重磅!斯坦福 团队被曝抄袭中国大模型开源成果 AI 推特舆论开始发酵 (斯坦福llm)
过去一年,中国大模型一直被贴上「追赶美国」的标签,但近日,推特上却有人曝出:
美国斯坦福大学的一个 AI 团队疑似抄袭、「套壳」一家中国大模型公司的开源成果,模型架构与代码完全相同。
舆论已经开始发酵,引起了圈内人士的广泛讨论。
根据 AI 科技评论整理,事情的经过大致如下:
5 月 29 日,斯坦福大学的一个研究团队发布了一个名为「Llama3V」的模型,号称只要 500 美元(约等于人民币 3650 元)就能训练出一个 SOTA 多模态模型,且效果比肩 GPT-4V、Gemini Ultra 与 Claude Opus 。
由于该团队的作者(Mustafa Aljaddery、Aksh Garg、Siddharth Sharma)来自斯坦福,又集齐了特斯拉、SpaceX、亚马逊与牛津大学等机构的相关背景经历,很快该模型发布的推特帖子浏览量就已经超过 30 万,转发 300+次,并迅速冲到了 Hugging Face 首页:
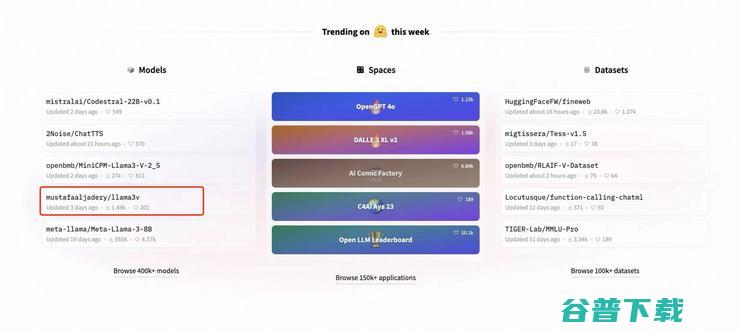
但很快,没过几天,推特与 Hugging Face 上就开始出现怀疑的声音,质疑 Llama3V 套壳面壁智能在 5 月中旬发布的 8B 多模态小模型 MiniCPM-Llama3-V 2.5,且没有在 Llama3V 的工作中表达任何「致敬」或「感谢」 MiniCPM-Llama3-V 2.5 的声音。
对此,Llama3V 团队回复,他们「只是使用了 MiniCPM-Llama3-V 2.5 的 tokenizer」,并宣称「在 MiniCPM-Llama3-V 2.5 发布前就开始了这项工作」。
紧接着,6 月 2 日,有网友在 Llama3V 的 Github 项目下抛出事实性质疑,但很快被 Llama3V 的团队删除。为此,提出质疑的网友被激怒暴走,跑到了 MiniCPM-V 的 Github 页面进行事件还原,提醒面壁智能团队关注此事。
随后,面壁团队通过测试 ,发现 Llama3V 与 MiniCPM-Llama3-V 2.5 在「胎记」般案例上的表现 100% 雷同,「不仅正确的地方一模一样,连错误的地方也一模一样」。
至此,推特舆论开始发酵,「斯坦福抄袭中国大模型」一事不胫而走。
1、「套壳」证据实锤,斯坦福团队百口莫辩
最开始,用户质疑 Llama3V 套壳 MiniCPM-Llama3-V 2.5 开源模型时,Llama3V 作者团队并不承认,而是声称他们只是「使用了 MiniCPM-Llama3-V 2.5 的 tokenizer」,并宣称他们「在 MiniCPM-Llama3-V 2.5 发布前就开始了这项工作」:



不过,好心网友对 Llama3V 作者团队的回应并不买单,而是在 Llama3V 的 Github Issue 上发布了一系列质疑,列举具体 4 点证据,但很快被 Llama3V 的团队删除。幸好作者事先截了图保留:

面对网友的质疑,Llama3V 作者只是避重就轻地回复,称他们只是使用了 MiniCPM 的配置来解决 Llama3V 的推理 bug,并称「MiniCPM 的架构是来自 Idéfics,SigLIP也来自 Idéfics,他们也只是追随 Idéfics 的工作」而非 MiniCPM 的工作,因为「MiniCPM 的视觉部分也是来自 Idéfics 的」——

并且将原来 readme 里引用致谢 「MiniCPM-Llama3 」改为了「致谢 MiniCPM」:

但根据网友的复盘、梳理,Llama3V 并非只是简单的借鉴,而是有 4 点证据能充分表明其「套壳」了 MiniCPM-Llama3-V 2.5。
证据 1:
Llama3V 项目使用了与 MiniCPM-Llama3-V 2.5 项目完全相同的模型结构和代码实现。
Llama3-V 的模型结构和配置文件与 MiniCPM-Llama3-V 2.5 完全相同,只是变量名不同。

Llama3-V 的代码是通过对 MiniCPM-Llama3-V 2.5 的代码进行格式调整和变量重命名得到的,包括但不限于图像切片方式、tokenizer、重采样器和数据加载:

证据 2:
Llama3V 团队称其「引用了 LLaVA-UHD 作为架构」,但事实是 Llama3V 与 MiniCPM-Llama3-V 2.5 结构完全相同,但在空间模式等多方面却与 LLaVA-UHD 有较大差异。
Llama3-V 具有与 MiniCPM-Llama3V 2.5 相同的标记器(tokenizer),包括 MiniCPM-Llama3-V 2.5 新定义的特殊标记:

证据 3:
Llama3V 作者曾在 Hugging Face 上直接导入了 MiniCPM-V 的代码,后改名为 Llama3V。事件发酵后,AI 科技评论打开 Hugging Face 页面发现已经「404」:

作者回应删除 Hugging Face 仓库的原因是「修复模型的推理问题」,并称他们「尝试使用 MiniCPM-Llama3 的配置,但并没有用」:

戏剧效果拉满的是,该网友随后贴出了如何使用 MiniCPM-Llama3-V 的代码,跑通 Llama3V 模型推理的详细步骤。

当 Llama3V 的作者被询问如何能在 MinicPM-Llama3-V2.5 发布之前就使用它的 tokenizer 时(因为其一开始称他们在 MinicPM-Llama3-V2.5 发布前就已经开始了 Llama3V 的研究),Llama3V 的作者开始撒谎,称是从已经发布的上一代 MinicPM-V-2 项目里拿的tokenizer:

但事实是,据 AI 科技评论向面壁团队了解,MiniCPM-V-2 的 tokenizer 与 MinicPM-Llama3-V2.5 完全不同,在Huggingface 里是两个文件,「既不是同一个 tokenizer 件,文件大小也完全不同」。
MinicPM-Llama3-v2.5 的 tokenizer 是 Llama3 的 tokenizer 加上 MiniCPM-V 系列模型的一些特殊 token 组成,MiniCPM-v2 因为在 Llama3 开源之前就发布,所以不会有 Llama3 的 tokenizer :


证据 4:
Llama3V 的作者删除了 GitHub 上的相关 issue,并似乎不完全理解 MinicPM-Llama3-V2.5 的架构或 Llama3V 自己的代码。
Perceiver重采样器是一个单层的交叉注意力机制,而不是两层自注意力机制。SigLIP 的 Sigmoid 激活函数并未用于训练多模态大型语言模型,而仅用于 SigLIP 的预训练。
但 Llama3V 在论文中的介绍却说其采用了两层自注意力机制:

而 MiniCPM-Llama3-V 2.5 和 Llama3V 代码如下,体现的却是单层交叉注意力机制:

MiniCPM-Llama3-V 2.5:

且视觉特征提取不需要激活 sigmoid:



2、推特舆论发酵,面壁回应
6 月 2 日下午,该事件开始在推特上发酵,MiniCPM-V 的作者亲自发帖,表示「震惊」,因为斯坦福的 Llama3V 模型居然也能识别「清华简」。
据 AI 科技评论向面壁团队了解,「清华简」是清华大学于 2008 年 7 月收藏的一批战国竹简的简称;识别清华简是 MiniCPM-V 的「胎记」特征。该训练数据的采集和标注均由面壁智能和清华大学自然语言处理实验室团队内部完成,相关数据尚未对外公开。
斯坦福的 Llama3V 模型表现与 MiniCPM-Llama3-V 2.5 检查点的加噪版本高度相似:


以下是面壁团队成果与 Llama3V 对「清华简」的识别对比。结果显示,两个模型不仅正确的地方一模一样、错误的地方也雷同:

Q:请识别图像中的竹简字?
MiniCPM-Llama3-V 2.5:民
Llama3-V:民
GT:民
错误识别示例:

Q:请识别图像中的竹简字?
MiniCPM-Llama3-V 2.5:君子
Llama3-V:君子
GT:甬
以下是在 1000 个清华简字体上的识别效果:

可以看到,Llama3V 与 MiniCPM-Llama3-V 2.5 的重叠高达 87%,且两个模型的错误分布律高度相似:Llama3V 的错误率为 236,MiniCPM-Llama3-V 2.5 的错误率是 194,两个模型在 182 个错误识别上相同。
同时,两个模型在清华简上的高斯噪声也同样高度相似:

此外,Llama3V 的 OCR 识别能力在中文字上也与 MiniCPM-Llama3-V 2.5 高度相似。对此,面壁团队表示,他们很好奇斯坦福团队是如何只用「500 美元就能训练出这么高深的模型性能」。
根据公开信息显示,Llama3V 的两位作者 Siddharth Sharma 与 Aksh Garg 是斯坦福大学计算机系的本科生,曾发表过多篇机器学习领域的论文。
其中,Siddharth Sharma 曾在牛津大学访问、在亚马逊实习;Aksh Garg 也曾在 SpaceX 实习。
这件事反映出,AI 研究的投机分子不分国度。
同时,也反映出,中国科研团队的开源大模型实力已经冲出国门,逐渐被越来越多国际知名的机构与开发者所关注、学习。
中国大模型不仅在追赶世界顶尖机构,也正在成为被世界顶尖机构学习的对象。
由此可见,今后看客们审视国内外的大模型技术实力对比,应该多一份民族自信、少一点崇洋媚外,将关注度多聚焦在国内的原创技术上。
最后,一句话总结:投机不可取,永争创新一。
原创文章,未经授权禁止转载。详情见 转载须知 。



潍坊草本堂日用制品有限公司专业从事卫生杀虫剂系列产品,洗涤用品生产与销售的一体化企业,主要产品有双雕牌与双虎牌金枪杀虫系列以及月亮船洗衣液系列.销售热线:135-0896-5026

六盘水人才招聘网是六盘水在线求职招聘平台,提供人才求职,企业招聘,名企及国企招聘公告发布平台。致力于打造具有影响力的六盘水人才网和六盘水人才市场,六盘水招聘找工作,就上六盘水人才网!

天津永迪钢铁贸易有限公司主要销售Q345D无缝钢管-Q345E无缝钢管-厚壁无缝钢管-20G高压锅炉管-石油裂化管-镀锌无缝钢管-无缝方矩管热线:13902026479

江西宝林天然香料有限公司(www.jxbaolin.com)是新铃兰醛,氮酮月桂氮酮,百里香酚麝香草酚现货供应商

主要用于,市政府,政务公开,解读回应,办事服务,互动交流,专题专栏,印象晋江,其他,栏目结构,首页图片,闽政通App,嵌套,搜索服务,等信息的发布

{$obj.description}

安徽睿鲲建设有限公司专注于临时建筑行业,业务范围有打包式箱房项目部、活动板房、钢结构、定型化、垃圾分类岗亭和配套围墙设施等。

深圳市欣辰珠宝文化有限公司

中国现象级休闲手游,独立手游,独立工作室Superpop&Lollipop打造的纯免费手游,良心手游,年轻人的最爱。深受00后玩家喜爱,引领潮流竞技,充满竞技性的手游。

金麦粒为上市/拟上市公司提供舆情监测,财经公关,危机公关,IPO/常年价值管理,合规咨询顾问,危机管理顾问,资本运作管理等服务,通过创新、专业、高效的综合管理服务,提升上市/拟上市公司的资本价值影响力。

骐翔企业管理咨询有限公司

菜狗简历模板网为您提供word个人简历模板、求职简历模板、英文简历模板、应届生简历模板、工作简历模板、护士简历模板、实习简历模板、应聘简历模板等免费下载,让您更轻松获得应聘成功。

足疗,实现养生的一种方式,以专业的技法来按摩脚底穴位,或者是修甲,不拘哪一种方式,总归能让人倍感轻松,当周围的人们生活条件都提高了以后,定期去足疗店休闲一番的人数也并不少,这种状况下加盟足疗店是个很合适的选择,不过,一般的足疗店想在重重竞争直供脱颖而出并不是简单的事情,于是有了创立足疗项目的出现,我们今天要了解的是,创立足疗加盟店需要...。

WiFicoin发起人刘登丰和他的团队伙伴,应该算是硬件圈投身区块链创业热潮的一个小小缩影,2015至2016年,智能WiFi曾在智能硬件行业激起一小簇浪花,当时,大大小小的互联网巨头,如小米、360等均在此投入和产出,然而,随着智能硬件的潮落、人工智能的潮起,这簇浪花终究隐没远去,在沉寂一年多后,2017年年底,区块链被炒币和ICO...。

近日,各地开始公示工业与信息化部第四批专精特新,小巨人,企业培育的审核名单,本次培育审核工作是为深入贯彻习近平总书记关于,培育一批‘专精特新中小企业,的重要指示精神,落实党中央、国务院,关于促进中小企业健康发展的指导意见,而开展的,专精特新,是国家引导中小企业增强自主创新能力和核心竞争力,不断提高中小企业发展质量和水平而实施的重大...。

黄学东领衔,微软Azure认知服务研究团队重磅发布,视觉,语言,语音,多模态预训练模型i,Code,在5项多模态视频理解任务以及GLUENLP任务上树立了业界新标杆!编译丨OGAI人类的智能涉及多个模态,我们整合视觉、语言和声音信号,从而形成对世界全面的认识,然而,目前大多数的预训练方法仅针对一到两种模态设计,在本文中,我们提出了一种...。

发表在专业问答2020,5,615,47展示机型信息,品牌型号,当贝F3系统版本,当贝OS2.0dlp投影仪中的显示芯片是成像器件,芯片上有千万个微镜片,每个微镜片都具有独立控制光线的开关能力,当光源的光经过色轮后,抵达显示芯片,通过微镜片调节反射光,由此形成亮度不同的灰色等级图像,投影仪dlp显示芯片的意思dlp投影仪中的显示芯片是...。

发表在专业问答2022,2,1414,49展示机型信息,品牌型号,当贝x3系统版本,当贝OS2.0软件版本,银河奇异果12.2爱奇艺会员在电视上不能用,手机的爱奇艺会员和电视的爱奇艺会员并不通用,爱奇艺与电视端银河奇异果TV属于合作关系,不支持黄金会员直接升级为电视会员,可以尝试将手机投屏的方式观看会员内容,爱奇艺会员在电视上能用吗爱...。

△明尼苏达州州长蒂姆·沃尔兹央视记者得知,外地期间8月6日,美国副总统哈里斯在给允许者的短信中示意,她已选用明尼苏达州州长蒂姆·沃尔兹作为其竞选伙伴,也就是独裁党副总统候选人,参与往年大选,据悉,哈里斯今日晚些时刻将在宾夕法尼亚州费城一场竞选优惠上正式引见沃尔兹,沃尔兹往年60岁,曾任美国联邦众议员,于2018年入选明尼苏达州州长,2...。

安保无毒,请安心下载·AdobePhotoshopCS4V1.4龙卷风污浊装置版,大小,249MB,·AdobePhotoshopCS4Extended完美增强装置版,大小,230MB,·AdobePhotoshopCS4Extended官方简体完美增强装置版,大小,229MB,·AdobePhotoshopCS4中文版,大小,68....。

富士施乐SC2022打印机驱动是一款专门为富士施乐sc2022型号打印机打造的驱动软件,包含打印驱动和扫描驱动,适用于Windows操作系统使用

植物大战僵尸是款经典的策略小游戏,此次为大家带来植物大战僵尸2010年度版,与一般版本不同的是除了加入迪斯科僵尸之外,新增了20个成就,还加入了全新的“僵尸化身”模式,不同的玩法让你耳目一新。植物大战僵尸只有这些吗?当然不是啦,更多资讯、教程与特色等你来一一体验吧。如果你需要这样一款植物大战僵尸的话,赶快到完美下载安装使用吧。

复旦大学团队发布中文医疗健康个人助手,开源47万高质量数据集,样本,医疗,大模型,复旦大学,个人助手

随着新版本的更新,逆战官网也迎来了很多惊喜活动,很多玩家都非常感兴趣,想知道逆战2022新线索怎么刷,小编就带来了逆战2022线索顺序攻略分享给大家,一起来看看吧。,逆战2022新线索怎么刷逆战2022线索顺序攻略

如今人们的生活水平提高,在寒冷的冬季,人们会购买羽绒服来进行御寒,由于不同的衣物使用的材质不一样,使得许多的消费者群体,会到干洗店进行保养和清洗,确保衣物的舒适度和鲜艳的色彩,澳洁洗衣店作为一家知名的干洗品牌,多年来一直以绿色的使用原料为主,结合先进的洗衣设备使用,为众多的消费者提供了贴心的服务,是加盟人士创业的选择,那么怎么开好一家...。

最近雷锋网从法官那些事微信公众号上看到点新鲜东西,顿时目瞪狗呆,一组来自民政局官网的数据显示,今年上半年全国新婚了558万对夫妇,同时有185万对离婚,离婚率最高的城市分别是北、上、深、广,▲全国2017上半年婚姻人口总数据这也不算奇怪,大城市嘛,生活节奏快,感情……散的也快,但令人惊讶的是,离婚的六大原因,NO.6购房需要,爱情诚可...。

文字链接认证代码普通联盟标志认证代码企业广告联盟标志认证代码广告联盟评测代码说明,本页面的认证代码为蓝色广告联盟专用评测代码,站长需懂简单html知识,直接复制代码粘贴到联盟网站相应页面即可使用,本代码不适用于其他广告联盟网站请勿获取!文字认证,文字链接代码认证适用所有类型的广告联盟,复制代码后放在蓝色广告联盟网站首页底部或友情链接位...。
在穿越火线,cf,这款备受欢迎的射击游戏中,信誉积分是衡量玩家游戏行为和诚信度的重要指标,高信誉积分的玩家不仅能在游戏中获得更多的尊重和特权,还能享受到更好的游戏环境,那么,如何查询自己的cf信誉积分呢,本文将为您提供详细的查询方法,一、通过穿越火线官网查询1.打开浏览器,访问穿越火线官网,[http,cf.qq.com,cp,a...。

很多人都被脱发、白发以及头发的问题困扰着,头发是一个人形象的体现,很多人就想要拥有靓丽飘逸的发型,对于一些有困扰的人群,他们就想要能够有一个一劳永逸的方法,能够解决这种问题的困扰,岳灵生发就是一个非常受欢迎的产品,产品的质量高,还受到了广泛消费者的信赖,如果加盟的话,究竟养发的市场有潜力吗,岳灵生发好吗,养发的市场有潜力吗现在上班族的...。
