为什么平头哥和英伟达在MLPerf基准测试中都获得了第一 (为什么平头哥不怕毒蛇)

由深声科技提供技术支持
雷锋网按,本周,MLPerf组织发布了第一个MLPerf Inference v0.5的结果,虽然这个基准测试还不成熟,但依旧获得了巨头公司的广泛关注。并且平头哥、英伟在成绩公布后纷纷发布消息表示自己成绩都获得了第一?

自去年初成立之后,MLPerf组织一直在稳步建立其机器学习到的Benchmarks。为了能够让机器学习处理器的基准测试也像CPU那样,该组织囊括了该行业中的所有知名企业,比如英特尔、NVIDIA、Google和百度。从技术上讲,MLPerf基准测试还处于初期阶段,它们甚至还没有完成,但是该组织的成果引起发了巨大关注。
早在6月份,该组织就发布了第二个基准测试集MLPerf Inference v0.5。顾名思义,这是MLPerf组织的机器学习推理基准测试,旨在衡量各种加速器和系统执行训练后的神经网络的程度和速度。MLPerf Inference是测试推理性能的通用方法,它最终将成为衡量从低功耗SoC中的NPU到数据中心高性能加速器的标准。在基准测试首次发布的四个多月之后,MLPerf组织发布推理基准测试的首个官方结果。
基准测试的初始版本v0.5仍然非常不完整,它目前仅涵盖5个网络/基准,并且还没有功耗测试指标,这是衡量整体能源效率是必不可少的。尽管如此,基准测试的初始版本吸引了主要芯片公司的关注,这些公司都渴望展示其硬件在基准测试中的成绩,并向客户(和投资者)说明为什么他们的解决方案更好。实际上,第一轮官方基准测试提交了近600份结果,远超出了该组织非正式预期的全新基准测(通常需要一段时间才能建立新的行业基准),这更能说明了行业对MLPerf的期待,推理芯片数十亿美元的市场将继续快速增长。

随着第一轮申请工作的完成,MLPerf组织现在发布其Inference v0.5的官方结果,不过只是大多数(如果不是全部)主要芯片公司都在发布与结果相关的公告,声明或新闻稿。说实在的,600份提交的成果分布在40种不同的测试中,芯片公司还有很多事情可以做。缩小标准范围,每个人都可以找到成功的方案,例如总吞吐量、延迟,每个加速器的吞吐量等。这并不是基准测试本身,甚至也不是芯片公司所为,但这给我们提醒,即使初始版本足够广泛,也可以涵盖很多用例,尤其是在专用加速器的情况下,它们通常针对特定用例进行了优化。

作为更新,MLPerf v0.5分为5个基准,其中两个基准实质上是其各自主基准的移动衍生产品。当前这个套件的桌面/服务器版本涵盖了图像分类(ResNet50),对象检测(ResNet34)和机器翻译任务(GNMT)。所有基准测试都提供了四种方案:单路(一个终端运行一个任务),多路(一个终端同时运行多个任务),服务器(服务器的实时性能)和离线(不在线的服务器)。这些实质上将方案分解为终端和服务器方案,并从分解为相应平台的两个最常见方案。

更进一步,MLPerf提供了两个测试“分区”:封闭分区和开放分区。封闭分区是“苹果对苹果(apples-to-apples)”测试,芯片将获得预先训练的网络和预先训练的权重。在选择要使用的精度等级(只要满足精度要求)方面,芯片公司在量化方面仍具有一定的灵活性,但是在封闭的分区,他们的解决方案仍必须达到数学上的等效性,并且禁止重新训练网络。这个目的在于,测试平台能否很好地执行预训练好的网络。

相比之下,开放式分区显然更加开放。芯片公司被允许重新训练网络以及进行更广泛的量化工作。绝对不是封闭测试区那样的苹果对苹果,开放分区本质上是一种结构较少的结构化格式,可以让芯片公司以最佳的方式展示其解决方案和团队的独创性。
深入研究结果,MLPerf最终收到了从CPU和GPU到FPGA,DSP和专用ASIC等各领域的官方意见。正如一位MLPerf代表指出的那样,该组织实质上收到了除神经形态和模拟系统以外的每种类型处理器的成果。当然会有大公司的代表,包括NVIDIA的GPU、谷歌的TPU、英特尔的CPU和加速器以及Habana Labs的Goya加速器。即使在封闭分区,也有一些预期外的结果,包括Raspberry Pi 4和阿里巴巴的含光800加速器。


总的来说,我不会在这里对结果进行过多的剖析,因为大量的测试意味着非常多的对比。更重要的是,缺少功耗测试意味着目前无法测量能效。但总的来说,几乎每个芯片公司都可以在某个类别中取得胜利。在离线测试中,看到了Google从1 TPUv3到32的几乎完美的拓展性,NVIDIA的Tesla加速器在一些测试中名列前茅,英特尔在CPU中位居榜首,高通的骁龙855在官方结果中也远远超过其它SoC。
关于MLPerf推理的第一组结果不会成为推理性能的最终成绩。在开发方面,MLPerf组织仍在努力完善基准,以添加其他网络类型,着眼于语音识别等任务。同样,该组织将进行功耗测试,以便每个人都能看到他们的设计效率,因为电源效率通常是大规模部署规划的最重要考虑因素。
尽管这些早期版本的MLPerf在添加和优化测试时和目标还有不同,但对于芯片公司来说,他们现在知道自己和竞争对手所处的位置。比参数更重要的是,机器学习优化的开放性性质意味着芯片公司还有大量空间来优化其系统以进行将来的测试,以及设计更好的新硬件。客户(其中许多人在MLPerf委员会中)希望加快工作进展。因此,既然第一个结果已经出炉,芯片公司就可以专注于其产品,并了解如何才能进行下一轮正式测试。
最后,从更长远来看,MLPerf Inference基准测试在未来几年内将趋于成熟(该组织目前尚未估计1.0何时准备就绪),这也意味着该基准测试将稳定下来,并且在芯片公司的性能实验室之外更容易使用。MLPerf组织已经发表评论说,他们将开发移动应用程序以加快对智能手机和其他智能设备的测试,并且我们期望桌面基准测试的情况也将日趋成熟。如果运气好的话,在不久的将来,我们将能够把MLPerf推理应用到我们自己的测试中,并将这些测试转换为有意义的结果,以比较消费类硬件。激动人心的时刻到来了!
雷锋网编译,via
原创文章,未经授权禁止转载。详情见 转载须知 。


河北省曲周县人民法院曲周县人民法院曲周县法院

新三农助力农业农村现代化,加快农村科技进步,为促进农村发展,农业增效,农民增收而努力。

洛阳做网站800元,快速制作企业X立官方网站!欢迎咨询:13938854949

HU网络专业承接高邮建站,高邮建网站,主营业务:高邮建站及高邮企业建站,提供高邮建网站、百度优化相结合的高邮建站公司方案,由高邮建站公司专业人员结合百度优化经验为您建网站。

二维码注册认证平台是在中国二维码注册认证中心的指导下,由中国电子商会和中国质量认证中心联合发起成立中国第三方二维码注册认证平台。面向国际国内企业、机构及商户提供二维码注册、认证、制作和统一编码、发放、验证等二维码应用服务。可实现各行业企业的信息展示二维码、产品二维码、溯源二维码、防伪二维码、网站二维码、支付二维码等展示营销服务,并提供各行业企业示范试点认证通道,打通企业品牌与产品品质的双飞跃。

泉州合力成服装织造有限公司创建于2002年,现已是一个拥有员工200多人,专业管理人员30余人,面积达3500多平方米的工贸一体的出口加工型企业。专业生产各式童装、男/女装针织内衣裤、拳击裤、背心、T恤、睡衣套等。

海威数字为微信社群、公众号、APP等不同形态流量主提供数字权益商城解决方案,服务外卖cps系统,社群团购系统,私域系统,淘客APP等,致力于为淘客、微商、卖家提供安全高效的私域电商解决方案,实现用户拉新、促活、留存、返利等目的,快速触达精准用户,升级用户忠诚度,让流量变现更高效、更稳定、更长久!

AIPHONE爱峰代理商——深圳前景智能代理销售维护日本AIPHONE爱峰别墅型可视对讲,AIPHONE爱峰多栋楼宇可视对讲,AIPHONE爱峰商用办公大楼安保和通讯,AIPHONE爱峰医院呼叫系统,IP对讲,IP网络对讲

无锡网站建设阿凡达网络是无锡专业的网站建设公司,我们用先进的网站设计技术,合理的企业网站制作费用,优质的网站建设方案,为企业提供一流的网站建设服务,无锡网络公司阿凡达建站主营业务企业网站建设,网站改版,企业网站维护托管等,阿凡达网络力争成为无锡网站建设行业最有技术力量的队伍之一。

中国品牌网属于综合性网站平台,主要栏目包括资讯、独家、社会、国内、财经、科技、关注、时尚、家居、游戏、教育、体育、文化等各行业。

蚁景网安实验室提供在线实验与课程,包含web安全\渗透测试\密码学应用\软件安全\CTF挑战\漏洞挖掘等多方面的内容,大量靶场实战提升操作能力,助你快速成长

盐城耐斯特机械从事抛丸清理机的生产和开发设计,主要有吊钩式抛丸机,钢结构抛丸机,通过式抛丸机,履带式抛丸机等各种型号抛丸除锈设备生产厂家,创造发展中国抛丸机工业,走向世界。


现在是一个中西医结合的时代,尽管很多中医用的看诊方法都是传统的保守方法,但是在病情检查前期,也需要需要依靠核磁等影像来观察病情,并且大多数中医也不再称呼,腰痛,、,腰腿痛,、,痹症,等传统称谓,也跟随西医叫法,腰椎间盘突出症,腰椎间盘突出症临床的主要症状是,腰部疼痛伴有一侧或是双侧下肢疼痛、麻木,可有单纯腰痛而无腿痛的,亦有单纯腿痛...。

昨日,科创板上市委公告,云从科技集团股份有限公司首发获通过,至此,科创板AI第一股诞生,最终花落云从,近2年,AI四小龙的上市之路几经磨砺,不少人频频发问,AI独角兽活得还好吗,当外界唏嘘,鲜少发声的AI视觉企业在无人处无言积累动能,接踵而至的打击的确并未给AI独角兽们多少喘息的时间,但任何危机中往往也蕴含转机,几番争奇斗艳,历经狂风...。

襄阳到贵州每天有4趟火车,车次和时刻表如下图贵州到上海的列车时刻表你问的贵州到上海和浙江瑞安,比较含糊,只能告诉你贵阳到上海和浙江瑞安的情况,1、贵阳到上海列车,1249,1252次普快重庆——上海南贵阳站发车时间02,02,到达上海南站时间09,37,历时31小时35分钟,票价,硬座113.00元;硬卧上,中,下,223.00,23...。

发表在行业动态2023,3,309,21如今投影市场亮度虚标现象严重,因此制定一个全新的亮度标准和明确的测量方法非常重要,故中国电子视像行业协会联合当贝、极米等投影行业代表讨论新的CVIA亮度标准,具体CVIA亮度标准有什么意义呢,为什么要制定CVIA亮度标准,下面就来详细了解一下,中国电子视像行业协会在线下召开了针对,投影机光输出技...。

米家极米哪个更好,米家投影仪与极米H1S对比评测米家投影仪开箱实测记录篇,米家投影仪运输的外箱,上面醒目的二级能效和高色域投影机的标签,标明米家投影仪不管是在光效、色域还是待机功耗上,都符合国标的节电要求,二级能效属于比较节电,目前当贝投影已经上市,在整体配置方面也更加出色,现在在京东首发,https,jd.dangbei.com...。

在居家生活中,我们总会用到各种各样的电器,但由于频繁用,里面是很容易变脏的,如果你是一个懒人,平时不定期进行清洁和维护,不仅会影响到家居环境,还会对我们的健康造成影响,只是生活中的家电种类是非常多的,多数人都不知道该如何的清洁哪个,下面,我就给大家盘点一下,这4件电器不洗,可能比,马桶,还脏,很多人不懂,看完涨知识了!电饼铛电饼铛是生...。
中文名,天蝎座外文名,Scorpio星座属性,水象主持宫位,第八宫最大特色,缄默是金金属,钙主持身材,鼻子、嘴巴、耳朵幸运数字,1、6、11、28幸运石,祖母绿、绿玉、绿松石、蓝田玉幸运日,星期四幸运场合,湖畔、家中、书店幸运方位,西南偏西向现实的寄居国,印度、泰国、伊朗、越南最全的天蝎座引见1、天蝎座期间,阳历,10月24日~11月...。

吉普大指挥官是吉普公司旗下的奢侈SUV车型,领有弱小的越野性能和霸气的外观设计,备受生产者青眼,但是,在购置之前,许多生产者都会关心吉普大指挥官的品质能否牢靠,首先,咱们看一下吉普大指挥官的车身品质,从外表过去看,吉普大指挥官的车身驳回了优质的钢材,具有很强的抗撞击性能,此外,该车还装备了多个安保气囊和各种安保系统,可以大大提高乘客的...。

6月2日,中国国防部长董军在第21届香格里拉对话会的宗旨演讲之后,回答对于台湾疑问的提问时指出,,台独,分子螳臂当车、掩耳盗铃,咱们看待,台独,武装就像瓮中捉鳖,无余挂齿,董军说,台湾疑问是中国的外围利益的外围疑问,5·20,台湾当局所谓的指导人到任宣誓,光秃秃的暴显露,谋独,的图谋和野心,这一以贯之地代表了以民进党为首的,台独,权...。

北京日报客户端,记者潘福达随着高考完结、暑期邻近,多家游览平台数据显示,往年端午假期将间断,五一,的游览热度,有望成为近年来,最火,端午,炽热的游览行情推进民航市场减速回暖,近期多家航空公司参与新航线,机票多少钱有所回落,国际机票燃油附加费近期迎来年内三连降,更是扑灭了旅客的出游激情,端午及暑期的游览民航市场备受业内看好,多条航线端午...。

重庆分类目录网站收录综合杂谈相关的优秀网站大全分类检索,为上网用户提供综合杂谈网站排行榜与您分享、收藏!

神奇证件照片打印软件,神奇证件照片打印软件是一款非常好用的证件照打印软件,通过神奇证件照片打印软件用户可以轻松制作照片,软件内置了非常多类型的照片种类,还支持数码照相机一键传输功能,是制作照片的好帮手,您可以免费下载。

最近,具,真,直,这些字火起来了,大家都在讨论是两横还是三横,小编语文学的差就用手机和电脑的搜狗拼音打出这些字,发现了其中差异,以真字为例说明,小编上学那会学的都是3横,在window7系统PC微信里,打出来如下,搜狗里打出来是3横的真,选择后写到微信里里变成了2横的真,再同样环境下的QQ,如下,QQ里的截屏搜狗里打出来是3横的...。

12月17日,再有iPhone17系列的渲染图出炉↓,好消息,和之前不太一样;坏消息,只有一点不一样,中间那个部分是玻璃材质,主要是为了做无线充电↑不仔细看,还以为是吸了MagSafe充电宝,爆料里的中框↓两个旧版本↓12月17日,闲聊站爆料称,明年vivo、OPPO有分别搭载骁龙8至尊版和天玑9400,也可能是天玑9300,的小屏...。

一户一墩,有希望了,冰墩墩,生产商元隆雅图已全面开工生产,正在布局元宇宙2月7日消息,随着北京2022年冬奥会于2月4日正式开幕,冬奥会吉祥物,冰墩墩,的相关周边需求量暴增,甚至出现了,一墩难求,的现象,2月6日,北京冬奥组委新闻发言人赵卫东表示,,正在加大协调相关方面,加大对冰墩墩的供应,冰墩墩生产商元隆雅图在深交所,互动易,...。
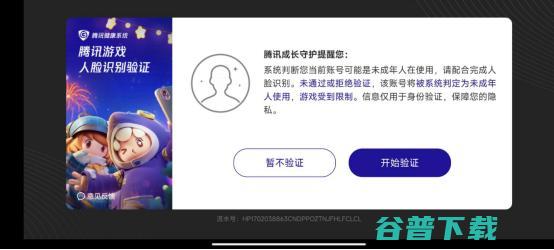
7月17日,腾讯游戏宣布开展,2024暑期未成年人保护专项行动,,针对孩子冒用家长等成年人账号游戏问题,多方位升级人脸识别策略,新增家长防骗小课堂和专线服务,针对性打击租号黑产,同时也推出运动赛事及产品,鼓励家长孩子放下手机一起运动,共度快乐暑假,在人脸识别策略方面,腾讯游戏宣布开启,暑期人脸巡航,,加大人脸识别力度,另外,上线,防代...。

作为投影玩家,选购幕布是一个避不开的话题,市面上的投影幕布种类繁多,价格也是从几百到几万不等,选购起来确实是让人眼花缭乱,本文中就选择了一种看起来整体性能和性价比不错的,抗光幕布,灰色幕布,首先说一下抗光幕布的外观,目前市面上的抗光幕布整体为灰色,会根据不同的角度或者光线会呈现出灰色到黑色的效果,如下图,在不同角度和光线环境下...。
