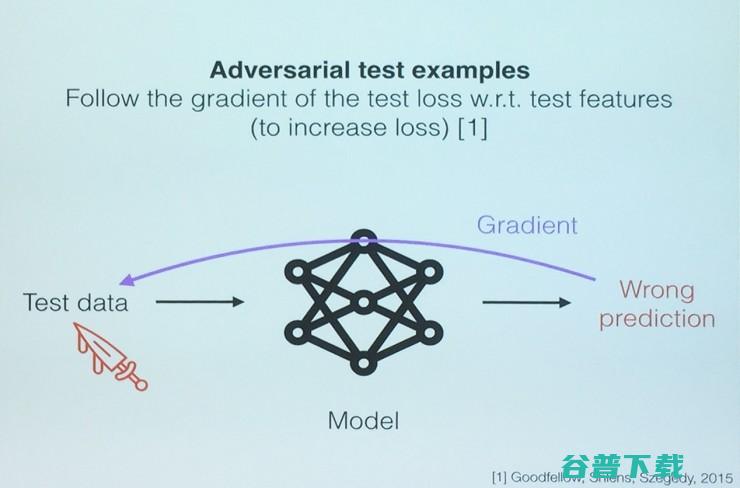
构建它们的方法之一是沿着测试输入对应的测试损失的梯度,不断修改测试输入,从而让测试损失增大。

那么既然有对抗性测试样本,我们能否创造出对抗性训练样本呢,其中训练点上的小变化就可以改变模型的预测结果。

我们问了自己这个问题,然后接下来很自然地就尝试在测试损失的梯度上做同样的事情。不过现在不是做关于测试特征的,而是做关于训练特征的。换句话说,我们先给定测试样本,然后沿着测试样本的梯度变化修改训练数据。

然后我们发现,它的影响函数可以帮助我们找到这个梯度,因为它们根本上是一回事,随着训练的进行,模型的预测上会发生的事情就是这样。我们得到的结果是这样的,从数学的角度讲它和基于梯度的攻击是一样的,对不同的模型和数据集都可以起作用。

这样的方法在实际应用中也可以发挥作用,我们设计了简单的二分类任务,模型要确定图像中的是狗还是鱼,两种东西看起来挺不一样的。我们用到了一个 Inception 那样的逻辑回归模型。令我们惊讶的是,如果仔细地选择训练数据,然后仔细地选择要增加在其中的干扰,那么训练数据中一点点的改变,就可以让同一个类型的多张测试图像的预测结果都出现问题。这说明这样的攻击在某些环境下具有相当的危险性。这个问题上其实还有很多值得研究讨论的,待会儿我们可以再聊。

结论
最后做个简单的总结。我们先讨论了模型是如何做出预测的。我们知道模型是通过训练数据得到的,我们将其写成公式,然后就知道改变训练数据以后模型会如何变化,而且我们还能通过它偏离训练数据的程度更好地理解模型的预测结果。影响函数为这些事情提供了一种高效的手段。

在这项工作中,我们还有很多事情需要做,例如如果从医院里移除了所有的病人怎么办,我们有什么办法防止这件事发生吗?如果我们有一个很大的凸模型,运行SGD好几次,……目前工作只是在这个方向上的一小步。在能够很好地理解模型之前,还有很多基础的问题等待我们去解决。
谢谢大家!
(完)
雷锋网 AI 科技评论整理。
论文下载:
重磅 | ICML 2017最佳论文公布!机器学习的可解释性成热点
原创文章,未经授权禁止转载。详情见 转载须知 。



亿克公积金代办服务网是您身边专业快速的公积金代办代取公司,速度快,收费低,在职/离职/封存-均可代办。代办经验丰富,正规流程,专业团队,欢迎来电话咨询亿克电子科技有限公司,电话:13688608225

聊城市坚美金属制品有限公司主营天津大无缝钢管,无缝方管,方矩管,大口径厚壁方管,无缝钢管零售等。电话:1340638500015165837888

贵州广恒达钢结构有限公司专注于钢结构工程、活动板房、彩钢大棚、车间净化工程设计、加工、安装,为贵州省贵阳、遵义、六盘水、安顺、铜仁、毕节、黔东南、黔南、黔西南等地区的客户提供一站式优质服务,源头工厂、质量好、价格低!

【深圳福荣鑫精密机械】专业生产精密设备零部件,零部件生产解决方案,专业航空,军工精密五金零部件加工,铝合金/钛合金等金属切削加工,CNC精密切削加工,专业金属车铣磨钳加工,非金属材质加工生产,精密自动化设备零件生产加工

丽蓓网致力于为您提供专业、个性化的整形美容解决方案。我们携手权威专家,为您量身定制美丽计划,全方位满足您的美丽需求。在这里,美丽不再是遥不可及,让您轻松实现外在美的全面提升。

广州驰早信息科技有限公司为企业提供短信平台、短信通道、短信发群发服务。

江西新余康展高级技工学校是经江西人力资源和社会保障厅批准的,位于江西新余面向全国招生的一所全日制高级技工学校,为江西省重点建设精品专业学校,培养高技术人才,咨询热线:13879190154

开眼是一个全球精品短视频平台,汇集了动画、广告、影视、运动、创意、游戏、旅行等领域的优质短视频以及这些领域的创意人群。

山西追梦科技有限公司拥有最新网站建设技术与优秀的网站设计服务经验,成功为众多企业提供了优秀的网站建设,网站设计,网页制作,网站优化等设计方案

传奇私服发布网(sf999.Com),提供新开传奇网站发布信息,第一时间发布今日新开传奇私服列表及游戏资讯,最大传奇私服发布网是传奇私服游戏玩家首选搜服平台。

中铁花水湾温泉酒店位于成都市大邑县花水湾度假小镇中心位置,海拔880米,与道教圣地鹤鸣山、西岭雪山相邻,森林覆盖率达85%,负氧离子含量极高。

北京眼神科技有限公司,专注于多模态生物识别技术的研发与应用,拥有人脸识别、虹膜识别、指纹识别、指静脉识别、机器视觉等多种自主知识产权核心算法,解决人工智能场景中的人机交互和强身份认证问题。


在3Q鏖战正酣之时,有评论指出,这反映了国家相应立法的缺失,最后在政府介入下,双方产品互相恢复兼容,偃旗息鼓,时至今日,试行条例出台,当时QQ是可以弹出很多广告的,360推出了一个产品,叫,扣扣保镖,,这样你用QQ的时候可以不弹出这些广告,甚至一些QQ的功能可以关掉,可以不用,但是那些东西QQ是要用来赚钱的,于是QQ发表了一个声明,说...。

来自青海省公安厅治安总队消息,12月1日起,青海省范围内全面实施居民身份证换补领,全程网办,为贯彻落实公安部和省委省政府推进,互联网,政务服务,工作,持续推进公安机关治安管理,放管服,改革,进一步提升公安政务服务效能,青海公安积极对接,互联网,公安政务服务平台,工作,实现了居民身份证换补领,全程网办,居民身份证换补领,全程网办,服...。

硅谷钢铁侠马斯克绝对称得上是世界上最棒的实干家,他脑中的疯狂创想简直取之不尽用之不竭,如用可回收火箭探索火星、在真空管道中的建超级高铁,而且人们总是无条件相信,毕竟马斯克说到做到,2017年,精力旺盛的马斯克再次下海创业,公司名为Neuralink,顾名思义,他要开发脑机接口,让人脑与电脑相连,2019年7月16日,Neuralink...。

双语原文链接,Pseudo,LiDAR—StereoVisionforSelf,DrivingCars在自动化系统中,和计算机视觉已经疯狂地流行起来,无处不在,计算机视觉领域在过去十年中发展迅速,尤其是是障碍物检测方面,障碍物检测,如YOLO或RetinaNet,提供2D的标注框,该标注框指明了障碍物在图像中的位置,为了获取每个障碍物...。

前日,泰晤士高等教育,THEWorldUniversityRankingsbySubject,发布了2023年世界大学学科排名的结果,在计算机科学学科排名中,前十名由国外高校包揽,英美占据多数,中国高校有清华大学、北京大学2所院校进入前二十名,12所进入前一百名,其中,清华大学位居国内第一、亚洲第二,泰晤士世界大学学科排名涵盖工程技术...。

zuojun大神级投影控发表于2024,03,06DLP,数码光处理技术,DigitalLightProcessing,,是利用微型芯片上的许多微小反射镜投射图像的一种数字投影技术,DLP技术的特点在于色彩饱满、色彩过渡自然、对比度高、暗部细节好、较小的尺寸和重量、长寿命、维护成本低等,缺点是存在彩虹现象,即由于DLP投影灯光在很短时...。

为什么会有专门水站的存在,着实是因为外部水污染严重,即便是通过自来水管道输送到家里的水烧开以后或许也会有味道,因此我们需要更洁净的水资源,位于社区附近的水站就成了很好的选择,普利思水站就是抓住水资源商机出现在市场上的品牌之一,目前已在不小区域内完成了站点布局,各个站点的经营情况还都很不错,于是普利思水站加盟问题开始广泛受到关注,普利思...。

十二星座配的小宠物如下,小狗、仓鼠、鹦鹉、猫咪、金毛、兔子、鱼、蜥蜴、猫、狗、猫、鱼,1、小狗白羊座的人激情开朗,生机充沛,青睐有生机和忠实的小狗陪伴在身边,小狗的忠实和生机能够和白羊座的人构成很好的共鸣,让白羊座的人觉得很有安保感,2、仓鼠金牛座的人平和持重,青睐一些小巧可恶的生物,例如仓鼠,仓鼠小巧可恶,青睐安静,和金牛座的人十分...。

建造国度招兵买马打仗类手游有哪些,大家可以在这里体验到许多的建造国度招兵买马打仗类手游,让咱们能够自在的建造国度,实现抗争,有着许多的打仗玩法,让咱们可以去实现游戏中的作战,史诗抗争模拟器2中文版古国崛起手游下载小小大抗争2中文版建造国度招兵买马打仗类手游有哪些1、史诗抗争模拟器2中文版介绍理由,史诗抗争模拟器2中文版游戏中玩家可以感...。

幸福是一颗可以传递的种子_苗靳婉青_新浪博客,苗靳婉青,

佳能mg3080打印机驱动是一款专门针对佳能旗下的同名打印机产品推出的官方配套驱动程序,用户只需通过安装这款驱动,即可让你的打印机正常工作

备案后改网站名称可以吗问备案后网站名称可以改吗答可以改动改动以后不会影响到你备过的情况但下次系统再次清查的时候可能会扫描到网站与备案情况的不符合其实现在你风站情况已经通过备案了所以你可以把你网站的名称改成你想要的名称然后再次再入系统提交你的备案号必码进行修改把你备案的名称也再改成你现在要用的名称这样就可以了现在备案也没...

玩家们要是喜欢模拟经营农场类型游戏的话,可能有的时候就会想不起来关于以前最火的农场游戏叫什么,这其实没有什么问题,因为游戏太多了,玩家们想要找的话还是挺难的,但是你们可以看看这篇模拟农场手游的文章,说不定在其中,你们也可以见到自己喜欢的其它款式,快来看看吧,1、,梦想城镇,这款,梦想城镇,绝对是对于农场模拟的类型当中,一款比较别出心意...。

听歌是大多数人的爱好,闲暇无聊的时候听听歌能让心情豁然开朗,早上挤公交、挤地铁的时候听听歌也能让精神焕发,今天小编带大家了解一下听歌免费的音乐软件哪个好,如果平时你也非常喜欢听歌,就可将今天的内容了解一下,选择一款比较好用的听歌软件下载到手机上,方便随时随地来听各种好听的音乐,使用该软件不仅可播放本地音乐,也可播放网络上的音乐,拥有众...。

很多小伙伴在做抖音、小红书、知乎、视频号等平台时都会遇到这样的问题,如果你有钱,你可以把钱直接花在广告上,比如dou,,千川投放等,只要视频内容质量不太差,一个月花个十几二十万推广肯定能把数字搞上去,然而,这种氪金玩法并不适合所有人,今天给朋友们分享一个不用花钱也能做账的小技巧——找对标,想在任何事情上取得成功,就得学会观察同行的账号...。

一颗芯片的诞生,需要经历芯片设计、制造、封装和测试等步骤,其中芯片设计和制造是最为核心和困难的环节,但相对设计而言,因为受资金和技术的限制,晶圆制造厂更为稀缺,对于任何人而言,如果想要制造芯片,在已经拥有RTL,电阻晶体管逻辑电路,的前提下,还需要克服两大障碍,一是从芯片代工厂获得工艺设计套件,PDK,,二是有足够的资金支付制造费用,...。

6月2日,美团,股票代码,3690.HK,发布2022年第一季度业绩,本季度,美团各项业务实现稳步增长,季度营收达463亿元,人民币,下同,,同比增长25%,财报信息显示,美团继续深入推进,零售,科技,战略,持续加大关键领域科技研发投入,单季研发支出同比增长40%至49亿元,企业研发费用占收入比接近11%,期间,在政府相关部门指导下,...。
