Graviton两年内为AWS提供超过50%的CPU算力 打破英特尔对市场节奏的掌控 (gravitational)
在超大规模和云计算厂商规模较小、ARM未能抢占数据中心市场以及AMD尚未走上复兴之路的时候,英特尔掌控着新计算引擎进入数据中心的节奏。
局势总是在变化。本周,英特尔的CEO帕特.基辛格(Pat Gelsinger)宣布离职,相比之下,亚马逊云科技(AWS)在拉斯维加斯举办年度re:Invent大会,线下参会人数达到6万,而线上人数高度40万人。谁在控制超大规模企业和云计算制造商的技术推出步伐,似乎有了新的答案。
对于AWS而言,他们也可以控制新技术的发布节奏,因为他们不需要像芯片厂商一样,进行定期的产品迭代。他们不需要像英特尔、AMD和英伟达那样,把计算引擎卖给ODM和OEM,而是直接向客户出售云上产品。显而易见的是,这是一项更容易的业务。
在re:Invent大会上,AWS以及其母公司亚马逊高管所带来的演讲,让外界对于他们的计算引擎有了新的期待,比如Graviton5、Inferentia3及Trainium3。

Trainium3使用3nm工艺蚀刻,相较于Trainium2能效提高40%、性能翻倍。AWS的新闻稿中表示,Trainium3 UltraServers的性能将是Trainium2 UltraServers的4倍,这意味着它们将从使用Trainium2的16台设备扩展到使用Trainium3的32台设备。
AWS CEO马特.加曼(Matt Garman)称,Trainium3将于2025年晚些时候推出,这意味着大概会在re:Invent 2025年会议发布这款产品。早在6月份,就有一些关于AWS高管确认Trainium3将突破1000瓦的传言,但这点并不出乎外界的意料,英伟达的Blackwell B200 GPU的峰值功率是1200瓦。
真正出乎外界意料的是,在上个月的SC24超级计算会议上,针对HPC应用的Graviton4E仍未推出,这与AWS在2021年11月推出的普通Graviton3和2022年11月推出的增强版Graviton3E的过往速度相比有所差异。2023年11月发布的Graviton4可以说是市场上基于Arm架构最好的服务器cpu之一,当然也是适用面最广的CPU。
AWS的CPU、人工智能加速器和DPU没有任何年度更新的压力,如果仔细观察英伟达和AMD的GPU路线图,就会发现他们的核心产品仍然是每两年发布一次,第二年会在第一年发布的GPU上进行内存升级或性能调整。
AWS在芯片领域的迭代周期大概是两年,其间会有一些波动。Graviton1实际上是一个基于Nitro架构的DPU卡,可以忽略不计。正如AWS公用事业计算高级副总裁彼得.德桑蒂斯(Peter DeSantis)在2018年发布的主题演讲中所说的,Graviton1只是“进入市场的一个信号”,主要用于验证客户需求。2019年推出的Graviton2, AWS采用了台积电的现代7纳米工艺,并使用了Arm的Ares N1内核,设计了一款64核CPU,与运行在AWS云上的英特尔和AMD的X86 CPU相比,性价比高出40%。
2021年,采用Arm Zeus V1内核的Graviton3问世,同样是64个内核却可以承担更多的任务。2023年,Graviton4问世了,这款芯片采用了台积电4纳米工艺,在插槽上塞入96个Demeter V2内核,与12个内存带宽为537.6 GB/秒的DDR5内存控制器搭配使用。与Graviton3相比,Graviton4的单核性能提高了30%,内核数量增加了50%,性能提高了2倍。根据我们的定价分析,产品的性价比提高了13%到15%。在实际的基准测试中,Graviton4带来的性能优化有时能达到40%。
AWS处理器投入的资金至少需要两年才可以收回。因此,在re:Invent大会上期待任何关于Graviton5的新消息都是不现实的。尽管如此,AWS的高管们还是会吊一下市场的胃口。
AWS的高管在主题演讲中提供了一些关于Graviton的数据。AWS计算和网络服务副总裁戴夫.布朗(Dave Brown)展示了这张图表,它在一定程度上解释了为什么英特尔最近几个季度的财务状况如此糟糕。粗略地说,AWS的四项核心服务(Redshift Serverless和Aurora数据库、Kafka的Managed Streaming和ElastiCache搜索)大约有一半的处理是在Graviton上运行的。

布朗称:“最近,我们达到了一个重要的里程碑,在过去的两年里,我们数据中心超过50%的CPU算力都来自Graviton,这比其他所有类型的处理器加起来还要多。”
这正是微软多年前所声称想做成的事情,而这也是AWS所期待达成的目标。从长远来看,X86是一种传统的平台,其价格也是传统的,就像之前的大型计算机和RISC/UniX。RISC-V也许最终也会这样颠覆Arm架构(开源的ISA与可组合的模块似乎是必由之路,就像linux开源系统让windows Server变成传统平台的)。
加曼让我们对AWS内部的Graviton服务器群规模有了一个大致的了解:“Graviton正在疯狂地增长,2019年,整个AWS的业务规模为350亿美元,而现在,单单Graviton运行的业务规模就与2019年整个AWS业务规模一样,这是非常快的增长。”可以估计的是,Graviton服务器集群的增长速度比AWS整体业务的增长速度还要快,而且幅度可能非常大。这对英特尔的伤害远大于对AMD的伤害,因为AMD多年来一直拥有比英特尔更好的X86服务器CPU。
Trainium系列,是否会成为英伟达和AMD之外的选择?
加曼谈论Trainium3的唯一原因是,人工智能训练对高性能计算的需求增长得比任何其他计算引擎快得多。面对英伟达在2025年加大其Blackwell B100和B200 GPU的产能,以及AMD扩大其Antares MI300系列,AWS如果想让客户将他们的人工智能工作负载移植到Trainium上,就必须在市场上展现出大力推行Trainium系列的决心。
在明年的re:Invent大会之前,希望能够看到AWS发布关于Trainium3的一些新优化,因为市场上的竞争对手太多,以谷歌和微软为首的一些公司将在2025年推出他们旗下的人工智能加速器。
就像Graviton系列一样,从现在开始,Trainium系列的更新周期或许将变为两年一更新。这些产品的研发投入都非常高昂,因此AWS要实现财务效益必须将Trainium的开发成本摊销到尽可能多的设备上。与Graviton一样,我们认为AWS的Trainium达成这一目标的日子不会太遥远。从长远来看,这对英伟达和AMD来说不是好事,特别是如果谷歌、微软、腾讯、百度和阿里巴巴都采取同样的行动。
AWS还没有愚蠢到试图在GPU加速器市场上与英伟达直面抗衡,但与谷歌的TPU、SambaNova的RDU、Groq 的 GroqChip和Graphcore的IPU一样,这家云计算商同样认为自己可以构建一个系统阵列来进行人工智能训练和推理,并为云计算客户带来差异化体验和附加值产品,与购买英伟达相比,客户购买AWS的产品可以节省成本并且掌握更多的主动权。
正如我们上面所指出的,AWS高管对Trainium3并没有透露太多的信息,但他们对Trainium2在UltraServer中的使用到非常兴奋。
今年的re:Invent大会上,AWS更多地介绍了使用Trainium2加速器的系统架构,并展示了基于这些加速器构建的网络硬件,以扩展和扩展其人工智能集群。下面是德桑蒂斯展示的Trainium2:

正如我们去年报道的那样,Trainium2似乎在单个封装上放置两个芯片互连,可能使用NeuronLink die-to-die内部互连技术,以在其共享的HBM存储器上一致地工作。Trainium2服务器有一个节点,该节点带有一对主机处理器并与三个Nitro DPU相连,如下所示:

这是计算节点的俯视图,前端有四个Nitros,后端有两个Trainium2s,采用无线设计以加快部署速度。

两个交换机托架,一个主机托架和八个计算托架组成了一台Trainium2服务器,该服务器使用2TB/秒的NeuronLink电缆将16个Tranium2芯片互连成2D环面配置,每个设备上96GB的HBM3主内存都会与其他设备共享。每台Trainium2服务器具有1.5TB的HBM3内存,总内存带宽为46TB/秒(即每个Trainium2卡略低于3TB/秒)。此节点在密集FP8(一种浮点数表示格式)数据上的性能为20.8千万亿次浮点运算,在稀疏FP8数据上的性能为83.3千万亿次浮点运算。
AWS将四台服务器相互连接以搭建Trainium2 UltraServer,该服务器在64个AI加速器中拥有6TB的HBM3内存容量,内存带宽总计为184TB/秒。该服务器具有12.8Tb/秒的以太网带宽,可使用EFAv3适配器进行互连。UltraServer服务器在密集FP8数据上的运算速度为83.2千万亿次浮点运算,在稀疏FP8数据上的运算速度为332.8千万亿次浮点运算。下面是德桑蒂斯对Trn2 UltraServer实例硬件的展示:

在布满电线的机架顶部,隐藏着一对交换机,它们组成了3.2TB/秒的EFAv3以太网网络的端点,该网络将多个Tranium2服务器相互连接,以创建UltraServer服务器,并将服务器与外部世界连接。

这还不是整个网络架构。如果你想运行大规模的基础模型,需要的加速器将远远不止64个。为了将成千上万的加速器连接在一起,可以进行大规模训练,AWS设计了一种基于以太网的网络结构,名为10p10u,其目标是在延迟不到10微秒的情况下,为整个网络提供每秒数十PB的带宽。下面是10p10u网络结构机架的样子:

由于原先服务器内部的电线非常复杂,AWS研发了一款光纤主干电缆,将需要使用的电线数量压缩为原先的十六分之一。其原理是将数百个光纤连接放在一条较粗的管线中,这样做的好处是让服务器内部的架构更为简洁。如下图所示,右边的机架使用的是光纤主干电缆,它更简洁小巧。更少的连接和线路管理意味着更少的错误,当你试图快速构建人工智能基础设施时,这一点很重要。

据悉,这种专门用于人工智能工作负载的10u10p网络由于其优异的表现正在被大规模采用。德桑蒂斯展示了它与AWS创建的老式以太网网络相比的增长速度有多快:

假设这是累积链接数(有效的计算),旧的Euclid网络结构(大概是100Gb/秒)在四年内逐渐增加到近 150 万个端口。名为One Fabric的网络与10u10p网络在2022年年中大致同时推出,我们猜测其中One Fabric使用400Gb/秒以太网,而10u10p基于800Gb/秒以太网。One Fabric有大约100万个链接,而10u10p有大约330万个链接。
加曼表示,与基于AWS云上的GPU实例相比,Trn2实例的性价比将提高30%到40%。当然,AWS应该加大拉开外部计算引擎与自家计算引擎之间的差距,保持这样的差距是Trainium抢占人工智能计算器市场的正确举措。
作为主题演讲的一部分,德桑蒂斯和加曼都谈到了一个代号为“Project Ranier”的超级集群,这是AWS正在为其人工智能大模型合作伙伴Anthropic建造的一个超级集群。截至目前,亚马逊已向Anthropic投资80亿美元,该集群主要用于训练下一代Claude 4基础模型。加曼说,“Project Ranier”将拥有数十万个Trainium2芯片,其性能将是训练Claude 3模型时所用机器的5倍。
本文由编译自:
原创文章,未经授权禁止转载。详情见 转载须知 。


湖北网站排名,根据网站的综合值按照不同的湖北网站进行筛选排名结果,通过筛选湖北网站可以看到每个湖北网站里面的网站排名优质的网站是哪些

东莞蔬菜配送,联系电话【13480411888苏先生】,是一家专业食材配送公司,东莞蔬菜配送公司欢迎您实地考察,东莞蔬菜配送中心做得好不好,实地考察才知道,配送品种包括蔬菜、肉类、粮油、干货、调味品等,欢迎来电咨询。

七目评选是专业的网络评选设计制作平台,免费提供文字投票、图文投票、音频投票、视频投票等微信投票活动创建方案。安全性好,稳定性高,可防止刷票,保证活动结果的公平公正。

中计研技术有限公司

四川斯坦福电力设备有限公司专业从事发电机的销售,租赁和维修,咨询电话:028-81463192,欢迎大家来电咨询有关四川柴油发电机组,四川发电机,,四川厂用大功率发电机,绵阳附近发电机四川发电机组的相关详情.

JOOH是专业提供免费网站计数器、网站统计、计数器、流量统计、在线人数统、网页计数器代码、网页统计源码的数据统计平台www.jooh.cn

内蒙古维泰建设有限责任公司成立于1999年05月,现注册资本金4500万元,法定代表人郭景诚,公司现有高级职称人员11人,中级职称人员10人,一级建造师3人,二级建造师30人,截止目前共完成各类大中型工业与民用建筑工程近百项,竣工工程一次交验合格率达100%。品质源于专业,专业铸就精品,内蒙古维泰建设有限责任公司在未来岁月的征程里定会始终以“一流的管理、一流的技术、一流的质量、一流的速度、一流的服务”为业主奉献更多的精品工程。

佛山市尚成夹芯板有限公司专注于夹芯板,泡沫夹芯板,玻镁夹芯板,岩棉夹芯板,彩钢夹芯板,百级净化板,泡沫彩钢板,彩钢复合板,无机预涂板,净化玻镁板等专业净化板材,产品远销澳洲,欧州,美州,中东地区......

北京服务器托管,机柜租用,大带宽租用,高电机柜租用,北京4U服务器托管,北京高电数据中心,北京IDC机房,北京IDC机房托管,北京服务器托管价格,北京整机柜租用电量,北京整机柜租用价格

重庆作为西部地区唯一的直辖市和国家级中心城市,长江上游的经济中心,位于西南交通枢纽,旅游资源丰富。近年来重庆旅游业发展可谓突飞猛进。 世界旅游及旅行理事会(WTTC)2017年11月最新发布的数据显示,全球发展最快的10个旅游城市全部在亚洲。

苏州方圆仪器设备校准检测服务有限公司是一家提供计量设备仪器校准服务的检测校准机构.多年行业经验,服务响应快,费用合理,流程透明,服务周到.咨询热线:17315817690.

成都沙盘模型公司,成都沙盘公司电话19981014812,沙盘模型,沙盘公司,沙盘模型公司,沙盘模型设计,沙盘模型制作,沙盘模型定制,沙盘模型厂家,成都沙盘模型制作,成都沙盘制作,地产沙盘,规划沙盘,厂区沙盘,电子沙盘,地形沙盘,数字沙盘模型,建筑沙盘模型,机械设备模型,军事沙盘模型,工业机械模型。


因为外观,耐用性,性能,屏幕,外放,摄像头等各个维度,都非常适合校园和职场用户,惠普星BookPro系列向来是各种笔记本榜单中的常客,它在今年双十一期间,甚至一度全网卖断货,而接下来的双十二,叠加2024年国补末班车的影响,预计到时还会有好价,我们这次就和大家看看,为什么大家会推荐英特尔Evo™版的惠普星BookPro14AI轻薄战力...。

因为外观,耐用性,性能,屏幕,外放,摄像头等各个维度,都非常适合校园和职场用户,惠普星BookPro系列向来是各种笔记本榜单中的常客,它在今年双十一期间,甚至一度全网卖断货,而接下来的双十二,叠加2024年国补末班车的影响,预计到时还会有好价,我们这次就和大家看看,为什么大家会推荐英特尔Evo™版的惠普星BookPro14AI轻薄战力...。
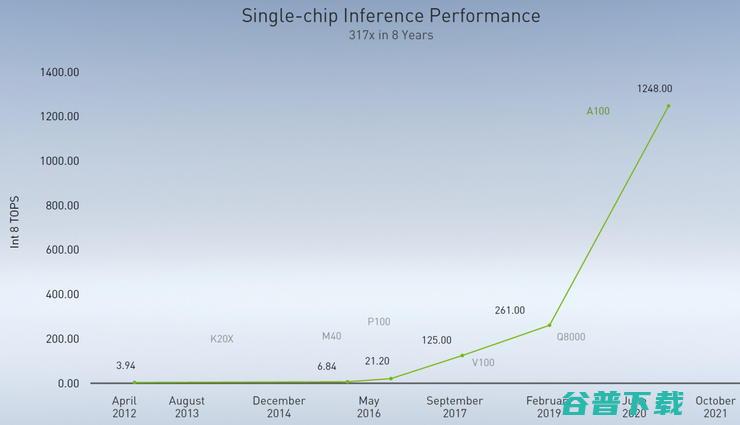
1965年,时任仙童半导体公司工程师,也是后来英特尔的创始人之一的戈登·摩尔,GordonMoore,提出了摩尔定律,Mooreslaw,,预测集成电路上可以容纳的晶体管数目大约每经过24个月便会增加一倍,后来广为人知的每18个月芯片性能将提高一倍的说法是由英特尔CEO大卫·豪斯,DavidHouse,提出,过去的半个多世纪,半导体行...。

前乐视网CEO梁军参观FF会面贾跃亭,不后悔在乐视的六年7月25日,前乐视网CEO梁军今日发布微博称,,时隔两年,再次有机会去参观FF,,并与贾跃亭会面,他表示不后悔在乐视的六年,从乐视和贾跃亭身上学到了很多东西,并祝愿FF能成功,贾跃亭能够东山再起,梁军微博信息显示,其现为新视家科技CEO,据一财报道,在乐视内部,乐视创始人贾跃亭曾...。

雷锋网按,随着AMD再次与英特尔在服务器市场竞争,服务器芯片市场50%的运营利润率的时代已经结束,另外,IBM的Power服务器、Arm服务器,还有潜力巨大的RISC,V架构芯片都努力瓜分x86架构服务器市场的份额,只是,除非英特尔和AMD的服务器销售出现重大问题,非x86服务器可能很难获得巨大的成功,但无论如何,这一市场未来将不会无...。
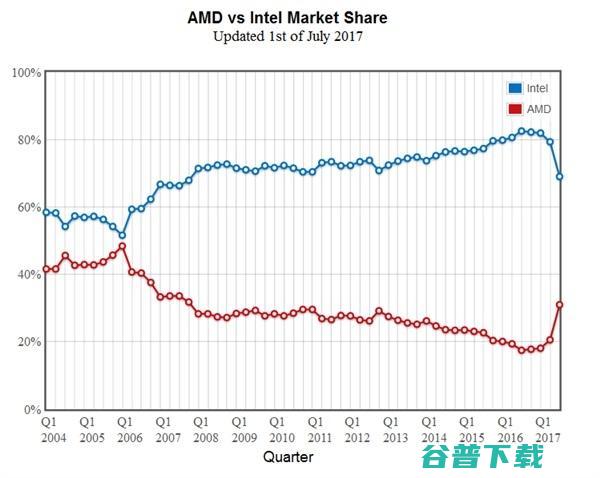
雷锋网消息,根据PassMark最新公布的全球CPU市场份额对比,截至7月1日,也就是刚刚开始的2017年第三季度,AMD凭借最新产品Ryzen系列处理器的强势表现,市场份额一度大涨至31%,但随着7月2日数据更新,这一数字又回落至23.9%,我们知道,AMD长期以来在CPU领域一直被英特尔压着打,市场份额更是遥遥落后,不过,随着近几...。
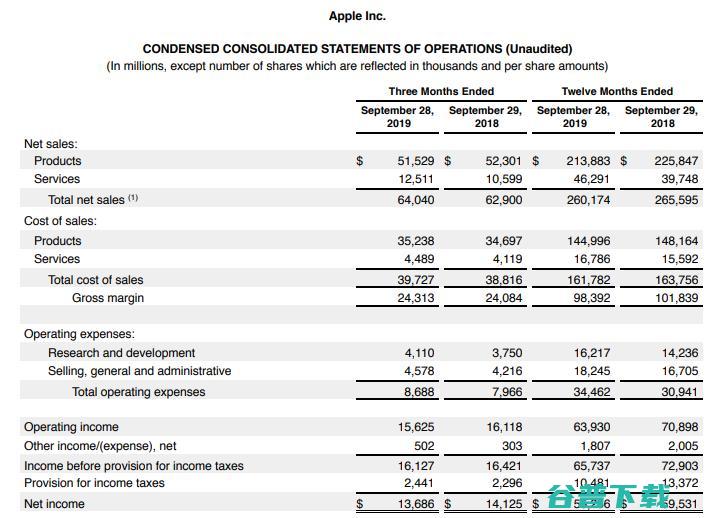
如同往常一样,在微软、亚马逊、Google陆续公布财报之后,苹果截至2019年9月28日的Q4财季财报才赶在10月30日姗姗来迟,雷锋网按,财季不同于自然季,这份财报的营收超出市场预期,财报一经公布,苹果的股价就在盘后交易中上涨了近2%,市值稳在万亿美元之上,苹果CEOTimCook也声称,,这是苹果公司有史以来营收最高的Q4财季,...。

这一周的自动驾驶圈,乐视再一次因为,钱,的事儿站在舆论的风口浪尖,谷歌和亚马逊继续用专利宣誓着自己的行业主导权,特斯拉终于光明正大地摆脱了半年前的死亡事故阴影……春节将至,但智驾圈的故事还在继续,雷锋网带你一起回顾本周要闻,1.法拉第未来回应谣言,内华达工厂并未停工,2018年交付新车18日下午,法拉第未来,FaradayFuture...。

向左走,还是向右走,近日,面部识别技术又遭遇,突发事件,本周二,由90个倡议团体组成的小组给三巨头AAM,亚马逊、谷歌、微软,写信,要求三家公司承诺不向政府出售面部识别技术,其中,这些团体中包括了美国公民自由联盟ACLU、难民移民教育和法律服务中心RAICES、电子前沿基金会EFF等重要组织,这封信一经公布,给予三家巨头公司非常大的...。

AI芯片在科技领域到底有多热门,如果高通、英特尔、英伟达这些传统芯片巨头都已开始制造AI芯片还不够证明其热度,那么电商巨头亚马逊、社交巨头Facbook、软件巨头微软等也都开始自主研发AI芯片不仅能说明AI芯片到底有多受关注,更能证明其重要性,相比美国的科技巨头,国内三大科技巨头BAT的脚步似乎并没有那么快,在中兴通讯事件再次引发全民...。

雷锋网按,本文作者连诗路,前阿里产品专家,在人工智能火热的现在,AI链接各行各业似乎是大势所趋,作为一名产品经理该如何适应这个,新时代,作者谈了谈他的看法,一、产品的驱动源力干了10年的PC、APP、智能硬件产品经理,经历B2B、B2B2C、C2C、B2CSOLOMO、O2O、C2M,F、P2P等等各种商业模式或事业模式,有的企业需...。

雷锋网AI科技评论按,在旧金山参加AAAI期间,经余凯老师的引荐,AI君来到了位于PaloAlto的亚马逊AWS办公室与李沐见了一面,从百度少帅到CMU博士再到MXNet,李沐的履历俨然自带距离感,但当穿着耐克灰色套头衫和牛仔裤的李沐坐在我们面前侃侃而谈时,AI君在会面前的担心一扫而光,严格来说这并不是一次采访,更像是朋友间的闲聊,经...。
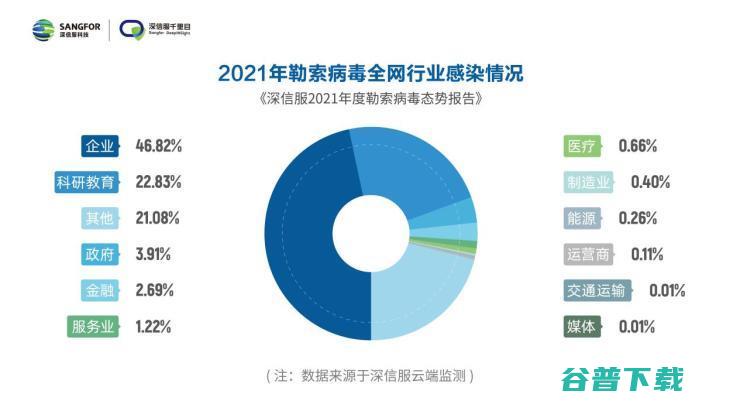
勒索病毒作为目前最具有破坏力的恶意软件之一,在2021年达到爆发高峰,据深信服云端监测,全网勒索攻击总次数高达2234万,,影响面从企业业务到关键基础设施,从业务数据安全到国家安全与社会稳定,同时,随着ApacheLog4j2漏洞等全球网络安全事件频频出圈,网络攻击的强度和破坏性都前所未有,网络安全不再只是计算机行业的,独角戏,,已然...。

自然美2017加盟招商火热进行中世间温柔的物质是水,世间坚韧的物质是水,水作的女人千娇百媚,万种风情,清新亮丽,高雅脱俗,自然美让您做水一样的女人,如出水芙蓉,浑然天成,随着美容市场需求不断扩大,美容院加盟也成为多创业者智慧之选优选项目,如何选择美容院产品加盟品牌,也是创业者比较头疼的问题,在这日趋激烈的美容市场如何正确的...。

11月24日,OPPO正式发布Reno9、Reno9Pro、Reno9Pro,,3台新机横跨骁龙778G、天玑8100,MAX和3GHz版骁龙8,,定价2499元起,另外,这是连续第三天有大厂新品发布会了,3台新机都搭载一样的6.7英寸2160HzPWM调光的双曲屏,而且是绿厂首个全系标配红外发射器的产品线,有趣的是,Reno9Pro...。

问,9月6日,荷兰宣布将扩展光刻机的管制范畴,请问中方对此有何评论,答,中方留意到相关状况,近来,中荷双方就半导体出口管制疑问展开了多层级、多频次的沟通商量,荷方在2023年半导体出口管制措施的基础上,进一步扩展对光刻机的管制范畴,中方对此示意不满,近年来,美国为保养自身环球霸权,一直泛化国度安保概念,胁迫一般国度加严半导体及设备出口...。

申明,1.以上内容仅代表揭发者自己,不代表黑猫揭发立场,2.未经授权,本平台案例制止任何转载,违者将被清查法律责任,3.黑猫揭发处置揭发不收取任何费用,凡以黑猫揭发名义不要钱的均为混充、诈骗行为,请及时报警并与黑猫官网反应,揭发邮箱heimaotousu@vip.sina.com,4.请大家选用官网渠道处置生产纠纷,不要轻信第三方机构...。
