擦出怎样的火花 德扑AI之父请来了最棒的博弈论学者们 2018 AI 他们能与 AAAI (擦出怎样的火花?)
美国当地时间 2 月 3 日,AAAI 2018 在第一天的预热之后逐渐热闹了起来。雷锋网 AI 科技评论在前瞻报道中提到过,本次大会将会有 15 个 Workshop 陆续进行,其中《非对称信息博弈的 AI( AI for Imperfect-Information Games)》就是其中一个。这一 workshop 的组织者包括 CMU 的Noam Brown, DeepMind 的 Marc Lanctot 还有 南加州大学博士生、曾获谷歌 PhD 奖研金的徐海峰 。
就像 AlphaGo 让大家更加熟知深度学习,大家对非对称信息博弈开始了解并熟悉,很大程度也是因为 2017 年初,CMU计算机系在读博士生 Noam Brown 和计算机系教授 Tuomas Sandholm 联合研发的 Libratus 在单挑无限注德州扑克(Heads-up no-limit hold’em)人机对战中完胜人类选手。在去年的 NIPS 2017 上,最佳论文正是由他俩的合作论文《Safe and Nested Subgame Solving for Imperfect-Information Games》所摘得。 雷锋字幕组也曾对这一论文解读视频进行独家编译。
正像 Noam Brown 和 Tuomas Sandholm 在 Reddit 上所表达的那样:深度学习远非人工智能的全部 ,非对称信息博弈也与 AI 联系得越发紧密。「非对称信息博弈」常被用来模拟涉及隐藏信息的各种战略交互(例如谈判,拍卖等)和安全交互中。由于隐藏信息的存在,解决这些事件需要的方法与传统的对称信息(比如国际象棋或棋类游戏)完全不同。尽管在一些研究「非对称信息模拟」的领域取得了相当大的进展,但是每个领域所使用的技术尽管具有普遍性,却仍然相对孤立。它们之间存在充分的跨学科交流的机会,让研究人员们会通过已经在一个领域中流行的方法的新应用、或使用建立在不同领域中已有方法来创建新的技术。
本场 Workshop 的主要话题几乎包含了「非对称信息博弈的 AI」相关的大部分内容,包括新近用于 AAAI 年度计算机扑克比赛(ACPC),用于解决大型不完美信息游戏的可伸缩算法,游戏中的对手建模和开发,一般和多于两个的算法建模和分析信息非对称在游戏中的作用,战略信号(又名说服),在不完整信息的战略环境中进行探索与开发,以及一些与非对称信息博弈有关的其他主题的研究。
研究者们将分享他们在研究 AI 在非对称信息博弈中的理论和实践方面当前的研究成果,也提出有关如何改善相关领域算法的构想,推动该领域的 AI 研究。
这场 Workshop 持续了一整天,原计划是早上 9:30 开场,下午 5:00 结束,有 8 个演讲者对他们的研究成果进行分享,每人限时半小时,以下是原定议程:

但由于第一位演讲者未到现场,所以第一个主题《Dynamic Adaptation and Opponent Exploitation in Computer Poker》取消,活动推迟到 10 点,并将第二个主题作为开场,并且其中一些主题也做了相应的调整。
开场的论文是由 CMU 的 Christian Kroer 带来的,题目为《广泛形式博弈中 Stackelberg 均衡的鲁棒性及有限前瞻的扩展(Robust Stackelberg Equilibria in Extensive-Form Games and Extension to Limited Lookahead)》 ,而作者也包括了 Gabriele Farina 和 Tuomas Sandholm。后者与本次议程的主持人Noam Brown 所研发的 Libratus 在 2017 年初打败了人类选手,他也被誉为德州AI之父。
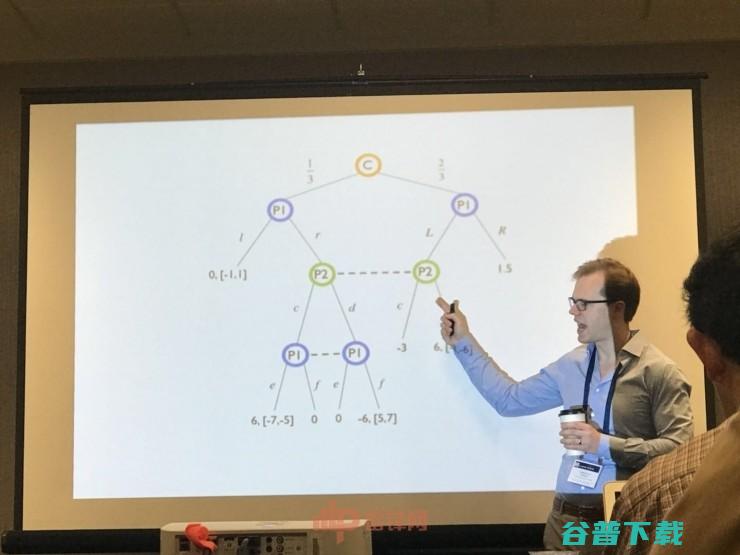
作为计算博弈论中的一个解决方案概念,Stackelberg 均衡已经变得越来越重要,这在很大程度上受到诸如安全设置等实际问题的启发。然而在实践中,关于对手的模型通常具有不确定型。据作者介绍,这篇论文是首个在广泛形式博弈中进行不确定条件下的 Stackelberg 均衡的研究。
Christian Kroer 的团队引入了鲁棒性较高的 Stackelberg 均衡,其中不确定性是关于对手的收益,以及对手有有限前瞻性和关于对手的节点评价函数的不确定。他们为确定性限制前瞻设置开发了一个新的混合整数程序。然后,系统把这个程序扩展到无限制下的 Stackelberg 均衡的鲁棒设置,并且仍然位于对手有限的前瞻范围内。
该论文证明了对于对手的收益区间不确定性的具体情况(或者在有限的前瞻的情况下关于对手的节点评估),可以用一个混合整数程序来计算 Stackelberg 平衡的鲁棒性,该程序的渐近大小与确定性设置相同。
第二篇论文是由哈佛大学的刘洋带来的《建立高质量信息的强化学习框架(A Reinforcement Learning Framework for Eliciting High Quality Information)》。
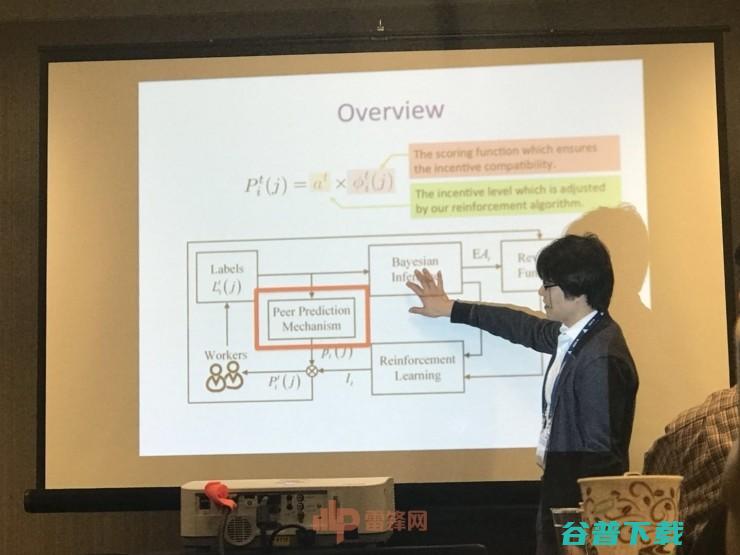
对等预测是一类机制,当没有验证贡献的基础事实时,它有助于从 strategic human agents 中获得高质量的信息。尽管它的设计看似完善,但是在实践中经常失败,主要是由于两个缺点:(1) agents 对提供高质量信息的努力的动机被认为是已知的; (2) agents 被建模为完全理性的。
在这篇论文中,作者们提出了第一个强化学习(RL)框架,在这个领域,加强对等预测,来解决这两个限制。在论文中提到的框架中,研究人员为数据请求者开发了一个RL算法,用于数据请求者动态调整缩放级别以最大化其收入,并使用对等预测评分函数调配工作人员。实验显示,在不同的模式下,数据请求者的收入显着提高。
第三篇论文是由密歇根大学的 Mason Wright 带来的《在连续双标拍卖中评估非自适应交易的稳定性:一种强化学习方法( Evaluating the Stability of Non-Adaptive Trading in Continuous Double Auctions: A Reinforcement Learning ApProach)》。

该论文是在本次 AAAI 2018 大会上首次公开, 此前 Mason 和他的团队曾在 2017 年发表过关于非对称性信息博弈在连续双标拍卖中的研究成果,在本次的论文中,主要针对新的强化学习方法进行阐述,由于本篇论文还未正式放出,雷锋网 AI 科技评论将在后续的报道中对该篇论文的演讲 PPT 进行详细报道。
第四篇是由 Facebook AI Research 的研究工程师 Adam Lerer 主讲的《在社会困境中结果主义的条件合作的非对称博弈(Consequentialist Conditional Cooperation in Social Dilemmas with Imperfect Information)》

在社会困境中,合作可以带来高回报,但参与者面临欺骗的动机,且这一情况在多主体的互动中无处不在。我们希望与纯粹的合作伙伴进行合作,并避免背叛者的剥削;此外,我们还需要鼓励其他的合作。然而,通常合作伙伴采取的行动(部分)未能被观察到,或者个人行为的后果很难预测。这篇论文中证明,在一个大型的活动中,好的策略可以通过调整一个人的行为来建立一个奖励机制,这被称之为结果主义的条件合作。在论文中,Adam Lerer 展示了如何使用深度强化学习技术来构建这样的策略,并通过分析和实验证明,它们在简单的矩阵游戏之外的社会困境中是有效的,此外,论文还说明了单纯依赖后果的局限性,并讨论了对行动的后果意图的理解的必要性。
第五个演讲内容是圣路易斯华盛顿大学 Samuel Ang等人的课题《应用于安全领域的博弈论目标识别模型Game-theoretic Goal-Recognition Models with Applications to Security Domains》。

在人工智能规划领域的目标识别 (GR) 和目标识别设计 (GRD) 问题的驱动下,论文分别介绍和研究了战略代理的 GR 和 GRD 问题的两种自然变体。更具体地说,就是考虑了游戏理论 (GT) 的场景,其中一个恶意对手的目标是在一个 (物理或虚拟) 环境中对一个防御者监视的目标进行破坏。敌人必须采取一系列行动以攻击预定目标。在 GTGR 和 GTGRD 设置中,防御者试图识别对手的预定目标,同时观察对手的可用动作,这样他/她就可以加强目标防御攻击。此外,在 GTGRD 设置中,防御者可以改变环境 (例如,增加路障),以便更好地区分对手的目标/目标。
在论文中,研究人员建议将 GTGR 和 GTGRD 设置为零和随机游戏,其信息不对称与对手的预定目标有关。游戏是在图形上播放的,顶点代表状态,边缘是对手的动作。对于 GTGR 设置,如果防御者只局限于只玩固定的策略,那么计算最优策略的问题 (对于防御者和对手) 都可以被制定并以一个线性程序来表示。对于 GTGRD 设置,在游戏开始时,防御者可以选择 K 条边来阻止,研究人员将计算最优策略的问题作为混合整数规划,并提出一种基于 LP 二元性和贪婪算法的启发式算法。实验表明,这一研究的启发式算法具有良好的性能。与混合整数规划方法相比,它具有更好的可扩展性。
目前研究中,现有的工作,尤其是 GRD 问题,几乎完全集中在决策理论范式上,即对手在没有考虑到他们可能被观察的情况下选择自己的行为。由于这种假设在 GT 场景中是不现实的,所以该篇论文提出的模型和算法填补了文献中的一个空白。
第六篇论文是来自南加州大学的 Sara McCarthy 带来的《在游戏中保持领先:用于威胁筛选的资源动态分配的自适应鲁棒性优化(Staying Ahead of the Game: Adaptive Robust Optimization for Dynamic Allocation of Threat Screening Resources)》

Sara McCarthy 的研究考虑在安检地点(例如,在机场或港口)动态分配不同效率的筛选资源(例如X光机等),以成功地避免一名被筛查者的攻击。在此之前,研究人员引入了威胁筛选博弈模型来解决这个问题,虽然理论上能假设屏幕到达时间是完全已知的,但实际上,到达时间是不确定的,这严重阻碍了该方法的实现和性能。
因此,研究者们提出了一种新的威胁筛选资源动态分配框架,明确说明了筛选到达时间的不确定性。研究者将问题建模为一个多阶段鲁棒优化问题,并提出了一个使用紧凑线性决策规则和鲁棒重构和约束随机化相结合的解决方案。在进行了大量的数值实验后,这些实验表明,这种方法在处理性方面胜过(a)精确的解决方法,同时在最优性方面只产生很小的损失,(b)方法忽略了可行性和最优性方面的不确定性。
最后一篇论文来自卡内基梅隆大学的于澜涛,主题为《基于网络信息绿色安全游戏的深度强化学习(Deep Reinforcement Learning for Green Security Game with Online Information)》。

出于保护濒危野生动物免受偷猎和防止非法采伐等绿色安全领域的迫切需要,研究人员提出了博弈论模型,以优化执法机构的巡逻。尽管有了这些努力,在线信息和在线互动(例如,巡逻者追踪偷猎者的足迹)在之前的游戏模型和解决方案中被忽略了。这篇论文的研究旨在通过将安全游戏与深度强化学习相结合,为复杂的现实世界绿色安全问题提供更切实可行的解决方案。具体来说,研究者提出了一种新颖的游戏模型,它融合了在线信息的重要元素,并对可能的解决方案进行了讨论,并提出了基于深度强化学习的未来研究方向。
以上就是 AAAI 第二天「人工智能非对称信息博弈」专场 workshop 的全部内容摘要,接下来,雷锋网 AI 科技评论会对全部 7 篇论文的 PPT 和演讲内容进行精编整理,逐步放出。
接下来 AAAI 的议程会更加精彩,明天雷锋网将继续在现场为大家报道精彩盛况。
原创文章,未经授权禁止转载。详情见 转载须知 。



人民网于1998年开始推出网上音视频节目,后专设多媒体频道,2007年更名为人民宽频频道,2008年推出人民播客,2010年3月人民电视开播。目前已经形成以新闻类视频节目为主,同时囊括文化、娱乐、体育、生活、社会等各类综合内容的业务格局。本页面汇总每日最新视频新闻。

上海圆直建筑设计有限公司,设计领域包括城市设计、景区规划、旅游建筑、观演建筑、酒店建筑、办公建筑、历史文化建筑保护等各方面。

东莞市锐风机械有限公司座落于制造业名城——广东东莞,专业生产“锐达”牌冷室压铸机、热室压铸机及其周边设备,广泛应用于汽车、摩托车、电子、通讯、礼品、玩具等领域。在湖北设有分公司:湖北锐动机械有限公司

瑞莱智慧RealAI是人工智能基础设施和解决方案提供商,致力于以安全、可信、可靠、可扩展的第三代人工智能技术,为高价值场景智能化升级提供一站式赋能方案。 RealAI依托清华大学人工智能研究院发起设立,团队坚持源头创新和底层研究,在国际测评和竞赛中多次斩获冠军、发表顶会期刊论文百余篇,累计获得各项知识产权250余项,其中授权发明专利近60项,并参与20余项国际、国家及行业标准制定。 ⽬前,RealAI已在政务、⾦融、能源、制造、互联⽹等领域落地,为合作伙伴提供了⼈脸识别系统安全、自动驾驶系统安全、深度合成和伪造检测、隐私保护计算、AI攻防靶场等全套产品和解决⽅案。

立志做全球最大的IPA分享网站,提供在线iOS应用下载服务,为您搜集最全、最专业的iPhone,iPad,iPod软件与IPA文件,支持iOS4,iOS5,iOS6软件,iOS7软件,iOS8,iOS9软件在线安装以及IPA文件下载。

内蒙古慧韬科技有限公司成立于2021年,现有员工9人,其中专业技术人员3人。公司于2018年入围内蒙古自治区政府采购协议供货单位。内蒙古慧韬科技有限公司自成立以来,凭借公司多年经营理念及良好完善的售后服务,建立了稳定的用户群体,用户遍及行政事业单位、政府、教育部门以及电力企业。与内蒙古广播电视台、内蒙古大学、内蒙古党校、内蒙古政府机关事物管理局、内蒙古电影集团等单位合作十余年,得到各单位的广大信任和赞誉。内蒙古炬盛兴通网络技术有限公司,拥有雄厚的流动资金,完善的财务管理,先进的专业技术队伍,优质的服务体系,已成为我区最具专业技术、销售、服务综合一体的公司。

PaperCcb查查呗官网-免费论文查重检测-首款免费论文检测软件,提供免费论文重复率检测,论文降重,论文格式规范,学术不端检测知网查重等一站式服务

中华网成立于1999年5月,作为一个综合性的网络媒体,中华网聚焦新闻、军事、国防军事、财经、汽车、文化等领域,近20个频道每天向世界滚动播报最新的信息和服务。중화망

浙江谷地机械科技有限公司拥有十五年以上工作经验的真空乳化机设计研发团队,公司服务于制药、化妆品、生物、食品等行业,产品从设计、采购、生产、总装和调试整个流程完全受控,致力于为客户提供高品质的产品,欢迎来电洽谈。

教育科技有限责任公司")
精英知了教育集团是国内最早、规模最大的专注中学生英美学术课程及出国英语培训的机构,业务覆盖全国多个城市,服务全国及在英美澳等国读中学的中国学生。咨询电话:13316964975

周口市物业服务行业协会


对于想要创业的人群而言,如何选择创业项目是一件难事,下面小编就为大家介绍一个不错的品牌,那就是贝克汉堡西餐小吃,该品牌兢兢业业的发展态度,赢得了社会各界人士的认可,有意向加盟的话,可以先来看看,贝克汉堡西餐小吃加盟店房租高吗,贝克汉堡西餐小吃加盟店房租高吗公司制定了标准化的加盟管理制度,其中就对于各项费用的收取进行了明确的规定,首先需...。

真我Neo7将在12月11日发布,按照,老规矩,,真我在12月10日放出电商的价格预热烟雾弹,标注的是2498元,比K80,骁龙8Gen3,的2499元低了整整一元,查一下老黄历,真我GT5Pro的实际售价和烟雾弹差200元,真我GT6差价400元,真我GT7Pro差价400元,按照差价200到400推算,真我Neo7的起步价应该是2...。

华为否认20万月薪工资条,内容漏洞百出日前,一张写着华为技术有限公司,数据中心能源集团军,2021年11月工资单的数张工资条在网上曝光,引发网络热议,图片显示,职称为,高工,的员工月工资,累加绩效后实发工资超过10万元,部分人员的月薪甚至超过20万元,月薪组成包括基本工资、科研补贴、交通补贴、餐饮补贴、绩效工资、五险一金扣款、个税等,...。

文字链接认证代码普通联盟标志认证代码企业广告联盟标志认证代码广告联盟评测代码说明,本页面的认证代码为奇窝广告联盟专用评测代码,站长需懂简单html知识,直接复制代码粘贴到联盟网站相应页面即可使用,本代码不适用于其他广告联盟网站请勿获取!文字认证,文字链接代码认证适用所有类型的广告联盟,复制代码后放在奇窝广告联盟网站首页底部或友情链接位...。

这个时代的滑稽和伟大之处皆在于,我们每天要证明自己是自己,在淘宝上购买一件衣服,你需要扫一扫,人脸识别,,证明一下你是你;去公司上下班,你需要点一点,指纹识别,,证明一下你是你;如果你在银行、政府单位的,重要场景,中工作,你还得接受一下,虹膜识别,,证明一下你的确是你,而上述这些技术,统称为生物识别,声纹识别便是其中之一,声纹识别也被...。

发表在坚果投影仪2024,5,2917,22微果C1S是微果C1的升级版本,主要提升了设备的画质和性能,那么微果C1S投影仪怎么样呢,下面就来全方位了解一下,看看微果C1S投影仪的参数配置究竟如何,各方面的优缺点有哪些,微果C1S投影仪怎么样,1.画质上亮度上,微果C1S的实际亮度达到400CVIA流明,实际不足以抵抗灯光干扰,需要在...。

咪咕MGV2000拆机TTL破解安装第三方软件教程分享一、尝试ADB首先用ADB端口扫描器扫描了端口,虽然扫出来大概10多个端口,但是一个都用不上;二、尝试双头USB连接电脑毫无反应,放弃;三、老方法拆机TTL,但是有瑕疵,不完美,值得注意的是,TTL型号不能用CH340g,会乱码,,得用才能正常跑码;破解工具下载,https,p...。

索兰托柴油,SolanoDiesel,是一种粗劣的柴油,由索兰托石油,SolanoOil,公司消费,索兰托柴油通过多年的研发,具备清洁功能优秀,抗磨功能杰出,易进行,节油功能优越,牢靠性初等长处,它是经常使用最宽泛的柴油,深受车主们的青眼,索兰托柴油清洁性优秀索兰托柴油驳回索兰托石油的共同技术,通过屡次的洗濯,使得柴油具备清洁功能优秀...。

Devkits是一款轻量级桌面端应用,提供了一系列开发者工具,提高开发效率。远离充斥可疑信息和广告的网站,提供含海量工具,满足开发人员日常需求。

广州网易房产为您提供开控|城投·云锦楼盘售楼处电话:4001-666-163转23119、最新房价参考:46000元/㎡、户型图、实景图和周边配套等最新楼盘详情信息,买新房尽在广州网易房产!

sjqy字体,钢筋符号SJQY字体,含有四种钢筋符号!Word和Excel里用的,复制到C:\WINDOWS\Fonts文件夹里,在使用WORD时插入符号,在SJQY里即可找到,您可以免费下载。

P2P终结者,该版本为去广告、最高权限,P2P终结者是由Net.Soft工作室开发的一套专门用来控制企业网络P2P下载流量的网络管理软件,针对目前P2P软件过多占用带宽的问题,提供了一个非常简单的解决方案,您可以免费下载。

今年春节,以,95后,和,00后,为代表的Z世代,流行找源头工厂定制平替年货,作为源头厂货直销平台,1688的数据显示,今年1月份,,平替,一词的日均搜索人数同比增长1821%,搜索次数同比增长1587%,源头平替成了年轻人的消费新主张,大量年轻人涌入1688,春节回乡之前上1688严选购买穿戴甲和假发,甚至找工厂定制,今年1月份,穿...。

独家获悉,近日华为EMT发布华为云内部调整意见,华为云不再以独立公司机制运作,将重新回到集团按业务部门管理,集团层也将针对云业务增设管委会,2017年,华为成立专门负责公有云的CloudBU,随后经过多次业务整合,在2020年形成云与计算BG,2021年,徐直军和余承东分别担任华为云董事长和CEO,华为云之独立性进一步加强,华为...。

发表在专业问答2020,9,2311,35展示机型信息,软件版本,当贝桌面3.3.4当贝桌面应用内进行升级,推送新版当贝桌面后,运行当贝桌面时会有升级提示;,当贝市场内进行升级,在当贝市场的应用管理中升级;,U盘升级,下载最新版的当贝桌面到U盘,再将U盘接入投影或电视进行升级,当贝桌面怎么升级1.当贝桌面应用内进行升级,推送新版当...。

发表在索尼投影仪2020,11,2314,12索尼投影机在投影行业一直排在金字塔顶端,是高端投影仪的代名词,近期,索尼发布了一款家庭影院投影机——索尼VPL,VW798,这是一款画面效果堪比影院投影机的设备,下面分享索尼VW798投影机的详细情况,了解这是一款怎么样的投影机,索尼VW798投影机怎么样1.超清画面索尼VW798投影机搭...。
文字链接认证代码普通联盟标志认证代码企业广告联盟标志认证代码广告联盟评测代码说明,本页面的认证代码为啊啊广告联盟专用评测代码,站长需懂简单html知识,直接复制代码粘贴到联盟网站相应页面即可使用,本代码不适用于其他广告联盟网站请勿获取!文字认证,文字链接代码认证适用所有类型的广告联盟,复制代码后放在啊啊广告联盟网站首页底部或友情链接位...。
