在近段时间又有哪些研究进展 掀起热潮的Wasserstein GAN (近段时间又出现了阳)
前段时间,Wasserstein GAN以其精巧的理论分析、简单至极的算法实现、出色的实验效果,在GAN研究圈内掀起了一阵热潮(对WGAN不熟悉的读者,可以参考我之前写的介绍文章: 令人拍案叫绝的Wasserstein GAN - 知乎专栏 )。但是很多人(包括我们实验室的同学)到了上手跑实验的时候,却发现WGAN实际上没那么完美,反而存在着训练困难、收敛速度慢等问题。其实, WGAN的作者Martin Arjovsky不久后就在reddit上表示他也意识到了这个问题 ,认为关键在于原设计中Lipschitz限制的施加方式不对,并在新论文中提出了相应的改进方案:
论文: Improved Training of Wasserstein GANs Tensorflow实现: igul222/improved_wgan_training
首先回顾一下WGAN的关键部分——Lipschitz限制是什么。 WGAN中,判别器D和生成器G的loss函数分别是:

 (公式2)
(公式2)
公式1表示判别器希望尽可能拉高真样本的分数,拉低假样本的分数,公式2表示生成器希望尽可能拉高假样本的分数。
Lipschitz限制则体现为,在整个样本空间
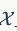 上,要求判别器函数
上,要求判别器函数
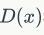 梯度的Lp-norm不大于一个有限的常数
梯度的Lp-norm不大于一个有限的常数
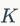 :
:
 (公式3)
(公式3)
直观上解释,就是当输入的样本稍微变化后,判别器给出的分数不能发生太过剧烈的变化。在原来的论文中,这个限制具体是通过weight clipping的方式实现的:每当更新完一次判别器的参数之后,就检查判别器的所有参数的绝对值有没有超过一个阈值,比如0.01,有的话就把这些参数clip回 [-0.01, 0.01] 范围内。通过在训练过程中保证判别器的所有参数有界,就保证了判别器不能对两个略微不同的样本给出天差地别的分数值,从而间接实现了Lipschitz限制。
然而weight clipping的实现方式存在两个严重问题:
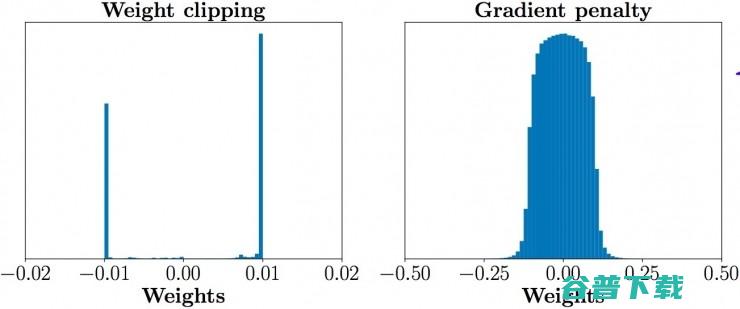
第一,如公式1所言,判别器loss希望尽可能拉大真假样本的分数差,然而weight clipping独立地限制每一个网络参数的取值范围,在这种情况下我们可以想象,最优的策略就是尽可能让所有参数走极端,要么取最大值(如0.001)要么取最小值(如-0.001)!为了验证这一点,作者统计了经过充分训练的判别器中所有网络参数的数值分布,发现真的集中在最大和最小两个极端上:

这样带来的结果就是,判别器会非常倾向于学习一个简单的映射函数(想想看,几乎所有参数都是正负0.01,都已经可以直接视为一个 二值化神经网络 了,太简单了)。而作为一个深层神经网络来说,这实在是对自身强大拟合能力的巨大浪费!判别器没能充分利用自身的模型能力,经过它回传给生成器的梯度也会跟着变差。
在正式介绍gradient penalty之前,我们可以先看看在它的指导下,同样充分训练判别器之后,参数的数值分布就合理得多了,判别器也能够充分利用自身模型的拟合能力:
第二个问题,weight clipping会导致很容易一不小心就梯度消失或者梯度爆炸。原因是判别器是一个多层网络,如果我们把clipping threshold设得稍微小了一点,每经过一层网络,梯度就变小一点点,多层之后就会指数衰减;反之,如果设得稍微大了一点,每经过一层网络,梯度变大一点点,多层之后就会指数爆炸。只有设得不大不小,才能让生成器获得恰到好处的回传梯度,然而在实际应用中这个平衡区域可能很狭窄,就会给调参工作带来麻烦。相比之下,gradient penalty就可以让梯度在后向传播的过程中保持平稳。论文通过下图体现了这一点,其中横轴代表判别器从低到高第几层,纵轴代表梯度回传到这一层之后的尺度大小(注意纵轴是对数刻度),c是clipping threshold:
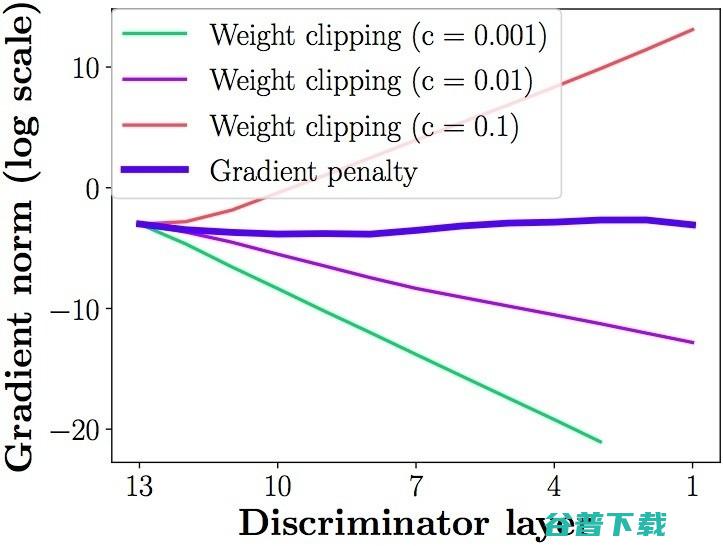
说了这么多,gradient penalty到底是什么?
前面提到,Lipschitz限制是要求判别器的梯度不超过K,那我们何不直接设置一个额外的loss项来体现这一点呢?比如说:
 (公式4)
(公式4)
不过,既然判别器希望尽可能拉大真假样本的分数差距,那自然是希望梯度越大越好,变化幅度越大越好,所以判别器在充分训练之后,其梯度norm其实就会是在K附近。知道了这一点,我们可以把上面的loss改成要求梯度norm离K越近越好,效果是类似的:
 (公式5)
(公式5)
究竟是公式4好还是公式5好,我看不出来,可能需要实验验证,反正论文作者选的是公式5。接着我们简单地把K定为1,再跟WGAN原来的判别器loss加权合并,就得到新的判别器loss:
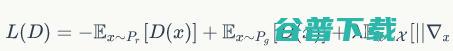 (公式6)
(公式6)
这就是所谓的gradient penalty了吗?还没完。公式6有两个问题,首先是loss函数中存在梯度项,那么优化这个loss岂不是要算梯度的梯度?一些读者可能对此存在疑惑,不过这属于实现上的问题,放到后面说。
其次,3个loss项都是期望的形式,落到实现上肯定得变成采样的形式。前面两个期望的采样我们都熟悉,第一个期望是从真样本集里面采,第二个期望是从生成器的噪声输入分布采样后,再由生成器映射到样本空间。可是第三个分布要求我们在整个样本空间
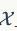 上采样,这完全不科学!由于所谓的维度灾难问题,如果要通过采样的方式在图片或自然语言这样的高维样本空间中估计期望值,所需样本量是指数级的,实际上没法做到。
上采样,这完全不科学!由于所谓的维度灾难问题,如果要通过采样的方式在图片或自然语言这样的高维样本空间中估计期望值,所需样本量是指数级的,实际上没法做到。
所以,论文作者就非常机智地提出,我们其实没必要在整个样本空间上施加Lipschitz限制,只要重点抓住生成样本集中区域、真实样本集中区域以及夹在它们中间的区域就行了。具体来说,我们先随机采一对真假样本,还有一个0-1的随机数:
 (公式7)
(公式7)
然后在
 和
和
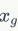 的连线上随机插值采样:
的连线上随机插值采样:
 (公式8)
(公式8)
把按照上述流程采样得到的
 所满足的分布记为
所满足的分布记为
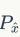 ,就得到最终版本的判别器loss:
,就得到最终版本的判别器loss:
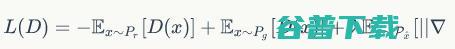 (公式9)
(公式9)
这就是新论文所采用的gradient penalty方法,相应的新WGAN模型简称为WGAN-GP。 我们可以做一个对比:
论文还讲了一些使用gradient penalty时需要注意的配套事项,这里只提一点:由于我们是对每个样本独立地施加梯度惩罚,所以判别器的模型架构中不能使用Batch Normalization,因为它会引入同个batch中不同样本的相互依赖关系。如果需要的话,可以选择其他normalization方法,如layer normalization、 weight normalization和instance normalization,这些方法就不会引入样本之间的依赖。论文推荐的是layer normalization。
实验表明,gradient penalty能够显著提高训练速度,解决了原始WGAN收敛缓慢的问题:
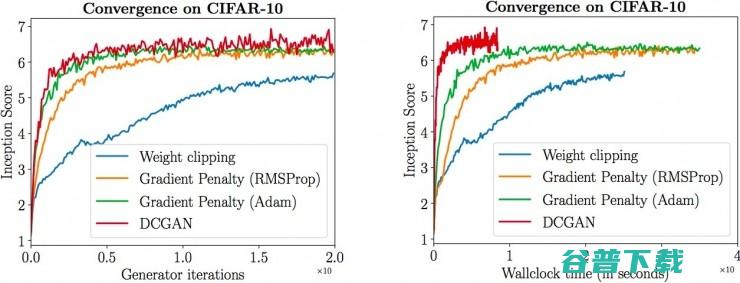
虽然还是比不过DCGAN,但是因为WGAN不存在平衡判别器与生成器的问题,所以会比DCGAN更稳定,还是很有优势的。不过,作者凭什么能这么说?因为下面的实验体现出,在各种不同的网络架构下,其他GAN变种能不能训练好是有点看运气的事情,但是WGAN-GP全都能够训练好,尤其是最下面一行所对应的101层残差神经网络:

剩下的实验结果中,比较厉害的是第一次成功做到了“纯粹的”的文本GAN训练! 我们知道在图像上训练GAN是不需要额外的有监督信息的,但是之前就没有人能够像训练图像GAN一样训练好一个文本GAN,要么依赖于预训练一个语言模型,要么就是利用已有的有监督ground truth提供指导信息。而现在WGAN-GP终于在无需任何有监督信息的情况下,生成出下图所示的英文字符序列:

它是怎么做到的呢?我认为关键之处是对样本形式的更改。 以前我们一般会把文本这样的离散序列样本表示为sequence of index,但是它把文本表示成sequence of probability vector。 对于生成样本来说,我们可以取网络softmax层输出的词典概率分布向量,作为序列中每一个位置的内容;而对于真实样本来说,每个probability vector实际上就蜕化为我们熟悉的onehot vector。
但是如果按照传统GAN的思路来分析,这不是作死吗?一边是hard onehot vector,另一边是soft probability vector,判别器一下子就能够区分它们,生成器还怎么学习?没关系,对于WGAN来说,真假样本好不好区分并不是问题,WGAN只是拉近两个分布之间的Wasserstein距离,就算是一边是hard onehot另一边是soft probability也可以拉近,在训练过程中,概率向量中的有些项可能会慢慢变成0.8、0.9到接近1,整个向量也会接近onehot,最后我们要真正输出sequence of index形式的样本时,只需要对这些概率向量取argmax得到最大概率的index就行了。
新的样本表示形式+WGAN的分布拉近能力是一个“黄金组合”,但除此之外,还有其他因素帮助论文作者跑出上图的效果,包括:
上面第三点非常有趣,因为它让我联想到前段时间挺火的语言学科幻电影《降临》:

里面的外星人“七肢怪”所使用的语言跟人类不同,人类使用的是线性的、串行的语言,而“七肢怪”使用的是非线性的、并行的语言。“七肢怪”在跟主角交流的时候,都是一次性同时给出所有的语义单元的,所以说它们其实是一些多层反卷积网络进化出来的人工智能生命吗?

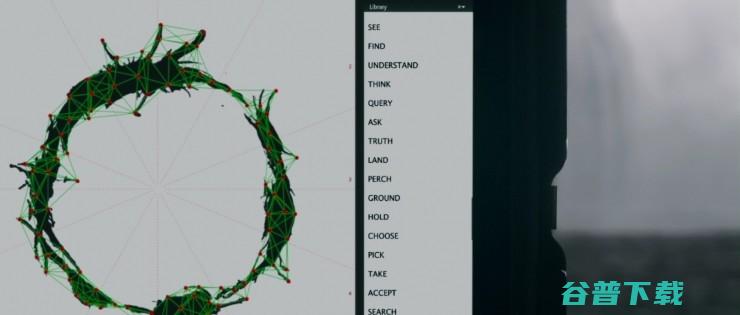
开完脑洞,我们回过头看,不得不承认这个实验的setup实在过于简化了,能否扩展到更加实际的复杂场景,也会是一个问题。但是不管怎样,生成出来的结果仍然是突破性的。
最后说回gradient penalty的实现问题。 loss中本身包含梯度,优化loss就需要求梯度的梯度,这个功能并不是现在所有深度学习框架的标配功能,不过好在Tensorflow就有提供这个接口——tf.gradients。开头链接的GitHub源码中就是这么写的:
#interpolates就是随机插值采样得到的图像gradients=tf.gradients(Discriminator(interpolates),[interpolates])[0]
对于我这样的PyTorch党就非常不幸了,高阶梯度的功能还在开发,感兴趣的PyTorch党可以订阅这个GitHub的pull request: Autograd refactor ,如果它被merged了话就可以在最新版中使用高阶梯度的功能实现gradient penalty了。
但是除了等待我们就没有别的办法了吗?其实可能是有的,我想到了一种近似方法来实现gradient penalty,只需要把微分换成差分:
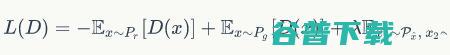 (公式10)
(公式10)
也就是说,我们仍然是在分布
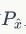 上随机采样,但是一次采两个,然后要求它们的连线斜率要接近1,这样理论上也可以起到跟公式9一样的效果,我自己在MNIST+MLP上简单验证过有作用,PyTorch党甚至Tensorflow党都可以尝试用一下。
上随机采样,但是一次采两个,然后要求它们的连线斜率要接近1,这样理论上也可以起到跟公式9一样的效果,我自己在MNIST+MLP上简单验证过有作用,PyTorch党甚至Tensorflow党都可以尝试用一下。
版权文章,未经授权禁止转载。详情见 转载须知 。



-招聘-人力资源网址

艾科迅(ACX)专业真空钎焊炉厂家,PCD、CBN、PCBN、CVD、PDC、陶瓷等硬质合金刀具真空钎焊炉。金刚石砂轮、金刚石滚轮、金刚石磨轮、金刚石磨头、金刚石铣刀、金刚石锯片等金刚石工具真空钎焊炉。服务于上海、广东、福建、江苏、浙江、河南、北京、河北、西安、山西、四川等地区的真空钎焊炉。

联系电话:0917-3370620宝鸡市锦盛达钛业有限公司位于中国钛谷—陕西宝鸡。依托“中国钛谷”的强大综合实力进行高效的资源共享。具备得天独厚的地域、材料、科研优势,为用户提供优质的产品。公司主营钛及钛合金棒、钛方棒及钛扁方、钛管等有色金属材料钛材。是一家集生产、加工、销售为一体的综合性企业。

青岛三木机械设备有限公司生产裁板锯,为您提供裁板锯价格,裁板锯参数等信息,精密裁板锯、砂光机、木工排钻以及相关辅助设备等木工机械已有二十余年生产经验,是一家专业木工机械生产厂家

上海云盾信息技术有限公司(YUNDUN),是专注于提供新一代安全产品和服务的创新创业企业。以纵深安全加速,护航数字业务的产品服务理念,替身和隐身的攻防思想,运用大数据、AI、零信任技术架构和健壮的全球网络资源,一站式解决数字业务的应用漏洞、黑客渗透、爬虫Bot、DDoS等安全威胁,满足合规要求,提高用户体验。

广东江门鹤山市顺鹤金属制品有限公司-拉伸盆系列-手工盆系列-配件系列本公司采用国际先进的专业数控设备和生产线进行生产高端不锈钢水槽。拥有一批高端技术设计团队和经验丰富的管理团队,秉承质量至上、以客户为中心的设计理念,不断研发新产品,不断追求工艺技术的完美。现已拥有众多设计时尚、美观实用、做工精细的高端不锈钢水槽,畅销海内外。产品迅速赢得了众多消费者的追随和青睐。

深圳市鼎音网络科技有限公司是国内知名的全渠道私域营销平台,为国内企业提供精准获客,全渠道营销,电商赋能,营销自动化,门店赋能,数字终端营销赋能等营销手段,帮助企业扩大获客渠道、降本增效,让私域数字化营销助力于每一家企业!

Pt100温度传感器PT1000热电阻,PT100铂电阻PT1000,K型热电偶T,NTC热敏电阻,温度开关,压力变送器,压力传感器,温控器,温度显示器,Pt1000温度探头PT100.工业热电阻,工业温度传感器PT1000,医用温度传感器,高温K型热电偶,红外温度传感器Pt100,T型热电偶,食品药品用温度传感器PT1000,贴片式温度传感器,导线式温度传感器PT100,压力开关,无纸记录仪。烟雾报警器,温湿度传感器。智能数显温度报警器温压一体化传感器就地显示温度仪多路输出型温度传感器圆模块智能温度变送器高精度智能温度变送器导轨型温度变送器多路输出型热电阻超小型热电阻变径式热电阻小型一体化热电阻液位传感器数显防爆压力变送器差压变送器卫生型压力变送器航插式压力变送器扩散硅压力变送器通用型压力传感器快插接头型热电偶表面安装型热电偶贴片式热电偶螺钉式热电偶工业炉热电偶R型热电偶B型热电偶S型热电偶铠装热电偶T型热电偶抗震热电偶K型热电偶高温热电偶工业通用热电偶风管水管型温度传感器各类插接头型热电阻防腐型温度传感器耐酸碱温度探头防腐热电阻赫斯曼接头型温度变送器管道表面测温探头卡箍型热电阻智能数显温度报警器温压一体化传感器就地显示温度仪多路输出型温度传感器圆模块智能温度变送器高精度智能温度变送器导轨型温度变送器多路输出型热电阻超小型热电阻变径式热电阻小型一体化热电阻液位传感器数显防爆压力变送器差压变送器卫生型压力变送器航插式压力变送器扩散硅压力变送器通用型压力传感器快插接头型热电偶表面安装型热电偶贴片式热电偶螺钉式热电偶工业炉热电偶R型热电偶B型热电偶S型热电偶铠装热电偶T型热电偶抗震热电偶K型热电偶高温热电偶工业通用热电偶风管水管型温度传感器各类插接头型热电阻防腐型温度传感器耐酸碱温度探头防腐热电阻赫斯曼接头型温度变送器管道表面测温探头卡箍型热电阻智能数显温度报警器温压一体化传感器就地显示温度仪多路输出型温度传感器圆模块智能温度变送器高精度智能温度变送器导轨型温度变送器多路输出型热电阻超小型热电阻变径式热电阻小型一体化热电阻液位传感器数显防爆压力变送器差压变送器卫生型压力变送器航插式压力变送器扩散硅压力变送器通用型压力传感器快插接头型热电偶表面安装型热电偶贴片式热电偶螺钉式热电偶工业炉热电偶R型热电偶B型热电偶S型热电偶铠装热电偶T型热电偶抗震热电偶K型热电偶高温热电偶工业通用热电偶风管水管型温度传感器各类插接头型热电阻防腐型温度传感器耐酸碱温度探头防腐热电阻赫斯曼接头型温度变送器管道表面测温探头卡箍型热电阻

必要商城是国内首家C2M(CustomerTOManufactory)模式电子商务平台,消费者直连制造商购物,享受大牌品质,工厂价格。2024年加入一线品牌商品,大牌特卖,买贵退差,为您提供高性价比的商品和服务。

南京传媒学院国际班既南京传媒大学国际部开设南京传媒学院国际本科2+2留学项目、南京传媒学院韩国留学班、南京传媒学院日本留学班,面向全国招收高中同等学历毕业生,高二结业生,南广学院国际班最终所获学历回国承认

湖南法律顾问律师网-先办案,后收费;不成功,不收费!

宇信达汇率换算网为您提供最新、最准确的货币汇率查询服务。我们24小时不间断更新,让您随时掌握市场脉搏,轻松进行汇率换算和追踪。无论是个人旅行还是企业金融决策,全球实时汇率网都是...


要闻提示1.曝苹果将对字节腾讯,下狠手,不堵上支付漏洞,就拒绝微信抖音更新上架2.字节跳动新加坡中毒员工菜单曝光,疑似来自新加坡云海肴和莆田两家供应商,涉事餐厅暂停营业3.小红书11周年信承认大公司病,官架子大、决策拖沓,需重新出发4.李国庆回忆当当大战亚马逊,他们本志在必得、却灰溜溜退出中国5.董明珠,格力已研发出美容仪,用一个星...。

一次疫情,原本深藏幕后的AI成果被搬至台前;一次公开课,科技成果背后的舵手来到大众视野,2020年伊始,AI掘金志就为大家呈上了一系列公开课,让更多的行业专家、企业高管得以分享、传播自己的研究成果;也让AI从业者们、高校师生们增进了对人工智能相关思维、知识、应用的认识,依托AI掘金志此前在安防等细分领域的持续深耕,我们先后邀请到了包括...。
图为纳米机器人示意图来自以色列拉马特甘巴伊兰大学和以色列赫兹利亚跨学科中心的研究者们利用DNA折叠的结构制造出空腔壳结构的纳米机器人,有了这种纳米机器人,医生便可以在一段时间内控制药物的释放,一次只释放小剂量的药物,他们声称,这种技术可以应用在治疗大脑疾病,比如精神分裂、抑郁症,以及注意力缺乏症,药物首先经过化学处理,使用氧化铁颗粒将...。

autosleep怎样导出睡眠活动记录,autosleep如果要更换新设备,用户可以将之前的睡眠相关数据导出全部,那么具体应该怎么操作呢,还不清楚的用户就一起来看看吧!...。

11月11日24点,2024年天猫双11收官,成交总额强劲增长,购买用户规模创新高,天猫始终是品牌成交爆发主阵地,天猫双11全周期589个品牌成交额破亿,同比去年增长46.5%,刷新历史纪录,其中苹果、海尔、美的、小米、耐克、五粮液等45个品牌成交额突破10亿,潮玩品牌米哈游、美妆品牌汤姆福特、可丽金、CT,比利时鱼油品牌WHC等首次...。

吃面,是很打一部分的传统习惯,但是祖国大地幅员辽阔,这也导致了面的口味差别很大,南方人比较喜欢甜口味,就是吃面,口味也偏甜,这一特色造就了东吴面馆品牌,东吴面馆,主打正宗地道的地方面食,很是吸引了大批消费者的眼光,也引起了创业者的兴趣,下面我们将会就东吴面馆怎么加盟话题回应一番,关于东吴面馆的品牌介绍东吴面馆是苏州东吴餐饮管理有限公司...。

来首先,须要预备以下硬件,1.服务器板,选用适宜自己需求的服务器板,包含品牌、芯片组、接口等,2.解决器,依据自己的经常使用需求选用适宜的解决器,包含品牌、型号、外围数等,3.内存,选用容量、频率和时序适宜自己解决器和服务器板的内存条,4.硬盘,选用不同类型,机械硬盘、固态硬盘,和容量的硬盘,5.显卡,假设须要启动游戏或图像解决等须要...。

据新华社德黑兰7月6日电伊朗选举委员会发言人穆赫辛·伊斯拉米6日清晨发表,伊朗第14届总统选举第二轮投票于5日午夜完结,计票上班随即开局,伊朗总统选举第二轮投票于外地期间5日8时开局,在第一轮投票中得票率排在前两名的前卫生部长佩泽什基安和前首席核谈判代表贾利利角逐总统职位,第二轮投票原定今日18时完结,为繁难更多选民投票,投票期间3次...。

撰文丨余晖7月4日,中央纪委国度监委官方刊发了,贵州省纪委监委课题组,撰写的文章,旗号显明讲政治不折不扣抓落实,文中点名提到了多个落马官员,其中,向红琼是2022年3月被查的,向红琼出世于1958年11月,她曾任职贵州农学院植保系,2000年7月任贵州大学农学院植保系副主任,1999年12月,向红琼被评为副传授,2000年12月被评...。

美团怎么设置小额免密支付?这是我们经常会遇到的问题。如何解决这个问题呢?接着往下看小编为您带来的教程吧。方法/步骤分享:1、打开美团客户端,点击下方

网易云音乐,网易云音乐作为起步晚、增长快的一款优质音乐播放器,是专注发现与分享的音乐播放器产品,网易云音乐电脑版尤其是创新的音乐社交俘获了众多音乐爱好者的心,是用户口碑、评价甚高的优质音乐应用,您可以免费下载。

欢迎来到pc6,我们有pc6下载站为您提供最新最热门及全面的qq技巧和qq使用方法、qq最新动态、常见问题解决方法等资讯教程。

第一种就是生活中,附近的人,记得有一位女孩子是卖水果的,她仅仅通过,附近的人,就做到一个月赚1万元的收入,她是怎么做的呢?在她家附近有好几个比较大型的小区,于是,她打印了很多二维码广告,贴在小区门口或塞在小区业主门缝里,二维码下面有一句话,微信扫一扫,加好友,买水果送货上门,再送苹果一个,看到的人很好奇,又心想,反正就是关注一下而已...。

在特斯拉的联合创始人兼CEOElonMusk放出人工智能恶魔论之后,今天又开始放话了,在未来,人类开车的,权力,被剥夺,而机器人将会取代人类,控制驾驶汽车,因为机器人比人类更加胜任驾驶工作,从统计学的角度来说,人类驾驶只会成为道路安全的不利因素,将来,特斯拉可是要做无人驾驶,也难怪这么说话~,在年度开发者大会上,Musk对NVIDI...。

4月18日,,腾讯文档,打开想象,2024产品发布会在线上举办,腾讯社交协作产品部总经理、腾讯文档负责人鄢贤卿在会上,正式发布智能白板创新品类、双核编辑,开物引擎,、云加端解决方案等产品矩阵,他表示,在自研文档品类和自研双核引擎的基座下,腾讯文档也全面搭载了AI助手,致力于打造专业、智能的Office产品体验,提升用户和企业生产力,同...。

这种行为严重扰乱公共秩序,地铁内有一名女乘客在地上爬行等异常行为,一男一女尾随拍摄,地铁公司发现后,立即安排工作人员登车处置,涉事乘客反映是在表演艺术,运营人员进行了劝阻,并向地铁公安举报,随后,涉事的3名乘客从东野生动物园站C出口出站,在此期间,乘客安全没有受到影响,公安部门对当事人进行了教育,其次是不能维护公共秩序的乘客有权拒绝乘...。

提到月收入这个敏感词,80%的伙伴都对自己不满意,每天夜里做梦都在祈祷老板涨点工资,减少加班时间,天,哪有那么好的事情,说实话,现在连国企也不好混了,何况私营企业呢,资本市场水也深,企业都是想办法节约成本,真正拿高薪的是那些付出了辛苦,耗费心血,拿下业绩的人,普通职员想达到那个程度,只有打怪升级练上去,学会职场,巴结,为人处事,而且这...。
