谈谈深度学习中记忆结构的设计和使用 从NLP终生学习开始

雷锋网 AI 科技评论按:终生学习,简单说是让模型有能力持续地学习新的信息,但更重要的是让模型学习新信息的同时还不要完全忘记以往学习过的内容(避免「灾难性遗忘」),是深度学习的长期发展和大规模应用中必不可少的一项模型能力。
近期,「NLP 网红」Sebastian Ruder 小哥把终生学习能力融入了语言模型中,方法是加入一个片段式记忆存储模块。实际上类似的做法也并不是第一次得到应用了,雷锋网 AI 科技评论一并介绍几篇相关论文。
终生语言学习中片段式记忆的作用
论文地址:
内容简介:首先我们把「终生语言学习」(lifelong language Learning)任务定义为:模型需要从连续的文本样本流中学习,其中不会指明数据集的边界。作者们提出了一个用片段式记忆存储结构增强语言模型的方式,模型中的存储可以进行稀疏经验重放,也可以进行局部适应,以减缓这种任务中的灾难性遗忘现象。另外,作者们也表明,这个记忆存储结构的空间复杂度可以进行大幅简化(可以降低 50% 到 90%),只需要随机选择把哪些样本存储在记忆中,这种做法对性能的影响非常小。作者们认为片段式记忆存储部件是通用语言智能模型中不可或缺的重要组件。
通过记忆能力增强模型表现其实并不是新鲜事,「经验重放(experience replay)」的思路最早可以追溯到 1990 年代的强化学习机器人控制论文《Programming Robots Using Reinforcement Learning and Teaching》()以及《Self-Improving Reactive Agents Based On Reinforcement Learning, Planning and Teaching》 (),论文中用教学的方式让机器人学会新的技能,那么记忆能力就与教学过程相配合,记录已经学会的技能。
下面我们再介绍几个新一些的成果
通过深度强化学习实现人类级别的控制
论文地址:
论文亮点:DeepMind 发表在《Nature》的鼎鼎大名的 DQN 论文中也使用了经验重放。在强化学习的设定中,智能体通过与环境交互获得数据(相当于监督学习中的标注数据集),经验重放可以让智能体重放、排练曾经执行过的动作,更高效地使用已经采集到的数据。当然了,DQN 的另一大贡献是学习到原始输入的高维表征,不再需要人工的特征工程。
MEMOry-Augmented Monte Carlo Tree Search
记忆增强的蒙特卡洛树搜索
论文地址:~mmueller/ps/2018/Chenjun-Xiao-M-MCTS-aaai18-final.pdf
AAAI 2018 杰出论文
论文简介:这篇论文把一个记忆结构和蒙特卡洛树搜索结合起来,为在线实时搜索提出了一种新的利用泛化性的方式。记忆结构中的每个存储位置都可以包含某个特定状态的信息。通过综合类似的状态的估计结果,这些记忆可以生成逼近的估计值。作者们展示了,在随机情况下,基于记忆的逼近值有更高可能性比原始的蒙特卡洛树搜索表现更好。
经验重放还有一些高级改进
优先经验重放
论文地址:
论文亮点:这篇论文的作者们提出,在之前的研究中,智能体学习到的经验是均匀地从重放记忆中采样的。而既然记忆的存储来自于智能体实际的探索活动,这就意味着智能体进行活动、获得记忆的分布和从记忆中采样、利用记忆的分布是一样的。作者们认为,智能体获得的记忆中肯定有一些是重要的、有一些是不那么重要的,我们应当更多地利用比较重要的记忆,这样可以用同样多的记忆提高智能体的表现。这篇论文中作者们就设计了一个为记忆的优先程度排序的框架,更多地重放重要的记忆,以便更快地学习。作者们在 DQN 上做了这个实验,改进后的 DQN 比原来的(均一记忆)的 DQN 在绝大多数游戏中都取得了更好的表现。
后见经验重放
论文地址:
论文亮点:假想要让机械臂执行一个用末端在桌面上推方块到指定地点的任务。对于强化学习模型来说,初次尝试基本是注定失败的;如果不是特别的幸运,接下来的几次尝试也同样会失败。典型的强化学习算法是无法从这些失败经验中学习的,因为它们一直接收到固定的失败(-1)反馈,也就不含有任何可以指导学习的信号。
人类在执行任务的时候其实有一个直觉的感受是:即便我没有达成原来那个给定的目标,我起码还是完成了另外一个目标的。HER的核心思想就是把这一人类直觉公式化。在这里,HER会把实际达到的目标暂且看成要达到的目标;进行这个替换以后,算法认为自己毕竟达到了某个目标,从而可以得到一个学习信号进行学习,即便达到的目标并不是最开始任务要求的那个目标。如果持续进行这个过程,最终算法可以学会达成任意一个目标,其中也自然就包括了我们最开始要求的目标。
依靠这样的办法,即便最开始的时候机械臂根本就碰不到圆盘、以及反馈是稀疏的,最终它也学会了如何把圆盘拨到桌子上的指定位置。这个算法之所以称为Hindsight Experience Replay 后见经验重放,就是因为它是在完成了一次动作之后再选定目标、重放经验进行学习。也所以,HER可以和任何策略无关的强化学习算法结合起来使用,比如DDPG+HER。
这 7 篇论文打包下载:
雷锋网 AI 科技评论整理
原创文章,未经授权禁止转载。详情见 转载须知 。



喷漆房、烤漆房、废气净化设备

比克尔下载中心主要为您提供免费软件、绿色软件、游戏软件、安卓手机软件下载及其相关的使用教程,同时还有通俗易懂的电脑技术教程、游戏资讯、游戏攻略秘籍等


风车团(www.jdfct.com)为你提供面料行情资讯、服装面料产品及企业大全信息库、网上纺织品批发采购信息.

武汉市中江科技有限公司专业维修电动执行器,维修西博斯(SIPOS),罗托克(ROTORK),奥托克(AUTORK),奥玛,瑞基,川仪执行器,维修变频器,维修伺服驱动器。芯片级维修工业控制设备、检测设备、电梯设备、自动化生产线、运动控制系统、数控机床、加工中心、工业生产机器人、烟机、纺机。芯片级维修变频器、软启动器、智能马达控制器、伺服驱动器、直流调速器、工业控制模块、电源模块、电动执行机构。芯片级维修PLC模块、DCS模块、PCS模块、工业控制电路板、各种卡件、机床控制电路板、电梯控制电路板。芯片级维修空压机、拧紧机、熔胶机、UPS、断路器。芯片级维修流量计、水位计、各种检测仪表。芯片级维修伺服电机。

书画儿学习网为您提供各类国学知识,包括但不限于汉语字典、汉语词典、成语大全、古诗词、诗词名句、造句、近反义词、英文缩写词、二十四节气、百家姓起名大全、范文工作报告总结等精品精选国学知识文章大全,希望成为你学习之路上最可靠的港湾。

扬州佰得粉末设备制造有限公司,专注生产粉末涂料,塑粉,涂装设备,欢迎新老客户来电合作。

卷板机,三辊卷板机,海安恒益机械厂,四辊卷板机

星辰影院网提供好看的首映最新热播电影,全集电视剧,综艺,动漫,高清美剧手机在线观看和剧情介绍,星辰影院网全天24小时在线更新,让大家以最快的速度享受视觉上的盛宴!

诸城市诚友机械科技有限公司主要以生产食品机械设备为主,业务客户遍布全国各地大中小城市及国外用户。经过多年的发展,现已成为集研发、生产、销售于一体的食品机械实力型生产企业。 我公司开发、制造的蔬菜清洗机、风干机、巴氏杀菌机、真空滚揉机、斩拌机、行星搅拌炒锅、夹层锅、真空包装机等设备。以结构独特、造型美观、制作精良、技术先进等特点,而且公司不断自我技术提升,完善产品的功能和质量,深受广大客户的好评。

【云企网】在2025年2月4日19时更新,成立于2011年,立志做国内知名的免费发布信息的平台,中小企业推广首选,任何人都可搜索“云企网”进入本站。

江苏博远人才管理股份有限公司


英伟达CEO黄仁勋去越南了,他主要做了三件事,今天咱们就说说,假如英伟达的AI研发中心成立了,将会给周边带来什么?首先,带来的是人们对未来的憧憬,你想象一下,数年后,一位越南普通的中专生毕业了,他坐了1小时公交,拿着简历,跑到了英伟达研发中心,很顺利面试成功了,小伙非常开心,回到家后,父亲搭在小伙肩膀上说,我们家种了一辈子的地,没想到...。

一家不大的小店,源源不断的购买队伍,还有香飘十里的味道,这就是桥头排骨的经营优势,作为火热的小吃项目,桥头排骨一直深受消费者的欢迎与喜爱,也深受创业者的心仪与青睐,下面就来看看,桥头排骨加盟经营范围是什么,餐品受欢迎吗,桥头排骨加盟经营范围是什么各大加盟店以桥头排骨作为招牌系列,配以不同的调味料佐味,迎合了不同食客的口味习惯与喜好,有...。
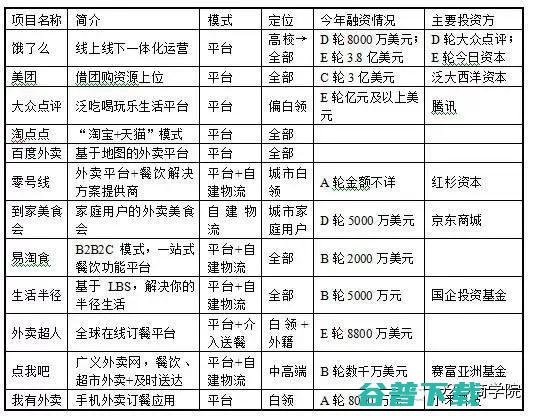
文管艺雯,IT老友记O2O领域观察者2014年年初,你或许还停留在团购大战的硝烟里,当烟雾渐渐散去的时候,你忽然发现你的周围到处都在谈论外卖O2O,润物细无声,当你察觉的时候,外卖O2O已经遍地开花了,外卖O2O的发芽或许细而无声,但是这之后的发展呈破竹之势,用轰轰烈烈来形容都不为过,也许你对外卖O2O的了解仅限于在手机上下单,领个红...。
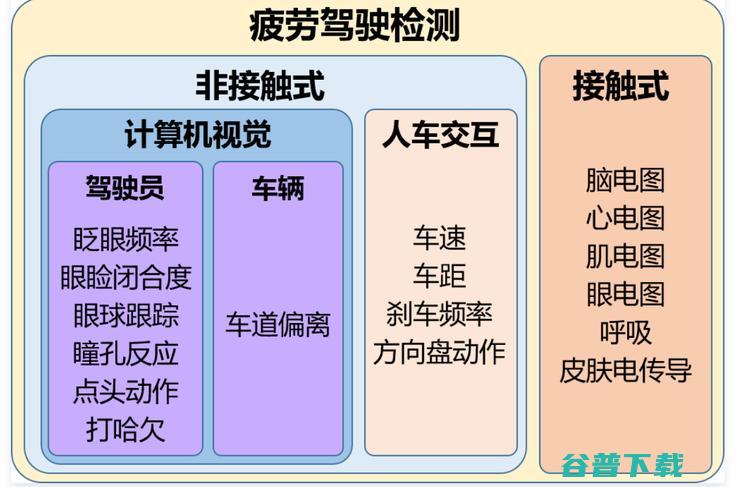
小孩或宠物因粗心遗忘车内而致死,长途司机因瞌睡、分神而车毁人亡,多少人因开车回信息、接电话险酿大祸,这些血淋淋的案例在我们身边屡见不鲜,针对这些交通痛点,自动驾驶技术研发商MINIEYE于今天在上海推出了一套I,CS,In,CabinSensing,座舱感知量产方案,这套方案可以及时发现遗落在车里的小孩或宠物,可以及时发现司机瞌睡或分...。

中国企业的出海之路不再是单一的线性发展,而是变得更加多元化和复杂化,从早期依托亚马逊等电商平台,到如今独立站的兴起,再到TikTok等社交媒体平台的内容电商模式,行业形态的每一次变革背后都会带来新的挑战和机遇,当前,成功的品牌出海不仅需要优质的产品和强大的品牌力,更需要对目标市场有深刻的理解和灵活的策略调整,最近我们邀请到了有行业实战...。

文,笑饮俄罗斯联邦安保会议副主席德米特里梅德韦杰夫被任命为俄罗斯武装力气征募委员会主席,普京总统签订了对于成立该委员会的命令,全球时报月日转引,俄罗斯商业咨询日报,网站当日报道如此称,从梅德韦杰夫的新职务可以看出,对俄罗斯来说,新一轮兵员征募,确实有须要经受考验之处,梅德韦杰夫何许人也,俄罗斯前总统,在苏联解体、俄罗斯联邦成立至今,一...。

华阳陆地钻研核心、中国南海钻研院和中国国内法学会7月11日在京联结发布了,南海仲裁案判决再批驳,报告,所谓,南海仲裁案判决,出台距今已有8年,报告重申了中国对仲裁案以及仲裁判决的立场,强调中国政府不会抵赖仲裁庭作出的合法判决,也不会接受任何基于判决的主张和执行,近日,中方发布,仁爱礁合法,坐滩,军舰破坏珊瑚礁生态系统考查报告,黄岩岛...。

最近有一档综艺节目创造里面有一位叫段奥娟的选手非常受大家欢迎且瞩目她一出场就让全场安静她唱了一首干净的从前慢令在场所有评委陶醉其中段奥娟一身清爽的装扮素颜搭配青葱的校服脸上甜甜地笑清亮的嗓音在众多浓妆艳抹的网红脸中脱颖而出这个青春十足的岁高中女生彻底火了那么抖音段奥娟从前慢在哪听小编在这里为大家带来这首段奥娟从前慢的歌...

顺企网佛山公司注册服务公司厂家大全列表,包括佛山市粤办事企业资质代理有限公司、广东慧伽企业管理有限公司、佛山市顺德区泽熹博洋企业管理服务部、鬼脚七(佛山)科技有限公司等在内的28家佛山公司注册服务公司厂家的地址电话法人代表和联系电话等信息。1页,当前显示第1页结果,按照产品多少和注册时间排名

网易汽车值得买为您提供十堰市缤智最低报价、团购。为您全方位评估推荐最优车型,网易汽车值得买您指尖上的购车顾问!

360安全卫士测试版,360安全卫士测试版是360安全卫士的新功能版,与正式版相比包含更多的新功能,实际上360安全卫士最新版使用起来其稳定性与正式版没有多大的区别,您可以免费下载。

掌握好销售技巧就是在销售过程中成功了一半,那么要如何去掌握完美经典的销售技巧呢?下面小编结合一位在酒庄销售葡萄酒多年的前辈谈谈自身经历和对于销售有什么技巧与方法?1、为人脚踏实地脚踏实地,与人接触得时候,该是怎么样,就是怎么样,可以稍微包装一些,但是切记,不要太过夸大事实,要为客户着想,不要太过追求利润,比如说说要200左右的葡萄酒,...。

众所周知,阿里巴巴有自己的花名文化如马云叫风清扬,张勇叫逍遥子,陆兆禧叫铁木真等等而高晓松入职阿里巴巴的时候,也被要求起一个花名高晓松觉得很为难,因为这么多年,好听的花名基本都已经被用完了想了很久,高晓松想到一个,肯定没人用过第二天到公司说我给我自己起的花名叫田伯光当即就被驳回,理由是阿里的员工怎么能用一个淫贼的名字呢高晓松辩解道,我...。

比亚迪汽车现已成为国产车企中的一把好手,这源于比亚迪汽车不断对夯实自身的技术实力,不断的研发出具有代表性的创立技术,而现在比亚迪汽车亦成为很多消费者的购车优选,那这样是否能够验证比亚迪汽车销量怎么样呢,下面随着小编的脚步一起来了解下,比亚迪汽车销量比亚迪汽车坚持以科技创立,不断的研发具有专利代表性的技术,为消费者提供更加智能化,更加安...。

随着串串加盟店越来越多,各种品牌也是层出不穷,商家变着花样的推销,但这也是几家欢喜几家忧,但是作为串串香加盟店的店主,必须要了解如何经营好自己的加盟店,才能在竞争激烈的串串香加盟店中脱颖而出,今天蜀师傅串串加盟店就给大家分享几点经营技巧,一、菜品创立串串加盟店的模式大都是大同小异,一锅底一把串,涮着、撸着,但是串串香加盟店一味地模仿他...。

云,端,的产业模式正向,云边端,迁移,在部分行业已经是正在发生的事实,,云,端,在以连接人与人为中心的移动互联网时代得到长足发展,面向5G开启的万物互联时代,,云边端,将开启下一个十年,边缘计算的兴起云边端中的边,指的就是边缘计算,边缘计算的出现解决了三大问题,带宽、时延和安全,关于边缘计算的定义不一而同,整体意思相近,业界一致同意...。
