从 再到 Vision Action 万字漫谈三年跨域信息融合研究 Language 到 (从再到再到)
雷锋网 AI 科技评论按:本文作者为阿德莱德大学助理教授吴琦,他在为雷锋网 AI 科技评论投递的独家稿件中回顾了他从跨领域图像识别到Vision-to-Language 相关的研究思路,如今正将研究领域延伸到与 Action 相关的工作。雷锋网 AI 科技评论对文章做了不改动原意的编辑。
大家好,我叫吴琦,目前在阿德莱德大学担任讲师(助理教授)。2014 年博士毕业之后,有幸加入澳大利亚阿德莱德大学(University of Adelaide)开始为期 3 年的博士后工作。由于博士期间主要研究内容是跨领域图像识别,所以博士后期间,原本希望能够继续开展与跨领域相关方面的研究。但是,在与博士后期间的导师 Anton van den Hengel、沈春华教授讨论之后,决定跳出基于图像内部的跨领域研究,而展开图像与其他外部领域的跨领域研究。恰逢 2015 年 CVPR 有数篇 image captioning 的工作,其中最有名的当属 Andrej Karpathy 的 NeuralTak 和 google 的 Show and Tell,同时 2015 年的 MS COCO Image Captioning Challenge 也得到了大量的关注。所以当时就决定开始研究与 Vision-to-Language 相关的跨领域问题。后来也在这个问题上越走越深,近三年在 CVPR,AAAI,IJCAI,TPAMI 等顶级会议与期刊上,先后发表了 15 篇与 vision-language 相关的论文,近期我们又将这个问题延伸到了与 Action 相关的领域,开启了一个全新的方向。接下来我就介绍一下我的一些研究思路,工作,以及我对这个领域的一些想法。
我们 15 年第一个研究的问题是围绕 image captioning 展开的,当时这个方向的主流模型是基于 CNN-RNN 框架的,即输入一张图像,先用一个 pre-trained 的 CNN 去提取图像特征,然后,将这些 CNN 特征输入到 RNN,也就是递归神经网络当中去生成单词序列。这种模型表面上看起来非常吸引人,依赖于强大的深度神经网络,能够用 end-to-end 的方式学习到一个从图像到语言(vision2language)的直接对应关系,但忽略了一个重要的事实是, 图像和语言之间,其实是存在鸿沟的。 虽然我们用神经网络将图像空间和语言空间 embed 在同一个空间当中,但直觉上告诉我,这两个空间应该需要一个共同的 sub-space 作为桥梁来连接。于是我们想到了 attributes,一种图像和语言都拥有的特征。于是, 基于上面提到的 CNN-RNN 结构,我们多加了一个 attributes prediction layer。当给定一张图像,我们先去预测图像当中的各种 attributes(我们的 attributes 定义是广义的,包括物体名称,属性,动作,形容词,副词,情绪等等),然后再将这些 attributes 代替之前的 CNN 图像特征(如图 1),输入到 RNN 当中,生成语句。
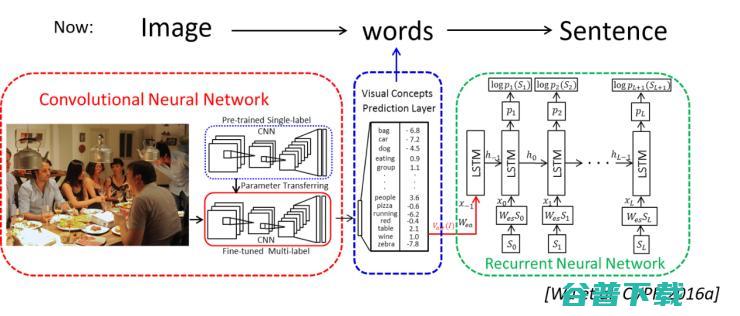
图 1:从图像到词语再到语句的 image captioning 模型
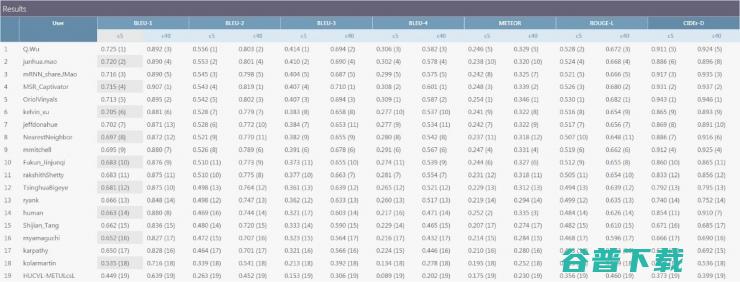
我们发现这个简单的操作使我们的 image captioning 模型得到了大幅度的提升(见图 2),并使得我们在 15 年 12 月的 MS COCO Image Captioning Challenge Leader Board 上在多项测评中排名第一(见图 3)。论文后来也被 CVPR 2016 接收,见论文 [1]。

看到 attributes 在 image captioning 上的作用之后,我们开始考虑,相同的思路是否可以扩展到更多的 vision-and-language 的问题上?毕竟, vision 和 language 之间的 gap 是客观存在的,而 attributes 能够有效地缩小这种 gap。于是我们尝试将相同的框架运用在了 visual Question answering(VQA)上(见图 4),也取得了非常好的效果。相关结果已发表于 TPAMI,见论文 [2].
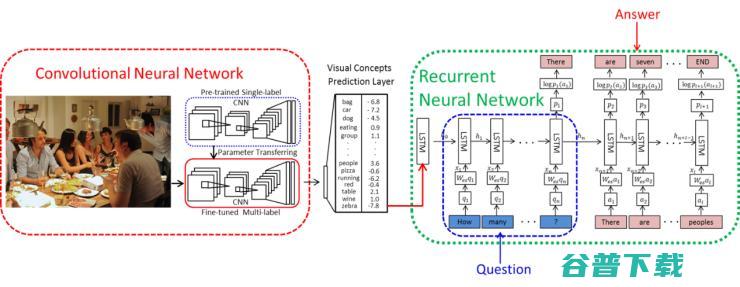
然而, VQA 与其他 vision-to-language 不同的是,当它需要一个机器去回答一个关于图片内容的问题的时候,机器不仅需要能够理解图像以及语言信息,还要能够具有一定的常识 ,比如,如图 5 左边所示,问题是图中有几只哺乳动物。那么回答这个问题,我们不仅需要机器能够「看」到图中有狗,猫,鸟,还需要机器能够「知道」狗和猫是哺乳动物,而鸟不是,从而「告诉」我们正确答案是 2.

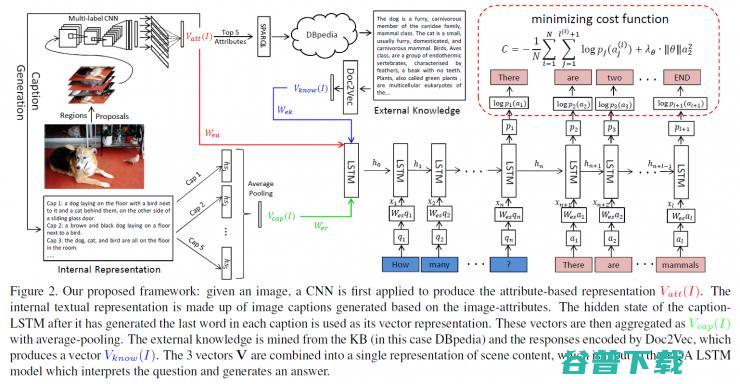
于是,我们就自然想到了将知识图谱(knowledge-base)引入到 VQA 当中,帮助我们回答类似的问题。那么该如何连接起图像内容和 knowledge base 呢?我们的 attributes 这时候就又发挥了作用。我们 先将图像当中的 attributes 提取出来,然后用这些 attributes 去 query knowledge base(DBpedia),去找到相关的知识,然后再使用 Doc2Vec 将这些知识信息向量化,再与其他信息一起,输入到 lstm 当中,去回答问题。 我们的这个框架(见图 6)在 VQA 数据集上取得非常好的表现,相关论文结果已发表于 CVPR 2016,见论文 [3].
虽然我们上面提出的框架解决了回答关于「common sense」的问题的挑战,但是我们发现在 VQA 当中还有两个重要的局限:
第一个局限指的是, computer vision 其实在 VQA 当中的作用太小了 ,我们仅仅是使用 CNN 去对图片当中的物体等内容进行理解。而一个基于图片的问题,可能会问物体之间的关系,物体中的文字等等,而这其实是需要多种的计算机视觉算法来解决的。
第二个局限指的是,在回答问题的过程当中,我们没有办法给出一个合理的解释。而恰恰是近几年来大家都很关注的一个问题。如果我们在回答问题的过程当中,还能够提供一个可理解的原因,将是非常有帮助的。
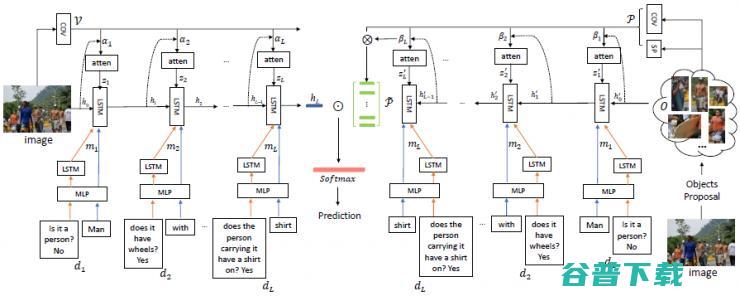
那么基于上面这两点,我们就提出了一种新的 VQA 结构,我们称之为 VQA machine。这个模型 可以接收多个 computer vision 算法输出的结果 ,包括 object detection,attributes prediction,relationship detection 等等,然后将这些信息进行融合,得出答案。同时, 我们的 VQA Machine 除了输出答案之外,还可以输出原因。 在这个模型中,我们首先将问题从三个 level 来 encode。在每个 level,问题的特征与图像还有 facts 再一起 jointly embed 在一个空间当中,通过一个 co-attention model。这里的 facts 是一系列的,利用现有计算机视觉模型所提取出的图像信息。最后,我们用一个 MLP 去预测答案,基于每一层的 co-attention model 的输出。那么回答问题的原因是通过对加权后的 facts 进行排序和 re-formulating 得到的(见图 7)。
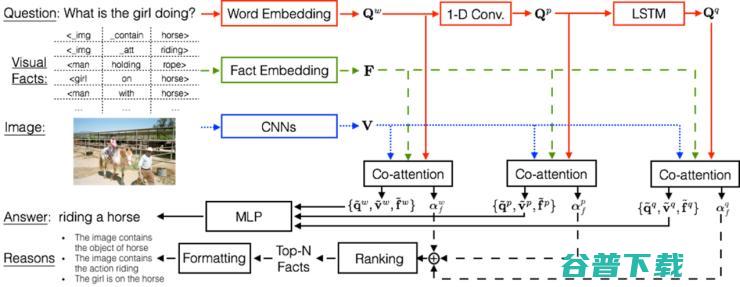
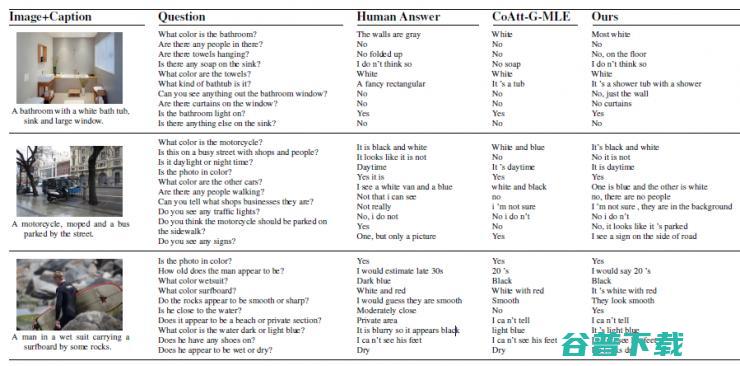
我们的这个模型在 VQA 数据集上取得了 state-of-art 的表现(见表 1),更重要的是,它在回答问题的同时,能够给出对应的解释,这是其他的 VQA 模型所做不到的。图 8 给出了一些我们模型产生的结果。论文已经发表在 CVPR 2017,见论文 [4].
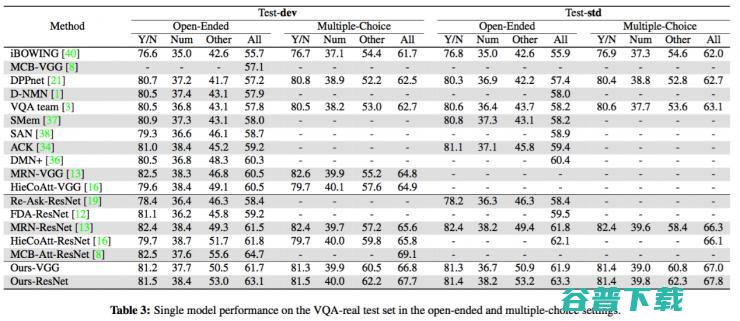

图 8:VQA Machine 结果,问题中带颜色的词表示 top-3 的权重。代表了这个词在回答这个问题时的重要程度。图像当中高亮的区域表示图像当中 attention weights。颜色越深的区域说明这个区域对回答问题更重要。最后是我们模型生成的回答问题的原因。
既然我们知道了 knowledge 和 reasoning 对 VQA 都很重要,那么怎么将它们两个结合在一起,同时能够进行 explicit reasoning(显示推理)呢?所谓 explicit reasoning,就是在回答问题的过程当中,能够给出一条可追溯的逻辑链。 于是我们又提出了 Ahab,一种全新的能够进行显式推理的 VQA 模型。 在这个模型当中,与以往直接把图像加问题直接映射到答案不同,Ahab 首先会将问题和图像映射到一个 KB query,也就是知识图谱的请求,从而能够接入到成千上万的知识库当中。另外,在我们的模型当中,答案是 traceable 的,也就是可以追踪的,因为我们可以通过 query 在知识图谱当中的搜索路径得到一个显式的逻辑链。
图 9 展示了我们这一方法。我们的方法可以分成两部分。
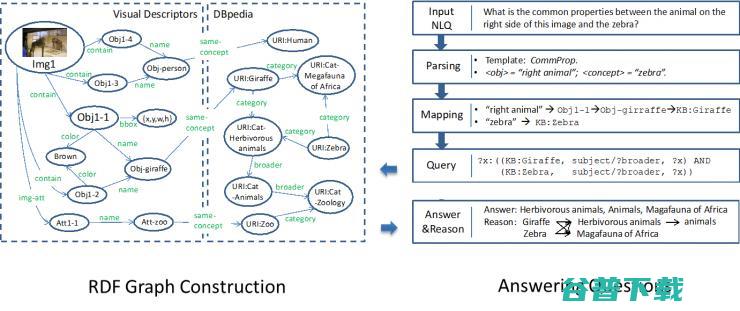
最近我们又建立了一个新的 VQA 数据集叫做,就是基于事实的 VQA。我们之前的基于 explicit reasoning 的数据集只能接受固定的模板式的问题,而新的 FVQA 数据集提供了开放式的问题。除此之外,对每一对问题-答案,我们额外提供了一个 supporting fact。所以在回答问题的时候,我们不仅需要机器回答出这个问题,而且还需要它能够提供关于这个回答的 supporting fact。图 10 展示了我们 Ahab 和 FVQA 模型和数据的一些例子。相关数据与结果分别发表于 IJCAI 2017 和 TPAMI,见论文 [5,6]

从 VQA 可以衍生出很多新的问题,Visual Dialog(视觉对话)就是其中一个。与 VQA 只有一轮问答不同的是,视觉对话需要机器能够使用自然的,常用的语言和人类维持一个关于图像的,有意义的对话。与 VQA 另外一个不同的地方在于,VQA 的回答普遍都很简短,比如说答案是 yes/no, 数字或者一个名词等等,都偏机器化。而 我们希望 visual dialog 能够尽量的生成偏人性化的数据。 比如图 11 所示,面对同样的问题,偏人类的回答信息量更丰富,也更自然,同时能够关注到已经发生的对话,并且引出接下来要发生的对话。而偏机器的回应,就非常的古板,基本没法引出下面的对话。

于是我们提出了一个基于 GAN(生成对抗网络) 的方法 (图 12),来帮助模型生成更加符合人类预期的回答。我们左边的生成网络是使用了一个 co-attention,也就是一个联合注意力模型,来联合的使用图像,对话历史来生成新的对话,然后我们将生成的对话以及从生成模型中得出的 attention,一起,送入到一个区别模型当中,去区别对话为人工产生还是自动生成,然后通过 reward 的形式,去鼓励模型生成更加符合人类的对话。
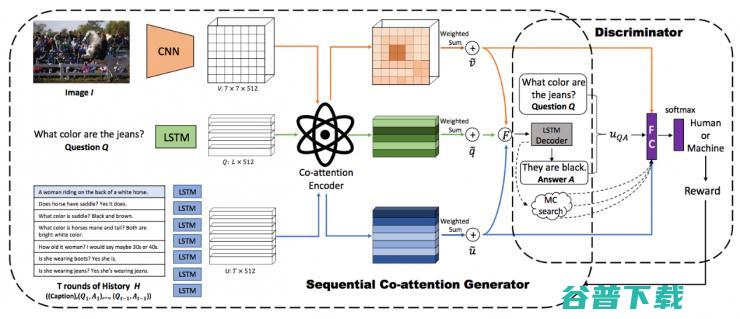
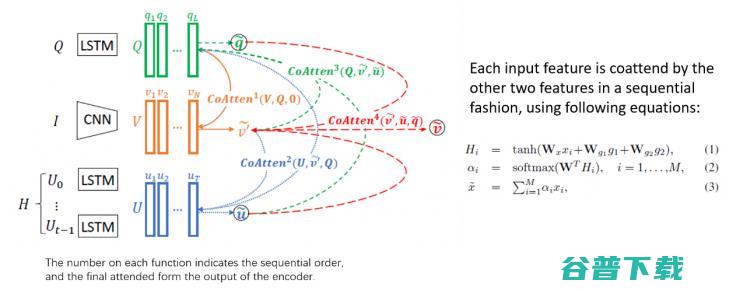
这项工作中,我们使用了一个 co-attention 的模型,来融合来自各个模态的信息,相同的模型也用在我们上面提到的 VQA-machine 当中。在一个 co-attention 模型当中,我们使用两种特征去 attend 另外一种特征,从而进行有效地特征选择。这种 attend 模式会以 sequential 的形式,运行多次,直到每个输入特征,均被另外两个特征 attend 过。该论文 [7] 被 CVPR2018 接受,大会 oral。
前面简单介绍了一些我们在 vision-language 方向上的工作,可以看到,两者的结合无论在技术上还是应用上,都非常的有意义。然而,对于人工智能(AI)而言,这只是一小步。真正的人工智能,除了能够学习理解多种模态的信息,还应该能与真实环境进行一定程度的交互,可以通过语言,也可以通过动作,从而能够改变环境,帮助人类解决实际问题。那么从今年开始,我们开始将 action 也加入进来,进行相关的研究。
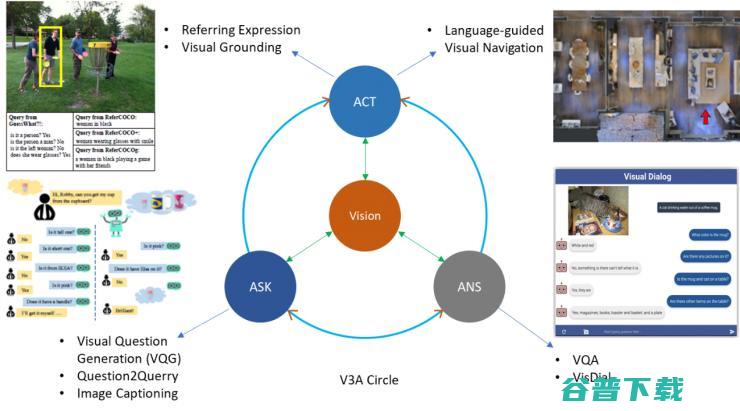
我为此提出了一个 V3A 的概念,就是 Vision,Ask,Answer and Act(如图 15),在这个新的体系当中, 我们以视觉(Vision)作为中心,希望能够展开提问(Ask),回答(Answer),行动(Act)等操作。 这样,我们不仅能够得到一个可训练的闭环,还将很多之前的 vision-language 的任务也融合了进来。比如在 Ask 这一端,我们可以有 Visual Question Generation,image captioning 这样的任务,因为他们都是从图像到语言的生成。在 Answer 这一端,我们可以有 VQA,Visual Dialog 这样需要机器能够产生答案的模型。在 Act 端,我们也有会有一些很有意思的任务,比如 referring expression 和 visual navigation。那么我们在今年的 CVPR2018 上,在这两个方面,都有相关的工作。
首先谈一下 referring expression,也叫做 visual grounding,它需要机器在接受一张图片和一个 query(指令)之后,「指」出图片当中与这个 query 所相关的物体。为了解决这个问题,我们提出了一个统一的框架,ParalleL AttentioN(PLAN)网络,用于从可变长度的自然描述中发现图像中的对象。自然描述可以从短语到对话。PLAN 网络有两个注意力机制,将部分语言表达与全局可视内容以及候选目标直接相关联。此外,注意力机制也是重复迭代的,这使得推理过程变的可视化和可解释。来自两个注意力的信息被合并在一起以推理被引用的对象。这两种注意机制可以并行进行训练,我们发现这种组合系统在不同长度语言输入的几个标准数据集上的性能优于现有技术,比如 RefCOCO,RefCOCO +和 GuessWhat 数据集。论文见 [8]。我们还提出了一个基于 co-attention 的模型,论文见 [9]。
接下来再给大家介绍一篇我们关于 Visual Navigation 的文章 [10],该论文也被 CVPR2018 接受,由于 topic 比较新颖,也被大家关注。这篇文章叫「Vision-and-Language Navigation: Interpreting visually-grounded navigation instructions in real environments」。我们这篇文章想要解决的一个问题就是如何使用一段复杂的人类语言命令,去指导机器人在模拟的真实环境当中,去完成对应的动作和任务。
那么在这篇文章当中,我们首先提出了一个 Matterport3D Simulator。这个 simulator 是一个大规模的可基于强化学习的可交互式环境。在这个 simulator 的环境当中,我们使用了 10800 张 densely-sampled 360 度全景加深度图片,也就是说可以提供到点云级别。然后我们总共有 90 个真实世界的室内场景。那么与之前一些虚拟环境的 simulator 而言,我们和这个新的 simulator 更具有挑战性,同时更接近于实际。图 17 展示了我们的一个真实场景以及机器人(agent)可移动的路线。
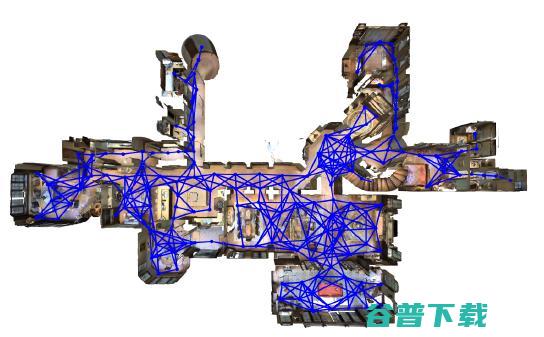
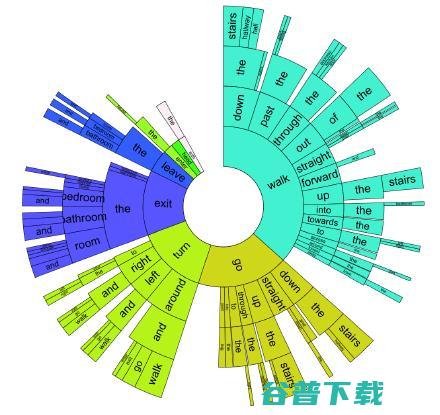
基于我们的 Matterport3D Simulator,我们又收集了一个 Room-to-Room (R2R) 的数据集,在这个数据集当中,我们收集了 21567 条 navigation instruction(导航指令),平均长度为 29 个单词。每一条指令都描述了一条跨越多个房间的指令。如图 18 所示。图 19 显示了我们导航指令的用词分布。
那么除了上述 simulator 和数据,我们这篇文章还提出了一个 sequence-to-sequence 的模型,改模型与 VQA 模型非常类似,只是将输出动作作为了一种 sequence,用 LSTM 来预测。我们还加入了诸如 teacher-forcing,student-forcing 等变种,取得了更好的效果。我们接下来会继续扩充数据,并保留测试集,提供公平的测试平台,每年举行相关的比赛。请大家关注!

图 18:Room-to-Room (R2R) navigation task. We focus on executing natural language navigation instructions in previously unseen real-world buildings. The agent's camera can be rotated freely. Blue discs indicate nearby (discretized) navigation options
人工智能是一个非常复杂的整体的系统,涉及到视觉,语言,推理,学习,动作等等方面,那么计算机视觉作为人工智能领域内的一个方向,除了关注经典的纯视觉的问题(比如图像识别,物体分类等),也应该关注如何与其他领域相结合来实现更高难度的任务与挑战。视觉与语言(vision-language)的结合就是一个非常好的方向,不仅引出了像 image captioning 和 VQA 这种有意思的问题,还提出了很多技术方面的挑战,比如如何融合多领域多维度的信息。 我们进一步将 vision-language 引入到了 action 的领域,希望机器能够具有问(Ask),答(Answer)和作(Act)的能力,实质上就是希望机器能够理解和处理视觉信息,语言信息,并输出对应的动作信息,以完成更高程度的跨域信息融合。
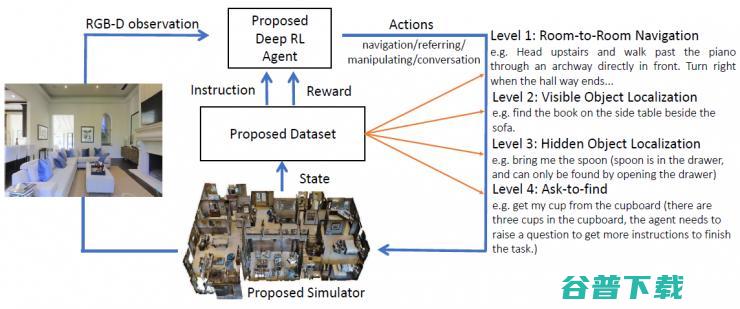
接下来我们将继续在 vision-language-action 的方向上做更多的探索,目前的 room-to-room navigation 数据集只是第一步,我们接下来将基于我们的 Matterport3D Simulator, 进一步提出 Visible Object Localization,Hidden Object Localization 和 Ask-to-find 的任务(如图 20),希望 agent 能够通过基于语言的指令,在场景中导航定位到可见(Visible)的物体,隐藏(Hidden)的物体,以及当指令存在歧义时,能够提出问题,消除歧义,从而进一步完成任务。

吴琦现任澳大利亚阿德莱德大学(University of Adelaide)讲师(助理教授),澳大利亚机器视觉研究中心(Australia Centre for Robotic Vision)任 Associate Investigator(课题副组长)。在加入阿德莱德大学之前,担任澳大利亚视觉科技中心(Australia Centre for Visual Technologies)博士后研究员。分别于 2015 年,2011 年于英国巴斯大学(University of Bath)取得博士学位和硕士学位。他的主要研究方向包括计算机视觉,机器学习等,目前主要研究基于 vision-language 的相关课题,包括 image captioning,visual question answering,visual dialog 等。目前已在 CVPR,ICCV,ECCV,IJCAI,AAAI,TPAMI,TMM 等会议与刊物上发表论文数十篇。担任 CVPR,ECCV,TPAMI,IJCV,TIP,TNN,TMM 等会议期刊审稿人。
原创文章,未经授权禁止转载。详情见 转载须知 。



企查查是官方备案的企业征信机构,为您提供全国企业信息查询,包括企业工商信息查询,信用信息查询,经营状况查询等相关信息。查企业,查老板,查风险就上企查查!

富贵论坛,二十年老富贵论坛,富贵论坛官网提供QQ号、抖音号、快手号、YY号、手机靓号、游戏账号交易,买号卖号就上富贵论坛交易平台!

最简洁的网址导航网站大全,办公白领设计师行业推荐比较好用的绿色小清新上网主页。企业实用工具综合极简商务风格,简单干净,自定义设置,简约个性网页官网入口。

辽宁工程职业学院是经辽宁省人民政府批准,国家教育部备案的公办全日制普通高等职业院校,是一所以工科为主培养高技能复合型、应用型、创新型人才的高等学府。

闲钻,二手钻石钻戒回收【卖钻石/钻戒就找闲钻——高价回收,实时到账】闲钻提供二手钻戒、钻石项链、钻石饰品、裸钻等回收业务,支持线上担保交易及线下门店高价钻戒钻石回收业务。闲钻,中国权威钻石钻戒回收品牌。

星空影视是全网最受欢迎的网上电影院,为广大网友整合全网视频,海量的高清电影、热播电视剧、韩剧、欧美剧及动漫作品均可免费在线观看。

东莞可源水处理设备公司是专业研制海水淡化设备厂家,提供最完善的设计方案,设备报价,是国内实力较强的从事海水淡化、苦咸水淡化、去离子设备、EID超纯水设备制造,中水回用设备等水处理设备厂家!公司热线:0769-23070972,欢迎新老客户前来考察!

无锡中新源机械有限公司(www.wxzxy.com)作为数控内圆磨床,数控外圆磨床厂家,主营产品有数控内外圆磨床,高精度内外圆磨床,本公司在提高机床精度,性能,自动化程度和方便操作等方面做了不懈的努力,可根据用户需求设计开发各种不同的非标专用磨床

萝卜玩手游不但免费为玩家提供好玩的手机游戏下载,而且提供电脑手游等手游模拟器,筛选市面上热门的手游进行排行,定期还有手游活动,提供最全面的手机游戏礼包领取,打造温馨的手游平台,萝卜玩手游一个专门提供优质手游的乐园!

本公司生产的多路阀,集美、德、日、意大利等国产品之长,形成了多品种、系列化。产品包括:DL8通径至DL20通径系列片式多路换向阀,FDL20型整体式多路换向阀,GD6通径至GD20通径隔爆电磁、电液换压阀,wy1.3、wy3.5、wy7.5、wy12.5挖掘机中央回转接头等矿山、煤矿、石油、化工、工程机械配套的各种液压阀。

Thisismypage

公司主要销售高能量纳秒激光器、高功率窄脉宽飞秒激光器、光束整形模组,和激光器附件等,是德国ActiveFiber,英国Litron,法国Cailabs,葡萄牙Sphere公司中国售后中心。


相对于传统的长焦投影仪,超短焦有着天然的场景优势,更节省空间、布线也更为容易,受到更多年轻租房群体的青睐,投影头部厂商对超短焦的选择的意向在进一步加强,截至目前,坚果、峰米、慧示、AOC、优派、LG等一批头部品牌已经推出非激光电视的家用超短焦投影,10月20日,投影行业头部品牌的当贝也加入了短焦智能投影品牌阵营,发布了首款超短焦激光投...。

昨天傍晚近7点,杭州西湖苹果店来了一位,不速之客,他身穿深蓝色衬衫,浅色裤子,眼睛一直往店里张望,这正是苹果公司CEO蒂姆·库克,这让苹果店内的店员和顾客一下子,懵,了,因为这一切发生得实在太突然,据一位当时在现场的网友说,很多人围着拍照合影、求签名,库克是有求必应,据苹果公司方面透露,这是库克第六次来到中国,除了有一次去了郑州的富...。

女士提供的服务主要有,皮肤护理、按摩、卵巢保养、香薰耳烛等,美容院是销售专业化妆品的终端机构,女士美容院加盟品牌有,克丽缇娜美容院、自然美美容院、唯美度美容院、百莲凯美容院、沙曼莎莉美容院、奈瑞尔美容院、姚大夫美容院、蕊丽思等,这些都是比较知名的美容院品牌,...。

这天,一位面带愁容的老先生步入了张大夫的诊疗室,老先生的脸上写满了不安,他轻声问道,张医生,最近老感觉不舒服,张大夫以温柔的笑容示意,并用手轻轻指了指诊室内的座椅,说道,请坐吧,让我为您做个检查,在经过一系列详尽的检查之后,张医生的脸色转为严肃,他向病人表示,依据您的检查结果,我们初步判定您可能处在胃癌的早期阶段,老先生吓...。

申明,1.以上内容仅代表揭发者自己,不代表黑猫揭发立场,2.未经授权,本平台案例制止任何转载,违者将被清查法律责任,3.黑猫揭发处置揭发不收取任何费用,凡以黑猫揭发名义不要钱的均为混充、诈骗行为,请及时报警并与黑猫官网反应,揭发邮箱heimaotousu@vip.sina.com,4.请大家选用官网渠道处置生产纠纷,不要轻信第三方机构...。

是感恩节,1941年,美国国会正式将每年11月第四个星期四定为,感恩节,感恩节假期普通会从星期四继续到星期天,除了美国、加拿大,环球上还有埃及、希腊等国度有自己共同的感恩节,但英国、法国等欧洲国度却与感恩节绝缘,也有学者建议设立,中华感恩节,,以弘扬传统文明,习俗习气感恩节的晚宴是美国人一年中很注重的一餐,这一餐的食物十分之丰盛,在...。

你好,张满意,的姓名测试打分结果如下,张满意,的姓名综合评分,79,满分为100分,60分及格,张,,繁体,张,拼音,zhāng,五行,火,笔划,11,姓名学解释,性刚口快,克父命,中年潦倒或奔走,晚年如意,吉,满,,繁体,满,拼音,mǎn,五行,水,笔划,15,姓名学解释,有恋情烦恼,身弱短寿,难幸福,再嫁守寡,完成隆昌,吉...。

oppo手机一键root权限,步骤如下,操作环境,opporeno7、ColorOS11、root巨匠最新版等,1、点击OPPO手机的系统设置,在设置界面的最下方,找到OPPO手机系统消息,2、进入到手机消息中,选用系统版本号,揭示进入开发者形式,3、而后在设置界面中找到开发者选项,4、进入开发者,选用USB调试,5、关上手机USB调...。

11月14日下午,“世界的香格里拉”主题采访活动在云南昆明启动。人民网记者虎遵会摄人民网昆明11月14日电(记者杜明明、虎遵会)14日下午,“世界的香格里拉”主题采访活动在云南省昆明市正式启动,由16

有些电脑已经安装了打印机驱动,而有些电脑没有安装,因此在连接打印机的时候会因为没有驱动程序而导致打印机不能正常工作,CanonTS308型号的打印机快来安装这款佳能TS308打印机驱动吧。打印参数打印分辨率:4800x1200dpi打印页面:A4打印速度:黑白7.7ipm;彩色4.0ipm墨盒:黑色PG-845,彩色CL-846接口:USB2.0;支持无线网络打印硬件ID:USBPRINT\CanonTS300_series45C3使用方法1、下载

腾讯软件中心提供2023年最新16.0.10325.30000官方正式版Office365高速下载,本正式版Office365软件安全认证,收费无插件。

中华成语掌中宝,该软件荣获“第八届全国多媒体教育软件大奖赛”二等奖。软件新版本界面焕然一新,内容更精彩!,您可以免费下载。

小学生玩的数学游戏有没有,很多小学生在学习数学的时候就会觉得比较困难,因为整天会面临着枯燥的数字,还有很多学生的数学基础本身就比较差,在学习数学时,就非常困难,可能跟不上老师的教学步伐,那么家长就可以为孩子选择一款能学习数学的游戏,通过一款游戏能锻炼孩子的口算能力,还能让孩子一边放松心情,一边掌握丰富的数学知识,接下来跟随小编的脚步,...。

今天要跟大家分享的是一个关于纯单机不联网手游的文章,随着智能手机的普及和技术的不断发展,手游已经成为我们日常生活中不可或缺的一部分,然而,对于一些喜欢独自享受游戏乐趣的玩家来说,纯单机不联网手游无疑是一种绝佳选择,接下来,小编将带领大家一起探索其中的奇妙!1、,汤姆猫总动员,在,汤姆猫总动员,中,你需要照顾你的汤姆猫,确保它们的饮食、...。

除了通过Windows系统直接升级Windows10之外,中国区用户还可以通过腾讯管家助手和360电脑卫士的渠道升级Windows10,不过通过这两个渠道升级Windows10的多数用户反馈在升级的过程中出现黑屏、死机、无限重启的各种状况,在经过,艰难的决定,后,腾讯和奇虎360都在今天中午相继宣布暂停Windows10的升级服务,腾...。
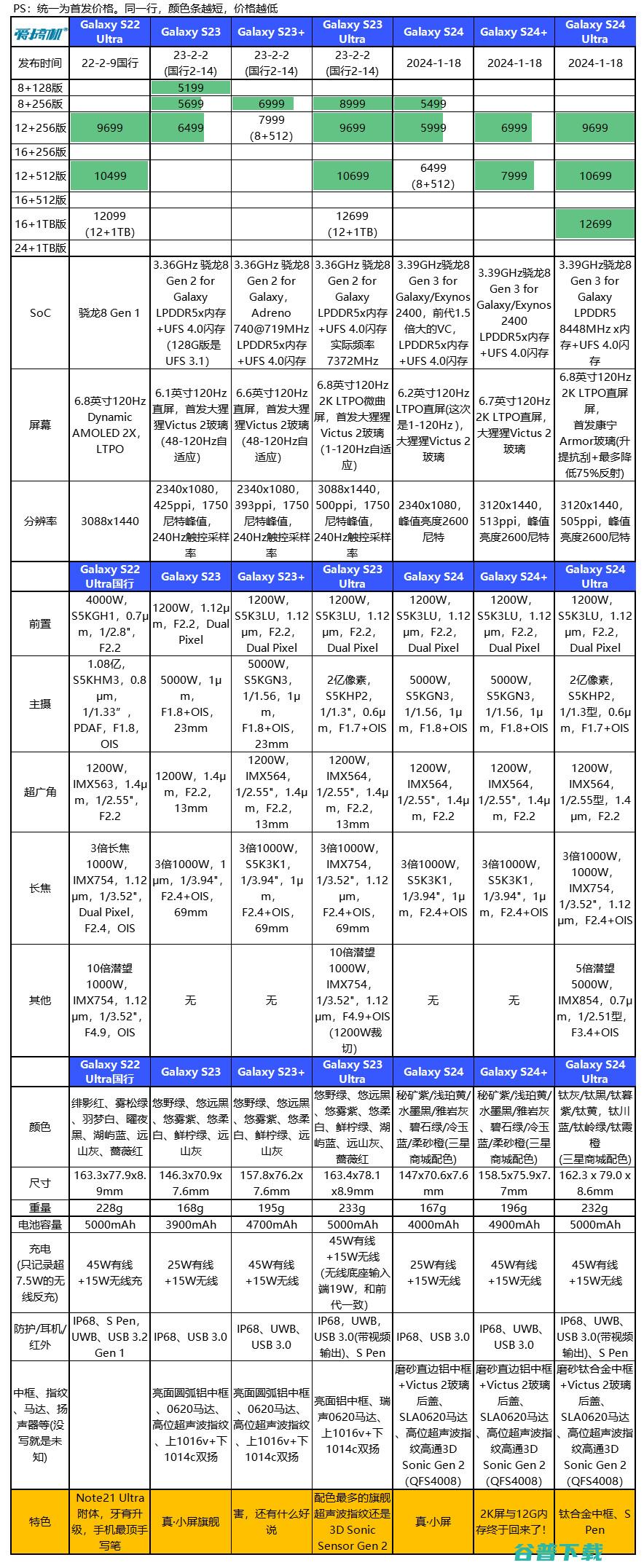
三星GalaxyS24系列国行版在1月25日晚发布,我们在发布会现场做了简单的外观和拍照对比,现在了看一下,开波先对比一下旗舰们,GalaxyS24,没什么好说的,正宗的小屏旗舰,就是在有12,256的情况下,往上一档竟然是8,512,这设定有亿点迷,这一代的屏幕大了0.1英寸,借用一下小白测评的图↓今年GalaxyS24,有大幅升级...。

读者姜翼问了一个同一架服务器上有多个网站是否影响SEO的问题,问题看起来简单,实际上有一些必须的背景并没有交代,所以要分两层回答,使用虚拟主机会影响SEO效果吗?如果仅仅是,同一个服务器,多个网站,,那这个问题就相当于问,使用虚拟主机会影响SEO效果吗?可以肯定地说,虚拟主机对SEO没有任何影响,因为这是常态,世界上大部分网站都是放在...。
