本体和知识图谱之间的区别是什么 (本体和知识图谱的关系)
双语原文链接: What’s the Difference Between an Ontology and a Knowledge Graph?
随着语义应用程序成为业界越来越热门的话题,客户经常来EK询问有关本体和知识图谱的问题。具体来说,他们想知道两者之间的区别。本体和知识图谱是一回事吗?它们有何不同?两者之间是什么关系?
在这篇博客中,我将引导您了解本体和知识知识图谱,讲述它们之间的区别以及它们如何组织大量数据和信息。
什么是本体?
本体是语义数据模型,用于定义domain中事物的类型以及可用于描述它们的属性。本体是广义的数据模型,这意味着它们仅对具有某些属性的事物的一般类型进行建模,而并不包含有关我们domain中具体个体的信息。例如,本体论不能描述您的狗,斑点和它的所有个体特征,主要描述狗的一般概念,尝试描述大多数狗可能具有的特征。这样做可以使我们在将来用本体来描述其他狗。
本体有三个主要组成部分,通常描述如下:
例如,假设我们有以下关于书籍、作者和出版商的信息:
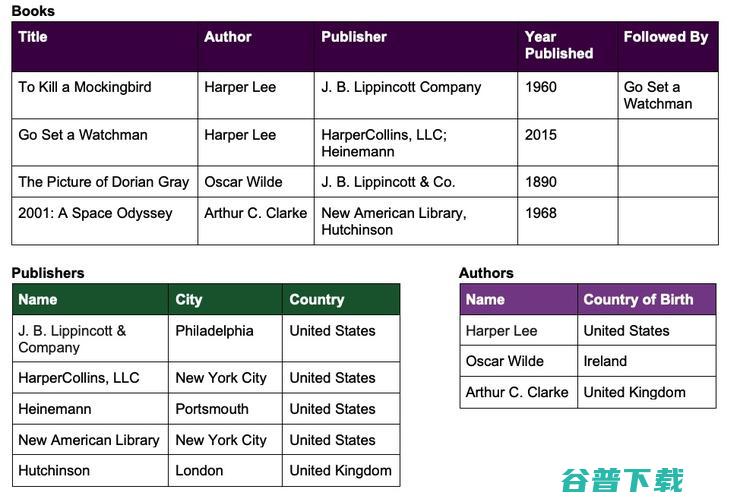
首先,我们要标识类(数据中事物的唯一类型)。这个示例数据似乎捕获了关于书籍的信息,因此它是类的一个很好的候选项。具体来说,示例数据捕获了关于书籍的某些类型的内容,比如作家和出版商。再深入一点,我们可以看到我们的数据还捕获了关于出版商和作者的信息,比如他们的位置。这给我们留下了这个例子中的四个类:
下一步,我们需要标识关系和属性(为了简单,我们可以将关系和实体属性都视为属性)。使用我们在之前定义的类,我们可以查看数据并开始列出我们看到的每个类的所有属性。例如,在书籍类中,一些属性可能是:
需要注意的是,这些属性可能适用于任何给定的书籍,但它们不一定适用于每一本书。例如,很多书都没有续集。这在我们的本体中很好,因为我们只是想确保我们捕获了可能适用于许多(但不一定是所有)书籍的属性。
虽然上面的属性列表很容易阅读,但是重写这些属性以更清楚地定义我们的类和属性会有所帮助。例如,“书籍有作者”可以写成:
书→有作者→作者
尽管你可以包括更多的属性,这取决于你的用例,对于这个博客,我已经定义了以下属性:
记住,我们的本体是一个通用的数据模型,这意味着我们不想在本体中包含关于特定书籍的信息。相反,我们希望创建一个可重用的框架,将来我们可以用它来描述其他书籍。
当我们结合类和关系时,我们能够以图的形式查看本体:

什么是知识图谱?
使用本体作为一个框架,我们可以添加关于个别书籍、作者、出版商和位置的真实数据来创建一个知识图谱。利用上面表中的信息和本体,我们可以创建每个本体关系的特定实例。比如,如果我们的本体中有这样的关系“书籍→有作者→作者”,这个关系的单个实例如下:

如果我们把我们拥有的关于《杀死一只知更鸟》这本书的所有信息加进去,我们可以看到知识图谱的开端:

如果我们对所有的数据都这么做,我们最终会得到一个使用本体对数据进行编码的图。通过使用知识图谱,我们可以将数据看作一个关系网络,而不是作为单独的表格在我们无法理解的数据点间绘制新的连接。具体来说,使用SPARQL,我们可以查询数据和使用推理功能(让知识图谱建立之前没有定义的连接)。

那么本体和知识图谱有什么不同呢?
正如你在上面例子中所看的,当你将本体(我们的数据模型)应用到一组单独的数据点(书籍、作者和出版商数据)时,那么就是创建了一个知识图谱。换句话说:
本体+数据=知识图谱
AI研习社是AI学术青年和AI开发者技术交流的在线社区。我们与高校、学术机构和产业界合作,通过提供学习、实战和求职服务,为AI学术青年和开发者的交流互助和职业发展打造一站式平台,致力成为中国最大的科技创新人才聚集地。
如果,你也是位热爱分享的AI爱好者。欢迎与译站一起,学习新知,分享成长。




股海明灯,股海明灯论坛是由黑马王子老师创办,独创量学理论,在伏击涨停,盘前预报,牛股预报方面积累了丰富的股票知识,并开设量学云讲堂,是学习量学知识,涨停技巧,股票选股公式的股票论坛。

广州市巴乐图装饰设计工程有限公司是一家专业从事幼儿园、早教中心、教育机构的整体规划,设计与施工为一体的大型人文艺术与技术相结合的企业,经过悉心的研究和探索,我们汇悟出超前的设计理念,储备并培养了大量的技术人才,拥有一批高水准的设计精英和门类齐全的能工巧匠。本公司专注于幼儿园外观洋装、室内装潢、活动广场、园林绿化景点工程及园内周边配套设施。一直以来公司在设计上的独具匠心,施工上的精心细琢,材料上的健康环保,质量上的标准精良,服务上的全心全意赢得广大教育机构的认可。我们以经济实用、美观大方、别具匠心的原则,

苏银信用管理中心|苏银企服|不良记录下架|解除限高|法律案件删除|征信修复|行政处罚解除|行政处罚下架|司法案件删除|裁判文书下架

财气网,是国内最热门的站长信息平台,致力为广大站长和SEOER提供最全面的站长资讯、创业经验、建站源码等

常德物流公司,常德货运公司,常德托运公司

杭州越展传动科技有限公司是一家专注从事减速机,减速电机,减速器生产与销售的厂家,设备型号齐全,质量上乘,大量现货供应,厂家直接销售,价格实惠,采购减速机,减速电机,减速器,欢迎来电咨询:0571-57105186.

山东美新玻璃科技有限公司是高端玻璃制品深加工企业,主要从事平板玻璃深加工技术开发和中空玻璃产品及配套件制造。主要产品包括钢化玻璃、中空玻璃、防弹玻璃、彩釉玻璃、防火玻璃、调光玻璃、夹胶玻璃、中空百叶玻璃等

高邮市华亿锻造有限公司,扬州锻造厂家为您提供锻件加工,锻造加工,锻造是一种利用锻压机械对金属坯料施加压力,使其产生塑性变形以获得具有一定机械性能、一定形状和尺寸锻件的加工方法,锻压(锻造与冲压)的两大组成部分之一.

「你来」是一款以帮助一亿国人正确高效地锻炼为使命的健身小程序。无论是想减肥增肌或塑形,还是寻找健身跑步瑜伽计步等训练计划,你可以随时随地选择课程进行训练!权威教练视频教学,健身干货自由分享.在这里健身打卡,结识志同道合的运动好友,让运动不再是孤单的坚持!

浙江思源节能电子科技有限公司是国家发改委、财政部首批备案的节能服务公司和浙江省高成长科技型企业,在稳步发展的同时积极创新“第五能源”。

装修词典网

浙江一加一网络科技有限公司是一家有着15年的互联网服务经验,是温州1688阿里巴巴诚信通渠道商,公司主营业务有电商代运营(阿里巴巴/淘宝/天猫/京东),诚信通托管、品牌/营销型网站建设、百度SEO、软件开发、全网营销、谷歌优化SEO推广等,咨询热线:15157705128/13587868446


TikTok这次面临巨大挑战,很可能会彻底成为美资收购企业,抖音公司下的TikTok真的很厉害,去年tiktok世界各国使用人数排名,美国列第一,打败了Facebook,打败了推特,X,,还有众多的美国社交软件,牢牢占据短视频领域的霸主地位,正因为越来越多的美国人使用,让传统的美国平台感到了恐惧和威胁,美国国会一看,美国公司没一个能打...。

26日晚上的一段英雄联盟直播中,选手李威俊,ID,Vasilii、死亡宣告,称被队友坑,突然暴怒开始砸东西,并疑似对女友实施家暴,整个过程直播出去,对此,李威俊所在的Newbee俱乐部英雄联盟分部官方微博@Newbee,英雄联盟,今天凌晨发布公告称,选手李威俊行为已触及最基本的为人底线,俱乐部将立即解约,今天下午,英雄联盟赛事官方微博...。

今日在脉脉里面看见一自称腾讯内部员工爆料,pony哥给内部高管开了会,说微视已经输给了西瓜抖音,新闻客户端也输给了头条,QQ直接输给了直播平台,布局不如阿里之类的,不确定是否是内部员工有待查证从1998年创立到2004年在香港上市,是腾讯的创业期,这一时期腾讯完成了产品仿制、应用创新到盈利模式探索的全过程,马化腾在创业之初提出2个产品...。

苹果14promax怎样开启微距镜头,苹果14promax手机的拍照功能不断地升级,你可以在这里设置好微距控制模式,这样就可以拍出微距照片,那么怎么开启微距镜头呢,一起来看看吧!...。

上海民警的工作一年有12万左右,根据律临资料显示,上海正式编制警察一年收入一般是12万左右,除月薪,年终奖金大概在5万左右,公积金每个月5000元,在全国的正式编制警察内,上海警察的工资是最高的,一个月有9000元,这是由于警察本身工作性质比较特殊,所以会有一些额外的津贴,如警衔越高,补贴就会越高,还有一些加班津贴等,再者,上海被称为...。
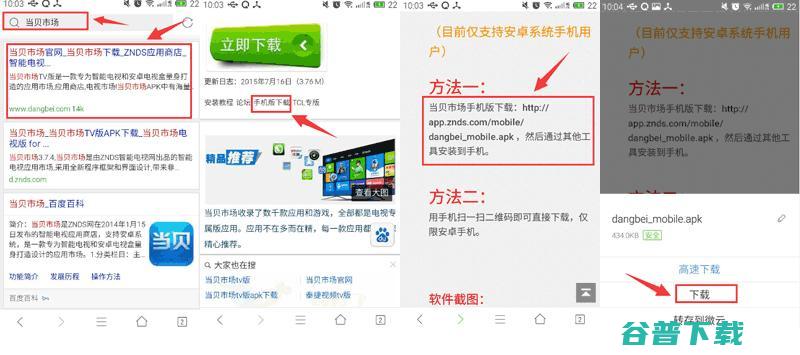
一、打开手机上的浏览器,百度搜索,当贝市场,,进入官网下载,手机版当贝市场,并安装到手机上,或点击直接下载,http,dlap1.dbkan.com,update,dangbeimarket.apk,注意,盒子和手机必须在同一局域网内,二、打开盒子,进入,Setting,——,SYSTEM,——,DeveloperOptions...。

2013年11月29日,我正式从360办完离职手续,2013年11月30日下午6点40,从北京飞回长沙,就这样,我结束了在帝都8年多的北漂生涯,以及360一年多的工作经历,离开北京前的半个月,几乎都在参加各种饭局和告别会,期间,也有很多同学朋友在问我,在这里你有那么多的同学、同事和朋友,真的舍得离开吗,这时候我都是很平静的说,没...。

从毕业后我进入了人生的很重要的一个阶段,那就是工作,开始是进入小公司的,也让我对小公司有一个了解,首先,也是我们所有人最关注的工资,在小公司里面工资相对大公司通常会是很低得,在小公司一般也会有一两个牛人在公司支撑,这样的人公司还是比较高的,其余的都很低的,并且我进的公司基本上五险一金都没有的,加班,那也是经常的事情,一个是能力不足加班...。

飞驰mb100商务车的多少钱大略在22万左右,1、MB100最大的特点是装备了多元化的奢侈车内设施,为了满足人们的须要,除了提高产质量量和性能外,MB100还装备有原厂初级音响,窗帘导轨全车地毯、防眩玻璃等设施;2、高效、节能的空调是商务车必备的设施,MB100的空调能够提供应乘客温馨的环境,前后独立的空调及车项气槽式循环系统,可以片...。
摸索MINICoupe的座位数MINICoupe,这款MINI旗下的跑车,以其共同的双座设计和出色的驾驶功能吸引了广阔车迷的眼球,MINICoupe能否真的是双座车型呢,答案是必需的,MINICoupe的车型尺寸精美,长宽高区分为3728毫米、1683毫米、1388毫米,轴距为2467毫米,这使得它能在拥堵的市区街道上轻松穿越,同时,...。

西风风神AX7来自西风二号军工平台,其越野型、能源性、牢靠性、消息化等方面的长处,与西风猛士一脉相承,风神ax7报价最低在9.5万元左右,目前最大的活动力度在5000元左右,无论哪一款尽量选用高配版的是最理智之举,国产自主品牌的西风风神性价比高性能好,高下配之间的差价很小,高下配之间的安保性和温馨性相差却很大,西风风神rx7如今市场多...。

获取窗口句柄方法:1、在Windows平台上,使用WindowsAPI函数可以获取窗口句柄;2、在Python中,使用第三方库pywin32来调用WindowsAPI函数获取窗口句柄;3、在Java中,可以使用java.awt.Window类的getWindows方法来获取所有窗口的句柄;4、在Linux平台上,使用XWindowSystem提供的函数来获取窗口句柄。

12月20日,第五届中国人工智能成果发布会在厦门召开,三六零,601360.SH,下称,360,集团因在人工智能安全治理,大模型安全攻防赛,中表现突出,荣获本届中国人工智能大赛A级证书,今年9月,在国家互联网信息办公室、公安部指导下,厦门市人民政府主办的第五届中国人工智能大赛正式启动,围绕人工智能安全治理和创新发展两大主线设置了赛题...。

合格的市场前景是创业者选择一个行业的先决条件,当然,大家不仅关注行业发展前途,还很关心收银,如果一个行业在未来年,乃至更多年,都可以稳定发展,而且收银丰厚的话,那对创业者而言,就是理想的掘金,那么问题来了,究竟未来年暴利行业有哪些呢,一起看看下面的回答,、药品行业随着国民生活水平的提升,大众在缓解保健方面的需求不断增加,因而医药行业愈...。

在火锅这个行业火锅这个品牌还是做的非常好的一个,有一些人就想要加盟到里面去,但是之前可能对于它的加盟信息并不是特别的了解,所以在真正的加盟之前还需要考虑一个问题那就是火锅火锅怎么样,这个问题的答案对于很多加盟商来说还是非常重要的,毕竟直接影响了以后的收银发展情况,下面就是关于火锅火锅怎么样这个问题的一个简单的回答,其实加盟到这个项目里...。
可修改dns,全网通网络可用;适合宽带到期的用户,破解全网通电视机顶盒;实现开机自启动功能,老人小孩必备,开机直达第三方应用;免费固件下载地址,点击直达刷机方法,在u盘建一个文件夹,upgrade,把文件刷机文件放入upgrade就可以刷机了,关机状态下插入通电或者开机状态下直接插入都可以,,系统会自动检测到刷机文件进行重启升级,无需...。

许多人通过一笔钱以后就会萌生出开店的念头,跟打工相比,开店能够挣到的钱更多,更加有希望过上富足的生活,然而,想要让自己的店铺被所在地居民关注可是很难的事情,如果没有使用好的运营策略,必定不能达成被民众关注的目标,枫庐新天地总部会指导加盟者使用运营策略,所以很多人都期望加盟这个品牌,那么,枫庐新天地加盟费用及要求是怎么样的呢,加盟者在采...。
