谷歌搜索也是拼了!为上马神经网络 PhD人工处理数据 百名 (谷歌搜索也是免费的吗)
编者按:近日,谷歌把神经网络算法加入手机端搜索。为了让搜索更智能,谷歌在全世界聘用了百名语言学博士,夜以继日地标注文本数据,来训练神经网络。虽然无监督学习成为热点已有些时日,谷歌还未能摆脱人工处理数据的困境。
Phone.com/uploads/new/article/740_740/201611/583e7f0755255.jpg" src="http://www.gpxz.com/zdmsl_image/article/20241209231630_38558.jpg" loading="lazy">
搜索“世界上最快的鸟是什么?”
谷歌会告诉你:“游隼。根据 Youtube,游隼被记录下最高 389 km/h 的时速。”
这的确是正确答案,但它并非来自于谷歌的数据库。当你输入这个问题的时候,谷歌搜索引擎找出了一个描述世界上五种最快鸟儿的 Youtube 视频。然后它只把最快的“一种”鸟儿的信息提取出来,不提及另外四种。
这是谷歌搜索最新的技术进展。为了回答这些问题,谷歌需要借助深度神经网络。 作为 AI 技术之一,它不仅正在重塑谷歌搜索引擎,还在革新谷歌全套人工智能服务。其它互联网巨头当然也受到波及,例如 Facebook 和微软。
深度神经网络是一种模式识别系统。它能通过分析海量数据,学习如何处理特定任务。这个例子中,它学会了怎么在网络上的长篇文字中找出相关的一句或一段话,然后提取其中的要点呈现给你。
移动端谷歌搜索刚刚上线这种“句子压缩算法”(sentence compression algorithms)。这个对人类来说很简单,但对传统的机器来说很难的任务,终于能被 AI 系统完成。这说明,深度学习正在促进自然语言理解这门艺术(理解并回应人类语言)的发展。
为了训练神经网络算法,谷歌在全世界聘用了约百名语言学博士处理数据,对它们人工筛选。 事实上,谷歌的系统是从人类那里学习,怎么在大段文字中提取有用信息。而这过程需要一遍遍地重复——这是深度学习一个很大的限制。雇佣大批语言学家不停地筛选数据既麻烦又极其昂贵,但短期内谷歌没有别的办法。

谷歌也使用过期的新闻来训练 AI 问答系统。这使 AI 逐渐理解,新闻标题是如何对文章主体进行归纳的。但这并不意味着谷歌不需要成批语言学家了。他们不仅示范句子压缩,还要对语句的不同部分做标记,以帮助神经网络理解人类语言是如何工作的。David Orr 把谷歌语言学家团队处理的数据称为“黄金数据”,过期新闻则是“白银数据”。“白银数据”作用不小,因为它的体量很大。但价值最大的还是“黄金数据”,它们是 AI 训练的核心。语言学家团队的负责人 Linne Ha 透露,在可见的将来,语言学家队伍仍会继续扩大。

这类需要人工辅助的 AI 学习便是“监督学习”(supervised learning),目前,神经网络都是这么运作的。 有时候公司会把这个业务进行众包,有时候它会自发地进行。比方说,全世界的网民已经为数百万的猫咪照片添加了“猫咪”标签,这会让神经网络学习识别猫咪变得很简单——训练数据已经处理好了。但很多情况下,研究人员们别无选择,只能自己一次次为数据添加标签。
深度学习初创公司Skymind 的创始人 Chris Nicholson 认为, 长远来看,人工标注数据是不可行的。 他说:“将来一定不会是这样。这是极度枯燥的活儿。我想不出比这更无聊的 PhD 工作了。”
监督学习的缺陷远不止如此: 除非谷歌聘请所有语言的语言学家,否则这个系统无法在其他语言中运转。 现在,语言学家团队的工作横跨了 20 至 30 种语言。谷歌必须在将来的某一天,采取更自动化的 AI 训练方式,即“无监督学习”(unsupervised learning)。
到了那时,机器将能够从未经人工标注的数据中学习。互联网上海量的数字信息可以被直接用于神经网络学习。 Google、Facebook 和 OpenAI这样的巨头们已经开始这个领域的研究,但它的实际应用仍然非常遥远。现在,AI 学习仍然需要幕后的大批语言学家队伍。
【招聘】雷锋网坚持在人工智能、无人驾驶、VR/AR、Fintech、未来医疗等领域第一时间提供海外科技动态与资讯。我们需要若干关注国际新闻、具有一定的科技新闻选题能力,翻译及写作能力优良的外翻编辑加入。工作地点深圳。简历投递至 guoyixin@leiphone.com 。兼职及实习均可。
Facebook Yann LeCun一小时演讲: AI 研究的下一站是无监督学习(附完整视频)
专访 Jeff Dean丨谷歌战神谈增强学习和无监督学习
AI 黑箱难题怎么破?基于神经网络模型的算法使机器学习透明化
回顾Google神经网络机器翻译上线历程 | 深度
原创文章,未经授权禁止转载。详情见 转载须知 。



加盟费是所有加盟者最关心的地方,每个加盟者都有权利知道加盟费的具体内容和金额。加盟费查询网,给你超详细的加盟费用清单,让你知道每一笔费用的具体金额。

开沙岛旅游度假区位于南通市通州区五接镇境内,是长江入海口溯江而上江苏段第一个江中小岛,万里长江中的一颗“绿色明珠”。被评为国家森林乡村、全国特色景观旅游名村、江苏最具魅力休闲乡村、特色田园乡村、江苏文明村等多项国家省级品牌和荣誉。开沙岛是一个集观光旅游、休闲度假、户外运动、康疗养生一体的知名旅游度假首选目的地。

佳木斯防爆电机有限公司是防爆电机、防爆电器制造的专业公司.我公司专业生产佳木斯防爆电机,佳电电机,粉尘电机,节能电机,是佳木斯电机源头厂家,欢迎来电咨询:13114549456

纵横软件公司专注工程软件、工程培训、工程造价事业,以“加班少一点胜算多一点”为追求,专业从事工程软件、工程培训、工程造价三大领域相关业务的开展。面向政府行政机关、行业主管部门、项目投资业主、设计、施工、建设、管理、养护、审计、审核、财审、监理、咨询、学校等客户提供优质的产品和服务。产品广泛应用于建筑、公路、市政、轨道、安装、园林、装饰、水利等行业领域。

河南吉宏机械_专业的辊式破碎,制砂设备生产厂家,30年品牌保证,生产的对辊式制砂机,四辊破碎机,双齿辊破碎机,强力分级破碎机等设备畅销国内外,查看实物图片,型号齐全,价格咨询:0371-64087888
")
恩施土家族苗族自治州企业联合会(企业家协会)官方网站,今点(www.day.net.cn)打造!

徐州特电电气有限公司专业提供TBB系列高压电容柜倒送电负载箱租赁电容器租赁负载设备35KV电容柜消弧消谐柜高压电抗器起动柜置等产品,我们致力于为客户创造价值。如需技术、购买咨询热线:18020595666

深圳市如新电子有限公司创立于2009年,是一家集研发生产和销售为一体的国家高新技术企业.专注于长条形液晶屏,条形屏广告机,货架条形屏,高亮液晶屏,户外高亮显示屏,工控屏.支持尺寸亮度定制,咨询热线:15014144192.

上海铭控传感技术有限公司是专业的智慧消防消火栓,地下智能消火栓,无线消防压力表供应商,主营产品有:智慧消防消火栓,地下智能消火栓,无线消防压力表等,上海铭控传感技术有限公司不仅具有专业的技术水平,更有良好的售后服务和优质的解决方案,欢迎来电洽谈

腾讯微保(TencentWeSure)是腾讯官方保险代理平台。腾讯微保成立于2017年11月,携手国内知名保险公司,为用户提供专业、便捷的保险服务,致力于成为用户微信服务里的保险帮手,让用户可以在微信服务里获取保险选购及理赔服务。

盛世昌华仪表有限公司是集燃气表工厂、智能燃气表、NB-IoT燃气表、IC卡表、煤气表、沼气表、远传表、RS485脉冲表、工商业大口径燃气表、燃气流量计等研发生产的高新技术工厂!燃气表已出口俄罗斯及东南亚等多个国家和地区。


万殿壹煲酸菜鱼米饭开店怎么样,万殿壹煲酸菜鱼米饭它选自好的原生态深海龙利鱼,高蛋白、低脂肪,老少皆宜,四季创收,是一个深受欢迎的好项目,看懂商机就行动起来加盟吧,万殿壹煲酸菜鱼米饭严格把控食材品质及制作工艺,制成的酸菜鱼肉质细嫩,汤酸鲜美,口感令人回味,时尚的品牌形象、舒适的格调氛围,符合现代消费群体审美需求,万殿壹煲致力于打造出立体...。

雷锋网按,2018年10月11日,纪念集成电路发明60周年学术会议于北京清华大学召开,中国科学院院士王阳元、中国工程院院士许居衍、清华大学教授魏少军等国内半导体行业顶级专业人士纷纷在会上发表了报告或演讲,其中,Intel中国研究院院长宋继强题为,智能时代的芯片技术演进,的演讲回顾并分析了摩尔定律在60年里的演进,并分析了神经拟态芯片和...。

巴菲特遭50亿巨额诈骗,对方通过PS捏造47笔商业交易据外媒报道,近日,一家德国名为威廉·舒尔茨,WilhelhelSchulz,的制造公司正在接受欺诈调查,原因是其在被巴菲特旗下伯克希尔哈撒韦收购期间涉嫌造假,需赔付差额6.43亿欧元,约合人民币50亿元,据悉,该公司创建假的订单和发票,从而夸大公司的收益,至少有47笔商业交易是完...。

雷锋网消息,成立不到一年的国内EDA,电子设计自动化,智能软件和系统公司芯华章今天正式推出支持国产计算架构的全新仿真技术,以及成本最多能节省4倍的高性能多功能可编程适配解决方案,全新仿真产品已经在国产飞腾服务器上通过验证,能兼容当前产业生态,全新仿真技术支持主流处理器架构EDA是帮助芯片设计人员利用计算机辅助设计,CAD,软件来完成超...。
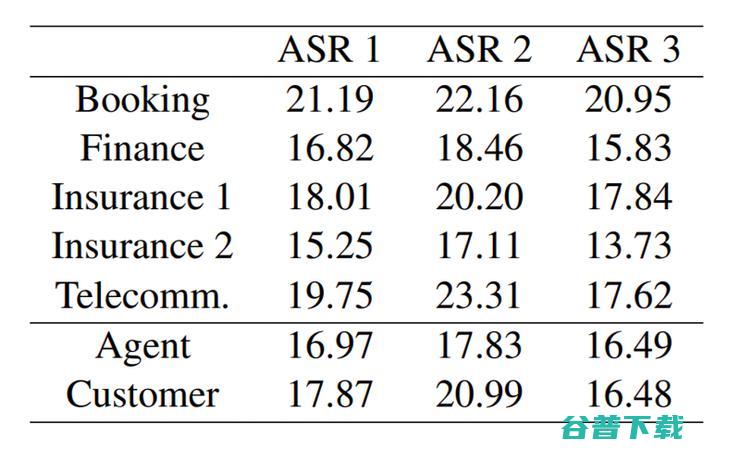
雷锋网讯,,某些语音识别系统,ASR,的准确性可能要比之前假定的差很多,这是最近约翰·霍普金斯大学、波兰波兹南工业大学、弗罗茨瓦夫科技大学以及初创公司Avaya的研究人员一项正在进行的研究主要发现,这项研究对内部创建的数据集上的商业语音识别模型进行了基准测试,共同作者声称,词错误率,WordErrorRate,WER,一种常见的语...。

用微信扫码二维码分享至好友和好友圈...。

手刹的上班原理是,机械式手刹,经过钢丝或许相似机构联动后轮的刹车卡钳,拉起手刹后,卡钳压住刹车片,从而成功驻车的性能电子式手刹,经过开启驻车开关,电机驱动钢丝或许相似机构联动后轮的刹车卡钳,经过卡钳压紧刹车片成功驻车性能,新胜达2点7手刹分制动原理手刹是车辆刹车系统中极端关键的组成局部,正确经常使用手刹可以有效防止溜车,缩小了停车时溜...。

2017年立春详细期间公历,阳历,2017年2月3日23时34分01秒立春的习俗1、祭句芒神句芒为春神,即草木神和生命神,句芒的笼统是人面鸟身,执规矩,主春事,2、咬春北边吃的食品是春饼,而南边则盛行吃春卷,吃春饼和春卷,是人们对,一年之计在于春,的美妙祝愿,值得一提的是,立春这一日,中国民间,咬春,的另外一种食品是萝卜,比拟广泛的...。

焯是什么梗?最近肯定有很多小伙伴在网上见过这个梗,但是肯定有些不知道这个梗的小伙伴看到后一头雾水,完全不知道是什么意思。下面小编给大家带来焯小丑是什么意思,感兴趣的小伙伴们一起看看吧。焯是什么梗【梗的意思】【焯】的读音是chao,是爆粗口操的另一种说法,也就是谐音梗。【梗的出处】【焯】这个梗出自B站up主哥谭噩梦赫然(抖音也是)他做了一系

2021第十届中国国际大学生微电影盛典作品征集 报送参赛作品截止时间:2021年9月15日 各大专院校在校学生、研究生,以及各影视机构工作人员、独立制作人、国内外视频拍摄爱好

重庆分类目录网站将2011年05月共222个网站收录信息按收录时间分类整理归档列表,可以方便网友浏览按年月查询,更好地享受精彩网站的魅力!

人工智能软件的出现,让人们的生活变得丰富多彩,也给人们带来更多的好处,这些软件可提高工作效率及日常的生活品质,通过自动化方式,帮助用户高效完成工作,那么人工智能软件有哪些呢,人工智能的出现促进了社会的发展,促进公共服务更加便捷,接下来小编推荐几款热门人工智能app,运动计步软件属于专业的计步助手,专注于跑步骑行记录,其中具有大数据,另...。

在社群里面经常看到有小白在寻找项目,购买项目而被割韭菜,我是不推荐小白去购买项目的,小白有时候无法甄别一个项目的好坏与否,可能很多项目的收益并不能弥补购买价格,而且小白缺少的不一定是所谓的项目,1.镰刀遍地如今内卷的情况下,很多人为了盈利是不择手段的,包装,宣传,吹捧,为的就是吸引小白,出售项目,收割韭菜,获得利益,1.1项目镰刀前一...。

雷锋网消息,2020年3月9日,聚芯微电子正式发布国内首颗自主研发、背照式、高分辨率、用于3D成像的飞行时间,Time,of,Flight,ToF,传感器芯片SIF2310,该产品原计划在今年巴塞罗那世界移动通信大会现场发布,但因疫情影响,今年巴展停办,聚芯微电子选择进行线上发布,ToF技术是目前被广泛看好的3D成像技术,实现了从成像...。

雷锋网消息,据外媒报道,机器人制造商波士顿动力公司周四宣布,其四足的Spot机器人已经在波士顿的一家医院使用,以帮助治疗冠状病毒,该公司计划扩大其机器人的使用范围,以便在新冠疫情期间为医护人员提供帮助,同时,该公司还开放了其使用的硬件和软件,以便其他医院和机器人制造商可以效仿,自上周以来,哈佛大学布莱根妇女医院一直在使用Spot对新冠...。

现在父母对孩子的各方面都十分注重,无论是学习,还是玩乐,都会较大的程度去满足孩子的需求,所以机器人乐园就成为孩子们喜爱的地方,也在市场的大力支持,得到快速地发展,很多品牌不断地涌现,其中就有机灵小匠这个品牌,它的出现,给孩子们带去更多的玩乐设备,也获得孩子的们喜爱,所以在消费者的大力支持下,就取得不错的成绩,但现在还是有人非常的好奇,...。
