1v1胜率99.8% AI 腾讯绝悟 技术解读 2100场王者荣耀 (1v1胜率最高的英雄)
围棋被攻克之后,多人在线战术竞技游戏(MOBA)已经成为测试检验前沿人工智能的动作决策和预测能力的重要平台。基于腾讯天美工作室开发的热门 MOBA 类手游《王者荣耀》,腾讯 AI Lab 正努力探索强化学习技术在复杂环境中的应用潜力。本文即是其中的一项成果,研究用深度强化学习来为智能体预测游戏动作的方法,论文已被AAAI-2020接收。
此技术支持了腾讯此前推出的策略协作型 AI 「绝悟」1v1版本,该版本曾在今年8月上海举办的国际数码互动娱乐展览会China Joy首次亮相,在2100多场和顶级业余玩家体验测试中胜率达到99.8%。
除了研究,腾讯AI Lab与王者荣耀还将联合推出“开悟”AI+游戏开放平台,打造产学研生态。王者荣耀会开放游戏数据、游戏核心集群(Game Core)和工具,腾讯AI Lab会开放强化学习、模仿学习的计算平台和算力,邀请高校与研究机构共同推进相关AI研究,并通过平台定期测评,让“开悟”成为展示多智能体决策研究实力的平台。目前“开悟”平台已启动高校内测,预计在2020年5月全面开放高校测试,并且在测试环境上,支持1v1,5v5等多种模式;2020年12月,我们计划举办第一届的AI在王者荣耀应用的水平测试。
以下是本次入选论文的详细解读:

在竞争环境中学习具备复杂动作决策能力的智能体这一任务上,深度强化学习(DRL)已经得到了广泛的应用。在竞争环境中,很多已有的 DRL 研究都采用了两智能体游戏作为测试平台,即一个智能体对抗另一个智能体(1v1)。
其中 Atari 游戏和棋盘游戏已经得到了广泛的研究,比如 2015 年 Mnih et al. 使用深度 Q 网络训练了一个在 Atari 游戏上媲美人类水平的智能体;2016 年 Silver et al. 通过将监督学习与自博弈整合进训练流程中而将智能体的围棋棋力提升到了足以击败职业棋手的水平;2017 年 Silver et al. 又更进一步将更通用的 DRL 方法应用到了国际象棋和日本将棋上。
本文研究的是一种复杂度更高一筹的MOBA 1v1 游戏。即时战略游戏(RTS)被视为 AI 研究的一个重大挑战。而MOBA 1v1 游戏就是一种需要高度复杂的动作决策的 RTS 游戏。相比于棋盘游戏和 Atari 系列等 1v1 游戏,MOBA 的游戏环境要复杂得多,AI的动作预测与决策难度也因此显著提升。以 MOBA 手游《王者荣耀》中的 1v1 游戏为例,其状态和所涉动作的数量级分别可达 10^600和 10^18000,而围棋中相应的数字则为 10^170和 10^360,参见下表 1。

表 1:围棋与 MOBA 1v1 游戏的比较
此外,MOBA 1v1 的游戏机制也很复杂。要在游戏中获胜,智能体必须在部分可观察的环境中学会规划、攻击、防御、控制技能组合以及诱导和欺骗对手。除了玩家与对手的智能体,游戏中还有其它很多游戏单位,比如小兵和炮塔。这会给目标选择带来困难,因为这需要精细的决策序列和相应的动作执行。
此外,MOBA 游戏中不同英雄的玩法也不一样,因此就需要一个稳健而统一的建模方式。还有一点也很重要:MOBA 1v1游戏缺乏高质量人类游戏数据以便进行监督学习,因为玩家在玩 1v1 模式时通常只是为了练习英雄,而主流 MOBA 游戏的正式比赛通常都采用 5v5 模式。
需要强调,本论文关注的是 MOBA 1v1 游戏而非MOBA 5v5 游戏,因为后者更注重所有智能体的团队合作策略而不是单个智能体的动作决策。考虑到这一点,MOBA 1v1游戏更适合用来研究游戏中的复杂动作决策问题。
为了解决这些难题,本文设计了一种深度强化学习框架,并探索了一些算法层面的创新,对 MOBA 1v1 游戏这样的多智能体竞争环境进行了大规模的高效探索。文中设计的神经网络架构包含了对多模态输入的编码、对动作中相关性的解耦、探索剪枝机制以及攻击注意机制,以考虑 MOBA 1v1 游戏中游戏情况的不断变化。
为了全面评估训练得到的 AI 智能体的能力上限和策略稳健性,新设计的方法与职业玩家、顶级业务玩家以及其它在 MOBA 1v1 游戏上的先进方法进行了比较。
本文有以下贡献:
对需要高度复杂的动作决策的 MOBA 1v1 游戏 AI 智能体的构建进行了全面而系统的研究。在系统设计方面,本文提出了一种深度强化学习框架,能提供可扩展的和异步策略的训练。在算法设计方面,本文开发了一种用于建模 MOBA 动作决策的 actor-critic 神经网络。网络的优化使用了一种多标签近端策略优化(PPO)目标,并提出了对动作依赖关系的解耦方法、用于目标选取的注意机制、用于高效探索的动作掩码、用于学习技能组合 LSTM 以及一个用于确保训练收敛的改进版 PPO——dual-clip PPO。
在《王者荣耀》1v1 模式上的大量实验表明,训练得到的 AI 智能体能在多种不同类型的英雄上击败顶级职业玩家。
考虑到复杂智能体的动作决策问题可能引入高方差的随机梯度,所以有必要采用较大的批大小以加快训练速度。因此,本文设计了一种高可扩展低耦合的系统架构来构建数据并行化。具体来说,这个架构包含四个模块:强化学习学习器(RL Learner)、人工智能服务器(AI Server)、分发模块(Dispatch Module)和记忆池(Memory Pool)。如图 1 所示。
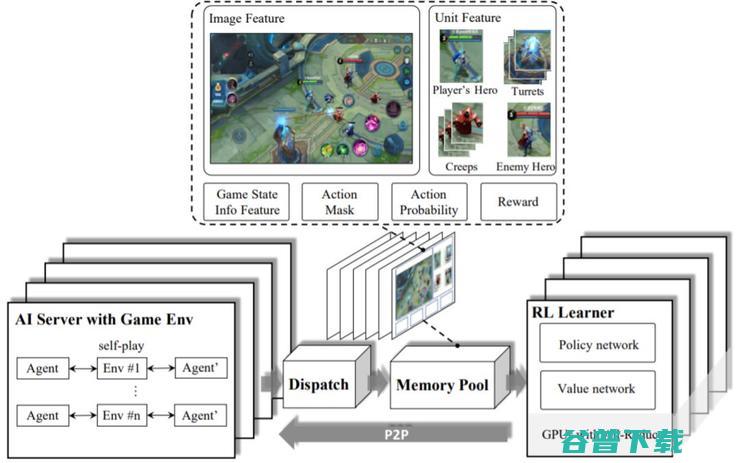
图 1:系统设计概况
AI 服务器实现的是 AI 模型与环境的交互方式。分发模块是用于样本收集、压缩和传输的工作站。记忆池是数据存储模块,能为RL 学习器提供训练实例。这些模块是分离的,可灵活配置,从而让研究者可将重心放在算法设计和环境逻辑上。这样的系统设计也可用于其它的多智能体竞争问题。
RL 学习器中实现了一个 actor-critic 神经网络,其目标是建模 MOBA 1v1 游戏中的动作依赖关系。如图2所示。
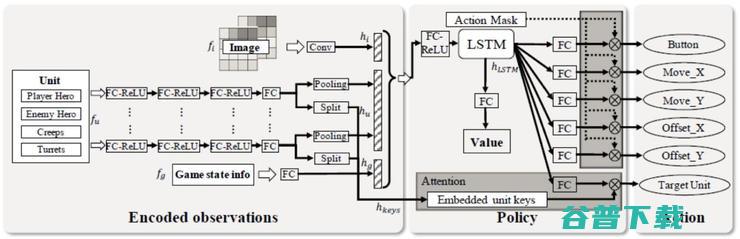
图 2:论文实现的actor-critic网络
为了实现有效且高效的训练,本文提出了一系列创新的算法策略:
1.目标注意力机制:用于帮助AI在 MOBA 战斗中选择目标。
2.LSTM:为了学习英雄的技能释放组合,以便AI在序列决策中,快速输出大量伤害。
3.动作依赖关系的解耦:用于构建多标签近端策略优化(PPO)目标。
4.动作掩码:这是一种基于游戏知识的剪枝方法,为了引导强化学习过程中的探索而开发。
5.dual-clip PPO:这是 PPO 算法的一种改进版本,使用它是为了确保使用大和有偏差的数据批进行训练时的收敛性。如图3所示。

图 3:论文提出的dual-clip PPO算法示意图,左为标准PPO,右为dual-clip PPO
有关这些算法的更多详情与数学描述请参阅原论文。
系统设置
测试平台为热门 MOBA 游戏《王者荣耀》的 1v1 游戏模式。为了评估 AI 在现实世界中的表现,这个 AI 模型与《王者荣耀》职业选手和顶级业余人类玩家打了大量比赛。实验中 AI 模型的动作预测时间间隔为 133 ms,这大约是业余高手玩家的反应时间。另外,论文方法还与已有研究中的基准方法进行了比较,其中包括游戏内置的决策树方法以及其它研究中的 MTCS 及其变体方法。实验还使用Elo分数对不同版本的模型进行了比较。
实验结果
探索动作决策能力的上限
表 3 给出了AI和多名顶级职业选手的比赛结果。需要指出这些职业玩家玩的都是他们擅长的英雄。可以看到 AI 能在多种不同类型的英雄上击败职业选手。
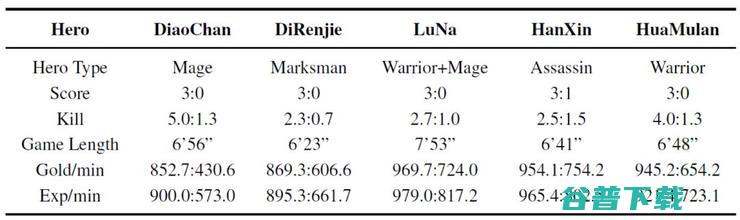
表 3:AI 与职业选手使用不同类型英雄比赛的结果
评估动作决策能力的稳健性
实验进一步评估了 AI 学习的策略能否应对不同的顶级人类玩家。在2019年8月份,王者荣耀1v1 AI对公众亮相,与大量顶级业余玩家进行了2100场对战。AI胜率达到99.81%。
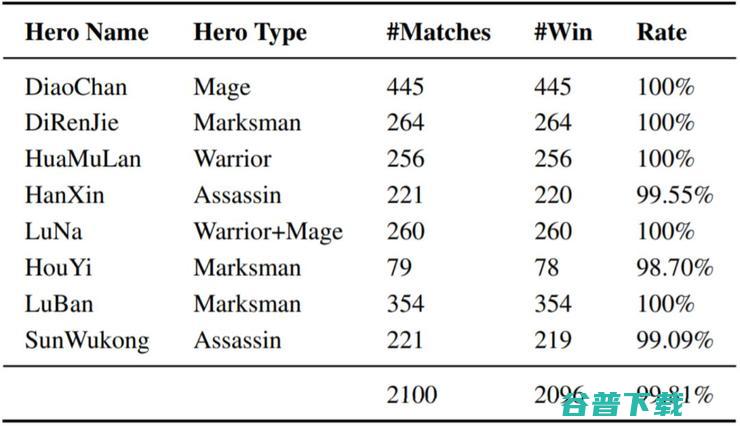
表 4:AI 与不同顶级人类玩家的比赛结果
基准比较
可以看到,用论文新方法训练的 AI 的表现显著优于多种baseline方法。
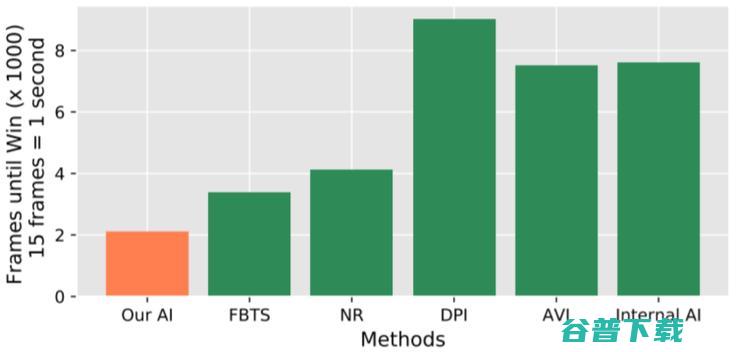
图 4:击败同一基准对手的平均时长比较
训练过程中模型能力的进展
图 5 展示了训练过程中 Elo 分数的变化情况,这里给出的是使用射手英雄「狄仁杰」的例子。可以观察到 Elo 分数会随训练时长而增长,并在大约 80小时后达到相对稳定的水平。此外,Elo 的增长率与训练时间成反比。

图 5:训练过程中 Elo 分数的变化情况
控制变量研究
为了理解论文方法中不同组件和设置的效果,控制变量实验是必不可少的。表 5 展示了使用同样训练资源的不同「狄仁杰」AI 版本的实验结果。
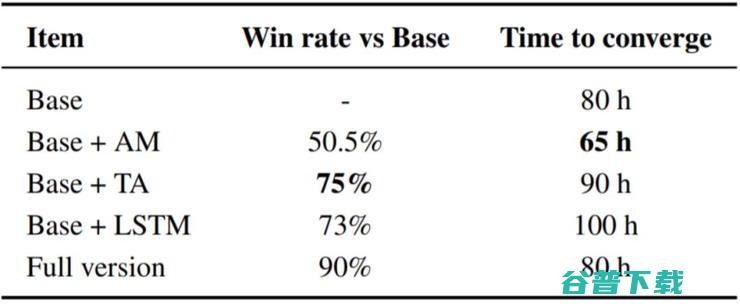
表 5:控制变量实验
4、未来工作
本文提出的框架和算法将在未来开源,而且为了促进对复杂游戏的进一步研究,腾讯也将在未来把《王者荣耀》的游戏内核提供给社区使用,并且还会通过虚拟云的形式向社区提供计算资源。
雷锋网 AI 科技评论报道。
原创文章,未经授权禁止转载。详情见 转载须知 。


")
为您提供详细的企业介绍、联系人资料、联系方式等企业信息。桂林人上网,从桂林黄页开始,专业的商务搜索,让您更精准找到企业资料!
")
CentralChinaNormalUniversity

漳州市医疗保障局,漳州市医疗保障局

湘潭市雨湖区庞氏中医诊所专业治疗各类鼻炎、过敏性鼻炎、鼻窦炎、急慢性咽喉炎、声带小结、食道炎、小孩腺样体肥大、扁桃体肿大、甲亢病、甲减病和甲状腺结节等疾病。长沙湘潭均有门诊,患者遍布全国各地,电话:13647323067。

深圳华普盾科技有限公司是由深圳深消科技有限公司全资控股的创新型科技企业。公司所生产销售产品均符合国家标准。承接一个项目,树立一个丰碑,发展一个客户,架起一座桥架,努力成为一个卓越的消防行业风向标

工程机械租售运输平台小程序

利宝保险有限公司创立于1912年的世界500强企业,主营财产保险,家庭保险,汽车保险,车险,意外险,商业保险.中国总部位于重庆,在北京,浙江,广东,山东,四川,云南,河南,河北,陕西,天津都有分公司。是全球公认的职业健康与安全服务研究的领导者!利宝保险咨询电话:400-888-2008

生活电器指的是能够提高人们生活质量的各种家用电器。

上海球鑫不锈钢有限公司

麻城人才网,汇聚黄冈地区各类招聘信息,涵盖教师|司机|临时工|小时工等多个岗位。同城人才市场动态更新,工厂|事业单位|兼职等职位一网打尽。找工作|求职,就来麻城人才网,轻松获取最新招聘信息,助您顺利找到理想工作!

为适应互联网+的发展及乡村振兴,特推出糖酒食材信息合作平台,为糖酒食材行业添砖加瓦,共谋发展!致力于打造中国糖酒食材及农副产品的信息合作平台,为广大糖酒食材厂家、经销商、市场商户等行业参与者提供完整的信息合作交流平台!

TPR教学法第一类简单的说就是动作教学,用动作示范教学。tpr教学法第二类就像洗脸刷牙等家庭动作。tpr教学法的升级就是序列法


话说一位科员因为长期得不到提拔,怨恨太深,索性破罐子破摔,天天迟到早退,有时有事就是找不到他人,科长找他谈了两次,都是不欢而散,毫无效果,屡教不改,只得向局长汇报,局长说,让他过来,我来找他谈,局长,知道我为什么找你吗?科员,科长做不了的事局长继续做呗,局长,你好像还有理了?科员,别人和我讲理我就讲理,别人不和我讲理,我也没办法讲理,...。

编者按,数据安全日益成为我们个人生活的核心,加密数据无疑是很有必要的,QuincyLarson将告诉你如何在一小时时间内加密你的整个人生,希望这份隐私安全保护教程能够让你从此免去数据泄密的担忧,本文编译自Medium上原文名为,Howtoencryptyourentirelifeinlessthananhour,的文章,AndyGro...。

2020年,在人工智能,新十年,和,新基建,新时代叠加前来之际,所有AI公司皆投入到了新基建三大版块之中,相继成为新基建主力军中的一员,包括,信息基础设施,5G、物联网、工业互联网、卫星联网、人工智能、云计算、区块链、数据中心、智能计算中心,;融合基础设施,智能交通、智慧能源、医疗生物物流防疫基建,;创新基础设施,产业技术创新基设、科...。
alcor,安国,au6983,09.02.27,u盘量产教程欢迎来到本篇教程,这里将详细指导您如何使用alcor,安国,au6983,09.02.27,芯片进行u盘的量产,无论是对于初学者还是有一定经验的技术爱好者,本教程都将为您提供详细的步骤和必要的提示,帮助您顺利完成u盘的量产工作,准备工具与材料在开始之前,请确保您已经准备好了...。

近日,博主,陈朵朵,颁布视频,记载了国庆假期在云南哀牢山搭帐篷露营2天1夜的经验,引发关注,据央视资讯信息,针对有网络博主颁布视频称其夜宿哀牢山2天1夜的经验,云南哀牢山国度级人造包全区镇沅管护局回复示意,已派收上班人员赴现场展开排查上班,确认该事情能否出当初辖区内,并将启动后续解决,如有其别人员私自进入哀牢山包全区外围区域,将启动...。

属兔的和羊,狗,猪属相最配,属兔兽性情平和,痴呆愚钝,有着较灵便的警觉性,生存中也是个十分浪漫的人,举止斯文,并且属兔人一旦认定一段感情以后就会全身心的投入付出,只管偶然不足沉着,不知道如何管理自己的情感,比拟感情用事,但少数时刻属兔人还是十分暖和体恤的,他们心理周密,擅长沟通和交际,所以人缘也特意好,属兔的和什么属相最配属兔和属羊属...。

公众途观l色彩有几种公众途观色彩有几种公众途观色彩有五种,区分是极光白、玄武黑、峻岭棕、天漠金、岩壁棕,以2017款公众途观为例,其是一款紧凑型suv,车身尺寸是,长4506mm、宽1809mm、高1685mm,轴距为2684mm,车身重量为1600kg,2017款公众途观搭载1.8t直系4缸涡轮增压发起机,最大马力是160ps,最大...。

1、三菱帕杰罗V97旗舰版的全车尺寸为4830*1885*1855mm,轴距为2780mm,,布雷式前脸,照旧硬朗而耐看,在宏大的车身上配合相当流利谐和,具备强悍粗犷但精细的外观外型设计,多横梁梯形车架结构,迷信的车身结构设计确保在越野路面时的车身强度和牢靠性,模块设计的前大灯撑持板和侧围结构,车门侧防撞杆确保乘员的安保空间,2、三菱...。

因该说中文吉普车,JEEP又是一个品牌,100万的吉普挺多的,但没有100万的JEEP2010款雷克萨斯RX450h凑近100万,卖95万,雷克萨斯LX570,159万新BMWX5xDrive4.8i上游型157万,奢侈型173万,BMWX6xDrive35i97万,xDrive50i,177万,飞驰G55,189万~225万,飞驰M...。

易车讯9月15日,吉利熊猫骑士正式上市,售5.39万元,新车定位为微型电动车,配有快慢充电口,可经常使用商用快充、家庭充电桩、随车充电枪,新车纯电续航里程为200km,9月30日前购置熊猫骑士的用户,均可享用骑士补贴礼,交1000元抵5000元新动力限时补贴;骑士质保礼,首任非营运车主享用三电永恒质保;骑士补能礼,赠送交换便携式充电枪...。

重庆分类目录网站将2023年09月共11个网站收录信息按收录时间分类整理归档列表,可以方便网友浏览按年月查询,更好地享受精彩网站的魅力!

上海500万的房首付降175万
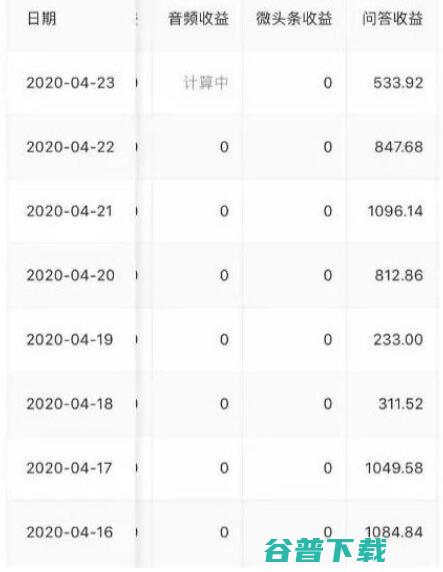
2020年比较特殊,因为疫情的影响,实体行业遭受巨大危机,但有危就有机,线上业务得到巨大的发展机会,想当年非典期间,阿里和京东就是趁势而起,不然当年很多人不会意识到原来网上买东西这么方便,今日头条也是如此,本来春节期间是流量最集中的时候,由于疫情延长了放假时间,头条的日活和装机量更是大增,此时,官方不失时机的推出了多项针对创作者收入的...。

4月16日,百度创始人、董事长兼首席执行官李彦宏在Create2024百度AI开发者大会上宣布,第二届,文心杯,创业大赛正式启动,参赛选手有机会获得最高5000万人民币投资,李彦宏在Create2024百度AI开发者大会的演讲主题是,人人都是开发者,,他指出,,AI正在掀起一场创造力革命,未来开发应用就像拍个短视频一样简单,人人都是开...。

发表在专业问答2024,11,2615,56展示机型信息,品牌型号,当贝F7Pro系统版本,当贝OS5.0投影仪画面太靠下了可以通过投影仪的画面位移功能进行调整,总共可以分为三步,下面为投影仪画面太靠下了怎么调的详细步骤做具体说明,投影仪画面太靠下了怎么调1.打开投影设置在投影仪主界面找到设置并点击打开;2.打开画面位移在画面设置中找...。

比如曾爷爷是AB国混血,曾奶奶是CD国混血,生下的就是ABCD四国混血的孩子,这个孩子再和一个EF国混血结婚生小孩,就有有了一个六国混血,再和一个gh国混血结婚就是八国混血五国混血儿什么意思五国混血儿通常指的是一个人的父母、祖父母或外祖父母来自五个不同的国家,因此这个人的血统融合了五个国家的遗传特征,混血儿这个词通常用来描述有不同种族...。

刚领到的家电以旧换新资历券,张望两天就发现购物车的产品都涨价了……,双十一,前后,不少消费者在澎湃群众互助平台,服务湃,https,tousu.thepaper.cn,、黑猫揭发、消费保及社交媒体曝料称,补贴政策出台后,此前关注的商品突然涨价,补贴后的多少钱与补贴前差异不大,有的甚至更贵,不法商家正借机,薅补贴的羊毛,更为顽劣...。
