EMNLP 2021 (EMNlP2025会议地点)

近期,字节跳动人工智能实验室在 EMNLP 2021 上发表了一篇关于在线更新机器翻译系统的论文。

机器翻译系统在线更新指的是使用单个翻译样本更新机器翻译系统。工业应用中对机器翻译系统在线更新的需求主要来自于两类场景:
当前主流的机器翻译系统都是基于神经网络搭建的,而参数众多结构复杂的神经网络模型难以做到在线更新。基于样本的机器翻译系统却很容易做到在线更新。在基于样本的机器翻译系统中,通常存在一个大规模的翻译语料库。给定一条源语言句子,生成对应翻译结果的过程中,需要从翻译语料库中检索出若干相似的翻译样本,并利用检索到的样本生成最终的译文。更新基于样本的机器翻译系统只需要更新翻译语料库就可以了,无需更新机器翻译模型的参数。
但是基于样本的机器翻译系统泛化性较差,在检索不到相似样本的情况下,很难生成高质量的译文。因此, 最近一些工作将样本检索与神经机器翻译结合,在神经机器翻译模型解码的过程中检索相似的翻译样本辅助译文生成 。这种样本检索机制赋予了机器翻译系统在线更新的能力。
在这个方向上,一个经典的工作是发表在 ICLR 2021 上的 kNN-MT[2]。kNN-MT 为神经机器翻译引入了词级别的样本检索机制,使得翻译系统在无需额外训练的情况下,显著提升多领域机器翻译和领域适应机器翻译的能力,同时具有了在线更新的能力。
但是 kNN-MT 仍然存在一些问题,使用固定的将神经机器翻译输出和样本检索进行组合的策略使得它难以适应多变的输入样本。如图1所示,带有领域内翻译语料库的 kNN-MT 领域内的翻译质量取得了明显提升,而通用领域翻译质量却剧烈下滑。造成这种现象的原因是,kNN-MT 过度依赖检索到的样本,在检索到的样本与测试样本不相似时,检索到的样本对于机器翻译而言反而是噪声,从而降低了翻译质量。
这篇工作主要针对该问题[3], 提出了一种动态结合样本检索和神经机器翻译的方法 KSTE R (Kernel-Smoothed Translation with Example Retrieval),使得翻译系统在检索到相似样本的情况下能够提升翻译效果,在检索不到相似样 本时,也能保持原有的翻译质量,同时保持在线更新的能力。
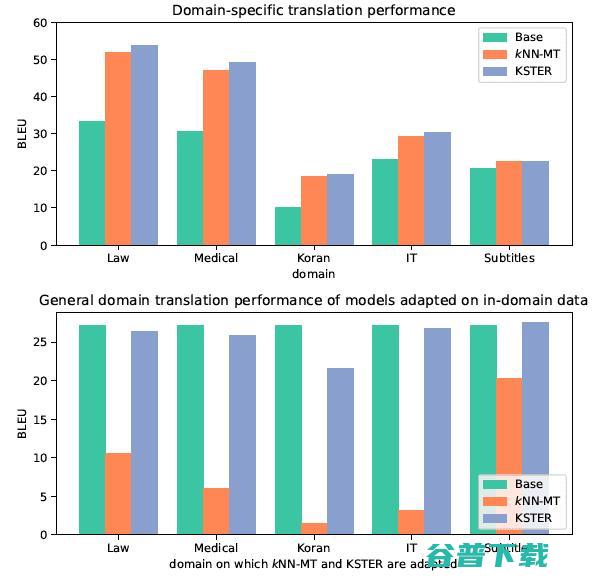
图1 带有领域内数据库的kNN-MT,在领域内数据和通用领域数据上的翻译效果。
在这篇工作的模型结构中, 翻译系统由两个部分组成,分别是一个通用领域的神经机器翻译模型——采用经典的 Transformer 结构[1],和一个样本检索模块——用于执行相似样本检索、相似度计算和概率估计。 自回归的机器翻译模型生成译文是按相似的方式逐词生成,因此只需考虑单步的解码过程。在解码生成译文的每一步中,翻译系统的两个部分都会产生下一个词对应的概率分布。这两个分布会根据一个混合系数进行线性插值,估计出一个混合的概率分布。下一个词将由这个混合的分布预测出。
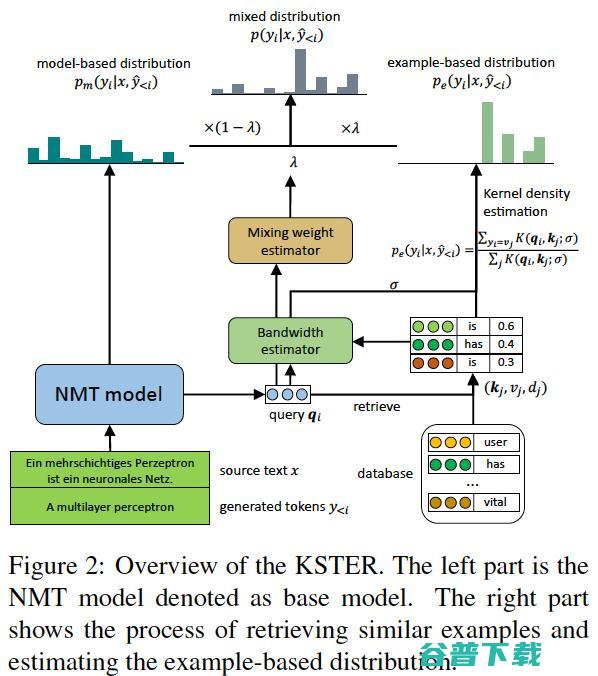
为了在解码过程中进行样本检索,作者 构建了一些词级别的翻译数据库 。数据库中存储的是词级别的翻译样本,每一个样本是一个键值对 。这个键指的是目标端语言的句子中一个词出现的上下文的向量表示 ,值指的是对应的目标端语言的词 。使用一个通用领域上训练好的 Transformer 模型,对每一条训练数据做强制解码,即可计算出目标语言每个词的上下文相关向量表示,构造出一组词级别翻译样本以供检索。
在解码的每一步中,NMT 模型会计算出一个基于模型的下一个词分布 。另外, NMT 模型会计算当前上下文的向量表示作为查询 ,从翻译数据库中检索Top- k 个 L2 距离最小的样本。
可学习的核函数
利用核密度估计根据检索到的样本估计出一个基于样本的分布 ,其中核函数是一个具有可学习带宽参数的高斯核或拉普拉斯核。带宽参数基于当前上下文和检索到的样本动态估计得出,主要是为了调整 的锐度。当检索出的 k 个样本只有几个头部样本与当前上下文相似时,低带宽的核密度估计会生成一个尖锐的分布,将绝大多数概率质量分配给头部样本,忽略尾部样本引入的噪声。
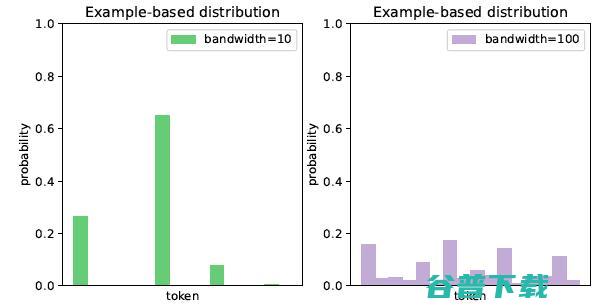
图3 核函数的带宽参数越小,估计出的分布越尖锐。
基于模型的分布 将和基于样本的分布 按一定权重 进行线性插值,得到一个混合分布 ,并由混合分布预测出下一个词。混合权重 决定了翻译系统预测下一个词是更多地依赖 NMT 模型的输出还是检索到的样本。如图4 所示,在解码的每一步中,混合权重都是不同的,根据当前上下文和检索到的样本估计出。翻译系统自适应地决定更多地依赖哪个部分。
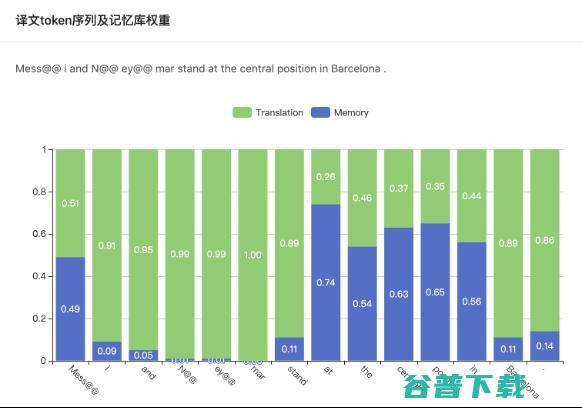
图4 动态的混合权重。Memory 表示基于样本的分布权重 ,Translation 表示基于模型的分布权重 。
模型训练策略
在 KSTER 训练过程中,NMT模型参数是固定不变的,需要训练的部分只有一个带宽参数估计器和一个混合权重估计器。作者使用交叉熵损失函数对翻译系统整体进行优化,但只更新带宽参数估计器和混合权重估计器的参数。
由于训练翻译系统的数据与构建翻译数据库的数据是相同的,在训练时总能检索到 top 1 相似的翻译样本就是查询自身。而测试数据通常在翻译数据库中没有出现过。这种训练和测试的不一致性,导致翻译系统容易过度依赖检索到的样本,产生过拟合的现象。为了缓解训练和测试的不一致性,作者在训练时检索最相似的 k + 1 个样本,并把第 1 相似的样本丢弃,保留剩下的 k 个样本用于后续的计算。这种训练策略被称为检索丢弃,在测试时并不使用这种策略。
这篇工作在机器翻译领域适应和多领域机器翻译两种任务上进行了实验,KSTER 相比 kNN-MT 在两种任务上均有提升。
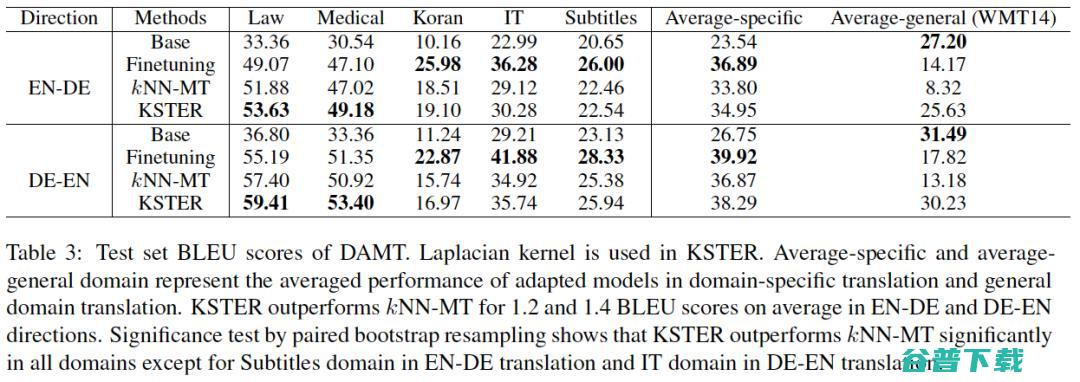
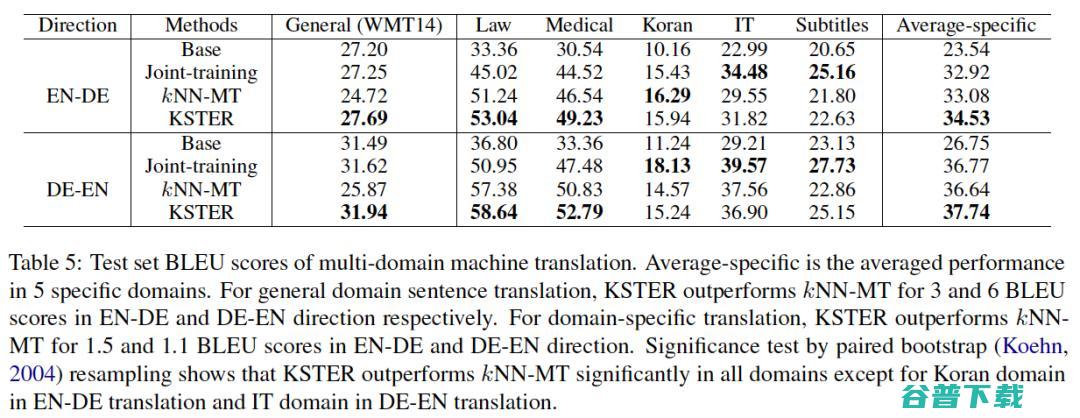
图6 多领域机器翻译任务上的实验结果
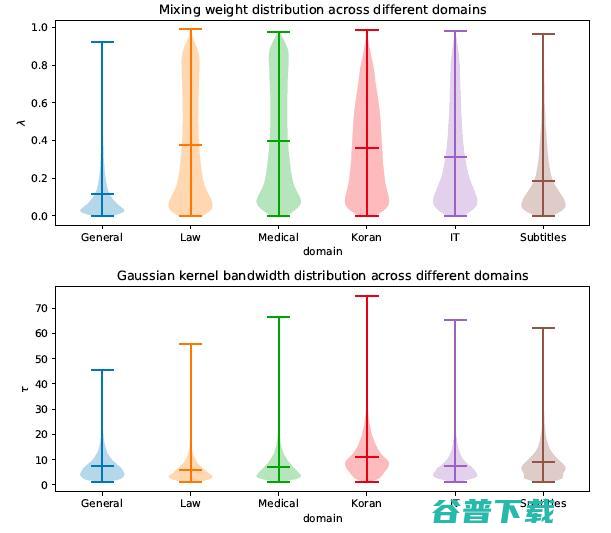
图7 不同领域的核函数带宽和混合权重分布
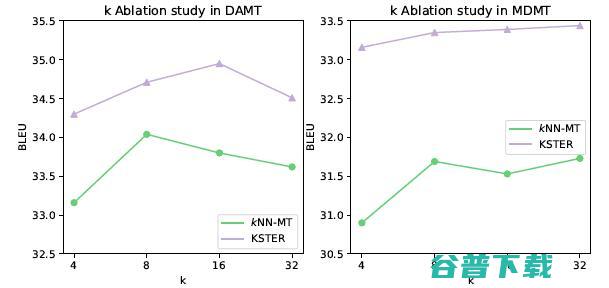
图8 检索不同数量样本 k 时,kNN-MT 和 KSTER 的翻译效果
图9 验证了检索丢弃这种训练策略的必要性。在不使用检索丢弃策略时,KSTER模型产生了严重的过拟合。而使用检索丢弃策略后,过拟合的现象得到明显缓解。
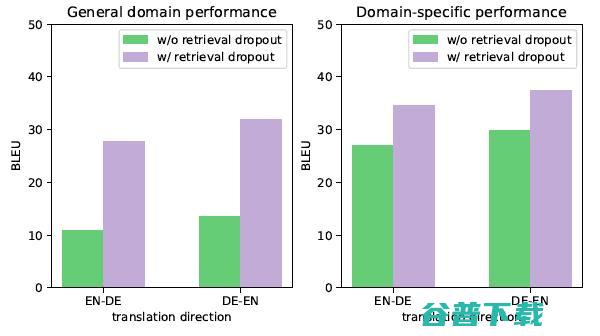
图9 检索丢弃训练策略有助于缓解过拟合
作者基于 KSTER 开发了一个基于在线干预机器翻译系统,用于展示翻译系统在线修复bad case的能力。 图10 - 14 展示了一些具体的样例。
如 图10 所示,由于训练数据中没有出现过“字节跳动”这种新兴实体,以及“C位”这类新词,翻译系统对它们的翻译效果是不好的。
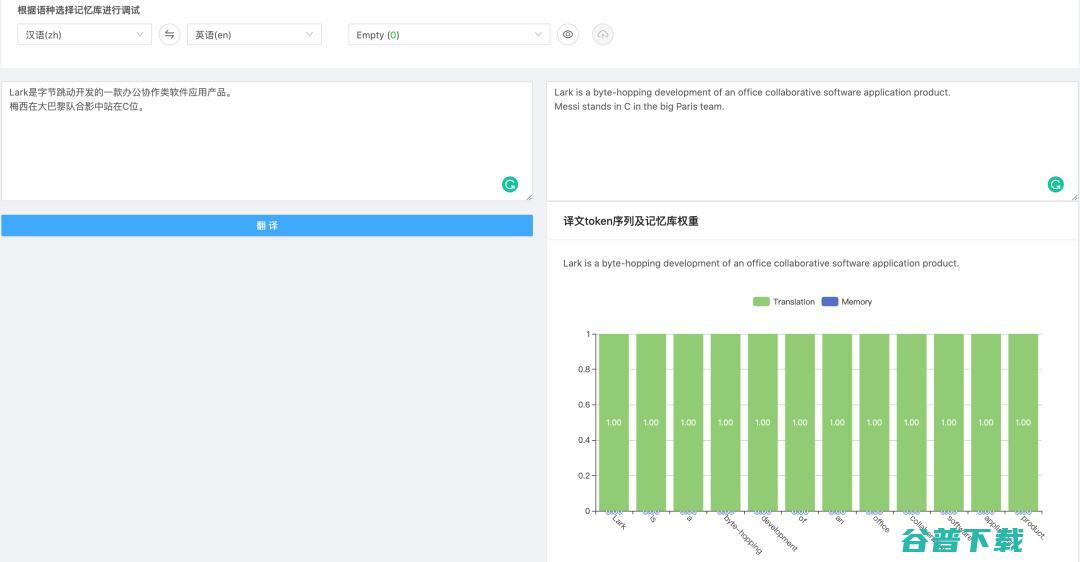
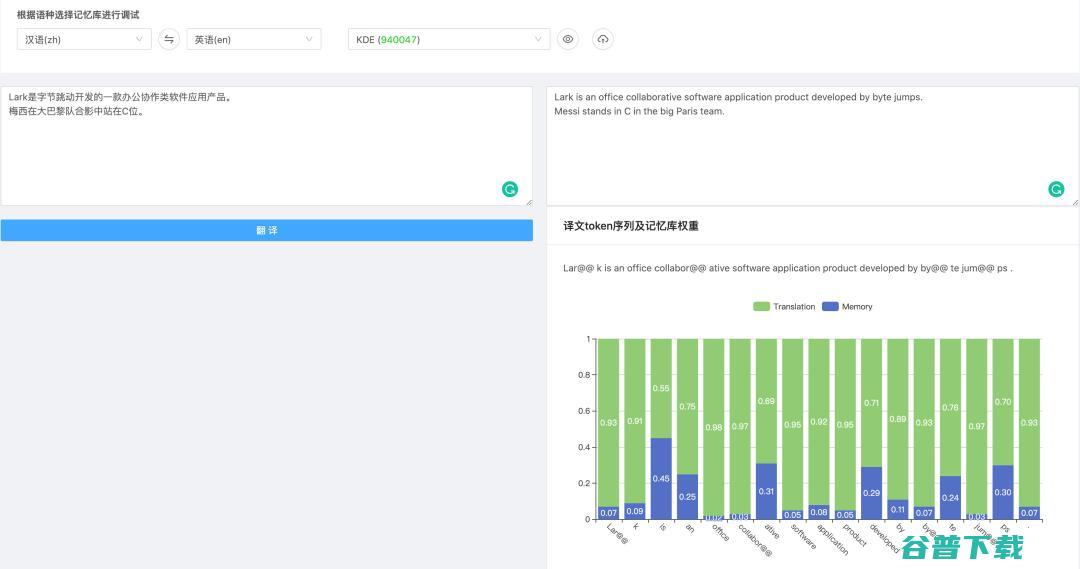
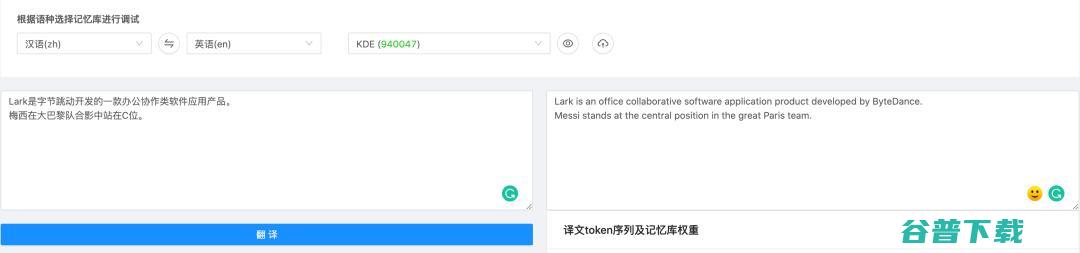
图12 向 KSTER 翻译数据库中添加以上样本
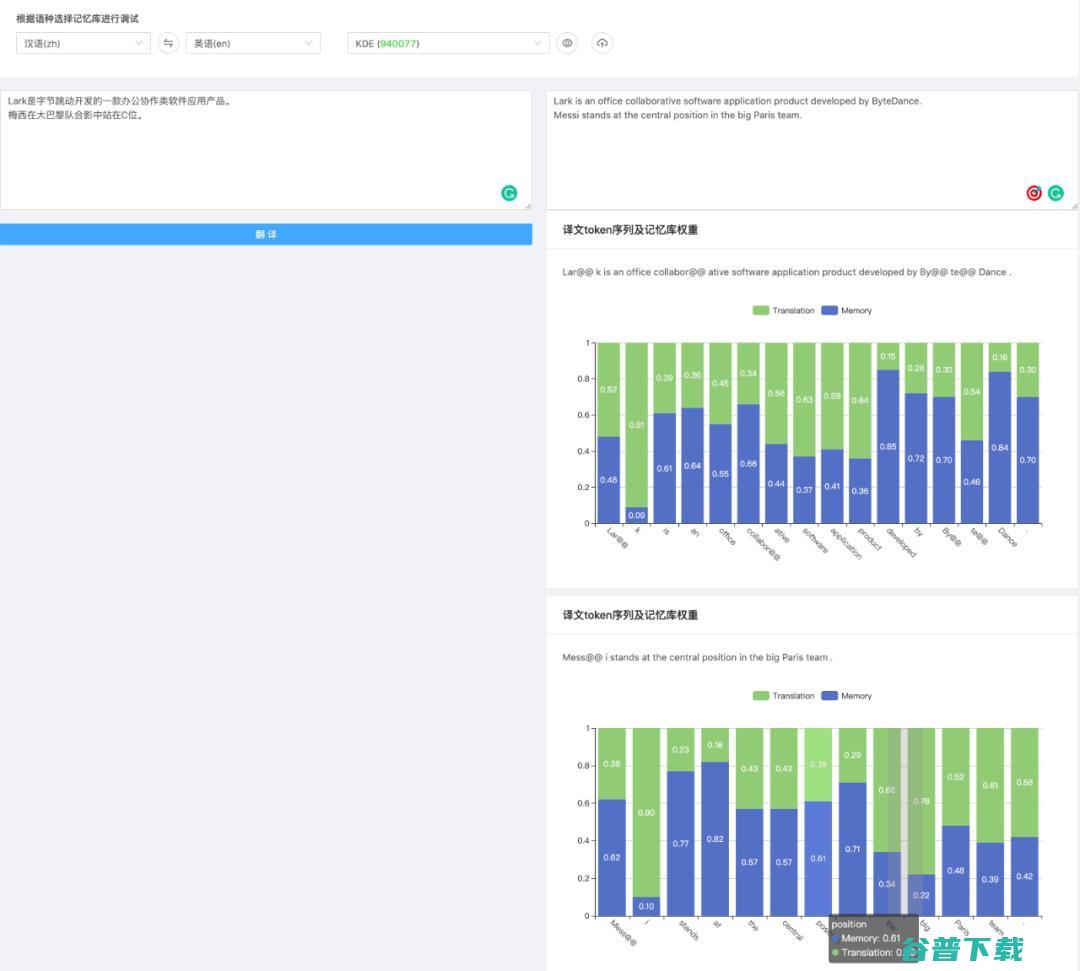
图13 添加样本之后KSTER的翻译结果
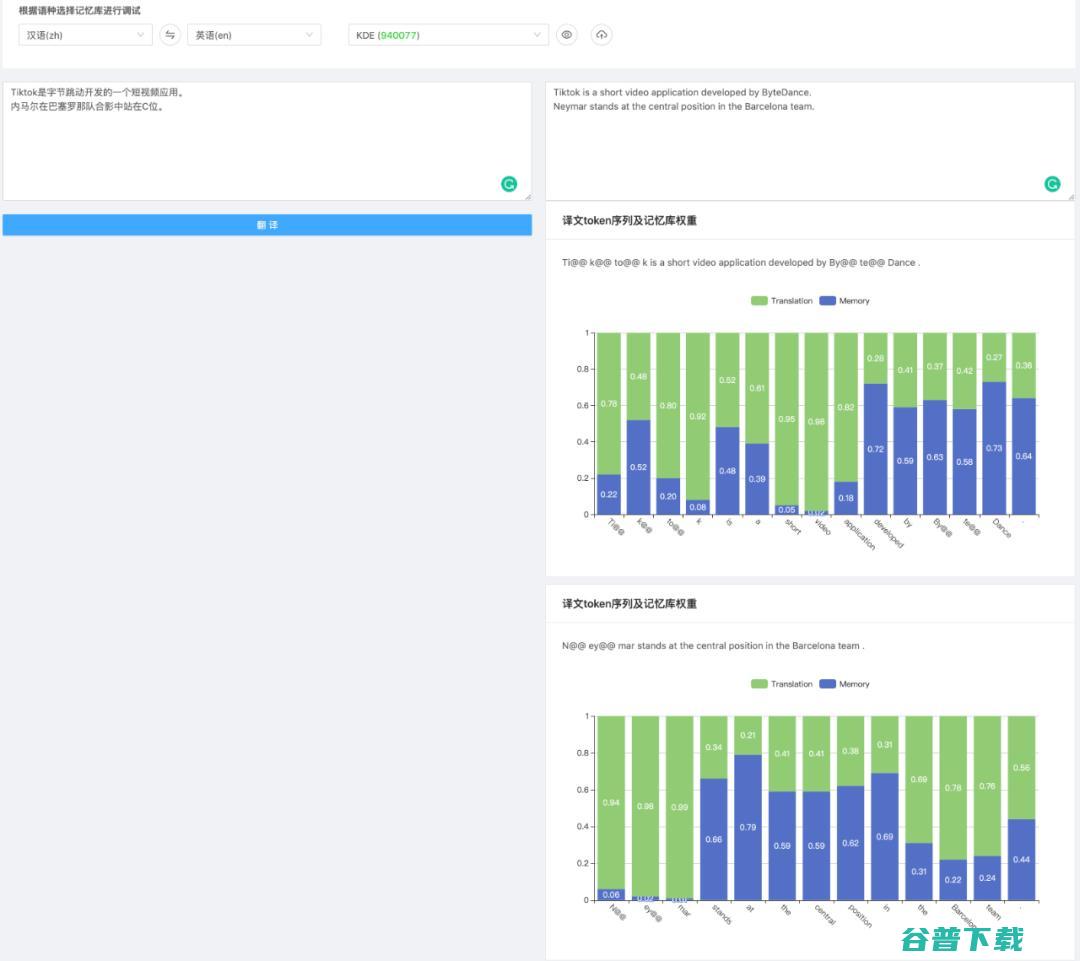
图14 KSTER 在相关样本上的翻译结果
本文主要介绍了 KSTER,一种有效的机器翻译系统在线更新方法。其在机器翻译领域适应和多领域机器翻译上均表现出优异的效果。同时展示了它的在线修复 bad case的能力。

版权文章,未经授权禁止转载。详情见 转载须知 。



高厦加盟网做为国内大型招商加盟网站,提供涵盖服装、饰品、教育、汽车、环保、家居、母婴、餐饮、美容等行业招商资讯信息。了解更多创业加盟项目信息,就上志运雅泓网!

信阳升华化工科技有限公司16年专注研发生产真石漆搅拌机,为客户提供一站式解决方案,主营:立式真石漆搅拌机、干粉搅拌机、腻子粉搅拌机、卧式真石漆搅拌机等,致力于帮助客户一站式解决真石漆问题,咨询电话:19603768669.

朗目疏眉网

悍邦灯光设计工作室专业别墅灯光设计、软装照明设计、大宅灯光设计、精装智能灯光、别墅精装灯光智能改造满足您的需求是我们最大的动力!

985.so为您提供:,短网址程序,短网址服务,短网址转换,短网址API接口,批量生成短链接,短网址生成,压缩所有网址包括图片、flash、mp3、rar等所有互联网地址,专业的网址缩短网站!。
景观工程有限公司")
鼎典(天津)景观工程有限公司

BLUE引擎官网论坛:Blue引擎代理完美、新Blue引擎免费注册、Leg引擎官网、AC封挂网关、BLUE登录器、BLUE版本库假人脚本、BLUE服务器!blue引擎问题解答每日更新!

江苏熊猫电源有限公司主要经营各品牌柴油发电机组,提供免费设计安装服务,并拥有完善的售后体系,销售热线:0514-82886982

正野电器超静音排气扇产品设计咨询服务,正野换气扇价格,正野排风扇型号,正野排气扇报价:13601886499林先生

深圳市沃道科技有限公司,不动产,办公空间,企业资产,设施设备.....;联系方式:4000919909


共道网络科技有限公司2018年成立于浙江杭州,是由杭州市城投集团投资,阿里巴巴集团给予强大技术支撑的互联网科技公司。公司目前主要从事网上法院解决方案研发销售,致力于打造全国一流的法律服务开放平台,目前已为近200家法院及政府行政机构提供服务,并在交易纠纷、知识产权纠纷、金融纠纷等行业智能化类案速裁领域积累了丰富的实践经验。全国首创的杭州互联网法院诉讼平台由共道科技研发,得到了国内外法律专家的高度关注和认可,代表着智慧法院建设的领先水平


近期收到了很多用户的爆料,注意是很多用户,说自己的QQ和微信都被封号了,而且是永久封号,要知道,面对这种情况,根本找不到腾讯客服,全部是人工智能的,全是语音自动回复,也没办法申诉,直接提示用就封禁,不仅仅是QQ,微信最近也在大力打击群控系统,一般正常的网络环境都不会封,如果判断为营销网络环境,即使是一个正常的QQ或微信,都有被永久封停...。

高通犯错,成为了联发科的机会,3月18日,首款搭载联发科天玑9000旗舰处理器的旗舰手机OPPOFindX5Pro就将上市,虽然上市时间比骁龙8版本的OPPOFindX5Pro晚了半个月时间,也没有集成OPPO自研的马里亚纳X芯片,但不少消费者对定价5799元的天玑版本OPPOFindX5Pro依旧十分期待,这种期待是对高通近几代旗舰...。

雷锋网AI科技评论按,你有没有想过,深度神经网络是依据什么来准确识别有猫的图片的,随着深度神经网络在金融、医疗及自动驾驶等领域的广泛应用,深度神经网络无法明确解释自身决策行为的问题也引起了越来越多的关注,明确解释深度神经网络的决策行为,能够大幅提升各类用户对深度神经网络的信任,并显著降低大规模使用深度神经网络所带来的潜在风险,是基于深...。

企业的数字化转型,既是一个大命题,也是一个大趋势,随着世界各国朝,工业4.0,迈进以及高新技术的兴起,发展高附加值的制造业正成为工业战略发展的共识,面向新一轮数字化浪潮,德国推出工业4.0参考架构RAMI4.0,美国推出工业互联网参考架构IIRA,日本推出工业价值链参考架构IVRA,我国为推进工业互联网发展,由中国工业互联网产业联盟于...。

代码说明,本页面的认证代码为第六联盟专用评测代码,站长需懂简单html知识,直接复制代码粘贴到联盟网站相应页面即可使用,本代码不适用于其他广告联盟网站请勿获取!文字认证,文字链接代码认证适用所有类型的广告联盟,复制代码后放在第六联盟网站首页底部或友情链接位置处,普通认证,普通联盟认证标志适用所有类型的广告联盟,能有效提升第六联盟的可信...。

詹姆斯·麦卡沃伊是一位苏格兰演员,因出演,末代独裁,、,赎罪,和,X战警,第一战,等电影而闻名全世界,他不仅演技好,而且颜值高,人送外号,詹一美,,丝毫不逊于世界上最帅的男人阿汤哥,詹姆斯·麦卡沃伊早期生活,詹姆斯·麦卡沃伊1979年4月21日出生于苏格兰的格拉斯哥,并在格拉斯哥长大,他的母亲是一位精神科护士,父亲是一位建筑师,在他7...。

申明,1.以上内容仅代表揭发者自己,不代表黑猫揭发立场,2.未经授权,本平台案例制止任何转载,违者将被清查法律责任,3.黑猫揭发处置揭发不收取任何费用,凡以黑猫揭发名义不要钱的均为混充、诈骗行为,请及时报警并与黑猫官网反应,揭发邮箱heimaotousu@vip.sina.com,4.请大家选用官网渠道处置生产纠纷,不要轻信第三方机构...。

申明,1.以上内容仅代表揭发者自己,不代表黑猫揭发立场,2.未经授权,本平台案例制止任何转载,违者将被清查法律责任,3.黑猫揭发处置揭发不收取任何费用,凡以黑猫揭发名义不要钱的均为混充、诈骗行为,请及时报警并与黑猫官网反应,揭发邮箱heimaotousu@vip.sina.com,4.请大家选用官网渠道处置生产纠纷,不要轻信第三方机构...。

西风风神AX7来自西风二号军工平台,其越野型、能源性、牢靠性、消息化等方面的长处,与西风猛士一脉相承,风神ax7报价最低在9.5万元左右,目前最大的活动力度在5000元左右,无论哪一款尽量选用高配版的是最理智之举,国产自主品牌的西风风神性价比高性能好,高下配之间的差价很小,高下配之间的安保性和温馨性相差却很大,西风风神rx7如今市场多...。

2014年,公众推出了一款以,粗劣、时兴、节能,为特点的中型车—2014速腾1.4t,只管如今它曾经不是最新款的车型,然而它依然能够吸引泛滥生产者,其中一个关键要素就是它杰出的性能,1、外观设计2014速腾1.4t的外观设计十分美丽,它驳回了公众最新的,蓝标,设计格调,汽车的线条愈加流利,全体外型愈加时兴,让每一位驾驶者都能够感遭到温...。

长安汽车是中国汽车制作业领军企业之一,旗下领有多款抢手车型,其中以迷你奔奔为代表的小巧便利车型备受消费者喜欢,迷你奔奔是一款经典的市区代步车,其外观小巧小巧,动力性能微弱,备受消费者青眼,接上去,咱们将为您具体引见长安汽车迷你奔奔的特点和长处,首先,长安汽车迷你奔奔的外观设计不落窠臼,它的车身线条流利、繁复,小巧小巧,十分诱人,而且迷...。

方程豹5同款底盘动力?比亚迪皮卡来了!,皮卡,电动汽车,新能源

炸串的风味是非常丰富的,因为炸串可以炸蔬菜、炸肉类、炸里脊,各种不同的食物,吃到嘴里面有着不一样的美味,嘿逵炸串希望做年轻人爱吃的一个小吃快餐店,主要面对九零后年轻群体,市场非常广阔,得到创业者的支持,那么,嘿逵炸串有哪些好的食材,客人喜欢吗,一、有哪些食材为了给顾客带来丰富多样选择,同时也让嘿逵炸串门店保持较好的产品竞争力,因此嘿逵...。

每个家庭都需要不同的家居产品,比如衣柜、橱柜等等,市场需求量一直都比较可观,让不少的创业者看到了家居行业所带来的商机,科凡家居是一家有名的家居品牌,自2006年在顺德成立以来,经过了十几年的发展时间,已经在全国建立了六百多家合作门店,在市场中有着不错的影响力和口碑,是创业者们所关注的品牌,科凡家居好运营吗,店内商品多吗,怎么加盟的,科...。

昨天看到一篇文章很火,叫,月薪三千与三万的文案的区别,,觉得传递了很多错误的思路,恐怕会造成很多的误读,所以还是需要正本清源一下,其实这个事情本身和文案无关,只是大家觉得文案不是文盲都可以写,然后就觉得学一下也许自己也能拿到三万呢,所以最后的问题是抓住了人的投机取巧心,和文案倒是没什么关系,其实文章第一句就错了,,无数打着互联网思维的...。

当天上午,天舟八号货运飞船发射义务组织全区合练,目前,发射义务各系统曾经实现了关系配置审核,并做好发射前的各项预备上班,总台央视记者王刚李昊,关系报道,天舟八号启动垂直转运,,月壤砖,将初次入地,央视资讯,太空快递又要入地啦!天舟八号船箭组合体垂直转运正在启动10月30日,中国空间站迎来神舟十九号乘组,按方案,天舟八号货运飞船将为神...。

近日,江西吉安市万安县委组织部发布一则干部任前公示,其中包含3名,95后,年轻女干部,拟提名乡镇人大副职,均为在职大专学历,引发宽泛热议,即使万安县委组织部发布了,状况说明,,但仍有很多不懂惹起网友质疑,25岁~27岁、大专学历选拔副科能否偏心,事业单位编制间接选拔副科,能否有依据,选拔环节能否地下透明,三人的效果和上班才干能否应该地...。
