VDC人工智能会场 2024 vivo全新蓝心大模型矩阵亮相 (人工智能 cv)
消息,2024 vivo开发者大会于10月10日在广东深圳正式召开,vivo发布自研大模型——全新蓝心大模型矩阵,并带来了多项核心能力升级。
首先是语言大模型升级,vivo自研语音大模型基于蓝心文本大模型开发,通过离散化编码结合文本大模型学习,实现更智能、丰富和简单的语音交互。它具备四大核心能力:语音合成、音色复刻、语音翻译和方言自由说。语音合成能将文本转化为逼真拟人的语音,支持多语言及方言;音色复刻则只需用户一句话即可复制音色;方言自由说功能不仅满足用户方言交流需求,还助力方言文化的保护与传承;语音翻译能力则能直接将语音转化为目标语言文本,提高翻译效率。
vivo将继续深耕语音大模型在各场景的应用,提升用户体验,并期待与各界共同探索大模型技术的更多可能性,造福社会。未来,vivo计划将语音大模型能力逐步开放至智能体平台,以更广泛地服务于用户和开发者。

BlueLM-70B 2.0新增学习了1亿知识问答,500w篇的论文,以及1.2亿代码仓库等高质量数据,模型整体能力提升30%。新增了多模态多轮对话能力,支持400+手机系统工具和180+三方工具的调用,以及全面升级了大模型的代码生成能力,能实现数理计算和Excel的数据分析能力。BlueLM-70B 2.0模型较1.0模型能力提升30%。
图像大模型方面,随着扩散模型与AI架构的深度融合,图像生成技术迎来了指数级飞跃,其中文生图技术尤为显著。vivo AIGC图像大模型技术总监阮晓虎在论坛上介绍了vivo的文生图大模型——蓝心图像大模型BlueLM-Art,该模型精通中文语境,融合了中国特色与东方美学,其在中文理解、中国文化诠释、人物摄影美学及中文文字绘制等多个维度都取得了出色的效果,多次荣登SuperCLUE-Image基准榜单中文领域榜首。

通过在算法架构、数据处理、工程以及算力上的全面优化,使蓝心图像大模型BlueLM-Art拥有诸多特性,不仅精通中文,拥有出色的指令跟随性,还能生成与图文完美结合的中文字符,并提供艺术字绘制插件。同时,蓝心图像大模型BlueLM-Art在人物摄影美学方面有着卓越表现,能呈现美观、真实、富有质感的人物形象。最后,BlueLM-Art还拥有可控性生成能力,能在图像创作中保持更高的主体一致性。
基于蓝心图像大模型BlueLM-Art,vivo在蓝心小V中推出了图像创作、AI消除、图像风格化、艺术字创作等一系列AI功能,并在PAD的原子笔记中加入了AI涂鸦美化功能,极大地提升了用户的创作体验。后续vivo将继续优化文生图大模型及其相关AIGC功能,为用户提供更多创意资源,让先进的AI技术惠及更广泛的用户群体,持续推动图像生成技术的创新与发展。

大模型时代,vivo持续推进各模态大模型端侧化能力建设,探索大模型在各业务场景端侧产品落地,覆盖“听、说、读、写、画”各应用场景。在“听”方面,vivo升级应用语音识别大模型,让语音操作随时可用;在“说”方面,利用语音生成大模型生成超拟人音色,为故事讲述赋予更鲜活的魅力;在“读”方面,利用多模态大模型针对视障用户打造图像问答功能;在“写”方面,将语言大模型在端侧更广泛的应用,同时升级为3B端侧大模型,给用户更为优质的体验。此外,vivo还探索了图像大模型端侧化,为用户带来随时可用的AI消除功能。
针对全模态大模型端侧化,vivo从算法模型设计,到量化、性能瓶颈分析工具建设,再到底层运行时异构方案设计和业务框架层灵活的多业务部署架构建设,提供了完整的解决方案。通过软硬件协同,充分挖掘芯片潜力,确保大模型在端侧运行时的强悍性能。未来,vivo计划开放成熟算法能力与端侧加速能力,与行业开发者合作,共同打造创新、便利、智能的业务场景,为用户提供更优质的智能化体验。
原创文章,未经授权禁止转载。详情见 转载须知 。


中国超雪官方网站

正穗香港公司注册网是广州专业服务于广州注册香港公司、香港公司注销,一站式解决香港公司注销流程及费用、香港公司注册价格、香港商标申请等问题,专业至诚,无微不至,值得信赖,请相信您的选择。

专门从事玻璃装饰8年的公司,一直专注于玻璃装饰行业的服务与发展,与各大城市的建筑性公司建立了良好合作关系,主要服务范围有:酒店、KTV、酒吧、会所、办公楼等

河南省逄德电气有限公司

四川宝利升钢铁有限公司厂家【现货电话:15756628678】提供各种规格20mm-530mm之间的四川无缝管,成都无缝钢管,四川Q345【B,D,E】无缝管,成都高压合金钢管生产厂家的价格、材质及规格表,低价定制批发任何规格口径的四川无缝管、成都厚壁钢管、合金钢管、高压钢管等!

瑞文网,为您提供优质实用美文!包含随笔、日记、古诗文、实用文、总结、计划、祝福语、句子、职场文档等,为您写作提供指导和优质素材。

运城市盐湖区人民政府网站首页

成都东科盛业自动化设备有限公司--赫思曼,赫斯曼工业交换机,赫斯曼工业以太网产品,Hirschmann,施耐德,Schneider,MOXA,摩莎交换机,TSC

双宏化工有限公司是一家在国内外染料、有机颜料和印染行业中具有重要影响力的化工企业

湖北省文物考古研究院是中国南方规模最大、技术力量最为雄厚的专业研究机构之一,主要担负湖北省境内的考古调查、勘探与发掘任务,以及科研工作。

麦站隶属于秀站网络科技公司,官网:www.xiuzhanwang.com,提供优质免费可商用的pbootcms模板、易优模板、云优模板、织梦模板等,及更多建站素材、网站源码下载。更有虚拟主机、服务器、仿站/网站定制业务。

常熟风范电力设备有限公司


卢松松博客文章发布出现了失误,有2个微信好友私信我说博客文章发的不对,周松松同学把帖子发到了论坛,并发帖调侃到,松松网编辑跑路了吗?暂时还没有,问题表现,编辑把空文章直接发布了,在加上周末放假,没人检查,空白文章发布了一天,没人察觉,后很多朋友都在反馈,情况说明,其实这问题出现不是一两次了,好几次都这样,我自己编辑文章时也出现过类似情...。

干洗店是广大市民日常生活中经常消费的场所,提供的服务项目比较齐全,满足不同人群的洗衣需求,洗幽管家干洗是行业中口碑较好的品牌,使用先进的设备和精湛的技术为消费者带来专业的洗衣服务,在市场上收获大众顾客的好评不断,是很不错的合作项目,那么,洗幽管家干洗的加盟优势有哪些,洗幽管家干洗的加盟优势有哪些优势一,投入成本费用低创业者与洗幽管家干...。

对于创业者来说,人人都想与市场需求量高的项目合作,依靠品牌的力量可以顺顺利利的打开市场,那么,这样好的项目到底有没有呢,下文中小编为大家介绍行业中火热发展的项目,秦氏膏药,是一家实力雄厚的膏药生产商,在市场上拥有庞大的消费群体,备受广大消费者的欢迎,成为人们不二之选的膏药品牌,在市场上销售业绩也出现续性的增加,那么,秦氏膏药好不好用...。

5月24日,国家信息安全漏洞库,CNNVD,2022年度工作总结暨优秀支撑单位表彰大会在中国信息安全测评中心隆重举行,奇安信作为CNNVD一级技术支撑单位,凭借在漏洞报送数量和质量等方面的突出贡献,在167家技术支撑单位中脱颖而出,荣获,优秀技术支撑单位,、,高价值漏洞优秀贡献单位,、,高价值通报优秀贡献单位,三项大奖,优秀技术支撑单...。
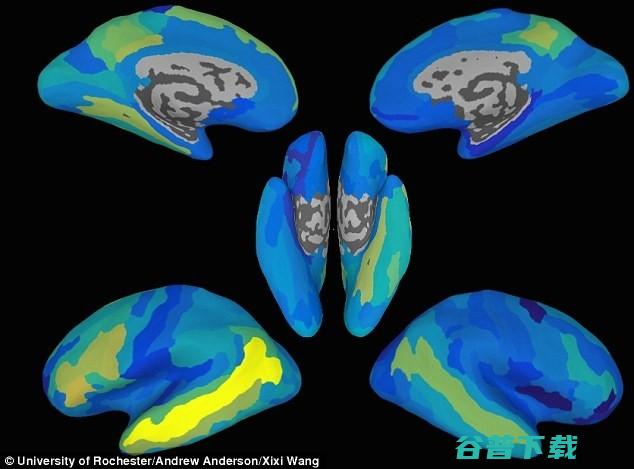
大多数的人可以对自己将要说的话做到完全保密,直到他们张嘴说话的那一秒,但是现在,计算机可以通过寻找你的大脑中与你将要说的话相关的大脑活动形式,迅速地预测你在想什么——是的,科学家们已经开始研发可以搜索与特定单词相关的大脑活动的计算机程序,并将这个程序用于猜测人们尚在大脑中构思的句子,这个程序预测的正确率大概在70%左右,AndrewA...。

深度调查,穹顶之下,引发了大的社会反响,每年的雾霾天气成为社会热点话题之一毋庸置疑,环保成为焦点有其必然性,由此推动了环保产品行业的发展,如果你错过了房地产、电商、汽车美容等行业,那就不要再错过环保用品这个黄金行业,也许现在不少打算智慧之选创业的朋友会问,到底环保产品代理好吗,为此,小编进行了简要的分析,接着就一起来看一看吧,前景广阔...。

现如今的人们越来越追求于个性化的美,所以很多人在除了会购买化妆品来保持自己美丽外,还会去到专业的美容院内,保养皮肤,做造型,因此,对于现时代的创业人士们来说,美容院本就是一个具备了不小吸引力的商机项目,也尤其适合加盟、代理这个模式,今天,小编就来带大家了解一下美容院加盟步骤是怎样的,美容院的加盟步骤大体上可分为三步,首先是寻找到合适的...。

据美国有线电视资讯网,CNN,最新信息,美国前总统特朗普集会上出现枪击事情后,美国总统拜登宣布了全国讲话,他在讲话中谴责这起枪击事情,并示意,美国不应该容忍这种暴力行为,这太令人厌恶了,这是咱们必定将这个国度勾搭起来的要素之一,,他在特拉华州宣布讲话时说道,,咱们不能准许这种事情出现,咱们不能这样,咱们不能放任这种事情,拜登补充...。

为期3天的北约峰会11日在美国首都华盛顿落下帷幕,峰会时期,北约各国示意将向乌克兰提供更多军事声援,支持乌克兰参与北约,并且渲染亚太地域弛缓形势,威望人士和专家学者指出,华盛顿峰会拱火欧洲、插手亚太,再次泄露北约怂恿对立、挑乱生战的本色,也再次证明北约是美国保养霸权的工具,重大要挟环球敌对与稳固,始终加深的军事狂热,俄乌抵触是此次峰...。

1、捷达是一辆合资汽车独立后的捷达依然属于公众的汽车品牌,所以捷达推出的车型依然是合资汽车望文生义,合资汽车是中方与本国投资者独特建设的名目中方出资转让土地厂房经常使用权和资金消费技术由国外提供其实汽车消费的核,2、捷达是合资车捷达是我国一汽汽车和德国公众汽车合资消费的一款紧凑型轿车值得一提的是,发起机驳回的是全铝材质,重要的改良在于...。

RoboMind是一款针对教育系统打造的编程环境,为用户提供了当下比较流行的编程技术、机器人学和人工智能学的知识。

SolidWorks2022是一款非常专业的计算机三维机械设计软件,具有系列零件设计表、水射流切割技术等功能,适用于工程制图建模、机械模型设计、钣金与焊接设计等领域

对于有充足资金的创业者,在选择创业项目时,可以考虑成立一家航空公司,那么,在决定加入此项目之前,先要知道成立航空公司开航空公司要多少钱,知道了费用后,再来判定自己是否能运营一家航空公司,那么,还在等什么,这就跟着小编一起来了解更多开设航空公司的资讯吧,想要成立航空公司的创业者,要具备充足的资金,根据航空公司的运营规模,来确定要支出的费...。

金融的本质是什么,风险滞后,利益先行,融慧金科创始人兼CEO王劲对雷锋网说,,但换个角度说,如果风控做不好,一旦经济下行,就是吃不了兜着走,融慧金科是前百度集团副总裁、百度金融事业群联合创始人王劲于2017年初成立的金融科技公司,主打端到端的全生命周期信贷解决方案,近日,融慧金科获得千万美元A,轮融资,本轮投资人为华创资本,其A...。

雷锋网·AI金融评论按,近日,在大洋彼岸的布宜诺斯艾利斯,G20峰会正在召开,这或许也是各国政府选择这个时候纷纷出台关于加密货币和区块链政策消息的原因,各国政府和监管机构纷纷发布相关措施,以进一步表达在ICO和虚拟货币业务领域的立场,如,英美两国相关机构在监管面前日趋理性,正尝试成立区块链或虚拟货币研究小组,以探索比特币等加密货币带给...。

雷锋网按,最近几个月半导体行业的大型并购频发,9月Nvidia宣布将以400亿美元现金加股票的形式收购Arm,十月底,AMD又宣布将以350亿美元收购赛灵思,紧接着,Marvell也宣布将通过股票加现金的方式,以总价约100亿美元的价格收购模拟芯片制造商Inphi,短短两个月就有总金额高达850以美元的收购交易,相比之下,英特尔最新的...。

创业简单的来说会出现这样两种不同的局面,一种就是在经营的过程中会红红火火,另外一种都是大家不想要面对的情景,那就是惨淡的生意,之所以会出现如今市场上这样的一些局面,就是因为大家不仅仅是在经营的过程中要面对许多问题,并且在面临每一个艰难问题的过程中,要如何做一个非常正确的选择,创业选择好品牌很重,嘿爱你寿司值得信赖,嘿爱你寿司作为一个全...。
