模型权重 推理代码全开放 腾讯版Sora发布即开源!130亿参数 (模型权重推理怎么做)
梦晨 西风 发自 凹非寺
量子位 | 公众号 QbitAI
腾讯版Sora,发布即开源!
,成为目前参数量最大的开源视频生成模型。
模型权重、推理代码、模型算法
 等全部上传GitHub与Hugging Face,一点没藏着。
等全部上传GitHub与Hugging Face,一点没藏着。
实际效果如何呢?
不瞒你们说,我真的看见一只大熊猫,在跳广场舞、吃火锅、打麻将,请看VCR:
到底是来自四川的猫!
目前该模型已上线腾讯元宝APP,用户可在AI应用中的“AI视频”板块申请试用。
开发者可通过腾讯云接入。
腾讯混元视频生成主打四大特点:
那么实际表现能否符合描述?下面结合实例一一拆解。
实测腾讯首个文生视频模型
首先是冲浪题材,涉及到画面大幅度运动,水的物理模拟等难点。
提示词中还特别指定了摄像头的运动,腾讯混元表现出流畅运镜的能力,只是在“最后定格在…”这个要求上稍显不足。
提示词:超大海浪,冲浪者在浪花上起跳,完成空中转体。摄影机从海浪内部穿越而出,捕捉阳光透过海水的瞬间。水花在空中形成完美弧线,冲浪板划过水面留下轨迹。最后定格在冲浪者穿越水帘的完美瞬间。
镜子题材,考验模型对光影的理解,以及镜子内外主体运动是否能保持一致。
提示词中的白床单元素又加大了难度,涉及到的布料模拟,也符合物理规律。
不过人们想象中的幽灵一般没有脚,AI似乎没学到,又或者是跳舞涉及大量腿部动作,产生了冲突。
穿着白床单的幽灵面对着镜子。镜子中可以看到幽灵的倒影。幽灵位于布满灰尘的阁楼中,阁楼里有老旧的横梁和被布料遮盖的家具。阁楼的场景映照在镜子中。幽灵在镜子前跳舞。电影氛围,电影打光。
再来一个综合型的复杂提示词,对主角外貌、动作、环境都有细致描述,画面中还出现其他人物,腾讯混元表现也不错。
特写镜头拍摄的是一位60多岁、留着胡须的灰发男子,他坐在巴黎的一家咖啡馆里,沉思着宇宙的历史,他的眼睛聚焦在画外走动的人们身上,而他自己则基本一动不动地坐着,他身穿羊毛大衣西装外套,内衬系扣衬衫,戴着棕色贝雷帽和眼镜,看上去很有教授风范,片尾他露出一丝微妙的闭嘴微笑,仿佛找到了生命之谜的答案,灯光非常具有电影感,金色的灯光,背景是巴黎的街道和城市,景深,35毫米电影胶片。
最后附上来自官方的写prompt小tips:
更多腾讯混元生成的视频,以及与Sora同提示词PK,还可以看看量子位在内测阶段的尝试。
最大的开源视频生成模型。
看完效果,再看看技术层面有哪些亮点。
首先从官方评估结果看,混元视频生成模型在文本视频一致性、运动质量和画面质量多个维度效果领先。
然后从目前公开资料看,腾讯混元视频生成模型还有三个亮点。
1、文本编码器部分,已经适配多模态大模型
当下行业中多数视觉生成模型的文本编码器,适配的主要是上一代语言模型,如OpenAI的CLIP和谷歌T5及各种变种。
腾讯在开源图像生成模型Hunyuan-DiT中适配的是T5和CLIP的结合,这次更进一步,直接升级到了新一代多模态大语言模型(Multimodal Large Language Model)。
由此能够获得更强大的语义跟随能力,体现在能够更好地应对画面中存在的多个主体,以及完成指令中更多的细节。
2、视觉编码器部分,支持混合图片/视频训练,提升压缩重建性能
视频生成模型中的视觉编码器,在压缩图片/视频数据,保留细节信息方面起着关键作用。
混元团队自研了3D视觉编码器支持混合图片/视频训练,同时优化了编码器训练算法,显著提升了编码器在快速运行、纹理细节上的压缩重建性能,使得视频生成模型在细节表现上,特别是小人脸、高速镜头等场景有明显提升。
3、从头到尾用full attention(全注意力)的机制,没有用时空模块,提升画面流畅度。
混元视频生成模型采用统一的全注意力机制,使得每帧视频的衔接更为流畅,并能实现主体一致的多视角镜头切换。
与“分离的时空注意力机制”分别关注视频中的空间特征和时间特征,相比之下,全注意力机制则更像一个纯视频模型,表现出更优越的效果。
更多细节,可以参见完整技术报告~
— 完 —
量子位 QbitAI · 头条号签约
关注我们,第一时间获知前沿科技动态


康企达美采购网(www.caigoula.cn)B2B电子商务平台,集采购和批发于一体,为中小企业提供撮合交易服务,旨在帮助用户一站直达全网商品信息,触达海量优质商家。让买家快速便捷地找到优质货源,为商家提供海量匹配的询价信息,获得更多曝光,快速达成交易,降低成本提升盈利。康企达美采购网,让采购批发变得更简单。

襄阳光瑞汽车零部件有限公司

南方人才网(job168.com)是广州人才集团官方唯一人才网,提供最新最全的人才职位招聘信息。主营人才招聘、人才培训、猎头、网络招聘、报纸招聘、薪酬调查、档案挂靠等服务。南方人才招聘网月发布职位信息高达48万条,日均页面浏览量超1000万,是华南最具影响力的人力资源网站。

南宁九龙商务公司(☏:189-7893-9080)成立于2004年,专注代办公司注册、工商注册、公司注销、注册公司流程、代办公司营业执照、会计代理报税记账、许可证、资质证等服务办理。九龙商务-您创业的好帮手

您身边的贴身视觉管家

重庆隆鼎科技有限公司

慧工商网提供专业注册公司服务,工商变更服务,公司注销服务,异章证遗失登报补办等全程免费服务无需第三方服务。

深圳鸿成敖网络科技有限公司(鸿成敖科技)是一家创新型互联网科技公司,成立于2016年,这里聚集着一群游戏爱好者,我们享受着游戏开发的乐趣,并希望将这种乐趣通过我们的游戏传递给大家。

03软件园是一个专业的软件下载门户,提供丰富的安卓手机软件和游戏资源。无论是热门手游排行榜还是最新应用下载,我们为您提供安全、快速的软件下载体验。探索手机应用的无限可能,尽在03软件园!

温州市焊接设备厂位于温州市区内吴桥工业区,面积8000平方米,建厂于1979年,是研究、开发、生产焊机,焊接辅助设备,机具的专业工厂。曾荣获国家劳动人事部,工商行政管理局,中国社会科学院,全国总工会,共青团中央,表彰的先进单位,多次被评为温州市先进企业。

年华数据科技有限公司


虽然现在人们的生活质量有了很大的提升,但是在快节奏的生活当中,总是会让自己的心情非常糟糕,因此人们都比较向往安逸的农场生活,可以自由种植农作物,养殖生物,经典的安卓农场游戏在哪里下载,相信是众多玩家比较关注的问题,这篇文章将为大家做出了详细的解答,都有简单的操作方式以及可爱又卡通的画面,不论多大年纪的人群都可无尽体验,在模拟农场系列当...。

最近工作压力比较大的朋友,可能会玩游戏放松一下,那么有没有什么舒缓又好玩的游戏呢,小编推荐这种左右点击杀怪的手游,打怪的游戏谁都爱,解压更是效果好,小编今天就为大家盘点五款超解压的点击杀怪游戏,假如你想拥有这种体验的话,就快来下载吧,1、,天天酷跑,天天酷跑,可以在一条路上跑酷并且战斗的游戏,通过跳跃和蹲伏,可以吃到特定道具来杀怪,...。

10月21日昨天,雷鸟创新发布新一代消费级XR眼镜雷鸟Air1S,首发尝鲜价2299元,据介绍,雷鸟Air1S采用BirdBath,MicroOLED技术方案,可提供130英寸高清巨幕,眼镜可覆盖观影、游戏、办公、无人机、智能座舱等多个场景,雷鸟Air1S搭载新一代SonyMicroOLED,并在业内首发超线性单元0.5mm冲程,在显...。

视觉中国网站和ICphotoy俩家版权图片网站,因违规与境外企业开展涉及互联网新闻信息服务业务,近日被国家网信办约谈,责令视觉中国网站和ICphotoy全面暂停网站服务自觉整改,网信办负责人指出,视觉中国网站和ICphoto网站严重违反国家互联网有关法律法规和管理要求,在未取得互联网新闻信息服务许可情况下从事互联网新闻信息服务,在未经...。
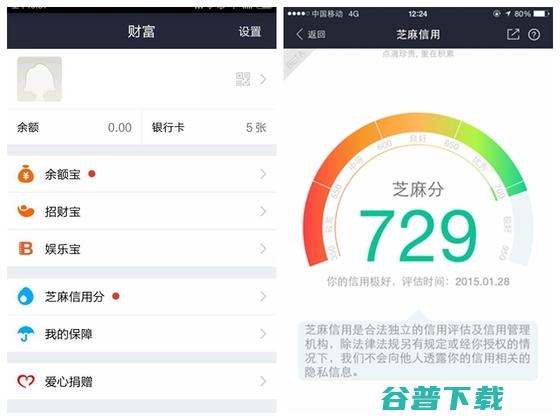
除了你的高考分数,另外一个对你很重要的数字诞生了,芝麻信用分数,1月28号,蚂蚁金服旗下的芝麻信用开始公测,以芝麻信用栏目出现在一些支付宝钱包用户的,财富,一栏,2014年9月底,超先声首先曝光了正在筹建中的芝麻信用,2015年1月5日下午,人民银行印发,关于做好个人征信业务准备工作的通知,,要求芝麻信用管理有限公司、腾讯征信有限公司...。
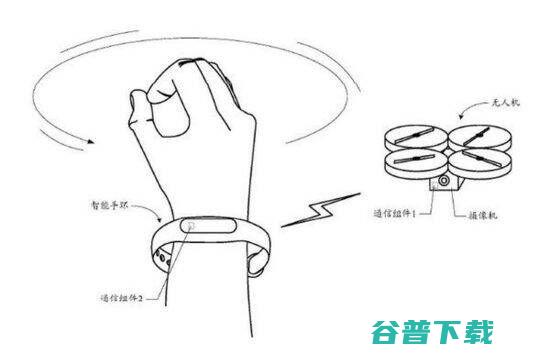
最近有专利文件显示小米目前正在研发自家制无人机,而且更有可能会加入采用体感方式操控,相信应该能提供另类的操作体验,其实过去几个月网上曾不断传出小米将会进军无人机领域的传闻,虽然官方一直对此不置可否,但据中国知识产权局最近公开的专利文件显示,原来小米于2015年8月26日申请了一项,无人机的拍摄控制方法及装备、电子设备,的专利,当中可以...。

4月3日,泰国曼谷,润和软件携手日本排名前两大芯片商瑞萨、索喜全球首发两款新一代高性能AI计算平台,HiHopeRZ,G2Boards,基于瑞萨2019年2月最新发布的RZ,G2M高性能芯片,符合LinuxCIP工业级规范,可广泛应用于智能机器人、工业自动化、楼宇自动化、行业人机交互系统等多个IOT领域,HiHopeAkebi96,基...。

雷锋网按,外界都在期待金蝶云业务收入60%能否兑现,但显然2020年初猝不及防的新冠疫情与前期对核心云产品苍穹的高研发投入以及业务云迁移中所耗费的交付成本,让金蝶云转型属实机遇与挑战并存,不过,现在的金蝶可以对外声称,云服务业务已经成为集团的主要业务,8月18日,金蝶公布了截止2020年6月30日的中期业绩,报告期内,集团收入同比下降...。

美容养生馆通常会提供多种不同的项目,以满足客户的不同需求和偏好,下面舜文源智美慧告诉你美容养生馆都有什么项目,美容按摩,包括全身按摩、足部按摩、淋巴排毒按摩、按摩等,面部护理,包括面部清洁、面部按摩、面膜护理、精华液护理、针对不同肤质的护理等,美容仪器,包括紧肤拉提、高频等美容仪器的使用,美甲,提供美甲服务,包括修剪、护理、美化指甲,...。

11月12日信息,多位知情人士泄漏,美国入选总统特朗普估量将任命共和党佛罗里达州联邦参议员马尔科·卢比奥,MarcoRubio,为国务卿,知情人士说,特朗普仍有或者在最后一刻扭转主意,但仿佛曾经选定了卢比奥,他在往年选用竞选同伴时也思考过卢比奥,纽约时报,...。

8月30日晚间,工商银行、农业银行、树立银行、邮储银行相继发布了半年报数据,至此,国有六大行半年报已悉数披露,往年前6个月,国有六大行算计成功归属于股东的净利润,下同,总计6833.88亿元,低于去年同期的6900.2亿元,往年上半年算计日赚37.54亿元,综合来看,六大行上半年业绩表现较为持重,且均将实施中期分成,多名国有大行高管承...。

福州一企业出现燃爆,有修建碎片飞入村民家中据福建省福清市应急控制局,2024年7月9日17时12分左右,福清市奋安铝业股份有限公司一熔铸车间,疑似机器设施运转中引发闪爆意外,事发后,公安、消防、应急、医疗等应急接济力气抵达现场组织施救,先后搜救出3名伤者,其中2名伤者因伤势过重,经抢救有效死亡;1名伤者送医治疗,伤情稳固无生命风险,目...。

为了买到回家的火车票,不少人求助抢票软件,相信不少人已经收到了好友的,抢票加速求助,,也有不少朋友选择购买抢票软件平台推出的,加速包,服务以提高抢票成功率,铁路部门表示各大抢票软件的服务器常年刷新12306,相关机器特征已经被识别并被实施限制措施,这就意味着即便是用户通过抢票软件购买了,加速服务,,抢票成功率也并不会像软件显示的那样高...。

便利店在人们生活中也起着重要的作用,可以给大家带来各种物品购买,也是很多创业者比较看好的项目,市场便利店品牌有很多,大家在选择时也需要做好比较与考察,亲邻达便利店就能让很多消费者满意,亲邻达便利店好不好加盟,商品配送及时吗,很多创业者也很关注这样的问题,了解清楚以后做出选择很重要,亲邻达便利店是现在很受欢迎的便利店品牌,也能以复合式便...。

一加5,正式,发布!激流中前进还是后退,雷锋网消息,跟OPPOR11类似,一加5在正式发布之前,这部手机的各类外观、硬件参数就已经泄露的差不多了,虽然离国内正式发布还有几个小时,但这部备受瞩目的国产手机,在国外官网已经正式上线了,在硬件配置方面,而在售价方面,6GB内存,64GB存储空间的版本卖479美元,约合人民币3270元,,而皇...。

6月18日,三大世界顶级计算机视觉会议之一,计算机视觉与模式识别会议,ConferenceonComputerVisionandPatternRecognition2019,CVPR2019,在美国长滩拉开帷幕,顶会吸引全球超过9200位顶尖专家、学者以及产业界人士,共同推进CV技术的发展与落地,相比2018年,本届CVPR的论文提...。

包子早餐店在人们生活中需求很大,也离不开,现在很多创业者也想开包子铺,满足大家用餐需求,市场有名气的品牌比较多,其中,李与白包子铺经营很有特色,让顾客吃的满意,李与白包子铺加盟费大概多少,作为加盟商也需要了解一下所需要的费用问题,李与白包子铺公司拥有十多年的餐饮店运营经验,从成立以来就能打造有特色的餐饮品牌,建立了一支有实力,有想法的...。
