英伟达仍是 MLPerf最新结果公布 王者 (英伟达仍是估值最低股票)
消息,北京时间6月30日,MLCommons社区发布了最新的MLPerf2.0基准测评结果。在新一轮的测试中,MLPerf新添加了一个对象检测基准,用于在更大的OpenImages 数据集上训练新的 RetinaNet,MLperf表示,这个新的对象检测基准能够更准确反映适用于自动驾驶、机器人避障和零售分析等应用的先进机器学习训练成果。
MLPerf2.0的结果与去年12月发布的v1.1结果大致相同,AI的总体性能比上一轮发布提高了大约1.8倍。
有21家公司和机构在最新一轮的测试中提交了MLPerf基准测试的成绩,提交的成绩总数超过了260份。
英伟达依然“打满全场”
本次测试中,英伟达依然是唯一一家完成2.0版本中全部八项基准测试的参与者。这些测试包含了目前流行的AI用例,包括语音识别、自然语言处理、推荐系统、目标检测、图像分类等方面的内容。
除了英伟达之外,没有其他加速器运行过所有基础测试。而英伟达自2018年12月首次向MLPerf提交测试结果以来就一直完成所有基础测试。
共有十六家合作伙伴使用了英伟达平台提交了本轮测试结果,包括华硕、百度、中国科学院自动化研究所、戴尔科技、富士通、技嘉、新华三、慧与、浪潮、联想、宁畅和超微。在这一轮MLPerf的基准测试结果中,英伟达及其合作伙伴占了所有参赛生态伙伴的90%。
这显示出了英伟达模型良好的通用性。
通用性在实际生产中,为模型协同工作提供了基础。 AI应用需要理解用户的要求,并根据要求对图像进行分类、提出建议并以语音信息的形式进行回应。
要完成这些任务,需要多种类型的人工智能模型协同工作。即使是一个简单的用例也需要用到将近10个模型,这就对AI模型通用性提出了要求。
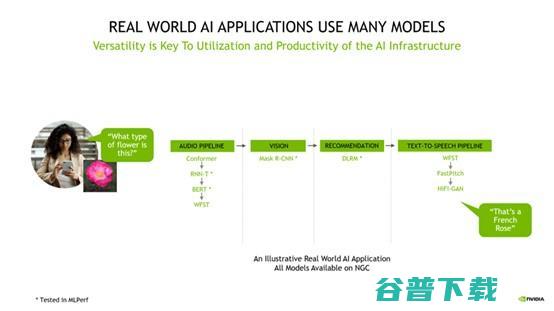
好的通用性意味着用户在整个AI流程中可以尽可能的使用相同的设施工作,并且还能够兼容未来可能出现的新需求,从而延长基础设施的使用寿命。
AI处理性能三年半提高23倍
在本次基准测评结果中,NVIDIA A100仍然保持了其单芯片性能的领军者地位,在八项测试中的四项中取得了最快速度的成绩。

两年前,英伟达在MLPerf 0.7的基准测试中首次使用了A100 GPU,这次已经是英伟达第四次使用该GPU提交基准测试成绩。
自MLPerf问世以来的三年半时间里,英伟达AI平台在基准测试中已经实现了23倍的性能提升。而自首次基于A100提交MLPerf基准测试两年以来,英伟达平台的性能也已经提高了6倍。
性能的不断提升得益于英伟达在软件上的创新。持续释放了Ampere架构的更多性能,如在提交结果中大量使用的CUDA Graphs可以最大限度地减少跨多加速器运行的启动开销。
值得注意的是在本轮测试中英伟达没有选择使用其最近发布的Hopper GPU,而是选择了基于英伟达Ampere架构的NVIDIA A100 Tensor Core GPU。
英伟达Narasimhan 表示英伟达更希望专注于商业上可用的产品,这也是英伟达选择在本轮中基于 A100提交结果的的原因。
鉴于新的Hopper Tensor Cores能够应用混合的FP8和FP16精度的数据,而在下一轮MLPerf测试中英伟达很有可能会采用Hopper GPU,可以预见在下一轮基准测试中,英伟达的成绩有望取得更大的飞跃。
原创文章,未经授权禁止转载。详情见 转载须知 。

")
辽宁省血液中心(沈阳中心血站)

金釜照明是一家专注太阳能路灯生产,集设计、开发、制造、营销、服务一站式太阳能路灯服务,提供太阳能路灯,光伏太阳能路灯,LED太阳能路灯,太阳能庭院灯,太阳能景观灯等太阳能系列;,我们主要经营和路灯、LED路灯、太阳能路灯厂家、太阳能路灯厂、路灯厂家、太阳能庭院灯、庭院灯、景观灯、壁灯、柱头灯,如果有兴趣请联系我们公司江门市金釜照明有限公司,我们会以好的质量有竞争力的价格是您的优选!

企业108网,从新时代的机遇汇聚信息里,展示更多就业机会给各个领域层面的人,更多的就业机会等您发现!在家玩手机?追剧?还不如浏览上百种行业的最新信息,提升寻找企业信息大全108网!快来就业玩家网沉浸式学习吧!

深圳航天智慧城市系统技术研究院有限公司(简称:航天智慧院)成立于2016年。着重发展:政府数字化和企业数字化两大业务板块。政府数字化,主要面向城市信息模型(CIM)、智慧园区(社区)、智慧水务、智慧安全应急等政府治理数字化建设需求,基于数字孪生产品技术体系提供咨询服务、顶层设计、综合解决方案和集成服务;企业数字化,主要围绕能源、制造、建工等领域的企业数字化建设需求,提供基础软件工具、数据终端和定制

游戏网为游戏玩家提供手游,网游,小游戏,手机游戏,安卓游戏,网页游戏,单机游戏,热门网络游戏攻略,阵容搭配,前十排行榜

中邮物流官网

余信电气公司主导产品有:RT18、RT14、NT00、RT16(NT)、HD11F、HS11F、HR6、HR17、熔芯、熔座以及各种刀开关系列等线路过载或短路保护用低压熔断器,和RSO、RS3、NGT等半导体设备保护用低压熔断器

检测网站是否可用,检查域名是否被跳转、网站是否被黑、被入侵、被改标题、被挂黑链等功能,全网唯一真机渲染检查网站是否可用,全国多地多线并发查询。

汇集新车资讯,车市信息,养车经验,行业动态,车主论坛,国内首家全方位、跨生态向车主提供服务的内容平台,是车主们真实交流的家。

内蒙古鱼得水资产评估有限公司主营:内蒙古资产评估公司,呼和浩特资产评估,呼和浩特房地产评估,主要从事各类资产评估、房地产评估、土地使用权评估、机器设备评估、有形无形资产评估、车辆价值评估、矿业权评估、知识产权评估、司法鉴定评估、以财务报告为目的的评估对机动车、房产、土地、股权债权、文物艺术品、农副产品、其他交通工具、无形资产、其他财产的拍卖。欢迎来电咨询!

合肥明瑞精密钣金科技有限公司

奇精机械股份有限公司是一家具有持续创新能力的多元化智能制造企业,现已形成家电零部件、汽车零部件及电动工具零部件三大业务的产业格局。总部位于浙江宁波,并在宁波宁海、合肥、上海、泰国等地设立多家子公司...

很多友友感觉记英语单词都十分困难,但是如果可以有效的利用英语单词游戏,那么就可以让我们在玩中学,在学中玩,一举两得,小编现在给大家整理出来了,网站的一些好玩英语单词游戏,大家如果是有学习英语需要的话,不妨下载这些英语单词游戏,随时随地就可以来一局,还能轻松记下单词哦~接下来大家就跟着小编一起看看这些英语单词游戏吧!1、,甜蜜英语消消乐...。

权力,财富,威慑,是世界十大家族秘密掌控世界所凭借的手段,他们或富可敌国,垄断一方经济,或权势滔天,主管一方政治,10.韩国巨人——李氏家族三星李氏家族资产达266亿美元,居是亚洲十大富豪家族之首,3代家族成员参与运营超过50家企业,整个集团2016年的收入相当于韩国国民生产总值的25%,集团总资产超过4000亿美元,三星集团是家族企...。

爱美是女人的天性,所以很多人越来越重视皮肤的护理,为了迎合这一市场所需,出现了很多美容院,而且根据市场调查表明,大部分的美容院生意都非常的红火,对于这样的市场现象也赢得了一些有志之士的关注,但开店没有想象中的那么简单,下面就美容院美容加盟费需要多少,这个问题,小编为大家做一些相关的分析,希望能够帮助到那些有需要的朋友们,美容院美容加盟...。
2月6日上午,银川市实验中学的王秀琴老师,打开自己家里的电脑和摄像头,登录北京四中网校的爱学平台,开始了人生第一次直播授课,王秀琴是银川市实验中学的一位高三历史老师,同时也是历史教研组组长,今年50岁,拥有28年从教经验,在此之前,王秀琴已经习惯了三尺讲台,虽然平时备课也会做网络课件和白板教学,但对于远程直播教学,还是头一回接触,,会...。

制造业数据的指数级增长,就像当年阿里巴巴的‘双11,购物节一样,在这样的景象下,作为一名数据从业者,我感到异常兴奋,这种熟悉的感觉仿佛让我回到了过去,但这一次,我站在了一个全新舞台,曾在阿里工作多年的奇点云CTO地雷,他的眼神中透露出热情与期待,简单来说,他们是独立第三方的大数据基础软件厂商,成功实现与全球十大IaaS云服务商的兼...。

发表在综合交流大区2018,11,2015,40在彩电行业加速更新换代,激光电视以下一代全新显示方式和更大屏、健康的观看体验引爆市场并引领产业升级之际,行业相关企业一直呼唤激光电视的相关标准出台,从而加速产业在规范化、标准化道路上越走越宽,在彩电行业加速更新换代,激光电视以下一代全新显示方式和更大屏、健康的观看体验引爆市场并引领产业升...。

发表在当贝投影仪2023,5,1917,58当贝F6是当贝F系列的最新产品,在画质和性能方面都有巨大变化,采用全新的旗舰芯片,那么当贝F6和极米H6有什么区别呢,下面就通过详细的参数配置进行对比分析,看看当贝F6和极米H6有什么区别,哪款更值得入手,一、当贝F6和极米H6有什么区别,1.光学参数对比在光源方面,当贝F6的亮度达到180...。

2023年的第一波红利项目来了,很多小伙伴已经入局并开始吃肉了,圈内的一个大佬,凭借这个玩法,年前布的局,年后一个月就变现了将近10个w,接下来还会继续爆发,这个玩法就是最近爆火的小红书无货源,我自己深入研究之后,发现整个项目的路径,还是比较简单的,并不像抖音小店那么复杂,今天我就一次性把这个玩法拆解给大家,如果你也想抓住这波机会,今...。

将于12月1日到职的欧盟外交与安保政策初级代表博雷利外地期间11日在社交媒体发文称,当日他观赏了乌克兰边陲左近的进攻工事并示意他在前线亲眼目击了,乌克兰军队的力气和韧性,此外,博雷利还呐喊称,,更多、更快的,对乌,军事援助至关关键,据此前报道,博雷利外地期间9日称其已达到乌克兰首都基辅,这是俄乌抵触迸发以来他第五次访问基辅,博雷利...。

间天一次性赶集网企业实名认证怎样弄的啊1.实名认证流程第一步上行营业执照第二步填写银行帐户第三步期待赶集网向您汇款第四步输入您收到的金额数目,即实现,2.营业执照查看不经过怎样办,填写的营业执照号必定与营业执照上注册号分歧,上行的营业执照需为加盖公司公章的正本复印件或扫描件,证件要求完整、明晰,证件上必定有工商部门的有效盖章,证件必定...。

据朝鲜电台,朝鲜之声,20日报道,朝鲜休息党总书记、国务委员长金正恩向俄罗斯总统普京赠送了一对朝鲜国犬丰山犬,该电台报道称,金正恩同志在平壤锦绣山迎宾馆花园向普京总统赠送了一对朝鲜国犬丰山犬,普京总统对这份礼物示意感谢,据报道,两国指导人19日独特散步玫瑰花园,启动了充溢,友谊和诚意,的交谈,双方探讨了进一步增强两国策略同伴相关和...。

多国语言生成器提供了整体国际化快速处理方式,界面简单,操作简单,直接变成国际化程序,如果需要提供了整体各环节的控制。

#成年人的崩溃往往就是一瞬间#,警惕!明明信用卡申办,失败,事后却被透支7万多,今年年初,孟先生无意间发现一条办理大额信用卡的信息,按照对方要求,提交资料半个月后,孟先生却没能拿到自己的信用卡,对方说孟先生未通过银行审核,三个月后,孟先生突然接到银行的客服电话,称其名下信用卡已透支7万余元,要求孟先生按期还款,孟先生这才意识到自己被...。
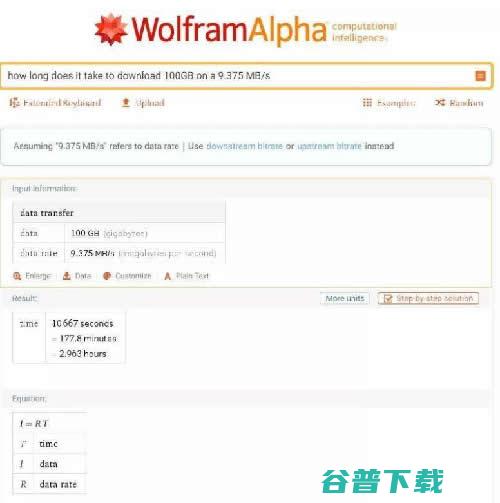
作为文字工作者,我每天都在跟搜索引擎打交道,比如在写Facebook的财报新闻时,Google可以告诉我它的实时股价、市值、近期高低点等非常有用的信息,但其实,还有另一个工具比Google更好用,那就是WolframAlpha,它比Google更进一步,可以用结构化的方式直接列出我可能需要的知识,举个最简单的例子,我家带宽是75Mbp...。

AI科技评论报道你永远不知道StyleGAN的想象力可以有多强大,刚刚英伟达最新推出的升级版StyleGAN3,因为一组合成艺术作品刷爆Twitter,不少网友感叹,AI制造了人类无法理解的恐怖!而更令人震惊的是,除了强大的它没有幻影的丝滑级过渡,以及对细节的高精度处理!StyleGAN生成式对抗网络是一种最先进的高分辨率图像合成方法...。

发表在专业问答2021,7,2816,46展示机型信息,品牌型号,当贝X3系统版本,当贝OS2.0可视流明是投影仪光源的亮度,ANSI流明是光源经过漫反射后的亮度;ANSI流明的数值需要通过九点测算法计算,而可视流明用照度计直接测量即可;投影仪ANSI流明的数值较低,可视流明的数值较高,可视流明和ansi什么区别1.可视流明是投影仪光...。

第三届武汉市全民创业赶集会暨中小智慧之选创业项目博览会,暨投融资洽谈会,时间,2009年12月1日-2日地点,武汉国际会展中心主办单位,武汉市经济委员会武汉市全民创业工作领导小组办公室联办单位,中共武汉市委统战部、市科技局、市监察局、市财政局、市人事局、市劳动社保局、市城管局、市农业局、市商务局、市知识产权局、市工商局、市质监局、市国...。
