哈工大刘挺 从知识图谱到事理图谱 (哈工大刘挺从政了吗)
雷锋网AI科技评论按:由中国计算机学会(CCF)主办,福州市人民政府、福州大学承办,福建师范大学、福建工程学院协办的 2017 中国计算机大会(CNCC 2017)于 10.26—10.28 日在福州•海峡国际会展中心举办。大会除了14场特邀报告,还有2场大会主题论坛、40余场学术论坛、30余场特色活动以及3个颁奖大会,同期还将有80余家企业举办科技成果展。雷锋网作为独家战略合作媒体对大会内容进行了全程覆盖和报道。
在“知识图谱预见社交媒体”的技术分论坛上,哈尔滨工业大学刘挺教授做了题为“从知识图谱到事理图谱”的精彩报告。会后雷锋网征得刘挺教授的同意,回顾和整理了本次报告的精彩内容。

刘挺教授的报告内容分为四部分: 知识图谱与《大词林》;事理图谱概念的提出;事理图谱国内外相关工作;哈工大在事理图谱方面的探索。
知识图谱与《大词林》
知识图谱最早是通过人工搜集数据和标注数据来构建的,随着需求的多样化和精细化(例如,需要获得“XX疾病是否可以被XX药物治疗”,“XX人和XX人之间是否是敌人/朋友”等信息),人工构建的知识图谱越发难以满足用户多种多样的需求。基于此,如何由机器去自动构建大规模的知识图谱已经发展成为热门的研究点。
知识图谱,是基于二元关系的知识库,用以描述现实世界中的实体(或概念,概念是实体的抽象,例如“水果”即为“苹果”的概念)及其相互关系,其基本组成单位是『实体-关系-实体』三元组(triplet),实体之间通过关系相互联结,构成网状结构。通过知识图谱,可以支持用户按主题而不是按字符串检索,从而真正地实现在语义层面上进行信息检索。基于知识图谱的搜索引擎,能够直接向用户反馈结构化的知识,用户不必浏览大量网页,就可以找到自己想要获得的知识。

封闭域知识图谱和开放域知识图谱各有优劣
2014年年末,哈工大正式发布《大词林》。现在只需在浏览器中键入www.bigcilin.com,即可访问《大词林》。《大词林》是一种自动从网络中爬取实体及实体的概念以形成基于上下位关系的通用知识图谱。这意味着,如果用户输入的词语不被《大词林》所包含,《大词林》即会实时地到互联网上去搜索,以自动挖掘该词语的上位概念词,并将这些上位概念词整理为层次结构。比如输入“林肯”,《大词林》就会根据“林肯”在网络中出现的语义信息,自动挖掘出“林肯”所具有的多个概念,例如“汽车”、“总统”、“交通工具”、“领袖”等,然后再根据这些概念的抽象程度,将这些概念刻画为层次结构。例如“领袖”相对于“总统”更加抽象,在图中“领袖”的层次就比“总统”更高。

上图左侧为《大词林》层次目录的一部分,其骨架是《同义词词林(扩展版)》。《大词林》选择《同义词词林(扩展版)》作为骨架的原因在于:经过反复的探讨,刘挺教授带领的团队认为词汇应具有两种类型,一种是“实体”与真实的事物相对应,比如具体的人名、地名、机构名;另一种是“概念”,是“实体”的抽象含义,比如“植物”、“水果”等。实体之间具有明显的横向关系,而“实体”和“概念”、“概念”和“概念”之间具有明显的层次关系,因此词汇之间应具有由横向关系和纵向关系所形成的网状结构。基于此,刘挺教授带领的团队将《同义词词林(扩展版)》作为《大词林》层次(纵向)关系构建的骨架。

这里简单介绍一下作为《大词林》的骨架-《同义词词林(扩展版)》存在的问题。《同义词词林》的第一个问题是仅具有固定的5层结构,但面对千万级乃至亿万级规模多领域、多样性的词汇,固定的结构显然无法对其进行有效描述;第二个问题是《同义词词林(扩展版)》包含的词语数目非常有限,且大部分为抽象的概念,其规模不到十万词,显然不适合实际应用。基于此,刘挺教授带领的团队决心打破《同义词词林(扩展版)》的上述限制,从而形成了现在的《大词林》。首先,《大词林》的层数是不固定的,其根据词语的抽象程度自动进行层次化;其次,《大词林》中包含了很多具体的实体(例如人名、地名、机构名),其规模是《同义词词林(扩展版)》的数百倍,并且还在不断的扩充。

《大词林》的特点在于能够从多种信息源中自动地构造词汇和词汇的上下位关系。这是刘挺教授带领的团队中一名博士生发表的一篇ACL会议论文(该会议是自然语言处理领域的顶级会议,被计算机学会评定为Rank A),这篇论文详细地展示了如何自动的从多信息源里获取实体概念词的技术框架。

简单来说,获取概念词的来源主要有三个,1)搜索引擎中检索得到的高概率的同现词,2)在线百科的类别标签3)词语的构词法,对于很多词,其后缀即为该词的概念词,例如像微软公司的公司就是微软公司这个实体的概念词。之后,采用排序算法对获取得到的这些候选概念词进行打分,然后截取超过一定阈值的候选概念词保留到《大词林》中。
上面的方法仅仅获取了针对某个词语的概念词,如左图所示。但是,概念词之间是有明显的层次关系的,如右图所示,而《大词林》的特殊之处就在于能够自动形成概念词之间的层次结构。基于上述的处理方案,从《同义词词林(扩展版)》的十万词出发,现在的《大词林》已经成为一个具有千万级词汇量级的知识图谱,并且其规模每天都在不断的增长。

由于《大词林》是自动构建的,因此需要对其质量做一个评估,以判别《大词林》中是不是包含了很多的错误,到底可不可以实用。刘挺教授带领的团队对《大词林》做过抽样评估。结果显示,针对某个词语,找到其概念词的准确率为85%,词语之间的上下位关系识别的准确率为90%。
相比于其他知识图谱,《大词林》主要专注于语言学中词汇的上下位关系的自动构建,是一种语言的知识图谱。当然,目前刘挺教授带领的团队也着手在《大词林》中引入横向关系,相信不久的将来就能看见更加全面的《大词林》。
关于事理图谱。现有的知识库普遍是以“概念及概念间的关系”为核心的,缺乏对“事理逻辑”知识的挖掘。刘挺教授团队认为在实际应用中,事理逻辑(事件之间的演化规律与模式)是一种非常有价值的常识知识,挖掘这种知识对我们认识人类行为和社会发展变化规律非常有意义。举个经典例子,北京人买房子,买完房子下一步就是装修,装修完了就会买家具,如果在网上发现有人发微博说他买房子了,装修公司就可以跟上去做广告,这就是一种预测。事理图谱并不是以名词为核心节点的知识库,而是以事件而且是抽象类事件为核心的事理逻辑知识库。举个例子,国家领导人访问另一个国家,这就是一个抽象事件。刘挺教授的团队三年前就提出了事理图谱的概念。

事理图谱只定义两种事件间关系:一种顺承,一种因果,这两种关系都有时间顺序。本质上事理图谱是一个事理逻辑知识库,描述了事件之间的演化规律和模式,可以应用在生活中的很多方面,比如事件预测 ,常识推理,消费意图挖掘,对话生成等等。

事理图谱与知识图谱的区别,知识图谱研究对象为名词性实体及其关系,事理图谱研究对象是谓词性事件及其关系。知识图谱主要知识形式是实体属性和关系,事理图谱则是事理逻辑关系以及概率转移信息。事件间的演化关系多数是不确定的,而实体之间的关系基本是稳定的。

事理图谱中的事件定义。事理图谱中的事件是一个泛化的抽象的事件,比如吃火锅,去机场 ,看电影都可以,但要是说非常的具体,某年某月干了什么,这就不是事理图谱中存储的知识。但也不能太抽象,比如,去地方,做事情,也不是事理图谱中存储的知识。事件间的关系就两种,一种顺承关系,吃饭,买单,离开餐馆,这就是很常见的事件顺承关系。还有就是因果关系,我们认为因果关系是非常重要的,只有因果关系建立了,才能通过控制因变量去影响结果。

事理图谱有3种典型的拓扑结构, 第一种是链状,顺承关系为典型代表。第二种是树状,这其中有一种事件是心理事件,打算去做某事,并不是真做了;第三种是环状,以打架报复住院为例,循环往复。



事理图谱国内外相关工作
与事理图谱最相关的两个研究方向是统计脚本学习和事件关系识别。统计脚本学习是与事理图谱非常接近的一个研究领域。1975年,美国学者Schank提出脚本概念;2003年,日本学者提出自动获取脚本的方法;2008年,Dan Jurafsky利用无监督的方法构建事件链,成为该方向一个具有代表性的先驱工作。2014至今,统计脚本相关研究工作进入了复苏和发展阶段。

除此之外,还有一条技术路线是事件间关系(时序和因果)识别。


哈工大主要在两个领域进行了事理图谱探索性的工作,一方面是出行领域事理图谱的构建和应用;另一方面是金融领域事理图谱的构建和应用。

出行事理图谱的潜在应用


出行领域更多是顺承关系,其构建过程包括数据清洗、NLP预处理、事件抽取和泛化、生成候选事件对、顺承关系识别、顺承方向识别。
第二个是金融领域事理图谱。


可将金融领域事理图谱应用于股市预测当中。

从知识图谱到事理图谱的总结
刘挺教授的总结:知识图谱在各个领域精耕细作,逐渐显露价值,但知识表示形式有待突破,推理能力有待提高。统计脚本学习和事件关系识别等事理图谱相关研究越来越吸引研究者的关注。以“谓词性短语”为节点,以事件演化(顺承、因果)为边的事理图谱方兴未艾。事理图谱必将在预测、对话等领域发挥重要作用,有力地提升人工智能系统的可解释性。
最后刘挺教授向他的合作者,哈工大社会计算与信息检索研究中心的秦兵教授、刘铭副教授、丁效老师,以及博士生赵森栋、李忠阳、姜天文表示感谢。
以上内容为刘挺教授在CNCC 2017 [ 知识图谱遇见社交媒体 ] 论坛上的精彩报告,雷锋网获其独家授权整理。
原创文章,未经授权禁止转载。详情见 转载须知 。



明嘉靖四十三年,在北京城西南取“安定、安宁”之祥意,建右安门,以护城市的安康。建国初期,彭真市长亲临右安门外,规划始建北京第二传染病医院,其建筑规模与学科设置均为亚洲之首。1989年更名为北京佑安医院。首都医科大学附属北京佑安医院是一家以感染、传染及急、慢性相关性疾病群体为主要服务对象和重点学科,集预防、医疗、保健、康复为一体的大型综合性医学中心。

hao123是汇集全网优质网址及资源的中文上网导航。及时收录影视、音乐、小说、游戏等分类的网址和内容,让您的网络生活更简单精彩。上网,从hao123开始。

苏州贝斯特叉车有限公司是专业从事防暴叉车,防爆搬运车,防爆堆高车,防爆牵引车,电动堆高车,电动叉车等仓储物流搬运的堆高车定制厂家.公司全体员工诚挚欢迎海内外朋友光临我公司增进友谊,洽谈业务,我们愿与您一起共创辉煌的未来

豫西紧定套官网

深圳市山嵘电子有限公司专业生产销售CBB电容。我们的CBB电容价格非常有优势。严谨的品质把控,CBB电容牌子就选山嵘电子。

运筹网络是面向虚拟数字产品行业的一站式充值平台。经营业务覆盖了视频会员、生活服务、游戏道具、文娱会员、食品生鲜、知识教育、兑换卷卡、音乐会员、阅读教育、游戏加速器、生活票务、游戏点卡、会员业务等所有虚拟类产品,我们致力于打造全国最受尊敬的数字产业系统类型团队,打造全国最受尊敬的数字产业服务平台

昆山泰仕通精密电子科技有限公司成立于2013年,同年全资收购成立于2010年的昆山宏达精密电子有限公司,生产工厂位于江苏省昆山市环庆路2588号,在台北及深圳设有营业处,主要经营项目有冲压件,注塑件,连接器,FPC/FFC排线。服务于消费类电子、电工电器、新能源、汽车等产业客戶,产品全部符合欧盟RoHS/REACH及GP绿色环保要求。

东位信息专注GPS定位系统、GPS定位器,主营GPSBD北斗卫星定位监控系统高并发、稳定可靠、可扩展性强、易维护升级,提供LBS软件各行业一站式解决方案。

湖北优升学堂教育咨询有限公司

音响代理,音响设备实力厂家认准广东长新电子科技有限公司。旗下品牌均镁音响是一家集研发、制造、销售“音响、卡拉OK音响系统、公共广播系统、家庭影院”于一体的综合型音响企业。

哈尔滨鸿腾二手车公司成立于2006年。是哈尔滨音乐广播FM90.9《徐峰侃车》、黑龙江交通广播FM99.8《汽车时代》、哈尔滨人民广播FM90.4《我是老司机》等汽车栏目常年特邀嘉宾单位。与奔驰、宝马、雷克萨斯、一汽大众、上海大众、广汽本田、一汽马自达、长安马自达等多家品牌保持战略合作伙伴关系。是省内著名的二手车经销商。本公司自成立十余年来,一直以诚信铸就口碑、品质铸就辉煌、专业才能永久的服务宗旨,为省内外客户提供过万辆高品质二手车,赢得良好的商誉。在本公司未来的发展中、以媒体为依托,诚信、专业、敬业、客户至上的原则,作为企业的经营理念,为各界人士提供一个可靠放心的交易平台。

火爆休闲食品招商网【6888.TV】汇集了休闲零食、饼干蛋糕、方便速食、罐头食品、进口食品等各类休闲食品代理、招商、加盟、批发信息。休闲食品招商、代理,就上火爆休闲食品招商网【6888.TV】。


短视频行业在当下是非常火热的,因为短视频的兴起带回了好多的短视频软件,在各种各样的短视频软件当中抖音是脱颖而出的,吸引了我们大家都去拍一些短视频,那么,抖音剪辑视频软件哪个好,很多的小伙伴们都想要一款全面的剪辑App,用来帮助我们剪出电影级别的大片,这些剪辑软件也是各式各样的,小伙伴们也不知道该选择哪一个,下面小编就为大家推荐几款好用...。
3个月之前,搜狗地图正式下线,3个月之后,搜狗搜索App停服,现在的搜狗除了输入法能拿得上台面,其他业务好像都没什么声音,不过给人感觉是搜狗搜索都快没了的感觉,自从搜狗并入腾讯生态圈后,QQ浏览器完美继承搜狗搜索,包括bingo的阅读器,在QQ浏览器里一模一样,就是入口比较隐蔽,今年1月,搜狗搜索曾发布公告称,由于公司业务调整,搜狗搜...。

创业哪个项目好,近年来儿童阅读加盟行业持续保持增长状态,主要在于以下几点,·全民阅读、文化自信是大背景,阅读是一个比较好的创业切入口;·9月份新的中小学新教材上线,整本书阅读对孩子的阅读量、阅读能力提出了更高的要求;·AI时代,培养孩子的综合能力成为大趋势,而阅读是其中的重要途径……在这种背景下,以借阅,读书会,研学活动为运营模式的书...。

作者,李梅编辑,陈彩娴尽管唱衰大模型的声音不绝,但无可否认,近年来人工智能领域的重大突破,都离不开大模型的支撑,以近日火热的AIGC为例,语言大模型在理解文本语境与知识推理能力上的突飞猛进,是人工智能跨越单一模态,读懂人类描述的语言、进而生成各色精美图像的基石之一,大模型被诟病之处突出,算力成本与不确定性为最大要点,但与此同时,几乎没...。

cctv22大神级投影控发表于2024,02,29针对自制投影仪模糊的问题,可以尝试以下方法来解决,1.检查投射光线是否太强,减少光线的强度,可以使用窗帘或厚布来降低亮度,2.调整投射距离,投射距离过近或过远都可能导致模糊,适度调整即可,3.检查投影片的质量,劣质的投影片会导致投射效果差,尝试更换新的投影片可以提高投射效果,4.调整角...。

申明,1.以上内容仅代表揭发者自己,不代表黑猫揭发立场,2.未经授权,本平台案例制止任何转载,违者将被清查法律责任,3.黑猫揭发处置揭发不收取任何费用,凡以黑猫揭发名义不要钱的均为混充、诈骗行为,请及时报警并与黑猫官网反应,揭发邮箱heimaotousu@vip.sina.com,4.请大家选用官网渠道处置生产纠纷,不要轻信第三方机构...。

北京时期7月1日2时,法国国民议会选举第一轮投票完结,初步计票结果显示,在首轮投票中,由玛丽娜·勒庞指导的极左翼政党国民联盟取得33%选票,得票率上游;左翼联盟,新人民阵线,取得28.5%选票,排名第二;执政党振兴党及属于马克龙营垒的两边派联盟,在一同,仅取得22%选票,位居第三,第一轮选举计票结果一出,多家外媒报道称这是马克龙执政7...。

宝马作为享誉环球的上流汽车品牌,自1928年推出第一辆BMW汽车以来,不时在环球范畴内自成一家,雷同,宝马的各款车型也备受车迷们的追捧,然而,在宝马的诸多车型中,不同的车型会有不同的性能、性能、温馨度等等,毫无不懂,出口525i无疑是宝马车系中的佼佼者,可谓真正的,宝马,首先,车辆的外观设计方面,出口525i驳回了宝马最新的设计理念...。

百度网盘AI修图是一款强大的图像处理工具,结合了人工智能技术,旨在帮助用户轻松实现高质量的图像修图和美化

模板,模板如何,什么模板,哪些模板,怎么模板

腾讯软件中心提供2023年最新6.90.66官方正式版LogitechSetPoint高速下载,本正式版LogitechSetPoint软件安全认证,免费无插件。

在中国开发和发布移动应用程序需要经过一系列的备案流程首先开发者需要在国家互联网信息办公室进行备案申请包括提供相关证件申请表格和技术方案等信息其次会对申请进行审核和审批确保应用符合相关法规和安全要求最后在备案通过后开发者可以正式上线发布应用进行备案的目的是为了确保应用的合法性和安全性保护用户信息和维护网络环境的健康发展备...

现如今大家的生活节奏都挺快的,爸爸妈妈和孩子们相处的时间少了,陪他们玩耍发现兴趣爱好的机会也不多,不过大家可以通过亲子游戏来促进感情的增长,那么好玩的陪小孩玩的游戏有哪几个,小编为大家收集了几款游戏,这些游戏就像是搭建了一座桥,让大人和小孩的心更贴近,还能悄悄地在玩乐中让孩子们的脑筋转得更快创造力爆棚,1、,JoJo亲子乐园,这个游戏...。
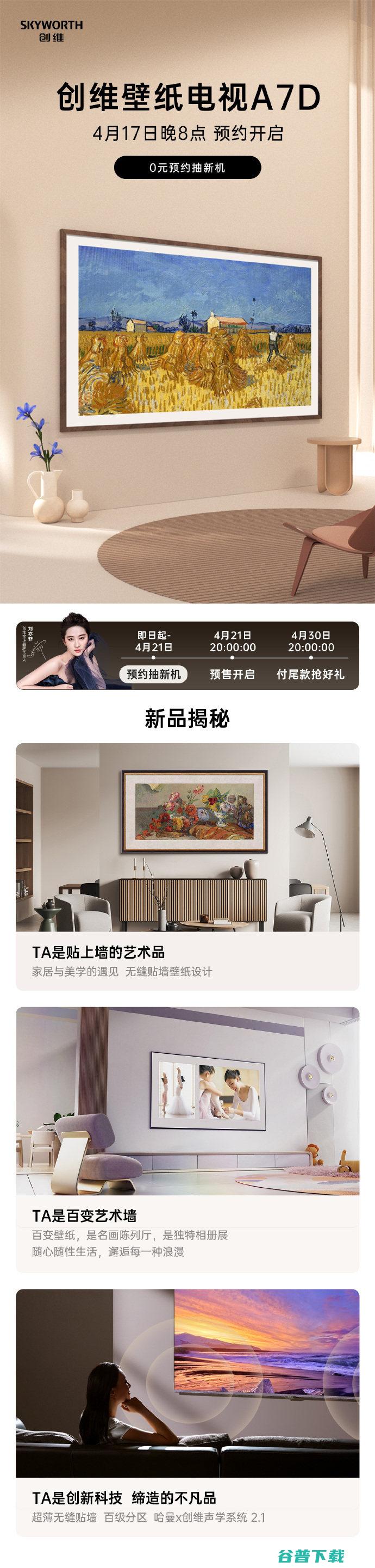
4月17日晚8点,新品创维壁纸电视A7D开启预约,并将于4月21日晚8点预售、4月30日晚8点正式上市,ZNDS智能电视网了解到,创维壁纸电视A7D有65英寸和75英寸两个尺寸,售价预计分别为5999元和7999元,另外根据创维壁纸电视A7D的电商页面显示,创维壁纸电视A7D为4K分辨率,色域97%DCI,P3,刷新率为240Hz,支...。
最近,关注全球科技趋势报道的权威媒体,亚洲科技日报,评出了四大2024下半年最值得期待的全球创新科技大会,美国旧金山的TechCrunch科创大会、日本东京的高新技术博览会、中国上海的Inclusion·外滩大会以及新加坡的金融科技节入选,报道指出,这四个科技大会均位于全球领先的科技创新中心,而且已经成为各自城市科创生态的关键组成部分...。

11月29日,iQOONeo10系列发布,iQOONeo10Pro,天玑9400,6400mm²不锈钢VC均热板,9600MbpsLPDDR5XUltra内存,UFS4.1闪存;6.78英寸144Hz1.5K的8TLTPO中置打孔直屏OLED,维信诺F1基材,2800x1260,452ppi,全白激发1800尼特,局部4500尼特,...。

发表在当贝投影仪2021,6,314,38导读,小明q1投影仪是一款采用了LCD显示技术的千元投影仪,主打迷你轻便,且小巧的个头,吸引了不少消费者关注,而便携式家用投影仪多数也是小巧机身,当贝C2更是一款超有料的小投影,下面就跟着小神童一起来看看小明q1和当贝c2对比哪个好,1、外观对比从外观上来看,小明q1和当贝c2都是微型投影仪,...。
