17篇论文 详解图的机器学习趋势 (论文篇数是什么)

雷锋网 AI 科技评论按:本文来自德国 Fraunhofer 协会 IAIS 研究所的研究科学家 Michael Galkin,他的研究课题主要是把知识图结合到对话 AI 中。雷锋网 AI 科技评论全文编译如下。
必须承认,图的机器学习(Machine Learning on Graphs)已经成为各大AI顶会的热门话题,NeurIPS 当然也不会例外。
在NeurIPS 2019上,仅主会场就有 100多个与图相关的论文;另外,至少有三个workshop的主题与图有关:
我们希望在接下来的这篇文章里,能够尽可能完整地讨论基于图的机器学习的研究趋势,当然显然不会包括所有。目录如下:

传统的嵌入算法都是在“平坦”的欧氏空间中学习嵌入向量,为了让向量有更高的表示能力,就会选择尽量高的维数(50维到200维),向量之间的距离也是根据欧氏几何来计算。相比之下,双曲算法中用到的是庞加莱(Poincare)球面和双曲空间。在嵌入向量的使用场景里,可以把庞加莱球面看作一个连续的树结构,树的根节点在球的中心,枝干和叶子更靠近球面一些(如上面的动图)。
这样一来,双曲嵌入表征层级结构的能力就要比欧氏空间嵌入的能力高得多,同时需要的维数却更少。不过,双曲网络的训练和优化依然是相当难的。NeurIPS2018中有几篇论文对双曲神经网络的构建做了深入的理论分析,今年在NeurIPS2019上我们终于看到了双曲几何和图结构结合的应用。
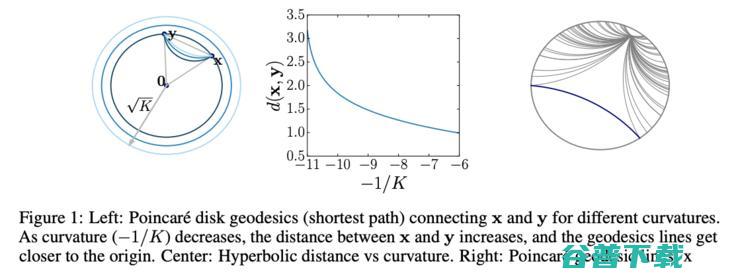
论文 1 和论文 2 两者的思想是相似的,都希望把双曲空间的好处和图神经网络的表达能力结合起来,只不过具体的模型设计有所区别。前一篇论文主要研究了节点分类和连接预测任务,相比于欧氏空间中的方法大大降低了错误率,在Gromov双曲性分数较低(图和树结构的相似度)的数据集上表现尤其好。后一篇论文关注的重点是图分类任务。
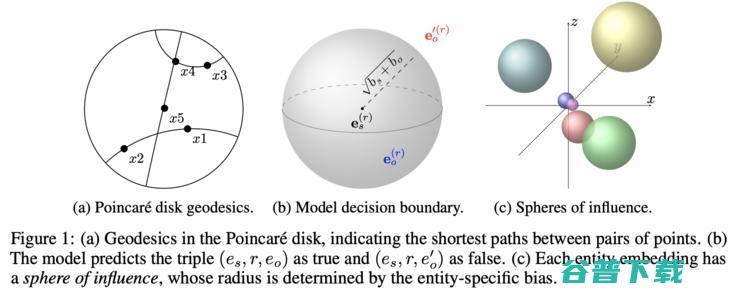
论文 3 在它们的多关系庞加莱模型(MuRP)的知识图嵌入中用上了双曲几何。直觉上,正确的三元组客体应该落在主体附近的某个超球面中,相关的这些决策边界是由学习到的参数描绘的。作者用来优化模型的是黎曼几何SGD(大量数学警告)。在两个标准的评测数据集 WN18RR 和 FB15k-237 上,MuRP 的效果比对比模型更好,因为它“更具备双曲几何”而且也更适用于树结构(如果能像上面的论文一样计算一下Gromov双曲性分数就更好了)。更有趣的是,MuRP只需要40维,得到的准确率就和欧氏空间模型用100维甚至200维向量的结果差不多!明显可以看到,双曲空间的模型可以节省空间维度和存储容量,同时还不需要有任何精度的牺牲。
我们还有一个双曲知识图嵌入比赛,获奖方法名为 RotationH,论文见,其实和上面的双曲图卷积神经网络论文的作者是同一个人。这个模型使用了双曲空间的旋转(思路上和RotatE模型相似,不过RotatE是复数空间的模型),也使用了可学习的曲率。RotationH 在WN18RR上刷新了最好成绩,而且在低维的设定下也有很好的表现,比如,32维的RotationH就能得到和500维RotatE差不多的表现。
如果你碰巧在大学学习了sinh(双曲正弦)、庞加莱球面、洛伦兹双曲面之类的高等几何知识但是从来都不知道在哪能用上的话,你的机会来了,做双曲几何+图神经网络吧。
如果你平时就有关注arXiv或者AI会议论文的话,你肯定已经发现,每年都会有一些越来越复杂的知识图嵌入模型,每次都会把最佳表现的记录刷新那么一点点。那么,知识图的表达能力有没有理论上限呢,或者有没有人研究过模型本身能对哪些建模、对哪些不能建模呢?看到这篇文章的你可太幸运了,下面这些答案送给你。

交换群:弱鸡;阿贝尔群:大佬
论文 4 从群论的角度来研究KG嵌入。结果表明,在复空间中可以对阿贝尔群进行建模,且证明了RotatE(在复空间中进行旋转)可以表示任何有限阿贝尔群。
有没有被“群论”、“阿贝尔群”这些数学名词吓到?不过没关系,这篇文章里有对相关的群论知识做简要介绍。不过这个工作在如何将这个工作拓展到1-N或N-N的关系上,还有很大的gap。作者提出一个假设,即或许我们可以用四元数域H来代替复数空间C……
……在这次NeurIPS' 19上,这个问题被 Zhang et al. 解决了。他们提出了QuatE,一个四元数KG嵌入模型。什么是四元数?这个需要说清楚。简单来说,复数有一个实部,一个虚部,例如a+ib;而四元数,有三个虚部,例如 a+ib+jc+kd。相比复数会多出两个自由度,且在计算上更为稳定。QuatE将关系建模为4维空间(hypercomplex space)上的旋转,从而将complEx 和 RotatE统一起来。在RotatE中,你有一个旋转平面;而在QuatE中,你会有两个。此外,对称、反对称和逆的功能都保留了下来。与RotatE相比,QuatE在 FB15k-237上训练所需的自由参数减少了 80%。
我上面并没有从群的角度来分析这篇文章,不过若感兴趣,你可以尝试去读原文:
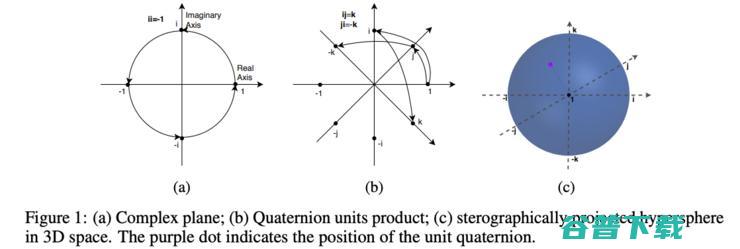
四元数域的旋转
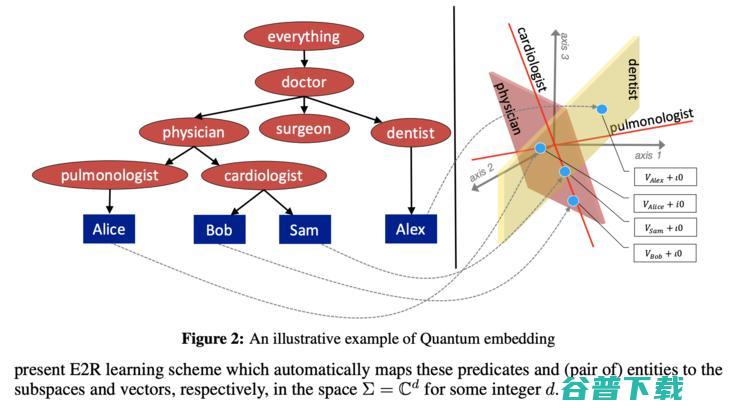
论文 6 提出了 Embed2Reason(E2R)的模型,这是一种受量子逻辑启发的量子KG嵌入方法。该方法可以嵌入类(概念)、关系和实例。
不要激动,这里面没有量子计算。量子逻辑理论(QL)最初是由伯克霍夫和冯诺依曼于1936年提出,用于描述亚原子过程。E2R的作者把它借用过来保存KG的逻辑结构。在QL中(因此也是E2R中),所有一元、二元以及复合谓词实际上都是某些复杂向量空间的子空间,因此,实体及其按某种关系的组合都落在了特定的子空间内。本来,分布定律a AND(b OR c)=(a AND b)OR(a AND c)在QL中是不起作用的。但作者用了一个巧妙的技巧绕开了这个问题。
作者在论文中还介绍了如何使用QL对来自描述逻辑(DL)的术语(例如包含、否定和量词)进行建模!实验结果非常有趣:在FB15K上,E2R产生的Hits @ 1高达96.4%(因此H@10也能达到);不过在WN18上效果不佳。事实证明,E2R会将正确的事实排在首位或排在top10以下,这就是为什么在所有实验中H @ 1等于H @ 10的原因。
补充一点,作者使用LUBM作为演绎推理的基准,该演绎推理包含了具有类及其层次结构的本体。实际上,这也是我关注的焦点之一,因为标准基准数据集FB15K(-237)和WN18(RR)仅包含实例和关系,而没有任何类归因。显然,大型知识图谱具有数千种类型,处理该信息可以潜在地改善链接预测和推理性能。我还是很高兴看到有越来越多的方法(如E2R)提倡将符号信息包含在嵌入中。
让我们继续来考察图神经网络的逻辑表达。论文 7 中对哪些GNN架构能够捕获哪个逻辑级别进行了大量的研究。目前为止,这个研究还仅限于一阶逻辑的两变量片段FOC_2,因为FOC_2连接到用于检查图同构的Weisfeiler-Lehman(WL)测试上。
作者证明,聚合组合神经网络(AC-GNN)的表达方式对应于描述逻辑ALCQ,它是FOC_2的子集。作者还进一步证明,如果我们添加一个独处成分,将GNN转换为聚合组合读出GNN(ACR-GNN),则FOC_2中的每个公式都可以由ACR-GNN分类器捕获。这个工作怎么说呢?简直是不能再棒了!
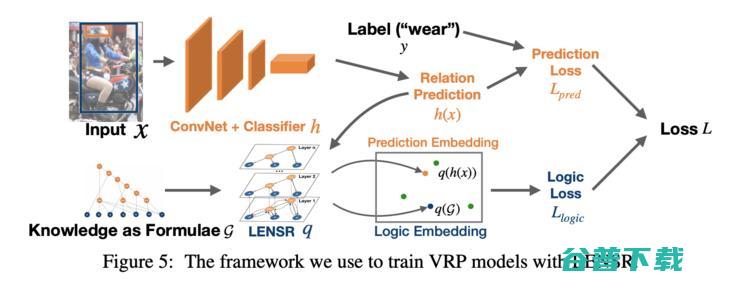
论文 8 提出了模型LENSR,这是一个具有语义正则化的逻辑嵌入网络,它可以通过图卷积网(GCN)将逻辑规则嵌入到d-DNNF(决策确定性否定范式)当中。在这篇文章中,作者专注于命题逻辑(与上述论文中更具表现力的描述逻辑相反),并且表明将AND和OR的两个正则化组件添加到损失函数就足够了,而不用嵌入此类规则。这个框架可以应用在视觉关系预测任务中,当给定一张图片,你需要去预测两个objects之间的正确关系。在这篇文章中,Top-5的准确率直接将原有84.3%的SOTA提升到92.77%。
3、马尔科夫逻辑网络卷土重来
马尔科夫逻辑网络(Markov Logic Network)的目标是把一阶逻辑规则和概率图模型结合起来。然而,直接使用马尔科夫逻辑网络不仅有拓展性问题,推理过程的计算复杂度也过高。近几年来,用神经网络改进马尔科夫逻辑网络的做法越来越多,今年我们能看到很多有潜力的网络架构,它们把符号规则和概率模型结合到了一起。
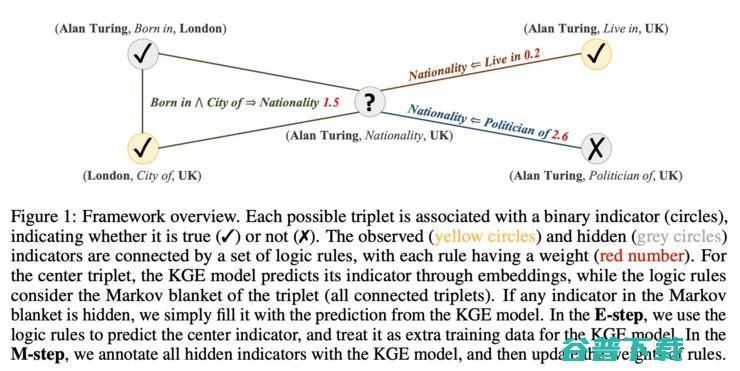
论文 9 提出了 pLogicNet,这个模型是用来做知识图推理的,而且知识图嵌入和逻辑规则相结合。模型通过变差EM算法训练(实际上,这几年用EM做训练&模型优化的论文也有增加的趋势,这事可以之后单独开一篇文章细说)。论文的重点是,用一个马尔科夫逻辑网络定义知识图中的三元组上的联合分布(当然了,这种做法要对未观察到的三元组做一些限制,因为枚举出所有实体和关系上的所有三元组是做不到的),并给逻辑规则设定一个权重;你可以再自己选择一个预训练知识图嵌入(可以选TransE或者ComplEx,实际上随便选一个都行)。在推理步骤中只能怪,模型会根据规则和知识图嵌入找到缺失的三元组,然后在学习步骤中,规则的权重会根据已见到的、已推理的三元组进行更新。pLogicNet 在标准的连接预测测试中展现出了强有力的表现。我很好奇如果你在模型里选用了 GNN 之类的很厉害的知识图嵌入会发生什么。
论文 10 介绍了一个神经马尔科夫逻辑网络的超类,它不需要显式的一阶逻辑规则,但它带有一个神经势能函数,可以在向量空间中编码固有的规则。作者还用最大最小熵方法来优化模型,这招很聪明(但是很少见到有人用)。但缺点就是拓展性不好,作者只在很小的数据集上做了实验,然后他表示后续研究要解决的一大挑战就是拓展性问题。
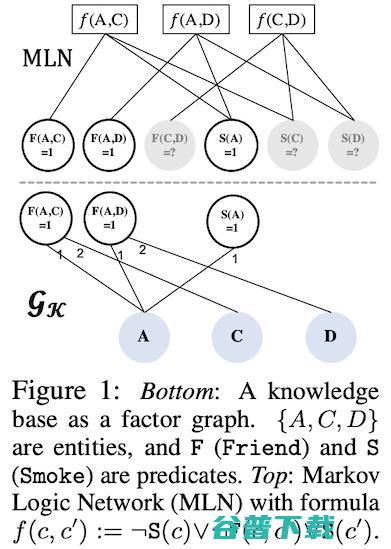
最后,论文 11 研究了GNN和马尔科夫逻辑网络在逻辑推理、概率推理方面的表现孰强孰弱。作者们的分析表明,原始的GNN嵌入就有能力编码知识图中的隐含信息,但是无法建模谓词之间的依赖关系,也就是无法处理马尔科夫逻辑网络的后向参数化。为了解决这个问题,作者们设计了ExpressGNN架构,其中有额外的几层可调节的嵌入,作用是对知识图中的实体做层次化的编码。
好了,硬核的机器学习算法讲得差不多了,下面我们看点轻松的,比如NLP应用。和NeurIPS正会一起开的workshop里有很多有趣的对话AI+图的论文。
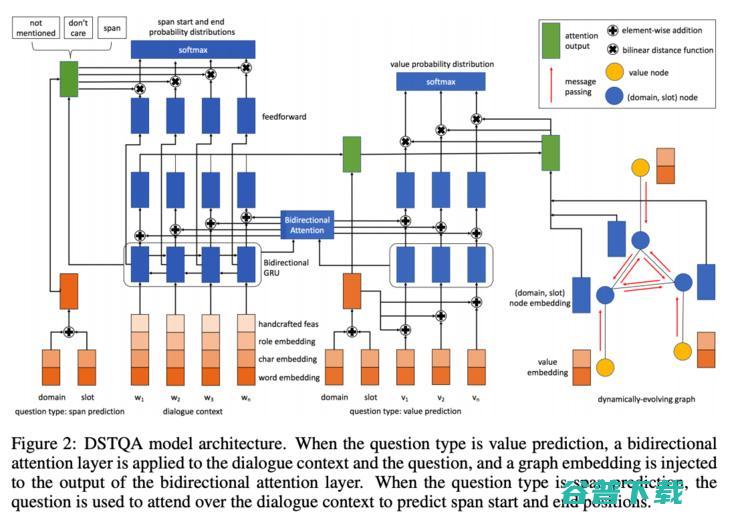
论文12:Multi-domain Dialogue State Tracking as Dynamic Knowledge Graph Enhanced Question Answering
链接:
这篇论文提出了一个通过问答追踪对话进度(Dialogue State Tracking via Question Answering (DSTQA))的模型,用来在MultiWOZ环境中实现任务导向的对话系统,更具体地,就是通过对话帮助用户完成某个任务,任务一共分为5个大类、30个模版和超过4500个值。
它基于的是问答(Question Answering )这个大的框架,系统问的每个问题都要先有一个预设模版和一组预设的值,用户通过回答问题确认或者更改模版中的预设值。有个相关的假说提出,同一段对话中的多个模版、多组值之间并不是完全独立的,比如,你刚刚订好五星级酒店的房间,然后你紧接着问附近有什么餐馆,那很有可能你想找的餐馆也是中高档的。论文中设计的整个架构流程很繁琐,我们就只讲讲他们的核心创新点吧:
DSTQA 在 MultiWOZ 2.0 和 MultiWOZ 2.0 上都刷新了最好成绩,在 WOZ 2.0 上也和当前的最好方法不相上下。根据作者们的误差分析,主要的丢分点来自于真实值的标注有一些不准确的 —— 大规模众包数据集中就是经常会发生这种情况,没什么办法,摊手
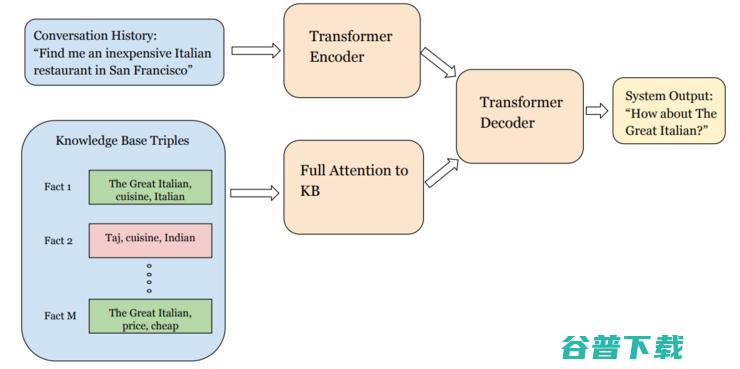
论文13 介绍了一个神经网络助理模型,这个对话系统架构不仅能考虑到对话历史,也能利用到知识库中的事实信息。系统架构可以看作是Transformer架构的拓展,它会编码对话历史中的文本;知识库中的内容是简单的单词三元组比如(餐馆A,价格,便宜)(没有 Wikidata 那种花哨的知识图模式),这些三元组也会被Transformer编码。最后,解码器会同时处理历史文本编码和知识图编码,用来生成输出语句,以及决定是否要进行下一步动作。
之前的论文中有很多人在所有的知识库三元组上计算softmax(只要知识库稍微大一点,这种做法就非常低效),这篇论文就没这么做,他们根据知识库中的实体是否在真实值回答中出现的情况做弱监督学习。他们的架构在 MultiWOZ 设置下比原本的Transformer架构得到更好的表现,预测动作以及实体出现的F1分数超过90%。不过,他们的进一步分析显示出,知识库中的条目超过一万条之后准确率就会开始快速下降。所以,嗯,如果你有心思把整个Wikidata的70亿条三元组都搬过来的话,目前还是不行的。
当你设计面向任务的系统的时候,往往有很多内容是无法长期留在内存里的,你需要把它们存在外部存储中,然后需要的时候去检索。如果是图数据,你可以用SPARQL或者Cypher建立图数据库来操作;或者用经典的SQL数据库也行。对于后一种情况,最近出现了很多新任务(),其中WikiSQL 是第一批引起了学术研究人员兴趣的。
如今,只经过了不到两年的时间,我们就已经可以说这个数据集已经基本被解决了,基于神经网络的方法也获得了超过人类的表现。这篇论文中提出了语义解析模型 SQLova ,它通过BERT编码问题和表头、用基于注意力的编码器生成SQL查询(比如 SELECT 命令、WHERE 条件、聚合函数等等) 、然后还能对生成的查询语句进行排序和评价。
作者们在论文中指出,不使用语义解析、只使用BERT的暴力编码的话,效果要差得多,所以语言模型还是不能乱用。模型的测试准确率达到了90%(顺便说一句,还有一个叫 X-SQL 的模型拿到了接近92%的准确率,),而人类的准确率只有88%;根据错误分析来看,系统表现的最大瓶颈基本就是数据标注错误了(和上面那个MulitWOZ的例子类似)。
除此之外我还有几篇NLP相关的论文想推荐给大家:
5、图神经网络的预训练和理解
在这一节,我会介绍一些从更通用的角度研究GNN的论文,包括一些研究GNN模型的可解释性的论文。
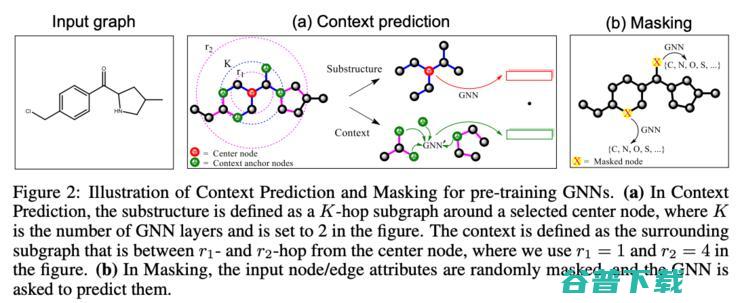
这篇论文挺火的,这是提出并解释预训练图神经网络框架的首批论文之一。我们都很熟悉预训练语言模型了,就是先在海量文本上预训练一个语言模型,然后在某个具体任务上做精细调节。从思路上来说,预训练图神经网络和预训练语言模型很像,问题重点在于这种做法在图上能不能行得通。简单的答案就是:可以!不过使用它的时候还是要小心谨慎。
对于用预训练模型在节点级别(比如节点分类)和图级别(比如图分类)捕捉结构和领域知识,作者们都在论文中提出了有价值的见解,那就是,对于在节点级别学习结构属性来说,内容预测任务的重点是在负采样的帮助下根据嵌入预测一个节点周边的节点(仿佛很像word2vec的训练对不对),其中通过掩蔽的方式,随机遮住一些节点/边的属性,然后让网络预测它们。
作者们也说明了为什么聚合-合并-读出的GNN结构(Aggregate-Combine-Readout GNN)的网络更适合这类任务,是因为它们支持用一个置换不变的池化函数获取一个图的全部表征。实验表明,只使用图级别的有监督预训练时,向下游任务迁移会造成表现下降,所以需要同时结合节点级别和图级别的表征。把特征这样组合之后能在40种不同的预测任务中带来6%到11%的ROC-AUC提升。
所以,这代表图上的迁移学习时代已经正式来到我们面前了吗?会有更多优秀的研究人员为预训练GNN模型编写优秀的库,让大家都可以更方便地使用预训练GNN吗?
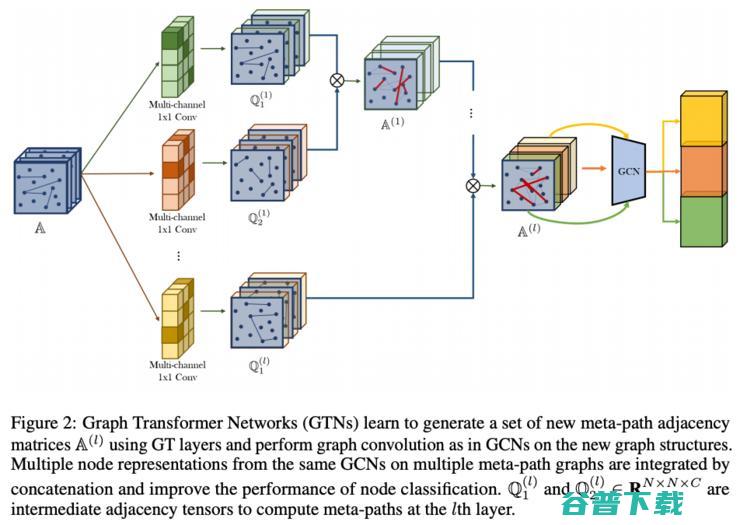
这篇论文为异质图设计了图Transformer(Graph Transformer)架构。异质图是指,图中含有多种类型的节点和边。图Transformer网络(GTN)中通过1x1卷积来获取元路径(边组成的链)的表征。接着,他们思路的关键在于,在此基础上再生成一系列任意长度的新的元路径(元-元路径?),长度可以由Transformer层的数量指定,这些元路径理论上可以为下游任务编码更多有有价值的信号。作者们的实验中,GTN凭借和图注意力网络(Graph Attention Nets)相近的参数数量刷新了节点任务分类的最好成绩。
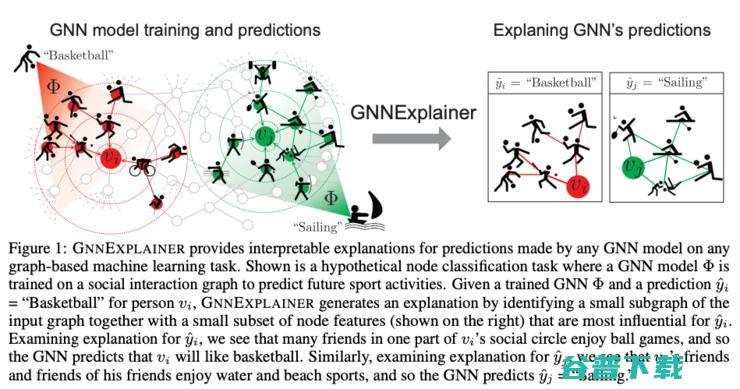
这里要介绍的最后一篇论文瞄准的是“图神经网络的可解释性”这个重要任务,论文中提出了用来解释图神经网络的输出的GNN Explainer,这是一个模型无关的框架,它能为任意任务上的、任意一个基于图的模型的预测结果做出解释。比如说,你在用图注意力网络做节点分类/图分类任务,然后你想看看你的问题的可解释的结果,那你直接用GNN Explainer就好了。
他们的设计思路是,GNN Explainer会让模型预测和结合图、节点特征形成的子图结构之间的共同信息最大化(当然了,生成子图的过程需要一些优化技巧,毕竟检测所有可能的子图是办不到的)。这个框架给出的解释的形式是,它会返回一个带有最重要的通路和特征的子图,这就很容易被人类解读了。论文里有一些很清晰的示例图(如下方)。很棒的论文,鼓掌!
在图上做机器学习是完全可行的!而且不管是CV、NLP、强化学习都能做。按照NeurIPS这样的规模,我们可以期待看到更多有趣的评审意见和给人启发的见解。顺便,我觉得有不少NeurIPS的workshop论文都可以在明年的ICLR2020再次看到。
via,雷锋网 AI 科技评论编译
版权文章,未经授权禁止转载。详情见 转载须知 。



百度营销,企业网络营销首选平台,为企业提供搜索广告、信息流广告、品牌广告等多种广告营销服务,获客热线:400-800-8888。

深圳1号鲜花凭鲜花运营经验打造花卉平台。主营鲜花预定送花批发、花艺布置、鲜花、礼篮、生日、婚庆宴会用花、开业舞狮、开业策划、汽球派对等产品,花艺师培训和办公室绿植租赁出租等,买花订花送上门就选1号鲜花同城送。

东莞市盈科新材料科技有限公司,成立于2007年,座落于东莞市寮步镇。毗邻深圳、香港,交通便利,是一家从事橡胶制品、硅胶制品、防静电硅胶产品开发和生产于一体的专业厂商。

重庆市大普动力设备有限公司是国内内燃机生产商广西玉柴机器股份有限公司授权重庆总代理。

长沙和储新材料科技有限公司

深圳市北汉科技有限公司,专业提供频谱功率分析仪,功率计,CAN卡,交直流电源等服务.其中数字万用表,示波器,直流电子负载在业内享有较高声誉,且赢得了客户的一致好评,欢迎来电咨询!

深圳市华显光学仪器有限公司以显微技术,为您提供光学解决方案公司是集设计、研发、产销、服务于一体的综合性公司.旗下产品有荧光倒置显微镜_高清视频显微镜_检测干涉显微镜_测量工具显微镜_金相显微镜_显微镜企业专注于光学领域和视觉图象的完美结合,与用户一起,引领光学走向未来.选购荧光倒置显微镜,高清视频显微镜,检测干涉显微镜认准华显光学

游戏策略实验室,为玩家提供独特的游戏攻略和创新战术。

本站为诡秘之主,宿命之环的官方站点,《诡秘之主》、《宿命之环》是爱潜水的乌贼在起点中文网连载的知名小说。本站提供诡秘之主系列IP的基本介绍、研究手册、活动资讯、卷毛狒狒研究会等资讯

好房通|房产中介系统行业标准引领者。好房通ERP——是国内先进的房产中介管理系统,集销售管理与OA办公于一体,是房产中介管理与营销不可或缺的办公系统房管软件,好房通房产中介管理软件让中介高效开展工作,大幅度提高收益

欢迎来到ACGN社区,这里收录最新最热门的二次元动漫资源论坛网站,开启你的二次元之门。你可以阅读,分享,讨论有关二次元的一切,在这里,你不是一个人,而是和大家一起遨游在二次元里的世界!

深圳市创伟达自动化设备有限公司是一家集研发、设计、制作、安装、服务为一体的涂装设备大型多元化企业,主营自动喷涂设备、自动喷漆设备、汽车零部件喷涂设备、汽车内饰件喷涂设备、五金静电喷涂设备、电泳涂装设备、无尘送风设备、环保废气处理设备、无尘车间、净化车间、流水线等。


丁磊和陈磊华一起开发了,分布式免费邮件系统,从手写书信到电子邮件,也就是这几十年间的一个悄然转变,但是,要提起中国电子邮箱的发展,就不得不提中国的第一家免费电子邮局和丁磊,借来10万美元却买不来一套软件1995年5月,意识到信息时代即将到来的丁磊,辞去老家宁波电信局的,铁饭碗,南下广州,打工两年后,他用自己多年写软件攒下的积蓄以及向...。

4月19日消息,国家图书馆互联网信息战略保存项目在北京启动,首家互联网信息战略保存基地落户新浪,新浪网发布的新闻和微博上公开发布的博文,都将被互联网信息战略保存基地保存,截至2018年12月,新浪网累计发布新闻超过2.1亿条、图片13亿张、视频4500万个、互动总量超过80亿,微博全站发布博文超过2000亿条、图片500亿张、视频4亿...。

深圳市铁汉人居环境科技有限公司于2015年加入深圳互联网学会,是学会的优先届会员单位,作为一家生态科技型企业,铁汉人居一直专注于人居微环境的改造和治理,将绿色生态和智能科技创立相结合,融入到室内生态的整体解决方案中,成功研发出am,10智能微森林自然生态净化器等系列产品,...。

10月16日消息,记者从云栖大会组委会获悉,2023杭州·云栖大会将于10月31日至11月2日在杭州云栖小镇举办,今年云栖大会以,计算,为了无法计算的价值,为主题,设有两场重磅主论坛,500余个热点话题,同时,大会现场将布设40000平米科技展,涵盖算力、人工智能,、产业创新三大主题,即日起,观众可在云栖大会官网免费预约参会门票,云栖...。

近日,第六届全球人工智能与机器人大会,GAIR2021,在深圳正式启幕,140余位产学领袖、30位Fellow聚首,从AI技术、产品、行业、人文、组织等维度切入,以理性分析与感性洞察为轴,共同攀登人工智能与数字化的浪潮之巅,在医疗科技高峰论坛上,AIMBEFellow、深圳理工大学计算机科学与控制工程院院长潘毅以,人工智能在生物医疗学...。

要说时下互联网圈内最受关注的方向是什么,相信智能硬件和O2O一定会挤进前三之列,但很少有人能把这两者结合到一起去,即便是国内顶尖的互联网公司和硬件制造商们,正是因为这种行业基调,因此笔者才会对最近一则消息感到非常好奇——近日,业界知名的智能移动周边设备品牌品胜,推出了旗下新品无线•中继宝的免费试用计划,并同步推行当日送达及免费上门安装...。

2018年夏天,小米通过上市聆讯两周后,在北京回龙观一家粥店包厢内,小米的第6至15号员工实现了一次久违的重聚,他们端起一碗小米粥,面带笑容,在斑驳的灯火中合影留念,但天下没有不散的筵席,转眼之间,那场对他们来说意味着财务自由的小米上市,已经过去了将近四年,这十名喝过,小米粥,的早期员工,也各有去路——有的已经离开小米,事实上,除了被...。

发表在坚果投影仪2019,9,1617,35坚果投影仪如何使用3D眼镜,现在坚果投影仪部分型号也开始支持3D模式,但是有很多网友都不太会使用,今天我来为大家详细分享一下坚果投影仪如何使用3D眼镜,1、坚果快门式3D眼镜使用方法,充完电后,按压一下电源开关,蓝色LED指示灯闪烁一次代表电源已开启,再次按压一下切换左右眼;2、坚果主动快门...。

发表在天猫魔屏2019,11,514,33选购投影仪最需要看的是什么,是亮度,分辨率,系统配置,不,都不是,需要看投影网,这篇文章给网友们分享一下最近比较热议的天猫魔屏S1与天猫魔屏S2,天猫魔屏S2作为天猫魔屏迭代产品目前售价比上一代S1高出六百元,网友们就有疑问在参数上有哪些方面的提升,带着这个问题我们去分析分析它们的参数,先了解...。

虎和兔相配婚姻很好,属虎人跟属兔人还是很相配的,属相虎的人和属相兔的人在一同,刚开局的情侣相关是十分甘美恩爱的,但是相处久了之后,彼此还是容易出现一些疑问,一开局的时刻一个温顺浪漫,一个王道强势都很入得了对方的眼,但是在短暂的相处中,属虎之人会明确属兔之人虽然看上去温顺灵巧,却并不是容易被压抑的人,而属兔之人兴许也会对对方的掌控欲多有...。

海马汽车s5智能挡的售价在6.98万至8.98万之间,海马汽车s5智能挡是一款外观时兴动感的车型,它驳回了流线型车身设计,侧面改换单横幅镀铬格栅,中央嵌入大尺寸品牌标记,更具时兴感,大灯组驳回分体式设计,日间行车灯形状长,底部大灯配一个透镜,车身的彩色侧围有圆形的雾灯,底部有一个银色的盾形装璜件,为车辆削减静止感,此外,海马S5的配色...。

KeystrokeVisualizer可以通过不断向观众展示您当前按下的按键来帮助您提升游戏体验,您还可以向他们展示他们也可以使用的快捷方式或热键。
一些玩家非常爱玩合成类的手游,在游戏中可以将很多东西合成在一起,这种游戏玩起来休闲又解压,那么受欢迎的几个合成一个的游戏叫什么?合成游戏玩起来超级容易上手,小白玩家也能在几分钟之内学会怎么玩合成游戏,快来下载下文这些合成游戏吧,1、,球球英雄,球球英雄是款可以合成球球的小游戏,这款游戏有着塔防类的玩法,玩家要控制自己的球球部队抵御敌人...。

所谓的餐饮加盟,就是该企业组织,或者说餐饮加盟连锁总公司与餐饮加盟店二者之间的持续契约的关系,根据契约,总公司必须提供一项独特的商业特权,并加上人员培训、组织结构、经营管理及商品供销的协助;而餐饮加盟店也需付出相对的报偿;它是一种经济而简便的经商之道,经由一种商品或服务以及行销方法,以小的危险和大的机会获得成功,...。
如果科学家们能够了解电子在分子中的活动,那么他们就能够预测一切事物的行为,包括实验药物与高温超导体,最近,权威学术媒介QuantaMagazine发表了一篇文章,介绍了DeepMind在内的许多研究团队正使用机器学习算法攻破物理领域的一个著名难题——密度泛函理论,他们企图通过机器学习算法来寻找第三级密度泛函的方程式,找出人类无法用数学...。

发表在综合交流大区2022,4,2614,55无意间在某平台看到售价只要五百的志高投影仪销量还不错,不禁对这款志高投影仪产生兴趣,之前也关注过志高投影仪这几年也是在不断更新的状态,一些想要购买百元的用户都想了解这款志高投影仪到底能不能购入,今天我们就找一款抖音销量做高的志高投影仪看看他的参数,研究志高投影仪值不值得买,志高投影仪好用吗...。

连锁酒店在城市中常能见到,连锁酒店以具有统一的服务、硬件配备与收费,许多在酒店入住过的消费者留下深刻的印象,而该类酒店也逐渐声名大噪,既然项目优势如此鲜明,那么创业者适时开家店运作显得再好不过,在此,文章将对天津连锁酒店加盟条件作出说明,给想开店的创业者提供必要的创业主张,天津连锁酒店加盟条件吉泰连锁酒店自问世以来,始终保持着与时俱进...。
