2022 新型图数据增强方法 杰出论文 G ICML 莱斯大学胡侠团队 (2022新型材料合集)

近日,备受关注的第十九届机器学习国际会议(ICML 2022)在美国马里兰州巴尔的摩市举办。自新冠疫情以来,大会首次恢复线下形式,采取线上线下结合的方式举办。
15 篇杰出论文奖和 1 项时间检验奖。 复旦大学、上海交通大学、厦门大学、莱斯大学等多个华人团队的工作被评位杰出论文奖。 ICML 2012 的一篇论文《Poisoning Attacks against Support Vector Machines》获得了时间检验奖。
今年的杰出论文奖不同寻常,评选数量多达 15 篇。而同样是 21% 左右的接 篇杰出论文,去年则仅有1篇。
本文我们来关注一下今年获奖的一篇优秀工作。AI 科技评论此次采访到 获得杰出论文奖的莱斯大学胡侠团队, 为我们解读他们的研究工作。该团队的获奖论文题目为:

在这项研究中,作者提出了一种新的图数据增强方法: 提高图神经网络的泛化性和鲁棒性。
胡侠,现任美国莱斯大学终身副教授,数据科学中心主任,AIPOW联合创始人兼首席科学家。其主导开发的开源系统AutoKeras成为最常用的自动机器学习框架之一(超过8000次star及1000次Fork),开发的NCF算法及系统(单篇论文他引3000余次)成为主流人工智能框架TensorFlow的官方推荐系统,主导开发的异常检测系统在通用、Trane、苹果等公司的产品中得到广泛应用,研究工作多次获得最佳论文(提名)奖。
图数据在我们的现实生活中无处不在,我们可以使用图来建模和描述各种复杂网络系统。而为了将图数据应用于具体任务,我们首先需要对图数据进行表征。近年来,通过深度学习技术对图数据进行表示学习的图神经网络(GNNs),在节点分类任务上取得了最优性能,因而已被广泛用于图形分析。同时,数据增强(data augmentation)和 Subgraph(子图)也被用于图分析,它们通过生成合成图来创建更多训练数据,以提高图分类模型的泛化性能。
当前流行的数据增强方法 Mixup 通过在两个随机样本之间插入特征和标签,在提高神经网络的泛化性和鲁棒性方面显示出优越性。但是,Mixup 更适用于处理图像数据或表格数据,直接将其用于图数据并非易事,因为不同的图通常:(1)有不同数量的节点;(2)不容易对齐;(3)在非欧几里得空间中的类型学具有特殊性。
为此,提出了一种 class-level 的图数据增强方法: 。具体来说,首先使用同一类中的图来估计一个 graphon。然后,在欧几里得空间中对不同类的 graphons 进行插值,得到混合的 graphons,合成图便是通过基于混合 graphons 的采样生成的。经实验评估,G-Mixup 显着提高了图神经网络的泛化性和鲁棒性。
G-Mixup 是一种通过图形插值的class-level数据增强方法。具体来说,G-Mixup 对不同的图生成器(graphon)进行线性插值以获得新的混合的生成器。然后,基于混合的新的生成器对合成图进行采样得到新的图数据以进行数据增强。改论文从理论上证明从该生成器中采样的图部分具有原始图的属性。
如图1所示,G-Mixup包括三个关键步骤: (1)为每一类图估计一个graphon,(2)混合不同图类的graphons,以及(3)基于混合的graphons采样生成合成图。
 图 1:在二值图分类任务中,有两类不同的图 G 和 H,二者拓扑不同(G 有两个社区,而 H 有八个社区)。G 和 H 具有不同的graphons。
图 1:在二值图分类任务中,有两类不同的图 G 和 H,二者拓扑不同(G 有两个社区,而 H 有八个社区)。G 和 H 具有不同的graphons。
Graphon 估计和 Mixup 。作者使用矩阵形式的阶进函数作为graphon来混合和生成合成图。对阶跃函数估计方法,作者首先根据节点测量值将节点对齐在一组图中,然后从所有对齐的邻接矩阵中估计阶跃函数。
合成图的生成 。一个 graphon W 提供一个分布来生成任意大小的图。
G-Mixup 的性能评估
那么,G-Mixup 在真实世界的图数据上表现如何?作者团队对 G-Mixup 的性能进行了评估。
一个数据集中不同类别的图的 graphons 显著不同。 图 2 表明现实世界中不同类别的图有完全不同的graphons,这为通过融合 graphon 来生成混合的图奠定了基础。
 图2:IMDBBINAERY 的 graphons 显示 class 1 的 graphon 有更大的密集区域,这表明该类中的图比 class 0 中的图具有更大的社区。REDDIT-BINARY 的 graphons 显示,class 0 中的图有一个高度节点,而 class 1 中的图有两个。
图2:IMDBBINAERY 的 graphons 显示 class 1 的 graphon 有更大的密集区域,这表明该类中的图比 class 0 中的图具有更大的社区。REDDIT-BINARY 的 graphons 显示,class 0 中的图有一个高度节点,而 class 1 中的图有两个。
G-Mixup 合成的图是原始图的混合。 作者团队将在 REDDIT-BINARY 数据集上生成的合成图进行可视化,如图 3,混合 graphon(0.5∗W0+0.5∗W1) 能够生成包含高度节点和密集子图的图,这可看作是包含 1 个高度节点和包含 2 个高度节点的图的混合图。这验证了 G-Mixup 更倾向于保留来自原始图的区别性图案,其合成图确实是原始图的混合。

图3:在 REDDIT-BINARY 数据集上生成的合成图的可视化。
G-Mixup 可以提高 GNN 在各种数据集上的性能。 作者比较了使用 G-Mixup 的各种GNN主干网络在不同数据集上的性能。 实验结果表明,G-Mixup可以提高图神经网络在各种数据集上的性能。
G -Mixup 可以提高 GNN 的鲁棒性 。作者对 G-Mixup 的两种鲁棒性(标签腐蚀的鲁棒性和拓扑腐蚀的鲁棒性)进行研究,发现 G-Mixup 能够提高 GNN 的鲁棒性。
这项工作提出了一种名为 G-Mixup 的新型图增强方法。与图像数据不同,图数据是不规则的、未对齐的且处于非欧几里得空间中,因此很难进行混合。然而,同一类别中的图具有相同的生成器(即graphon),它是规则的、良好对齐的且处于欧几里得空间中。因此,作者转而对不同类别的 graphons进行混合来生成合成图。综合实验表明,使用 G-Mixup 训练的 GNN 获得了更好的性能和泛化能力,并提高了模型对噪声标签和被损坏拓扑的鲁棒性。
AI 科技评论:祝贺你们的研究获得ICML 2022杰出论文奖。首先,能否概括一下你们这项工作的主要贡献?
作者团队: 我们提出了 G-Mixup 来增强用于图分类的训练图。由于直接混合图是难以处理的,因此 G-Mixup 将不同类别的图的图元混合以生成合成图。其次,我们理论上证明合成图将是原始图的混合,其中源图的关键拓扑(即判别主题)将被混合。最后,我们证明了所提出的 G-Mixup 在各种图神经网络和数据集上的有效性。大量的实验结果表明,G-Mixup 能够增强图神经网络的泛化性和鲁棒性。
AI 科技评论:当时论文收到的审稿意见是怎样的?
作者团队:审稿意见总体比较 positive,不过当时审稿人对我们做数据增强的意义有一点疑问,我们对此作了详细的解释,比如就训练而言,有时训练数据集特别少,我们就可以用数据增强来获取更多的数据。审稿人在最后的意见中也表明认识到了数据增强的重要意义。
AI 科技评论:与以往的Mixup方法相比,G-Mixup的不同之处在什么地方?
作者团队: Mixup 技术主要应用在图像上,已经比较成熟,它是将训练数据中的两个数据集线性地加起来,得到一个新的训练数据,从而完成数据扩增。但它在图数据上还没有一个很好的解决方案。而我们的G-Mixup 是一个简单且有效的方法,它是对不同类别的图生成器进行混合来生成合成图。
AI科技评论:与图像数据和表格数据相比,对图数据做mixup的难点在什么地方?
作者团队: 目前针对图的mixup的研究比较少,因为图数据比较难处理,它不容易表示,而且两个图的节点数量、无结构信息是不一样的,所以很难将其融合到一起。图像数据和表格数据可以表示成连续的向量或矩阵的形式,所以很容易做融合,但图数据无法表示成这种形式。
AI科技评论:为什么说G-Mixup 是一种Class-level的图数据增强方法?
作者团队: 我们是用两个类来生成一个新的类,我们用多张图来估计图的生成规则也就是图的生成器,然后对每一类图来估计一个生成器,这样来生成一个新的类别。以往针对图像的mixup是用两张图片来做,属于instance-level,但针对图的处理方法与此不同。
AI科技评论:有哪些途径可以提高图神经网络的泛化性?
作者团队: 比如设计新的网络结构,做数据增强,以及训练技巧方面的一些工作,都可以提高泛化性,我们这项工作展示的是其中一种方法。
AI科技评论:针对这项工作所研究的问题,有什么下一步的研究计划?
作者团队: 我们这项工作提出的方法主要是用于图分类任务,以后我们可以进一步考虑在节点分类任务上做融合,节点分类也是图神经网络方面的一个重要任务。
AI科技评论:这次获得杰出论文奖,有没有什么经验、体会可以分享?
作者团队: 首先文章的写作质量要好,要将研究清楚地表述出来;研究的 idea 要十分合理;以及,研究问题本身要有意义和价值。
AI科技评论:这项研究的成果对相关领域有怎样的影响?有哪些实际应用的价值?
作者团队: 由于图数据的本身特性,使得mixup这个在其他数据上很有效的方法不能直接适用在图数据上,我们提出的g-mixup使用了图生成器去融合图数据,实现了class-level的图数据mixup, 希望能对图数据的mixup能有一定的启发作用。希望提出的方法能够在图生成,新药物发现方向能有一定的启发。

版权文章,未经授权禁止转载。详情见 转载须知 。



江苏品冠人造草坪有限公司

腾讯开放平台,让天下没有埋没的才能!腾讯开放平台,不寂寞的平台!

网址导航――RC0991.COM是最实用的上网导航网站,是方便网民上网的入口平台,及时收录包括网络电视、电景、音乐、视频、小说、游戏等热门分类的优秀网站,与搜索完美结合,提供最简单便捷的网上导航服务,是数千万网民的上网主页。

五谷养生网是知名的养生门户网站,主要收录来自互联网的健康养生知识,旨在为广大网民提供养生保健知识,包括中医养生,食疗养生,运动养生,健康养生方法,春夏秋冬四季养生小常识等知识内容参考,是您健康知识的好助手!

河南坤锋钢结构有限公司主要从事各类铁路、公路、大型桥梁模板、钢制箱梁、高铁液压箱梁模板、隧道台车、悬浇挂篮、牵索挂篮、钢结构景观桥、各类钢结构的设计、加工、销售及周转料租赁与施工。

扶余市泾盛煜农业发展有限公司创建于2015年,位于吉林省扶余市长春岭镇,面积400余公顷,种植面积达6000亩。农场周边自然环境优越,水源丰富,水陆交通便捷,区位优势显著。农场以种植稻花香和长粒香等有机弱碱优质水稻为主,同时兼顾绿色有机蔬菜,水果种植、稻田蟹和稻田鸭的养殖。

SAWTX锯天下专注带锯条29年,差异化服务1000多家中外优质企业,直供双金属带锯条,硬质合金锯条,金钢石锯条...

南方布艺始建于1996年,是一家以高品质窗帘、软包、沙发、床上用品、办公卷帘、墙纸、灯饰等整体软装配套的室内装饰销售公司, 专业为高端楼盘、别墅、大型办公会所、五星酒店、工程等业务提供最佳室内设计和装饰方案,为客户打造一站式的家居软装采购中心。

中国国际纺织面料及辅料博览会,简称intertextile面辅料展,2025年将在3月和9月上海举办。详情请咨询:江先生13681789769

DmegoHome

欢迎访问吃瓜51网站,您的一站式娱乐资讯平台!我们为您提供最新的吃瓜新闻、娱乐八卦、社会热点、明星动态和时事评论。无论是想了解明星背后的故事,还是关注社会事件的发展,吃瓜51都能为您带来及时、专业的报道和深度分析。加入我们,和亿万网友一起“吃瓜”,掌握最新资讯!

为您提供最优质的汽车服务,在线车险,提供包括维修,保养美容,洗车,酒后代驾,二手车,非事故车道路救援等一站式汽车服务的解决方案——盛世大联网


泰山原浆啤酒紧跟市场发展,积极引进新产品,使产品更具竞争力,是一个典型的良心品牌,泰山原生质啤酒联盟以其独特的方式受到公众的青睐,行业内相对较低的联盟费用可以获得较高的收效,并吸引大量特许经营者讨论联盟事宜,泰山原浆啤酒今天取得了丰硕的成果,引起了巨大的反响,吸引了一大批来自远方的忠实粉丝,那么,泰山原浆啤酒加盟费用,代理泰山原浆啤酒...。

文字链接认证代码普通联盟标志认证代码企业广告联盟标志认证代码广告联盟评测代码说明,本页面的认证代码为蓝色广告联盟专用评测代码,站长需懂简单html知识,直接复制代码粘贴到联盟网站相应页面即可使用,本代码不适用于其他广告联盟网站请勿获取!文字认证,文字链接代码认证适用所有类型的广告联盟,复制代码后放在蓝色广告联盟网站首页底部或友情链接位...。

麻辣烫是时下流行的大众美食之一,它制作简单方便,而且口味多样,食材丰富,所以受到消费者的追捧,有一些投入者想学做麻辣烫,不知道学做麻辣烫要多少钱,接下来小编就为大家介绍一个美食培训学校以及他所需要的费用,北京唐人美食学校是一个涵盖西点、中餐、日韩西餐面点等多个种类的美食烹饪学校,性价比超高,技法全,内容广,能够给加盟者提供全面系统的烹...。

雷锋网消息,近日,深圳市精锋医疗科技有限公司,下称,精锋医疗,宣布完成近6亿元B轮融资,融资由LYFECapital,济峰资本,和康基医疗领投,老股东三正健康投资和国策投资联合领投,祥峰投资、博远资本、雅惠投资、老股东保利资本跟投,精锋医疗创始人王建辰博士表示,本次融资将用于支持精锋产品的临床实验、注册以及后续的市场营销工作,精锋...。

品牌型号,小米10系统,MIUI11mi10是小米公司旗下的一款手机,mi10的中文名是小米10,小米10于2020年2月13日在国内正式发布,于2020年3月27日在海外正式发布,手机采用左上角挖孔曲面屏设计,长度162.6毫米,宽度74.8毫米,厚度8.96毫米,重量208克,提供,钛银黑,、,蜜桃金,、,冰海蓝,和,国风雅灰,四...。

发表在当贝投影仪2021,6,314,38导读,小明q1投影仪是一款采用了LCD显示技术的千元投影仪,主打迷你轻便,且小巧的个头,吸引了不少消费者关注,而便携式家用投影仪多数也是小巧机身,当贝C2更是一款超有料的小投影,下面就跟着小神童一起来看看小明q1和当贝c2对比哪个好,1、外观对比从外观上来看,小明q1和当贝c2都是微型投影仪,...。

发表在专业问答2024,10,3114,40展示机型信息,品牌型号,当贝D6XPro系统版本,当贝OS4.0当贝投影仪连接遥控器可以通过按下遥控器的配对按键完成连接,总共可以分为三步,下面为当贝投影仪如何连接遥控器的详细步骤做具体说明,当贝投影仪如何连接遥控器1.开启投影仪按下当贝投影仪的开机键打开投影仪;2.遥控靠近投影将当贝投影仪...。

environment英[ɪnˈvaɪrənmənt]美[ɛnˈvaɪrənmənt,ˈvaɪən,]n.环境,外界,周围,围绕,上班平台,运转,环境双数,environments形近词,entironment1TheplanswillbeexaminedbyEUenvironmentministers.欧盟各国环境部部长将细心钻...。

天涯明月刀萧四无怎么打?打嘲天宫3号BOSS萧四无有什么特别的技巧吗?下面为大家带来的是天涯明月刀萧四无攻略,一起来了解一下吧。天涯明月刀萧四无怎么打现在打萧四无得控制输出,不然没出切割线就进2阶段,直接灭了,所以贪输出很没必要。现在的战力打这个本是输出溢出的,但这个本需要至少8个人会打才行,确实遇到新手不会打很难过。基本思路是一个人负责切线

莱维特DGT260声卡驱动是一款可在各种情况下提供清晰声音的电容式拾音多功能USB麦克风,功能强大,修音效果完美。软件特色莱维特DGT260是人声录音、配音、游戏、直播和播客以及在线教学的完美解决方案。其高性能电容拾音器提供了清晰的声音,在其同类别中设置新的基准。可定制的多色LED表达您的心情和风格,因为它以一种时尚的方式来指示I/O电平、削波、闪避等。使用

NewFileTime是用来修改文件时间属性的小工具,可以修改文件的创建时间、访问时间、和修改时间三项数据。修改文件时间信息的必备利器!可对单个文件进行修改

万众瞩目的数字人民币终于开放下载了,目前正在部分地区进行先行试点,要不了多久就会完全开放供大家使用。数字人民币的指定运营机构包括工行、农行、中行、建行、交行、邮储银行、招商银行、微众银行、网商银行等,与纸钞和硬币等价,具有价值特征和法偿性,
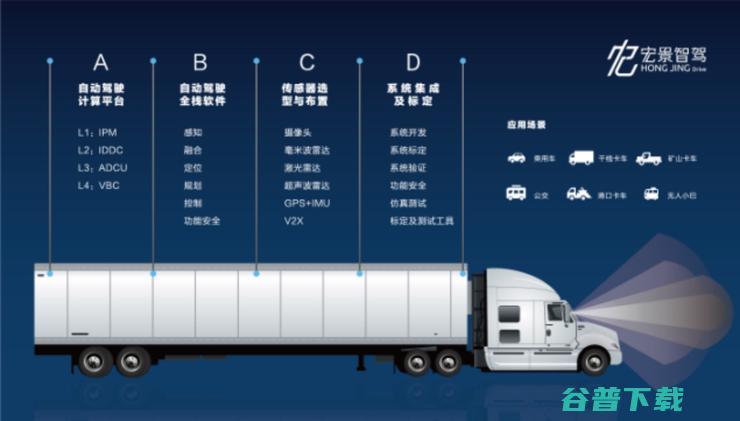
自动驾驶领域从不缺富有潜力的创业公司,尤其是在这个落地至上的时代,近日,宏景智驾宣布完成规模达亿元的A轮融资,该轮融资由领先投资机构达泰资本领投,德联资本和云九资本跟投,此外,老股东高瓴资本、蓝驰创投、Translink、线性资本、清研资本等机构纷纷超额跟投,宏景智驾创始人兼CEO刘飞龙透露,新一轮的融资工作也在有条不紊的推进当中,相...。

文字链接认证代码普通联盟标志认证代码企业广告联盟标志认证代码广告联盟评测代码说明,本页面的认证代码为奇优广告联盟专用评测代码,站长需懂简单html知识,直接复制代码粘贴到联盟网站相应页面即可使用,本代码不适用于其他广告联盟网站请勿获取!文字认证,文字链接代码认证适用所有类型的广告联盟,复制代码后放在奇优广告联盟网站首页底部或友情链接位...。

2022年以来,国内疫情对多个行业产生重大影响,实体业务往来受到严重冲击,供应链、人员流动受阻,生产、业务恢复减缓,企业迫切地希望挖掘新的增长点,找到新形势下的破局之路,在当前数字生产力快速崛起的新阶段,数字技术正在以不可阻挡得趋势深入到实体产业中,成为企业竞争的关键要素,科技向实,成为了新的时代趋势,科技为基础,数字化转型为引擎,陆...。

在2018年12月份的时候,上海有一名警察在自己结婚之后出轨了一名女性,经过调查了解之后,这名女性知道了警察有了妻子,而且还有了孩子,于是就前去找警察理论,但是当时警察的妻子也是在家里面的,所以说这夫妻两个人就一起联合起来,把这个女子打成了轻伤,在2019年3月,2019年12月5号的时候,这个女子多次被警方殴打,其实在最先开始的时候...。

陶艺文化是我国传统文化中的重要组成部分,随着国家对于传统文化的大力弘扬和重视,现在手工陶艺变得十分受欢迎,再加上二胎的开放,更好的推动了手工陶艺行业的发展,一些经验丰富的创业者抓住时机,加盟开手工陶艺店,陶语手工坊名气很响亮,加盟很不错,但是,陶语手工坊可以加盟吗,具体需要什么条件,陶语手工坊品牌已经创立发展很多年,在此期间,用自己的...。
