Execution TensorFlow推出Eager 紧跟未来深度学习框架需求 (executive)
雷锋网按:Google的TensorFlow是AI学习者中使用率最高、名气也最大的深度学习框架,但由于TensorFlow最早是基于Google的需求开发的,在实际使用上也会存在如 文档乱、调试难 等诸多缺点,而且开发时间比较早未能及时对一些新的需求进行反应(据雷锋网了解,由于缺乏类似PyTroch、DyNet的动态图功能,Lecun就不止一次吐槽过TensorFlow是“过时的深度学习框架”(yesterday deep learning framework)),而针对用户的需求,Google也在对TensorFlow不断改进。在10月31日,Google为TensorFlow引入了动态图机制Eager Execution,而Google Brain Team的工程师Asim Shankar和Wolff Dobson也在Google官方博客发文详细阐述了这一功能带来的变化,雷锋网摘编如下:
同时Google还举了一些使用 Eager Execution 的直观例子,例如使用两个矩阵相乘的代码是这样编写的:
使用 print 或者 Python 调试器检查中间结果也非常直接。
梯度与自定义梯度
大多数 TensorFlow 用户对自动微分感兴趣。因为每次调用期间可能会产生不同的运算,因此我们将所有的正向运算录到一个“磁带”上,并在计算梯度时进行反向运算。计算了梯度之后,这个“磁带”就没用了。
这一API与 autograd 包非常类似,例子如下:
在这里,gradients_function 先调用了一个预先定义的 Python 函数 square() 作为参数,并返回一个 Python 可调用函数 grad 来计算相对于输入的 square() 的偏导数。如以上例子中当输入为 3.0 时, square() 的计算结果为9,而 grad(3.0) 为对 square() 进行偏导,其计算结果为 6。
同样,我们也可以调用 gradient_function 计算 square 的二阶导数。
此外,用户也可能需要为运算或函数自定义梯度。这一功能可能有用,例如,它可以为一系列运算提供了更高效或者数值更稳定的梯度。
以下是一个自定义梯度的例子。我们先来看函数 log(1 + e^x),它通常用于计算交叉熵和对数似然。
上述例子中,当 x=0 时,梯度计算表现良好。然而由于数值的不稳定性,当 x=100 时则会返回`nan` 。使用上述函数的自定义梯度可用于分析简化梯度表达式。
使用 Eager 和 Graphs
Eager execution 使开发和调试互动性更强,但是 TensorFlow graphs 在分布式训练、性能优化和生产部署中也有着诸多优势。
当启用 eager execution 时,执行运算的代码同时还可以构建一个描述 eager execution 未启用状况的计算图。要将模型转换成图形,只需在新的 Python 进程中运行同样的代码即可。这一做法可以从检查点保存和修复模型变量值,这允许我们在 eager(命令式)和 graph(声明式)编程之间轻松转换。通过这种方式可以轻松地将启用 eager execution 开发出的模型导出到生产部署中。
在不久的将来,我们将提供工具来选择性地将模型的某些部分转换为图形。这样就可以融合部分计算(如自定义RNN单元的内部),以实现高性能并同时保持eager execution的灵活性和可读性。
新功能势必带来代码编写上的变化。Google还很贴心地给出了几个Tips:
更多内容可参阅 Google博客 。
原创文章,未经授权禁止转载。详情见 转载须知 。



清风DJ音乐网精品DJ舞曲汇聚,每天更新快人一步,专业DJ团队精心制作好听的串烧,打造车载DJ舞曲,为DJ工作者收录国外DJ舞曲,提供高音质在线试听及MP3下载,全方位满足DJ工作者及音乐爱好者的需求。

深圳市冠联通信技术有限公司主营:工业级PON、工业级ONU、OLT光猫设备等,在惠州建有3.5万平方米的现代化光纤通讯产品生产基地,经过十几年的持续发展,已成为国内光通讯行业产品系列全、综合实力强的高新科技企业。

京东国际是国内最有保障的海外购物平台,提供母婴用品,护肤品,彩妆,钟表首饰,数码电器等全球优质商品,全球直供,售后无忧,来京东国际,开启您的海外购物之旅吧.

城市联合网络电视台(CUTV.COM城视网)关注民生,提供包括新闻、民生、城市、影视、生活、科教等方面内容的视频、网络电视、直播、社区、微博、视频点播、视频上传、视频分享等信息服务。

重庆申欧通信科技有限公司是专业从事煤矿及矿山调度通信联络系统、冶金、化工及水电站电厂数字程控调度机系统安装销售、销售服务企业!产品服务于重庆、四川、贵州、云南、广西、山西、陕西、新疆、甘肃、内蒙古、广东梅州、福建龙岩等煤矿及矿山行业专用品牌等,其中重庆申欧提供申瓯调度系统设备历经10多年的市场和技术磨练,申瓯通信公司是国内早期的生产数字程控调度通讯设备制造商!年销售量达150万线以上,为煤矿及矿山企业量身提供数字程控调度系统品牌服务解决方案!也是煤矿及矿山企业采购通信联络系统时推荐选择!

汇泉集团展示

大尾猿协会商会管理服务软件是为协会商会提供的一款以互联网为工具,结合协会商会实际工作情况的互联网会员管理软件。旨在合理安排协会商会日常的管理工作,解决对于会员服务的手段太过单一导致的协会商会管理制度不严谨、资源信息不透明、沟通管道不畅通、会员服务不到位等问题;以及在会员服务方面,容易出现拓展会员不容易、会员参加活动不积极、留不住会员等问题

苏州阿丽贝科技有限公司,自成立以来企业着重培养技术人才及职工的操作技术,并长期与科研院校紧密合作,在产品设计生产、开发上更科学、更完善。本厂所生产的产品广泛应用于石油、化工、医药电力等领域。 我厂主要生产PP板材、PE板材、PPH板材、PP阻燃板等产品。

灵犀互娱官网为游戏玩家提供高品质的手机游戏,众多热门手游免费下载,找精品好玩的手机游戏,就来灵犀互娱。

浙江电动叉车,浙江电瓶叉车,比亚迪新能源叉车,托盘搬运车,托盘堆垛车,前移式叉车,牵引车,堆高叉车,新能源叉车,锂电叉车,电动叉车,电瓶叉车,防爆叉车,电池叉车,适用于各种工况,实时给您报价多少钱。

济南威龙自动化控制系统有限公司


晚了抖音3年的腾讯,终于在微信,短内容,上实现了它的视频梦,微信在春节前夕揭开了,短内容,的神秘面纱,上线十多天,越来越多的用户开始灰度体验,这个被张小龙,惦记,了两年的短内容代表到底怎么玩,值不值得玩?小编今天想跟大家唠个五毛钱,新上线的视频号怎么玩?首先,视频号入口内嵌在微信,发现,页面,位于朋友圈下方,两者分量相当,因此不少人戏...。

孩子学习问题一直受到很多家长的关注,很多教育机构也在不断的完善自己的教学课程以及教学方法,特别是阅读类的数据受到很多教育机构的注重,能够把更多有价值的书籍带到店内,满足孩子阅读需求,培养兴趣,寰球阅读成长中心就能让大家好评不断,寰球阅读成长中心的书籍多吗,如何更新,寰球阅读成长中心是一家很受欢迎,以儿童阅读成长中心为教育理念的教学机构...。

诞生于加州大学伯克利分校的RISC,V开源指令集近来在中国关注度非常高,5月,上海发布国内首个RISC,V的支持政策,9月,中国RISC,V产业联盟在上海成立,11月,中国开放指令生态,RISC,V,联盟在乌镇宣布成立,有意思的是,中国最早做RISC,V的公司选择了落户深圳,并且仅用7个月就设计出了一款基于RISC,V指令集的AI芯片...。

随着2019年9月10日的临近,几乎可以确认,苹果将会在今年的发布会上发布三款全新的iPhone,而它们的命名也极有可能指向传言中的iPhone11&,iPhone11Pro&,和iPhoneProMax——还有一点也基本上没有悬念,它们依然会很贵,即使是不少对iPhone感兴趣的潜在消费者,也会持币观望一番,这时候,一款...。

很多人都喜欢吃烧烤,烧烤也是百吃不厌的美食,不少年轻人都有需求,在很多城市都有店面,烤肉店一直受到不少创业者看好,有着很不错的发展市场,店面运营收效空间又很大,大家也有开店的意向,在开店加盟之前可以来了解一下烤肉店加盟条件,资金烤肉店创业加盟的首要条件,需要准备资金,没有资金寸步难行,根本无法筹备店面,所以在开店之前要根据自己开店的运...。

9月13日消息,近日Google新机Pixel6Pro出现在了GeekBench跑分库当中,这台Pixel6Pro的GeekBench5跑分为单核414、多核2074分,很显然应该不是SoC真实性能,,而其所搭载的GoogleTensor芯片CPU部分规格也出现在下方的设备详情中,包括2颗2.8GHz大核、2颗2.25GHz中核以及4...。

发表在大眼橙投影仪2024,10,2809,26大眼橙C1D高亮版是大眼橙C1D的升级版本,主要提升了投影亮度,具体大眼橙C1D高亮版投影仪怎么样呢,下面就分享大眼橙C1D高亮版投影仪的详细参数配置,看看这款投影仪优缺点有哪些,是否可以符合家用需求,大眼橙C1D高亮版投影仪怎么样,1.光学参数在亮度方面,大眼橙C1D高亮版的实际亮度达...。
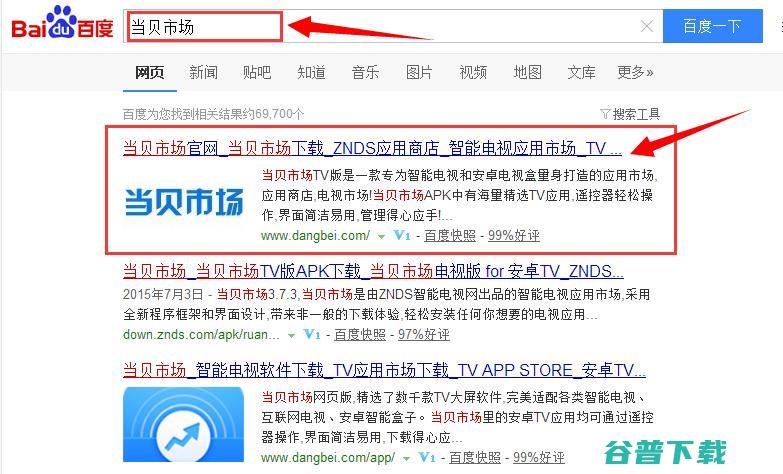
准备工作,联想电视,C系列,、u盘、电脑一、百度搜索,当贝市场,,进入官网下载最新版本apk文件,或点击直接下载,http,dlap1.dbkan.com,update,dangbeimarket.apk,,并拷贝进u盘,附,当贝市场官网,http,www.dangbei.com,二、将U盘插到盒子的USB接口上面,检测到外...。

网络输入法是一款有着诸多配置的低劣输入法!不同的配置可认为用户们带来不同的便利操作,当天小编为大家带来的就是网络输入法手写输入形式开启方法!一同来看看吧,网络输入法手写输入形式开启方法,1、在切换进去的网络输入法输入图标上右键鼠标点击关上,2、选用网络工具箱而后关上,3、在网络工具箱界面中如图找到手写输入图标点击进入,4、在进行的手写...。

全新迈腾280提供1.4T和2.0T两种引擎决定,迈腾的外观设计驳回了与辉腾相似的X外型,少量经常使用镀铬装璜和双横向线条,内饰方面,迈腾驳回典型的欧式格调,俗气流利,并遵照人体工程学原理和高效率设计准则,此外,迈腾还决定了公众B级车平台的最新优化前轴系统,并对副车架启动了增强,迈腾280是全新迈腾的其中一个车型,搭载1.4T引擎,全...。

游戏类型精品手游实况足球游戏简介实况足球下载最新手机版免费安装实况足球是一款足球体育类手游酷炫虚幻引擎打造极致流畅画面真实物理碰撞打造实况足球魅力指尖上的真实绿茵场喜欢这类游戏的玩家不要错过哟实况足球游戏简介最佳体育游戏原版操控手游实况足球正式公测游戏由主机原班制作团队打造搭载主机版同款虚幻引擎高解析度和模式为比赛画质...
百度sitemap这款工具是利于网站收录的,还可以用来提交历史数据和重要数据,并且能实时推送内容,一般站长使用的网站程序,CMS,就自带提供的有,...。

如果让你重回过去,在自动驾驶行业创一次业,你会怎么做,面对发出的这一设问,智驾创业者们给出了近乎一致的答案,在2023年之前,疯狂融资,守着金库什么都不做,广积粮,缓称王,耐心等到,端到端,来的那天,毕竟之前的几次技术路径几乎都被端到端推倒了重来,之前的领先优势也会因为新技术路径的切换而不复存在;等到2023年时,花高价招聘...。
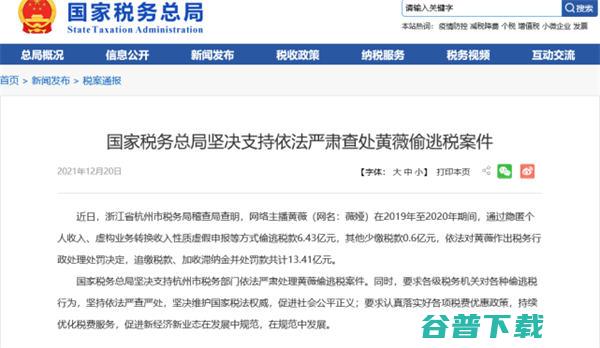
直播带货,要,熄火,了,下一个风口来临,已经有人赚了上百万了,前些天随着税务机关的一纸罚单,让红极一时的网络直播带货,渐渐降温,林珊珊、雪梨、薇娅相继被罚,有关人士透露,薇娅并不是最后一个,随着税务机关的深入调查,将会有更多的主播被公布出来,当然具体的处罚也不会在同一天公布,直播带货可能蕴含着一些新式的营销骗局,在2019年直播带货兴...。

在4月27日的发布会上,卢伟冰宣布了这一消息,卢伟冰表示,在充分研究了游戏手机市场之后认为,要解决游戏手机存在的痛点和困境,只有一个解决方案,就是大厂要入场,基于此,在本场发布会上,Redmi带来了首款游戏手机RedmiK40游戏增强版,用卢伟冰的话形容,这是一款,日常使用的主力旗舰机与游戏手机的结合体,游戏手机存在三大痛点4月27...。

今天,清华大学校友、杜克大学ECE系的陈怡然教授在微博上官宣,裴健教授将于今天秋天正式加入杜克大学,据官网消息核查,裴健在杜克大学的任职将始于今年的7月1日,且同时任职于计算机科学、电子与计算机工程、生物统计和生物信息等三个大系!此前,裴健为人熟知的身份是,京东集团副总裁,,不知是否已离职,裴健教授是数据科学领域的国际知名学者,在数据...。
