谷歌研究员 我可太开心了! 2022 ACL Sebastian Ruber 线下参加 (谷歌研究所)
今年 ACL 线下召开,谷歌研究员Sebastian Ruber也到现场参会了!
ACL 2022的举办地点是都柏林,Sebastian Ruber位于谷歌伦敦,过去不远。ACL之行结束后,他兴致冲冲地写下了他的参会感受,分享了他对几个学术动态的关注,包括:1)语言多样性和多模态;2)提示学习;3)AI 的下一个热点;4)他在大会中最喜欢的文章;5)语言和智能的黑物质;6)混合式个人体验。
以下AI科技评论对他的分享做了不改变原意的整理与编辑:

图注:ACL 2022 主题演讲小组讨论支持语言多样性的小组成员及其语言
ACL 2022 有一个主题为“语言多样性:从低资源到濒危语言”的主题赛道。除了赛道上的优秀论文,语言多样性也渗透到了会议的其他部分。史蒂文·伯德(Steven Bird)主持了一个关于语言多样性的小组讨论,其中研究人员会讲和研究代表性不足(under-represented)的语言。小组成员分享了他们的经验并讨论了语言之间权力动态等话题。他们还提出了切实可行的建议,以鼓励在此类语言上开展更多工作:创建数据资源;为资源匮乏和濒危语言的工作建立会议轨道;并鼓励研究人员将他们的系统应用于低资源语言数据。他们还提到了一个积极的进步,即研究人员越来越意识到高质量数据集的价值。总体而言,小组成员强调,使用此类语言需要尊重——对说话者、文化和语言本身。
濒危语言也是 Compute-EL研讨会的重点。在颁奖典礼上,最佳语言洞察论文提出了KinyaBERT,这是一种利用形态分析器为基尼亚卢旺达语(Kinyarwanda)预训练的模型。而最佳主题论文为三种加拿大土著语言开发了语音合成模型。后者提供了一个多模态信息【译者注:此处的多模态是指语言的不同形态的信息,例如语音、文字、手语等等】如何有益于语言多样性的一个例子。


其他多模态论文利用电话表示来提高斯瓦希里语和基尼亚卢旺达语[1]中的实体识别任务的性能。对于低资源的文本到语音,也有工作[2]使用发音特征,例如位置(例如,舌头的正面)和类别(例如,浊音),这些特征可以更好地泛化到训练集中没有见到过的音素。一些工作还探索了新的多模态应用程序,例如检测美国手语中的手指拼写[3]或为声调语言翻译歌曲[4]。
多语言多模态研讨会在MaRVL数据集上主持了一项关于多语言视觉基础推理的共享任务。看到这种多语言多模态方法的出现特别令人鼓舞,因为它比前一年的 ACL 有所改进,其中多模态方法主要处理英语。
之后作者也受邀做了关于“将NLP系统拓展到下1000种语言”的口头汇报。

图注:Sebastian Ruder在ACL 2022上现场做的汇报
在受邀演讲中,作者除了介绍将NLP 系统扩展到下1000 种语言的三个其他挑战,即计算效率、真实语料上的评估以及语言变种(如方言)之外,他还强调了多模态的重要性。多模态也是由Mona Diab宣布的ACL 2022D&I特别倡议“60-60通过本地化实现全球化”的核心。该计划的重点是使计算语言学(CL)的研究能够同时被60 种语言应用,并且包括文本、语音、手语翻译、隐藏式字幕和配音在内的所有模态。该计划的另一个有用方面是整理最常见的CL术语并将其翻译成 60 种语言,而缺乏准确的科学术语表达对许多语言在CL的发展造成了障碍。
代表性不足的语言通常几乎没有可用的文本数据。两个教程侧重于将模型应用于此类低资源语言种。(1)使用有限文本数据进行学习的教程讨论了数据增强、半监督学习和多语言应用,而(2)使用预训练语言模型的零样本和少样本NLP教程涵盖了提示、上下文学习、基于梯度的LM任务迁移等。


如何在不同语言中以最佳方式表示token是一个悬而未决的问题。一些工作采用了几种新方法来克服这一挑战。最佳语言洞察论文KinyaBERT利用了形态学分词方法。类似地,霍夫曼等人[5]提出了一种方法,旨在在标记化(tokenization)过程中保留单词的形态结构。该算法通过确定词汇表中最长的子字符串来标记一个单词,然后在剩余的字符串上递归。

Patil等人[6]并没有选择在多语言预训练数据中频繁出现的子词(这会使模型偏向于高资源语言),而是提出一种更偏向那些多种语言共享的子词的方法。CANINE[7]和 ByT5[8]都完全取消了标记化,直接对字节进行操作。
通常情况下,语言不仅在言语形式上有所不同,而且在文化上也有差异,其中包括说话者的共同知识、价值观和目标等。赫什科维奇等人[9]对——什么对于跨文化NLP的很重要——这一问题提供了一个很好的概述。举例来说,考察一种特定文化下和时间有关的语言表达,例如早晨,在不同语言中它可能指的是不同时间。

图注:不同文化语境下可能会变化的四个维度:言语形式、目标价值、共有知识和侧重传达的内容
除了上述提到的文章,作者还罗列了他自己比较喜欢的文章:
文章讨论了NLP对非洲语言的挑战,并就如何应对这些挑战提出了切实可行的建议。它突出了语言现象(语调、元音和谐和连续动词构建)和非洲大陆的其他挑战(识字率低、正字法不标准化、官方语境中缺乏语言使用)。

这篇论文刚出版时,作者就写过它。文章对涵盖 70 种语言的大规模多语言数据集进行了仔细审核,并发现了许多以前未被注意到的数据质量问题。它强调了许多低资源语言数据集质量低下,一些数据集的标记甚至完全是错误的。

我们想知道模型的性能如何如果将它迁移到一种新语言,这可以有助于告知我们在新语言任务中需要多少训练数据。文章通过联合学习预测跨多个任务的性能,使性能预测更加稳健。这还可以分析在所有任务上,影响零样本迁移的特征。

而以下则是作者参与的和这个领域相关的论文:
文章提供了对于印度尼西亚中的700多种语言在NLP上的挑战的概览(印度尼西亚是全世界语言多样性方面第二多的国家)。这其中包含各种各样的方言、说话风格的差异、相互混合以及正字法的变化。作者们做出了实用性的建议,包括方言文本化,并将信息录入到数据库中。

作者分析了不同的利用双语预料来为低资源语言训练合成数据的策略,并分析了如何把合成的数据和现有的数据结合(如果有的话)。文章结果发现,这要比直接翻译合成的数据效果要好(针对这些低资源语言的神经翻译模型也往往做的不好)。

这是一篇综述反省性的文章,作者们定义一个称作“单一角落”(Square one)的NLP原型研究趋势,并通过检验461篇ACL‘21的做了口头汇报的论文,发现现在的NLP尽管已经超越了这一趋势,却还是存在研究维度单一的问题。他们发现几乎70%的文章仅仅使用英语进行评估,几乎40%的文章仅仅评估性能。仅仅6.3%的文章评估公正性、偏差等方向,以及仅6.1%的文章是“多维度”的,也就是他们在2个及以上的维度上都做了分析。
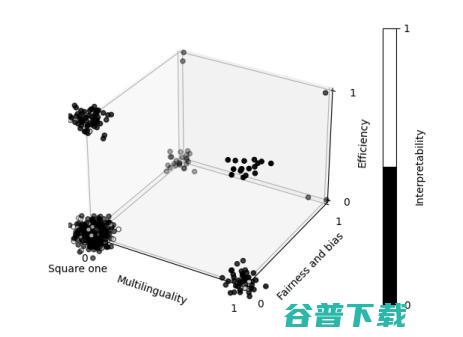
ACL’21文章研究内容的分类可视化,聚集现象表明研究的单一性
提示学习(Prompt)
提示学习是另一个受到广泛关注的领域。最好的展示样例是由清华大学开发的OpenPrompt,这是一个用于提示学习的开源框架,可以轻松定义模板和语言器(verbalizer),并将它们与预训练好的模型相适配。

一个常见的研究思路是将外部知识纳入学习过程中。等人建议用知识库中的单词扩展语言器。Jiacheng Liu[11]等人先使用语言模型在少量样本的设置中生成相关的知识陈述,然后使用第二个语言模型来回答常识性问题。我们还可以通过修改训练数据来整合额外的知识,例如,通过在实体之后插入元数据字符(例如,实体类型和描述)[12]。
其他论文则提出了一些适合于特定应用的提示。Reif等人[13]提出一个可以处理带有不同风格例子的模型,用于风格迁移;而 Tabasi 等人[14]使用语义相似性任务的相似性函数得到特殊符号[MASK]标记的词嵌入。Narayan等人[15]则通过预测目标摘要之前的实体链来引导摘要模型(例如,“[ENTITYCHAIN] Frozen | Disney“),如下图所示。Schick等人[16]用包含某个属性的问题提示模型(例如,“上述文本是否包含威胁?”)以诊断模型生成的文本是否具有攻击性。Ben-David等人[17]生成域名和域相关特征作为域适配的提示。

图注:Narayan等人[16]则通过预测目标摘要之前的实体链来引导摘要模型
在和视觉相关的多模态设定中进行提示学习也受到了一些关注。Jin等人[18]分析了多样的提示在少样本学习设定中的影响。Haoyu Song等人[19]使用CLIP探讨了视觉-语言领域下的小样本学习。他们使用T5模型根据视觉问答的问题生成提示,并使用语言模型过滤掉不可能的答案。然后将提示与目标图像配对,并使用 CLIP计算图像-文本对齐分数。如下图所示。

图注:Haoyu Song等人[19]使用T5模型产生prompt,并用CLIP得到图像文本匹配程度
最后,有几篇论文试图更好地理解提示学习。Mishra等人[20]探索重新构建指令的不同方法,例如将复杂任务分解为几个更简单的任务或逐条列出指令。Lu等人[21]分析模型对少样本顺序的敏感性。由于没有额外的开发数据就无法确定最佳排列,因此他们使用语言模型本身生成合成开发集,并通过熵确定最佳示例顺序。
以下论文是与作者合作的与少样本学习有关的工作:
文章引入了一个评估框架,使小样本评估更加可靠,包括新的数据拆分策略。我们在这个框架下重新评估了最先进的小样本学习方法。我们观察到某些方法的绝对和相对性能被高估了,并且某些方法的改进会随着更大的预训练模型而降低,等等。

我们研究最先进的预训练模型的记忆和泛化行为。我们观察到当前模型甚至可以抵抗高度的标签噪声,并且训练可以分为三个不同的阶段。我们还观察到,预训练模型的遗忘比非预训练模型要少得多。最后,我们提出了一个扩展,以使模型对低频模式更具鲁棒性。


图注:「下一个大热点」(Next Big Ideas)会谈现场
作者专门提到了他最喜欢的会议之一是Next Big Ideas,这是会议组织者开创的一种新形式。该会议的特色是高级研究人员对重要的研究方向提出了有见地的看法。
对作者而言,本次会议中突出的两个主题是:结构(structure)和模块化(modularity)。研究人员强调需要提取和表示结构化信息,例如关系、事件和叙述。他们还强调了思考这些是如何表示的重要性——通过人类定义和适当模式的设计。许多主题需要处理多个相互依赖的任务,无论是故事理解、推理还是模式学习。这将需要多个模型或组件相互连接。(如果读者想了解有关模块化方法的更多信息,作者将在EMNLP 2022上介绍一个何NLP 模型的模块化和参数高效微调的教程。)总的来说,这些研究提案勾勒了一个令人信服的愿景,即 NLP 模型以结构化、多智能体的方式提取、表示和推理复杂的知识。
Heng Ji 在该会议开始时热情地呼吁NLP模型有更多的结构表示。她强调(从当前的句子级和文档级信息提取)转向语料库级信息提取,并注意到从其他类型的文本,例如科学文章以及低资源语言,中提取关系和结构。在多模态设定下,图像和视频可以转换为视觉token,之后组织成结构,并使用结构化模板进行描述。提取的结构可以进一步泛化为模式和事件模式。我们可以通过将结构嵌入到预训练模型中来表示结构,通过图神经网络或通过全局约束对其进行编码。
Mirella Lapata 讨论了故事,以及我们为什么应该关注它们。故事有形式、结构和反复出现的主题,这是自然语言理解(NLU)的核心。它们还与许多实际应用相关,例如问答和摘要。为了处理故事,我们需要进行半监督学习和训练模型,以便可以处理很长的输入或者多个相互依赖的任务(例如建模角色、事件、时间性等)。这需要模块化的模型以及在闭环包括人类协作。
Dan Roth 强调了基于NLU做出决策推理的重要性。鉴于推理过程的多样性,这需要多个相互依赖的模型和确定一个与哪些模块相关的规划过程。我们还需要能够推理时间和其他物理量。为此,我们需要能够提取、上下文化(contextualize)和搜寻相关信息,并为推理过程提供解释。为了监督模型,我们可以使用附带监督,例如可比较的文本。
Thamar Solorio 讨论了如何为世界上一半的多语言人口和经常使用语言转换的人口提供服务。相比之下,当前的语言技术主要迎合单语使用者。通常使用语言转换的非正式环境变得越来越重要,例如在聊天机器人、语音助手和社交媒体的背景下。她指出了诸如资源有限、对话数据中的“噪音”以及音译数据问题等挑战。我们还需要确定相关用途,因为语言转换并非在所有 NLP 场景中都相关。最终,“我们需要能够代表人们使用语言的实际方式的语言模型”。
Marco Baroni 专注于模块化。他提出了一个研究愿景,即一个冻结的预训练网络通过自主地相互交互来共同解决新任务。他建议模型应该通过一个易于推广的学习接口协议进行通信。
Eduard Hovy 敦促我们重新发现对表征和知识的需求。当知识很少或从未出现在训练数据中时,例如隐式知识,模型不会自动学习到它。为了填补这些空白,我们需要定义一组我们关心的人类目标以及捕捉未说或将要说的内容的模式。这需要将学习的流程发展为一组相互关联的流程,例如在大流行背景下患者、流行病学家和病原体的流程。同样,为了捕捉群体中人们的角色,我们需要人为的定义和指导。总体而言,他鼓励社区构建可以被模型学习到的拓扑结构。
最后,李航强调了符号推理的必要性。他为NLU提出了一种神经符号架构,该架构结合了通过预训练模型进行的类比推理和通过符号组件进行的逻辑推理。
除了 Next Big Ideas会议外,会议还包括早期职业研究人员的演讲。作者有幸与Eunsol Choi、Diyi Yang、Ryan Cotterell 和 Swabha Swayamdipta等优秀的年轻研究人员一起发言。他希望未来的会议将继续采用这些格式,并与其他人一起进行试验,因为它们带来了新的视角并为研究提供了更广阔的视野。

图注:Yejin Choi教授推测ACL 2082可能是什么样的
Yejin Choi教授发表了一个鼓舞人心的主题演讲。除此之外,这是我看到的第一个使用DALL-E 2来绘制幻灯片的演讲。她通过类比物理学强调了 NLP 的三个重要研究领域:模糊性、推理和隐含信息。
在现代物理学中,更深入的理解往往会导致模糊性增加(例如,参见薛定谔的猫或波粒二象性)。Yejin同样鼓励ACL社区接受模糊性。过去,研究者往往不去做未达到高度注释者间一致性的任务;同样,在传统的情感分析中,中性类经常被丢弃。理解不能仅仅局限于简单的类别。带有注释者意见偏见的语言模型和模棱两可的例子提高了泛化能力。
与时空的概念相似,Yejin认为语言、知识和推理也不是独立的领域,而是存在于一个连续统一体上。maieutic提示等推理方法[22]允许我们通过递归生成解释来研究模型知识的连续性。
最后,类似于暗物质在现代物理学中的核心作用,NLP 未来的研究应该关注语言的“暗物质”,即世界运作的潜规则,它影响人们使用语言的方式。我们应该立志尝试教给模型,例如默认规则、价值观和目标。
Yejin坦率地总结了导致她成功的因素:谦虚、向他人学习、冒险;但也很幸运并在一个包容的环境中工作。

图注:都柏林会议中心,ACL 2022 的举办地
作者直言他非常喜欢面对面的会议体验。会议期间有严格的戴口罩要求。唯一的问题是在全体会议和主题演讲中出现了一些技术问题。
另一方面,作者也发现很难将面对面的会议体验与虚拟会议体验相协调。虚拟的海报会议往往与早餐或晚餐时间重叠,这使得参加会议变得困难。据我所知,许多虚拟海报会议的观众几乎是空的。看来我们需要重新考虑如何在混合环境中进行虚拟海报会议。作为替代方案,在rocket.chat 或类似平台中创建异步的每张贴者聊天室可能更有效,并且能够设置即兴视频通话以进行更深入的对话。
作者对于有合理数量的虚拟参与者的口头报告和研讨会的体验也很喜欢。他也特别感谢能够多次观看的主题演讲和其他受邀演讲的录音和视频。

版权文章,未经授权禁止转载。详情见 转载须知 。



免费自动秒收录(yiyou168.com)提供网址导航,自动秒收录为你提升流量,免费外链发布的网站目录导航,自助式申请加入自动收录,是发外链神器!快速加入自动秒收录平台吧!

随时随地,想唱就唱,让音乐无处不在,让生活因为有了音乐而更加精彩!魔三音响科技(深圳)有限公司致力于打造专业户外多功能便携式充电音箱。目前,魔三音箱系列产品深受各地音乐爱好者喜爱。这里拥有最无敌的创意、最精美的视觉、最具国际化的意识和前瞻性思维!

中国认证信息网全力打造ISO认证咨询、验厂咨询、检验检测、认证培训及企业管理培训等相关行业信息服务平台,目前已成功开通北京、上海、重庆、广州、深圳、惠州、东莞等三十余家城市分站。

嘉标网,专业的商标转让平台。为您提供安全、高效的商标交易服务。在这里,您可以轻松找到心仪的商标,实现品牌价值的最大化。购买商标选择嘉标网,让商标交易更简单、更放心!

江苏小度网络运营服务有限公司定位于全网数字营销专家,公司服务范畴有:google优化推广,外贸seo整站优化,谷歌推广竞价广告,词条创建,百度seo推广,内外贸网站建设,以及facebook推广,外贸代运营等服务。拥有专业海外推广团队及执创人员,十年以上专业内外贸推广经验,为您的网站量身定制打造高质量的流量及询盘。

专业大型树枝粉碎机厂家,绿化果园打树枝机器全套设备生产厂家,设计合理,操作简便.拥有优异的市场占有率,产品性能完善,深得客户信赖,赢得了国内外客户的近悦远来.

实验游戏网是一个集海量游戏攻略、资深玩家社区、安全下载服务、个性化推荐和优质服务于一体的游戏平台。我们专注于为游戏爱好者提供全面、详细的游戏指南,以及安全、便捷的游戏下载服务,让您的游戏体验更加丰富多彩。快来与我们一起探索游戏的无限可能吧!

AI工具导航专注于人工智能的工具导航,收录了国内外5000+个AI工具!为用户提供丰富的AI资源。帮助您加入人工智能浪潮,自动化高效完成任务!

曾芬博客

智慧微游

郑州天彩电子产品有限公司主要产品有:led显示屏,led电子屏,led舞台屏,led广告屏,led租赁屏,led移动屏,小间距led屏。是LED显示屏,LED光源研发、生产、销售、工程、维护一体化专业性公司,是LED产品从原材料到售后维护“一条龙”配套服务的厂商。

燃旭软件是一家专注于行业应用软件开发的创新型企业。提供专业的信息管理软件、App开发、小程序开发服务。业务领域包括:办公管理、电商、生活服务、在线教育、交通出行等。


微软终于发布了Office2016forMac预览版,适配Retina高分屏并支持全屏模式,过去的一年里,微软在不遗余力地将Office办公软件带到新的平台——iPhone,iPad,Android手机和平板,只是微软唯独没有发布新版的OfficeforMac,尽管此前它已经推出了新版Outlook和OneNote的客户端,最主要的W...。

杭州第19届亚运会电竞项目已正式开赛,为了让普通用户也能体验足球竞技的乐趣,9月27日,作为电竞项目之一的,足球在线4,EASPORTSFCONLINE,同款推广互动,FCOnline点球大战,小程序正式在支付宝上线,用户上支付宝搜,点球大战,即可体验足球射门、球衣收集、球员换装、对战积分挑战、夺真实金条挑战等玩法,感受足球场上紧张...。

举报董事长高管表态,瑞幸已面目全非,公道自在人心1月6日,网曝瑞幸咖啡24名中高管签署联名信要求罢免董事长郭谨一,在该封信中,高管们,举报,瑞幸咖啡现任董事长、CEO郭谨一存在诸多问题,并以此请求董事会罢免郭谨一职务并改组管理层,此外在联名信发出后不久,1月6日,郭谨一对瑞幸全体员工发布了内部公开信,他表示自己已第一时间提请董事会成立...。

苹果有Siri,微软有Cortana,亚马逊有Alexa,谷歌有GoogleAssistant,如今,三星也正式加入了智能语音助手这一战场,据外媒报道,在经过几个月的各种传闻之后,三星日前正式确认,其语音助手的名字为Bixby,预计将会取代此前的SVoice,去年,三星宣布收购VivLabs,该公司的联合创始人是,Siri之父,Dag...。

好吃又营养的美食,总能俘获人们的味蕾需求,还能为顾客留下深刻印象,现在高水准的消费者追求的不仅仅是食物口感,同时还要健康有特色,以至于现在餐饮市场开始倾向于健康饮食,老汤和乌鸡米线以不一样米线口感,在市场圈粉无数,将乌鸡与小吃米线结合起来,迎合现在人们健康饮食需求,那么吃过老汤和乌鸡米线评价如何,老汤和乌鸡米线作为一种地道正宗中式美食...。

想要在餐饮行业中取得成功,就需要了解到大家的口味偏好情况,春笋所谓一种特色的食材,经过了烹饪之后,味道更加的鲜美,人们在外出就餐的时候都喜欢购买一份春笋,随着市场中对春笋美味需求量不断增加的同时,创业者们纷纷萌生了加盟一家春笋饭店的想法,那么春笋饭店加盟费多少钱,春笋饭店加盟费多少钱,春笋饭店加盟费和品牌的名气、门店的规模和城市的消费...。

寻找好的陪聊平台,体验玩家通常会推荐微信公众号,尤其是微信公众号小酒馆的树洞,提供了丰富且贴心的互动体验,在这里,你可以享受到陪聊、陪玩、哄睡的温馨服务,甚至还有温柔的提醒,帮助你按时起床,无论你感到不开心还是无聊,这里都能提供一个倾诉的平台,小酒馆的用户群体中,小哥哥小姐姐们以其出色的颜值,为平台增添了一抹亮丽的风景线,他们不仅外貌...。

作为,受死游戏,死にゲー,的代表,初代,仁王,曾仰仗硬核的,魂,like,玩法以及妖怪横行的日本战国时代设定吸引了许多粉丝,而在阔别将近一年之后,仁王2,也终于登陆了PC平台,仁王,系列最新作品的,仁王2,,在系统上完美承袭了前作的好处,并在这之上启动了改良和优化;从,残神思制,到,上中下,三段的武器形式,以及单一的武器种类和帅气...。

北青:国足在日本的首训强度降低伊万带领教练组寻找对手漏洞,伊万,国足,北青,日本

国际可以买到的9座汽车如下1、飞驰,威霆、经销商参考价,29.60,34.90万3、公众,凯路威、经销商参考价,32.88,39.18万4、长安超过,长安V5、经销商参考价,4.28,4.66万元5、金杯,阁瑞斯、经销商参考价,7.98,27.78万元6、长安轻型车,睿行M90、经销商参考价,6.85,9.25万元7、金杯,海狮、经销...。

[女生买2份饭拿6双筷子被申斥偷盗,高校回应]6月20日,福建厦门,有网友爆料在厦门东海职业技术学院一女生在食堂买2份饭拿6双一次性性筷子,被食堂上班人员申斥偷窃,当事女生称,在食堂商铺买2份饭拿了六七双筷子,食堂上班人员说我偷窃食堂东西还说要报警,自己一气之下也报了警,警察来了之后,他却通知警察食堂被偷了1500个勺子,也拒绝赔罪...。

我引见的梅赛德斯,迈巴赫旗下新车——2024款迈巴赫S级S4804MATIC、2023款,改款,迈巴赫S级S5804MATIC、2023款迈巴赫S级S6804MATIC上市,售价区分为146.8万元、248.9万元、329.8万元,迈巴赫是哪国的1、德国的迈巴赫MAYBACH是一个充溢了传奇色调的汽车品牌,独创于20世纪20年代,由德...。

今天下午微信发布公告称,对,微信外部链接内容管理规范,相关规则进行了进一步升级,此次相关规则升级针对试听内容有严格限制,外部链接不得在未取得信息网络传播视听节目许可等法定证照的情况下,以任何形式传播含有视听节目的内容,同时微信还对特殊识别码、口令类信息传播进行规范,朋友圈内不允许发布及传播具有识别、标记功能的特殊识别码、口令类信息,此...。

今天晚上,MIUI官方微博发布消息称,将全面下架360软件,按照MIUI官方微博的说法,这次事件的起因是360恶意诱骗安装名为,雷电OS,的程序,并在用户并不知情的情况下静默执行Root刷机行为,篡改MIUI系统签名,植入非官方的系统应用,导致小米手机无法升级到最新版MIUI系统,偷跑流量,甚至手机系统崩溃无法正常启动,在官方声明中,...。

在,十字路口,的中国消费产业2024消费产业独角兽峰会12.7揭幕播报文章语音播报文章,释放双眼三言科技关注作者获得积分关注2024,12,0512,00来自北京作者,陈李编辑,卢旭成消费者分化和减少支付更高价格的意愿是2024年两大显著的消费挑战,从国家、地方到各行各业,大家都在为,促消费,这件事而努力,但是,消费市场,似乎没有像很...。

独家获悉,淘天集团正在筹建大模型研究团队,目前已开启招聘,据悉,淘天集团的大模型研究将主要围绕两个场景展开,一是搜广推,二是逛逛的内容化,团队组建工作由淘天集团CEO戴珊、淘天集团CTO若海、阿里妈妈CTO郑波等人共同牵头,关于淘天集团的技术体系,后续将有专文详述,欢迎与作者交流讨论,微信,LW,PLUS,一位大模型相...。
温馨提示,创维电视第三方刷机固件下载方法一,准备工作,从电脑里下载好当贝市场,点击立即下载,和影视快搜,点击立即下载,并拷贝到U盘;的主页,选择,酷开应用圈,,进入后选择推荐,打开左下角,搜索,功能;的USB接口,然后在,搜索,功能界面输入,XCX,并下载安装;四、打开,小程序,,这时候需要输入密码,密码输入正确后就可以自动识别U盘内...。
