平安科技前沿技术部门负责人王磊 大规模预训练模型在垂直领域应用的缺陷与改进 (平安科技前沿技术部门负责人王磊)

整理 |维克多
这些模型的实际应用情况如何?它们能解决哪些实际问题?还有哪些不足?
2021年12月, 平安科技前沿技术部门负责人王磊 在 CNCC 2021“产业共话:大型预训练模型的商业应用及技术发展方向”论坛上,做了《大规模预训练模型金融领域应用中面临的主要问题与应对技术探讨》的报告。在报告中,他指出了当前大规模预训练模型在垂直领域的“致命”问题,针对这些问题提出了平安科技的解决方案。
例如,他认为大规模预训练模型在垂直领域性能达不到要求的原因可能是: “大规模预训练模型的训练语料库规模很大,既包含了该领域的关键信息也包含了其他无关信息,使得模型缺少对关键信息的关注”,“当前大规模预训练模型的机制改进也也很少涉及对关键信息的提取”。
基于此,王磊认为,大规模预训练模型本质上都是在处理信号,但只要是信号,就可能进行分解,将背景信息和垂直领域的信息分离开来,从而有效贴合下游场景。
金融客户对上线模型的精度要求很高,不少场景直接使用预加载模型往往很难满足需求。 王磊提出置信度评估方法,利用强化学习和Bagging思想评估模型靠谱程度。
以下是演讲全文,AI科技评论做了不改变原意的整理。
在平安公司场景下,大规模预训练模型在金融业务上的应用主要集中在贷款风控与股市投资。同时,这 两个领域近些年的建模在因子层面会比较依赖大数据,例如文本信息,使用 预训练模型进行处理能够形成一些特征因子,从而方便分析理解。
大规模预训练模型已经在几十个任务上刷榜,在医疗领域的表现更是令人瞠目结舌。但是深入到金融领域,其性能仍然无法满足要求。 以选股为例,传统方法在信息获取阶段会人工从研报、雪球、知乎等论坛找寻一家公司的信息以及风评,然后结合基金经理或投资人自己的判断获得对这家公司的洞察,从而决定是否买进。
由于金融领域的容错性特别低,而且要求模型对专业知识有很深的理解。如果达不到一定的理解水平,从业者宁可不用AI模型。

一般而言,对于单任务,一个模型的性能能达到90%,但如果需要理解一段话或者一段专业评语,则需要三层模型才能形成一定的特征,这时模型性能就会下降为70%左右的水平。因此,在投资等要求严格的场景下,预训练模型很难应用。
为什么会出现这种问题?个人认为,大规模预训练模型的语料库是大型文本,它注重广度和背景,对于深度和细节较少关注。
以国内企业研发的一些预训练模型为例,其早期改进的方式都集中在Mask层面,而Msak机制更倾向于集中学习信息的广度。而当模型应用到法律、医学等领域时,更需要的是“深度”理解。
如何解决?目前有很多思路,例如加入专家知识,知识增强、混合训练等等。目前,中国平安在探索语义空间分解技术和置信度评估方法。

大规模预训练模型涵盖了很多背景信息,那么能否进行再一次的分解,将背景信息和垂直领域的知识体系分离开来?分解不能没有标准和依据,而大规模语言模型实际上是在处理信号,当模型理解信号的时候,虽然信息和语义仍然在,但却在中间发生了各种形式的变换。因此,无论是哪种大模型,其本质都是将信息或语义重新转述为信号。
那么,既然是信号,就能够进行分解。我们已经尝试了多种方式,其中一种做法是:基于国内机构提出的大规模预训练模型,加入高中低滤波器,然后用自适应频谱机制进行处理,可以理解为一个Attention机制,最后进入下游任务训练。
经过实验表明,我们提出的频谱分解网络结构(Filter-Loss和Filter-layer ) ,结合经典语言模型训练神经网络,在各类型任务中均可显著提升语言模型能力。

更为具体,不仅是在垂直领域,改进后的语言模型在11个国际公开数据集上测试结果较BERT模型提升。这也证明,将语义空间进行分离,然后和下游任务结合的做法具有通用性。
在金融领域,无论模型达到什么样的水准,其上限永远是客户需求。例如客户的标准是95%的性能,而模型只能达到92%,仅仅差3个百分点,就会让模型很难上线。这类问题在金融企业非常容易遇到。
为了解决上述问题,平安科技提出了基于置信度评估的方法,通过这种方法,模型可以评估其“靠谱程度”。如果靠谱程度高,就通过,如果低,那么就需要人类接手,或者直接放弃。因为很多场景并不是信息越多越好,信息冗余已经成为了不可忽视的现象。
而且,还需要解决围绕各类复杂经济主体的多源异构大数据难以统一表述、信息难以整体耦合和关联的问题。平安通过对数据标签化提取的置信度技术研究,提升金融数据标签化提取精度,提升流程自动化水平;通过对多尺度多维度融合语义关联的经济主体表达技术的研究,构建金融领域知识图谱。

信度评估方法采用的是强化学习构建置信度框架。主要分为三个部分:
1.用BERT等语言模型等抽取语义向量
2.利用双向长短期记忆方式组合全局向量
3. 强化学习模块根据人工打分拟合相关标准,输出置信度分数。

此外,还可以尝试通过Bagging思想构建置信度框架。模型pipeline有4个阶段:
1.利用Bagging思想,从数据中抽样5份,训练出5套模型参数;
2. 在少量测试集上测试各套参数性能,根据性能例如F1值,分配各模型置信度权重;
3. 各套参数选择某个标签后,在结果统计中累加对应参数权重;
4. 最终输出累加置信度最高标签。

改进后的语言模型在语义相似度、多分类、语义蕴含等多类型国际公开数据集上测试精度较BERT模型的提升大多在10%-20%,但召回率下降20%-50%; 在实际项目中从舆情中提取公司标签的模型精度提升11个百分点,达到93%。
这在商业上非常有价值,例如虽然 召回率 降低了50个百分点,但意味着只有一半的模型需要人工干预,另一半的模型完全可以交给自动化,这远比模型无法上线要好的多。
在金融领域,例如选股,模型的精准度是首先需要考虑的,其他指标可以稍差。 例如从1000只备选股票中模型只选出了50只良好股票,可能会错过50只良好股票。但这种错过也是允许的,毕竟模型会“保证”选出来的50只股票大概率能够赚钱或有超额收益。
原创文章,未经授权禁止转载。详情见 转载须知 。



表格主要分为表格jquery特效代码、表格js特效代码、表格网页代码下载。

黑猫投诉平台是新浪旗下消费者投诉平台,快速解决315消费投诉,315投诉维权,共享服务投诉,购物平台投诉,旅游出行投诉,住宿投诉,娱乐生活投诉,教育培训投诉,金融支付投诉等,拥有海量企业库,各领域专家,专业律师团队及权威帮帮团来帮助消费者。

军人征婚交友网-军民婚恋网-军中红娘-8181军人网——尽在绣球缘

南瓜馒头的做法,南瓜馒头怎么做请看步骤:1.南瓜蒸的时候忘记拍照了,南瓜去皮切块上锅蒸熟,捣成泥放点白糖搅拌均匀,等温热的时候放入酵母粉搅拌均匀。分次加入面粉揉,因为南瓜含水量不一样,所以面粉要分次加,直到不是很黏手了就可以了,放在温暖地方发酵就可以了...

北京泓泰天诚科技有限公司(简称泓泰天诚)于2009年成立,是集研发、生产、服务于一体的国家和中关村双高新技术企业,已通过ISO9001、ISO14001、OHSAS18001等认证,拥有多项自主知识产权和专利。 泓泰天诚重点面向石油化工行业,围绕生产过程控制与优化、生产管理信息化、节能减排等业务领域,提供有竞争力的产品、整体解决方案以及配套的软硬件开发、系统集成、技术支持和技术服务,是中国石油、中国石化、中国海油、中化集团、中国兵器工业集团等公司认证的设备与技术服务供应商。

网站描述

中誉财税专业从事公司注册,代办营业执照,代理记账,公司注销等业务,已有多年行业经验,服务超500家公司,免费提供咨询,助力企业成长。

火树游戏平台收录了海量精品、热门小游戏以及H5游戏;为玩家提供最新手机游戏下载,还有海量H5游戏、小游戏福利礼包,更有好玩有趣的H5游戏、小游戏攻略;以“用心创造,热衷好游戏,分享乐趣!”的理念,打造最精品、最优质以及最热门的小游戏平台,更多好玩游戏,尽在火树游戏。

江西赣州华鑫针织有限公司

主营电缆电缆样品,电缆样品制作,电缆样品设计,电缆样品展板,电缆样品头,电缆样品批发,电缆样品生产,电缆样品销售,电缆样品图片,电缆样品展柜,电缆样品盒,电缆电力电缆,铝合金电力电缆样品,矿用电缆样品,船用电缆样品,硅橡胶电缆样品,氟塑料电缆样品,计算机电缆样品,控制电缆样品,特种电缆样品,核级电缆样品,变频器专用电缆样品,分支电缆样品,扁电缆样品,拖缆样品,射频电缆样品,信号电缆样品,光缆样品,,扬州宏远电缆样品有限公司

万千技术人必备的ChatGPT中文社区网站,在这里获Prompt灵感、学AI教程、领AI资源,更有无数志同道合的AI技术人和你一起交流经验共同进步。无论是想深入学习AI知识,或是想实现自己的梦想,ChatGPT中文社区都是你必上网站。带你领略科技之美,探索无限可能,让创意不再受限!

滕州中合锻压机床有限公司是国内专业的液压机厂家,主营四柱液压机、三梁四柱液压机、框架式液压机、单臂液压机等设备,定制行业专用液压机,滕州液压机厂家直销。采购热线:13963280040


成人用品的市场需求量高,成人用品行业发展迅速,尤其在大城市中或者经济实力强的城市中,拥有大量的人口优势,就可以带来大量的市场需求,能够增加开店的成功几率,现在市面上有很多成人用品的品牌,其中宸趣成人用品就是个不错的品牌,品牌形象好,产品品质高,还获得很多网友的认可,很多网友就想要了解,宸趣成人用品现在有市场吗,能加盟吗,宸趣成人用品现...。

冷启动推荐一直是推荐系统中一个极具挑战的问题,跨领域推荐系统使用源领域中的交互数据来帮助目标领域的冷启动推荐,这篇文章提出了一种个性化迁移用户兴趣偏好的跨领域推荐的方法,给目标领域冷启动用户进行更精准的推荐,本文基于论文,PersonalizedTransferofUserPreferencesforCross,domainRecom...。
沈阿姨今年四十七岁,之前是城厢街道丁香公馆小区里一户人家的家政阿姨,没想到被前东家错认成了偷钱包、手机的小偷,平白无故在派出所被扣留了一天一夜,之后说明清白放了出来,前东家也没有任何安慰的话语,让她感到非常委屈,在她家我做了五天,然后到21号结束不做,工资也是结算给我的,直到22号出了这件事,她报了警,说我偷她的东西,之后派出所打电...。

雷锋网按,7月12日,7月14日,2019第四届全球人工智能与机器人峰会,CCF,GAIR2019,于深圳正式召开,峰会由中国计算机学会,CCF,主办,雷锋网、香港中文大学,深圳,承办,深圳市人工智能与机器人研究院协办,得到了深圳市政府的大力指导,是国内人工智能和机器人学术界、工业界及投资界三大领域的顶级交流博览盛会,旨在打造国内人工...。

高新兴接下来想做的事情是要给每一辆车都配上专属,身份证,成立于1997年的高新兴集团是最顶尖的智慧城市系统解决方案提供商之一,他们即将为全国车辆打造的这张身份证学名叫做,汽车电子标识,,也可以称之为,汽车电子车牌,汽车电子标识形似,居民身份证,,其中嵌有专属电子芯片,储存了包括车牌号码、车辆保险、车辆年检等相关信息,它可直接贴于汽...。

现在很多年轻人聚会场所以蹦迪酒吧为主,在蹦迪酒吧有非常热烈的氛围,喝酒、娱乐等各种活动让人们在工作之余放松身心,因此越来越多的蹦迪酒吧出现,吸引了年轻人们的关注,也是创业者们想要了解的项目,那么,蹦迪酒吧需要多少钱,市场上经营蹦迪酒吧的品牌还是比较多的,想要更加快速的吸引消费者目光,要建设一个具有创意装修、氛围感较好、项目多元化的酒吧...。

网易公益“一块屏”落地浙江泰顺科技助推县域学校“教育共富”,公益,教育,乡村振兴,智慧化,信息化

申明,1.以上内容仅代表揭发者自己,不代表黑猫揭发立场,2.未经授权,本平台案例制止任何转载,违者将被清查法律责任,3.黑猫揭发处置揭发不收取任何费用,凡以黑猫揭发名义不要钱的均为混充、诈骗行为,请及时报警并与黑猫官网反应,揭发邮箱heimaotousu@vip.sina.com,4.请大家选用官网渠道处置生产纠纷,不要轻信第三方机构...。

[全球网报道]据台湾中时资讯网、中天资讯网7月11日报道,,美国在台协会,AIT,新任处长谷立言日前与台当局指导人赖清德会面,重申美国对台湾的允许,并称这合乎美国长期以来的,一中政策,而台媒留意到,谷立言,一中,两字在赖办的资讯稿中,被消音,了,台湾中天资讯网报道称,依据AIT在会后所颁布的资讯稿,谷立言与赖清德会面时谈到,美国会...。

[全球网报道记者姜蔼玲]美国白宫外地11日宣布申明称,美国、加拿大和芬兰将建设,极地破冰船协作方案,三边协定,在极地破冰船消费等方面启动协作,这一信息引发多家外媒关注,路透社对此渲染称,美加芬此举旨在增强三国造船业,以便在策略位置日益关键的极地地域与中国和俄罗斯相,抗衡,依据白宫11日申明,美国、加拿大和芬兰指导人今日宣布,计划建设...。

山西2024年将实现全省117个县(市、区)全部通高速公路,里程,太原,山西省,高速公路

绿联USB3.0千兆网卡驱动,本驱动用于Ugreen绿联USB3.0千兆外接网卡,本网卡使用了亚信AX88179高速芯片。包括全平台操作系统windows/Mac/Linux支持WINXP/7/WIN8系统,您可以免费下载。

雷锋网AI科技评论按,2018年12月16日,在全国博士后管委会办公室、中国博士后科学基金会、国家自然科学基金委信息学部、中国计算机学会等单位的大力支持下,由鹏城实验室举办的,2018第六届全国计算机学科博士后论坛,于广东省深圳市鹏城实验室召开,2018第六届全国计算机学科博士后论坛,召开自2010年6月以来,全国计算机学科博士后论...。

彭博社援引消息人士的说法称,美国第二大打车应用Lyft正在寻找收购方,不过,Uber高管在几周前对投资人表示,该公司不会支付超过20亿美元的价格收购Lyft,同时也有知情人士表示,Lyft不会考虑20亿美元的收购报价,上周,美国科技博客Recode报道称,Lyft寻求高达90亿美元的收购报价,但并未吸引收购方的兴趣,消息人士表示,作为...。
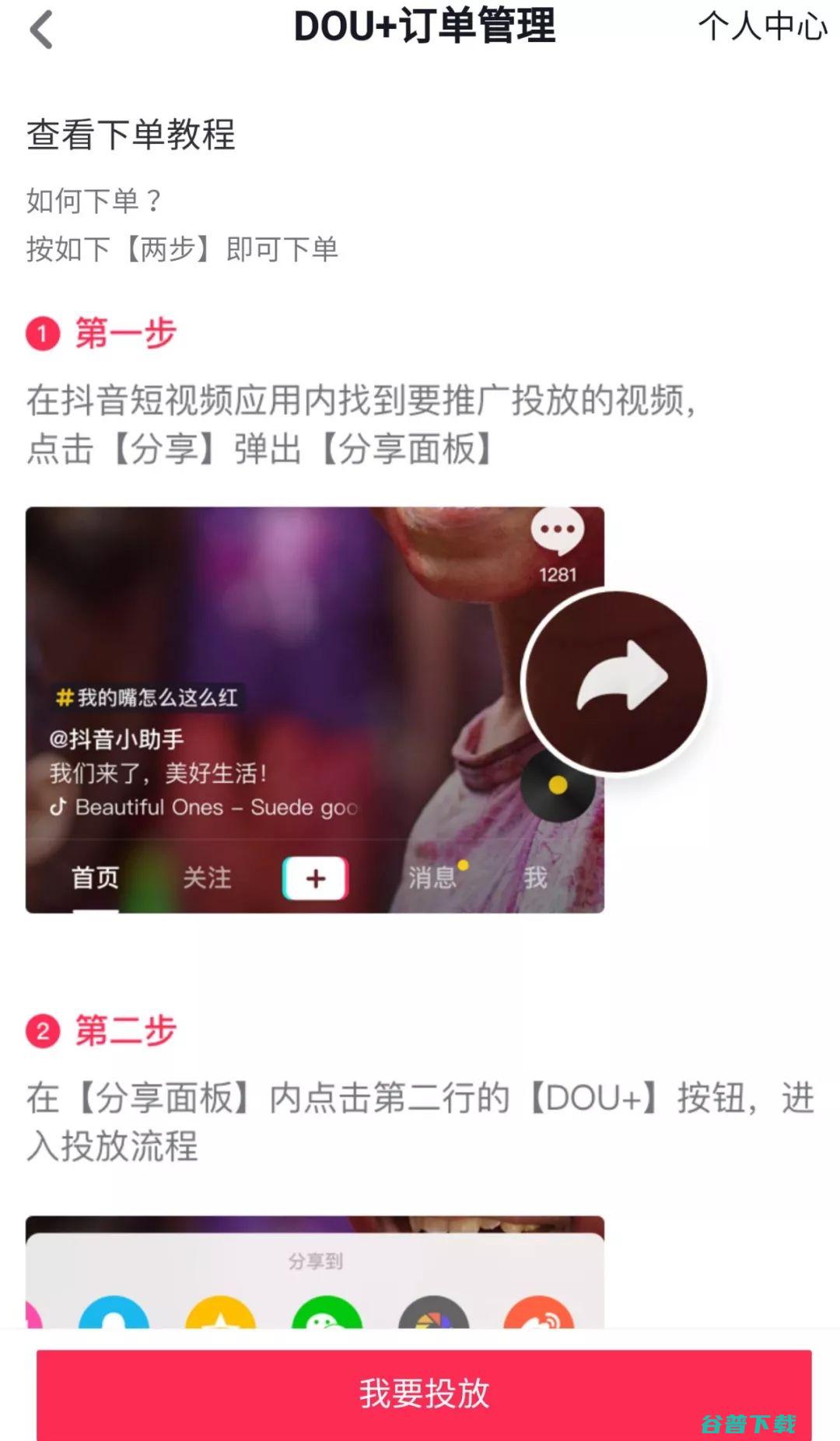
抖音作为目前非常热门的一款娱乐软件,大家不仅能在这里观看各种视频来打发时间,同时还能通过软件来检测账户状态,那么具体怎么操作呢?看完下文,你就明白详细的方法步骤了,...。
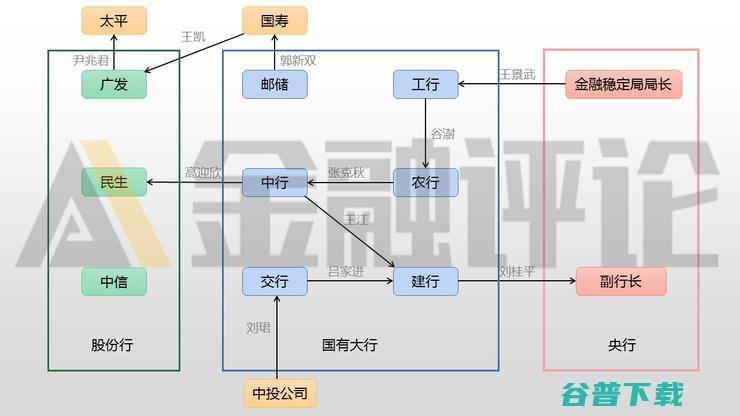
大中型银行频繁的高管人事,大挪移,,从2020年延续到了2021年,这期间,除交行外,其余五位国有大行的正行长或董事长均有职务调动;工行、中行、邮储银行的行长位置,仍然无人接替,民生、广发、中信等股份行,也出现了不同程度的中高层变动,雷锋网AI金融评论整理了2020年至2021年初,大中型银行的高管流动如下,雷锋网AI金融评论根据公开...。

2009年1月3日,位于芬兰赫尔辛基的一台小型服务器上,第一个序号为0的,创世区块,诞生,六天后,序号为1的区块出现,与前者相连形成链,区块链的序幕由此拉开,十多年过去,幕后推手,中本聪,仍是互联网上的,神秘人,,而区块链技术早已风靡全球,走过疯狂造富、赤身狂奔、幻影泡沫的野蛮生长后,逐渐回归理性,在不同国度寻找最妥帖的叙事方式,在我...。
