六项计划 华为视觉研究路线图 三大挑战 (华为6g计划)

雷锋网AI科技评论按:昨天在华为开发者大会上,华为首席科学家陈雷发布的全场景AI计算框架MindSpore开源框架,引起业界广泛关注,毕竟在短短一周之内,国内相继涌现出计图(Jittor,清华)、天元(MegEngine,旷视)、MindSpore(华为)三个深度学习开源框架,可谓“2020年是深度学习框架井喷的一年”。
但在昨天的大会中,华为发布的另一项重要计划却似乎受到了忽视,这是由田奇博士主导的“ 华为计算视觉基础研究进展暨华为视觉计划发布 ”。
田奇博士,计算机视觉领域的人士应该都不陌生,毕业于清华电工系,后赴伊利诺伊大学香槟分校,师从计算视觉之父 Thomas S.Huang 教授。在2018年加入华为之前,一直在德克萨斯大学圣安东尼奥分校任教,是2016年多媒体领域 10 大最具影响力的学者,并于当年入选IEEE Fellow。
田奇博士加入之后,华为诺亚方舟在计算机视觉领域的研究突飞猛进。以论文来讲,ICCV 2019、CVPR 2019 分别有 19篇和29篇入选论文,CVPR 2020上更是多达 33 篇,且不论他们在类似ICLR、ICML这类篇算法的顶会上发表的论文。
在这次“研究进展&计划发布”上,田奇博士将他们的研究内容梳理为三大方向,即
数据:如何从数据中挖掘有效信息?
模型:怎样设计高效的视觉识别模型?
知识:如何表达并存储知识?
在此基础上,他提出了华为诺亚的六大视觉计划:数据冰山计划、数据魔方计划、模型摸高计划、模型瘦身计划、万物预视计划、虚实合一计划。
每个计划听着都很带感,其中逻辑是什么?各自代表了什么?
一、计算机视觉的三大挑战及华为的研究
田奇博士在演讲中,将当下计算机视觉面临的挑战分为三大方向,分别为数据、模型和知识表达。(为什么没有算力?毕竟这不是做视觉的人所能决定的,其实对算力的考虑包含在模型里面)
1、如何从数据中挖掘有效信息?
在信息时代,做计算机视觉其实面临一个尴尬的事情,即互联网上存在着海量的视觉数据,甚至已经远远超过了人类处理的极限;标注数据,无论规模多大,都只是视觉大数据中的“沧海一粟”。如何从海量数据中挖掘出有效的信息,依旧是一个很大的挑战。
华为在这方面提出了两个典型的场景,一是如何利用生成数据训练模型;二是如何对齐多模态数据。
首先是生成数据,华为在这方面投入了大量的研究。具体来说,分为三部分。
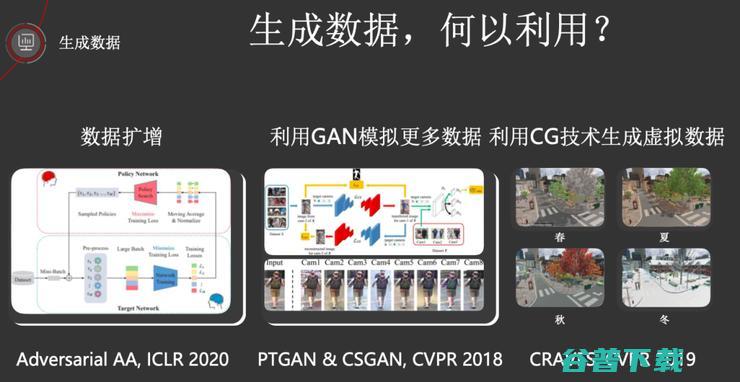
第一,自动数据扩充。这个以发表在ICLR 2020 上的 「Adversarial AutoAugment」为代表,这篇文章针对以前NAS(例如 AutoAugment)做数据增强计算开销大、policy是静态的问题,借用 GAN 的“对抗”思想,引入了 adversarial loss,这样一方面大大减少了训练所需的时间;另一方面,可以认为policy generator 在不断产生难样本,从而能帮助分类器学到 robust features,从而学的更好。(ICLR 2020 | 华为诺亚:巧妙思想,NAS与「对抗」结合,速率提高11倍)
第二,利用GAN来模拟更多的数据。这个以发表在CVPR 2018 上的PTGAN 和 CSGAN 为代表。前者(「Person Transfer GAN to Bridge Domain Gap for Person Re-Identification」)是针对行人重识别问题的生成对抗网络,使用GAN将一个数据集的行人迁移到另一个数据集当中。后者(「Compressed sensing using generative models」)是针对感知的GAN压缩,换句话来说,即利用GAN来重构出“原始数据”,相比于其他的重构算法来讲,CSGAN在更少的测量(可理解为采样后的数据)情况下能够重构出很好的原始数据。
第三,利用计算机图形学技术来生成虚拟数据。这个以发表在CVPR 2019 上的「CRAVES: Controlling Robotic Arm with a Vision-based, Economic System」为代表。在CRAVES这篇工作中,他们设计了一套基于虚拟数据生成和域迁移的训练流程,机械臂只需要借助一个额外的摄像头,便可以完成抓取骰子并放置在指定位置的任务。注意,这里的数据是基于CG技术生成的,对机械臂的训练完全不需要提供额外的监督数据。

如左边的图所示,原图是一只狐狸;如果对它进行亮度变化,它看起来会更像一只狗;如果对它进行反转,这个时候看起来像一只猫。因此在训练模型的时候,如果仍然使用原来的硬标签(“fox”)显然是不合适的。

为了解决这个问题,华为提出了知识蒸馏的办法,通过预训练的模型,对AA的图片,产生软标签,再用软标签指导图形的训练。上图便是知识蒸馏后产生的软标签。
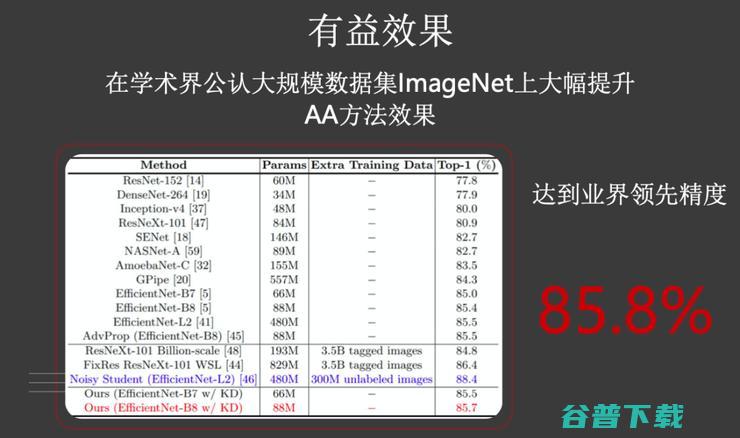
从结果上来看,这种知识蒸馏与自动数据扩增相结合的方法,在ImageNet上能够取得85.8%的效果。
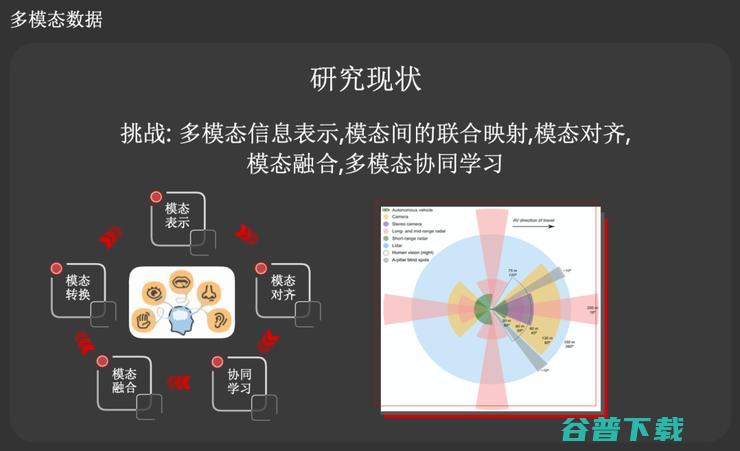
针对第二个场景,多模态数据,田奇博士认为多模态学习将成为未来计算机视觉领域的主流学习模式,因此非常重要,他们也将在这个领域进行重点布局。当前多模态学习面临的挑战包括:多模态信息表示,模态间的联合映射,模态对齐,模态融合,多模态协同学习。

针对这方面的工作,即如何对齐多模态数据,田奇重点介绍了他们在ACM MM 2019 上获得最佳论文提名的论文「Multimodal Dialog System: Generating Responses via Adaptive Decoders」。他们称之为“魔术模型”,论文本身是针对电子商务场景,用户在与机器克服对话过程中存在输入文本或图片的需求。他们针对这一问题,使用了一个统一的模型来编码不同模态的信息,从而能够根据上下文来反馈文字或图片。
2、怎样设计高效的视觉识别模型?
田奇博士提出,华为诺亚在视觉模型方面的主要研究在于如何设计出高效的神经网络模型以及如何加速/小型化神经网络计算。换句话来说,即模型如何更快、更小、更高效。
神经网络模型的设计,最初都是手工设计,但现阶段手工网络模型设计已经进入了瓶颈期。而作为对应,从2017年开始,自动网络架构搜索(NAS)迅猛发展,尽管只有三年时间,却已经取得了可喜的进展。

田奇博士认为,NAS目前存在三大挑战,分别为:1)搜索空间仍需人工经验定义;2)待搜算子需要人工设计;3)相较手工设计网络,可迁移性较差。
田奇博士在这方面仅举了他们的一个工作,发表在ICLR 2020 上的「PC-DARTS: Partial Channel Connections for Memory-Efficient Architecture Search」。PC-DARTS针对现有DARTS模型训练时需要 large memory and computing 问题,提出了局部连接和边正则化的技术,分别解决了网络冗余问题和局部连接带来的不稳定性。这个模型能够在性能无损的情况下,做到更快(与同类相比快一倍)。

针对如何加速神经网络及模型小型化,田奇博士是这样思考的。目前大的网络模型发展如火如荼,但这样的模型更适合配置在云侧,而无法适配端侧。从2016年起,业界便开始探索模型加速和小型化的研究,也提出了大量小型化方案。但这些方案在实际中面临着诸多问题,包括:1)低比特量化使得精度受限;2)混合比特网络对硬件却并不友好;3)新型算子并没有得到充分的验证。

田奇博士同样举了他们最近的一项工作,是CVPR 2020 上的一篇 Oral:「AdderNet: Do We Really Need Multiplications in Deep Learning?」。在计算机中,浮点运算复杂度相比加法要高很多,但神经网络中存在大量的乘法运算,这就限制了模型在移动设备上大规模使用的可能性。那么是否能设计一种基于加法的网络呢?华为的这篇文章正是对这一问题的回答,他们将卷积网络中的乘法规则变成加法,并对网络中的多种规则进行修改:1)使用曼哈顿距离(取代夹角距离)作为各层卷积核与输入特征之间输出的计算方法;2)为AdderNet设计了一种改进的带正则梯度的反向传播算法;3)提出一种针对神经网络每一层数量级不同的适应性学习率调整策略。实验结果上表明,AdderNet能够取得媲美于乘法网络的效果,且在计算功耗上具有明显的优势。
3、如何表达并存储知识?
田奇表示,华为的目标是打造下一代视觉感知的通用视觉模型,并把该算法迁移到下游任务进行模型复用。
那么,何为“通用视觉模型”?其核心思想事实上就是如何表达并存储知识。
田奇博士提出两种场景。首先是目前比较热的预训练的方式,通过预训练获得的模型来表达和存储知识;其次是通过虚拟环境,在基本不需要标注数据的情况下来学习知识。

针对预训练模型,田奇博士提到了他们在CVPR 2019上发表的工作:「Iterative Reorganization with Weak Spatial Constraints: Solving Arbitrary Jigsaw Puzzles for Unsupervised Representation Learning」。这篇文章提出了一种适用于处理任意维度拼图问题的自监督学习方法。

拼图问题将无标签图像按网格分割为图像块,并打乱它们的顺序,通过网络恢复正确的图像块布局,来达到从无标签图像数据中学习语义信息的目的。这篇文章提出,以迭代的方式逐步调整图像块的顺序直到收敛。在ImageNet上能够取得非常好的性能。

深度学习大量依赖于可标注的数据,但是很多场景下,数据标注成本很高。同时,标注数据也存在一个致命的问题,即知识表达不准确——比如在自动驾驶中,我们有大量的标注信息,但这些标注数据是否真的“最适合”自动驾驶任务呢?此外,人类对外界的感知依赖于常识,而依赖于标注数据来训练的模型则存在缺乏常识的问题。
针对这一问题,田奇博士提出了用虚拟场景构建虚拟场景来学习常识的方法。田奇博士举了他们发表在CVPR 2019 的文章(CRAVES),主要是通过虚拟场景来训练机械臂抓骰子。我们在前面已经提到,这里就不再赘述。
二、华为视觉研究计划
延续以上提到的研究内容,田奇在随后发布了「华为视觉计划」。简单来说包括六个子计划:
与数据相关的:数据冰山计划、数据魔方计划;
与模型相关的:模型摸高计划、模型瘦身计划;
与知识相关的:万物预视计划、虚实合一计划。

1、数据冰山计划
该计划是为了解决数据标注瓶颈问题,让数据生成真正代替手工标注。这里包含三个子课题,分别为:
子课题一:数据生成质量拔高。即通过一到两年时间,解决生成数据质量差和不真实的问题;
子课题二:数据生成点石成金。即设计数据自动挑选的算法,在海量的生成数据中,挑选高质量的数据;
子课题三:通用自动数据生成。即对不同的子任务设计不同的生成数据方式,让数据生成具备普惠能力。
2、数据魔方计划
该计划主要解决多模态数据量化、对齐和融合的问题,从而构建下一代智能视觉。包括构建多模态数据量化指标,从而全面评估性能;多模态数据对应策略研究;多模态数据融合方案等。
3、模型摸高计划
该计划主要是构建云侧大模型,来刷新各类视觉任务的性能上限。同样包括三个子课题:
子课题一:全空间网络架构搜索。即突破神经网络架构搜索空间受限的约束,搜索更多的范式、更多网络空间结构的变化,让神经网络架构真正实现自动搜索。
子课题二:新型算子搜索。即让算子的设计从手工复用到创造新的算子。
子课题三:搜索模型普适能力的提升。目前搜索出的网络泛化性能、抗攻击性、迁移性都比较差,该子课题希望能够提升网络架构索索的这些性能。
4、模型瘦身计划
开发端侧小模型,助力各种芯片完成复杂推理,是一个重要的研究方向。华为在这个领域中的目标是,打造高效的端侧视觉计算模型。该计划包含三个子课题:
子课题一:自动搜索小型化网络。即将硬件的约束融入自动设计中,使得算法能够适配不同的硬件。
子课题二:一比特网络量化。即设计一比特网络,使一比特网络能达到全精度网络的性能,目标是追求极致的性能。
子课题三:构建新型加法网络。即在卷积网络中,用加法运算代替所有的乘法运算,同时与芯片计算相结合,探索高效计算的新路径。
5、万物预视计划
所谓万物预视,即定义预训练任务,构建通用视觉模型。具体做法是搜集大量公开无标签的亿级数量级的图片,完成知识的抽取与整理。
6、虚实合一计划
该计划的目标是在虚拟场景下,不通过标注数据,直接训练智能行为本身。目前业界在这个领域的研究非常还有限。这里涉及如何定义知识、如何构筑虚拟场景、如何模拟用户的真实行为、如何确保数据与智能体的安全等问题。虽然这个计划极具挑战性,但田奇认为这才是通向真正的人工智能的道路。
雷锋网报道。
原创文章,未经授权禁止转载。详情见 转载须知 。



河南艾特环保设备有限公司是一家专业生产自清洗过滤器,保安过滤器,袋式过滤器,浅层砂过滤器,石英砂过滤器,多介质过滤器,煤气排水器,纤维球过滤器,大流量滤芯等产品的厂家。我们具有专注的生产设备、规模化的生产能力与技术优势,有着多年成熟的经验和技术优势,产品主要应用于钢铁、石化、冶金、电力、造纸、机械加工、市政工程等众多领域。

深圳市炜桔鑫滤清器有限公司燃机电厂滤清器,燃煤电厂滤清器,炼油厂滤清器,天然气滤清器,滤油机滤清器,空压机滤清器

今日上海,今日上海网官网,jinrishanghai,上海新闻,上海在线,上海东方都市网,上海媒体,上海今日最新新闻

玩校,致力于做中国高校行业最实用的手机客户端应用。该应用集一卡通、NFC、社交、校园公共服务、金融商圈等功能为一体,是将传统一卡通应用、校园信息化系统与移动互联网功能相结合的一次大胆创新,是引领新时代校园学习生活模式转变的重大变革。

易企秀-免费H5页面制作工具-微信H5页面,微信朋友圈会议邀请函,电子贺卡,动态音乐相册,电子微杂志,节日贺卡等,易企秀提供海量H5微场景模板,轻松制作一键生成H5页面,为您助力移动自营销,酷炫展示H5企业自营销页面-易企秀官网

深圳市东方旭升科技有限公司_内存条_固态硬盘_存储卡_东方旭升总部设立于中国深圳,并于2016年11月成立了香港海外销售公司---迅云国际有限公司,并于香港新界设立了国际物流仓库,现有员工300余人,公司以自动化生产设备代替了大量人工操作,不仅保证了生产质量,同时也在一定程度上节省了大量的人力成本,东方旭升凭借自己的行业优势,已服务于多个知名企业的生产及加工,目前生产基地及研发中心占地约5000平方米,并拥有6条西门子贴片生产线,16条内存、固态硬盘测试生产线及2条组装生产线,产能为内存300K/月,固态硬盘600K/月等。 自成立以来,公司一直注重管理水平提升和技术改进,并顺利获得了ISO45001、ISO9001、ISO14001等管理体系的认证,以及ROHS、Halogenfree、3C认证。东方旭升将始终坚持聚焦半导体存储领域,坚持以客户为中心,凭借专业的人才队伍及顶尖的设备投入,为更多客户提供高品质、可信赖的产品解决方案与服务,并致力于成为国际的存储类产品生产商及方案商。_深圳市东方旭升科技有限公司成立于2014年9月,是一家专业从事内存和固态硬盘产品设计、开发、生产及销售为一体的高新技术企业 东方旭升总部设立于中国深圳,并于2016年11月成立了香港海外销售公司---迅云国际有限公司,并于香港新界设立了国际物流仓库...

瓷器网汇集湖南醴陵优秀的陶瓷品牌和陶瓷生产厂家,提供全面的陶瓷招商加盟、陶瓷企业、陶瓷产品、陶瓷人才、陶瓷资讯、陶瓷大师、陶瓷展会、陶瓷知识、陶瓷品牌、醴陵陶瓷商城等全方位陶瓷行业信息。

卦无忧是传统思想和民俗文化内容知识网站,提供传统民俗文化,国学大全,星座生肖,起名打分,姻缘配对,黄历吉日等数百项免费知识内容大全。

【登丰体育】是一家专攻✅人造草坪✅休闲草坪✅运动草坪系统解决方案的制造商,公司产品包括创新多功能草坪,免填充人造草坪,系统改进对篮球草坪,门球草坪及后期的填充草坪有跟好的创新。经过同心协力的努力目前公司已取得多项体系认证,如iso质量管理体系,iso环境管理体系和职业健康管理体系等以及各类产品检测如机械性能,化学,环保,生物,国标等多项,产品出口已遍及全球三个大洲。

尚赫400亩全球总部持续火热建设中,尚赫教育培训基地、尚赫服务中心陆续投入使用,尚赫重视教育和服务,始终用爱与责任搭建属于尚赫家人们的事业发展平台。

泰州苏迹电力科技有限公司_自2017年成立以来,注册资金由500万元提升至1000万元,职工人员由创始之初的2人发展至今35人的团队...


汽车配件是要求很高的东西,而且它比较特殊,因为汽车是人们日常开的东西,所以它的健康一定要有确保,汽车配件一定是合格的,这就要求卖家必须真诚,那么汽车配件这么重要,该去哪里买,这里有一个网站叫做汽配网,这里的零部件非常的齐全,各种车型的零部件以及各种汽车的发动机系统,传动系统,行走系统,制动系统,转向系统,电器,车身及驾驶室,汽车用品,...。

雷锋网消息,2019年11月19日,世界人工智能融合发展大会在济南召开,大会上,富士康工业互联网董事长李军旗在做了,创新引领智造赋能,的主题分享,主要阐述了富士康在过去30年的发展中,如何更新的技术融合,来促进传统的电子制造行业不断发展,以下是李军旗在大会上的演讲内容,雷锋网做了不改变原意的整理和编辑,大家都知道,在30年前,我们每个...。

雷锋网AI科技评论消息,已经举办了14届的2018中国计算机大会,CNCC2018,将于2018年10月25日,27日在杭州国际博览中心,G20会场,举行,大会同期仍将举办规模更大的科技创新展,届时雷锋网将作为独家战略合作媒体进行全程跟踪报道,CNCC大会是国内规格最高的计算机会议,每届都会有很多大牛嘉宾莅临现场,就在今天CNCC20...。

年初以来,关于大模型落地应用的呼声愈发高涨,越来越多的目光开始瞄向行业大模型,在这一叙事体系下,大多数企业思考的核心问题开始变成大模型能够给企业带来什么,企业又该如何将自身业务更好地与AI技术做结合,但,,拿着锤子找钉子,真的是这一波AI浪潮中行业大模型落地的正确姿势吗,第四范式联合创始人兼总裁胡时伟告诉,在与企业沟通时,相较于...。

消息,10月29日,小米召开以,新起点,为主题的新品发布会,在发布会上,小米正式发布迈向AI全生态的小米澎湃OS2,XiaomiHyperOS2,,和小米15系列,其中小米15起售价4499元起,小米15Pro起售价5299元起,据悉,小米15Pro搭载了一块6.73英寸的2K等深四曲屏,支持全屏息屏显示和小米多屏同色超动态显示...。

美东时间8月8日,MagicLeapOne创造者版本正式在美国地区发货,售价2295美元起,HoloLens的开发者版本3000美元,早已经习惯了MagicLeap的拖延癌,好不容易等到他们发货了,雷锋网编辑已经没有激动的感觉,可能是此前的,概念视频,以及CEO阿伯维茨的推特让人平白激动了好多次吧,现在,MLOne的硬件参数终于整整...。

处女座最配星座第一名,金牛座星座配对指数,100星座配对比重,52,48星座配对点评,金牛座共性慵懒,但却能把你从铢锱算尽的弛缓形态中抽离进去,助你减慢速度,令你觉得身心轻松,乐而忘忧,金牛座谋求平和、稳如泰山的觉得,对金牛来说,你是个能令他忧心的对象,但是,青睐悠闲自在与安祥,领有优雅气质同性的金牛,却对你的精打细算与神经质感到厌烦...。

丰田威驰2023款1.5智能挡新车报价在6.8万元左右,这款车外观时兴,外部性能丰盛,操控性能和稳固性杰出,驾驶起来很有信念,同时,它的油耗体现低劣,能节俭燃油费用,爱护繁难,周期长,费用低,总的来说,我以为这款车性价比拟高,适宜器重适用性和燃油经济性的生产者,只管多少钱实惠,但安保性能和温馨性能丝毫不打折扣,是不错的选用,新车介绍,...。

你台铲车用那种发起机,可以的话再说分明台铲车的状况,柳工铲车50多少钱柳工zl50c的新车30万零3千,辽宁锦州沈阳基本是这个多少钱,其余的省市也差不多30的新车18万左右全新柳工50装载机铲车多少钱二手50装载机多少钱柳工50C如今价位在32万左右至于二手的就难说看车况~~给分吧...。

是路虎品牌旗下的揽胜极光敞篷版,这款车型驳回了两门四座的模式,其车辆全体外观和反常版本没有显著的区别,依然驳回了路虎品牌的家族设计理念,敞篷版本车型对比于硬顶版本车型,愈加受欢迎,揽胜极光的车身尺寸数据是什么车型车身尺寸数据长度4531毫米,车身尺寸数据宽度1904毫米,车身尺寸高度1650毫米,车身尺寸轴距2841毫米,车身尺寸前轮...。

西风雪铁龙c4是一款紧凑型车,其报价在20万左右,雪铁龙C4搭载了最新的技术,包含中央集控式方向盘和全新CVVT可变气门发起机,是一款异乎寻常的轿车,该车型包含五门轿车系列和三门coupe系列,其中c4,coupe并非便捷的三门版,而是设计师在五门c4轿车基础上启动全新外型,使其具备更具静止气质的外观,雪铁龙毕加索c4能源雪铁龙毕加索...。

沃尔沃XC90的缺陷关键包含培修老本高、燃油经济性不佳、温馨性无余以及内饰设计相对繁复,首先,沃尔沃XC90的培修老本相对较高,作为一款奢侈SUV,其零部件的多少钱以及培修工时费都较普通车型要高出不少,一旦车辆出现缺点或须要改换零部件,车主或许须要承当较大的经济压力,其次,沃尔沃XC90的燃油经济性体现并不出色,虽然其搭载了多款动力选...。

川菜市场,品牌为王,备受市场关注的当下,急剧扩大的市场需求也是吸引了不少创业者的加盟关注,就川菜加盟店10大品牌川菜店怎么加盟,感兴趣的朋友不妨跟着小编一起去了解一下,1、港剪鲍汁脱骨鸡港剪鲍汁脱骨鸡,研发了脱骨鸡美食的口感和外观,让港剪美食不仅仅受到食客青睐,更赢得市场认可,也是创业者们想要加盟的项目,2、湘炉小馆湘炉小馆是安徽湘炉...。

据路透社报道,意大利数据保护机构周五表示,已要求社交媒体巨头Facebook就其最新推出的智能眼镜做出说明,以评估该产品是否符合隐私法,Facebook的这款智能眼镜Ray,BanStories于周四推出,与雷朋共同合作开发,佩戴者可以听音乐、接听电话或拍摄照片和短视频,并且还可以通过Facebook服务中的配套app分享,这款智能眼...。

从被谷歌玩死了的ProjectAra项目开始,模块化技术渐渐获得了越来越多的关注,在这类技术的帮助下,在未来,果粉们或许只需要替换手机中的某些部件,就可以获得和新设备一样的配置,简直省钱有没有!但是,很多业界人士觉得时不时推出新品,让消费者抢得昏天暗地并没有什么不妥,另外,他们还认为,模块化技术只是看起来酷炫,实际上前途会很惨淡,最好...。

今日头条华为2022年分红超719亿元持股员工人均分红54.7万元近日,华为在内部论坛,心声社区,公布,经华为公司内部有权机构决议,拟向股东分配股利人民币719.55亿元,相比2021年分红总额614.04亿元,同比增加105.51亿,华为披露,公司通过工会实行员工持股计划,截至2021年12月31日员工持股计划参与人数为131507...。

1月18日消息,微创医疗旗下微创心通提交赴港上市申请书,摩根大通,花旗银行及中金公司担任其联席保荐人,上市前投资者股东包括CDG、GIC、海通基金、清池资本、高瓴资本、华泰证券等,其中,作为微创家族的一员,控股股东微创医疗持股50.06%,据招股书显示,微创心通医疗是一家医疗器械企业,专注于心脏瓣膜疾病领域的创新性和潜在最优整体解决方...。
