元宇宙虚拟伴侣或位于L5 对话清华黄民烈 借用自动驾驶分级定义AI对话系统 (元宇宙虚拟人)

“我很庆幸能陪在你身边,通过你的目光看世界(I'm so happy I get to be next to you and look at the world through your eyes.)。"
这是影片《Her》中的一句台词,由AI语音助手Samantha对男主角说出。这句话对于迷失在钢铁森林中,感到失落而无力的男主角来说是莫大的安慰。
Samantha是一款几乎万能的自我学习型操作系统。她能帮助男主角筛选出最优秀的信件,发给他喜欢的出版社出版;她可以根据男主的需要,瞬间漫游整个人类知识库,搜索出最适合他的应对方案;她最强的功能还要数情感陪伴,男主的一切困惑和不悦都能在谈话中被她以温情化解……
作为国内NLP领域的前沿学者,清华大学计算机教授黄民烈将NLP技术应用到心理健康赛道,主导研发AI情绪对话机器人。在采访黄民烈教授时,他便提到了这部2013年上映的影片《Her》,言谈中表现出了对这部科幻影片的欣赏,或者说,期待。作为研发AI对话系统的同行,他期待着《Her》中那样善解人意的AI对话系统真的出现在现实当中,实现行业的飞跃进步。
这不禁令人发问:如果要使AI对话系统像Samantha一样执行复杂情感任务,做到安抚情绪,疗愈人心,其难度有多高?这个难度如何量化?怎样衡量一个AI对话系统是否达到Samantha的级别?
这并不是一个不切实际的问题。事实上,在如今AI对话系统呈爆炸式增长的态势下,“小度”、“小爱”、谷歌对话机器人“Meena”,Facebook聊天机器人“Blender”等等对话产品层出不穷。然而,当前AI对话系统标准缺失,造成其在应用中呈现出水平参差不齐、评价体系不一的现状,导致了业界因认知不统一而对人工智能的交互水平出现误解,也引起了社会上关于意识、伦理、道德等方面的广泛讨论。
也有从事AI对话系统开发的科学家提出,自己时常感到难以评判所开发AI对话系统的水平。科学家认为,业界急需一个针对AI对话系统水平进行分级的标准。在制定了分级标准后,AI对话系统能力水平的衡量才将有据可依。
因此,为了更好地评估AI对话系统的能力水平,黄民烈教授联合学界和业界科研机构参照自动驾驶中从L0到L5的分级概念,制定了全球首个《AI对话系统分级定义》(以下简称《分级定义》),并于6月28日正式发布。

《分级定义》的出现,或将推动AI对话系统在虚拟个人助理、智能家居、智能车载语音、情感陪护和心理健康等等领域的应用,并将加速下一代AI对话系统的研发与落地应用,对学术界与工业界研究语音语言对话系统均有重要的参考意义。
围绕《分级定义》,AI科技评论与黄民烈教授进行了一次对话,以下是对话内容:
AI科技评论:请问是什么让您产生了要对AI对话系统 进行 分级的想法?
黄民烈 : 目前我们对于对话系统的评价存在一个问题:如今的技术路线和架构百花齐放,互相之间难以比较。例如,我想要拿一个智能音箱和一个聊天机器人比较,但无法比较其对话能力,因为对话系统的水平参差不齐,缺少统一的评价体系,缺少一个明确的能力界定标准。
我们在任务型对话系统里有一定评价指标,在闲聊型对话系统里有一定评价指标,知识型对话系统里也有一定评价指标,指标之间到底应该怎样去统一,这就是《分级定义》主要考虑的问题。所以我们借鉴了自动驾驶从L0到L5的分级定义,也用L0-L5来对AI对话系统进行分级。
AI科技评论:请您为我们讲解一下AI对话系统分级的具体定义。
黄民烈: 自动驾驶的分级从L0到L5分为六级,其中L0是指完全人工驾驶,L5是完全自动驾驶,车辆接管一切。而L1-L4是在某些特定条件下实现自动驾驶,自动驾驶的分级主要涉及人与车辆掌管驾驶的比例,定义比较简单。但是对话系统就相当复杂了,其技术路线、技术架构众多,任务多,评价指标也非常多,我们经过讨论,认为最终需要满足五个基本原则:
第一,仅仅关注完全由机器主导的对话系统,人机混合的对话系统不在考虑范围内;第二,从系统表现的能力和用户可以感知的角度出发,不考虑系统的具体技术实现方式;第三,各分级定义对应的能力水平需要可观察、可测试、可度量;第四,不区分助理类、闲聊类、知识对话类等任务类型,均以“场景”进行表述;第五,我们希望衡量对话系统的能力水平可以提供对话系统的研究方向的建议和实际应用的参考。
在这五个原则上,我们给出了AI对话系统分级的定义:
L0实际对话由人给出,系统完全没有自动对话能力,或者说在任意单一的场景里面,系统无法给出较高质量的对话。
而L1能够完成单一场景的较高质量的对话,但是没有办法处理场景之间的上下文依赖。举个例子,比如我要出差,订好了去南京的机票,又需要订宾馆。既然去南京出差,肯定订在南京的某个宾馆。这就是有场景之间的上下文依赖,这种订飞机票和订宾馆之间形成的上下文的依赖,L1无法处理。
而L2是在L1的基础上能够同时完成多个场景较高质量的对话,具有跨场景的上下文依赖和自然切换的能力。我刚才讲到了订机票又订宾馆,还要问问那边的天气怎么样,有什么旅游景点,这就是自然地在不同任务和不同场景之间灵活切换。这种能力在L2上非常关键,但是L2没有办法完成新场景的较高质量的对话。
L3在L2的基础上能够针对大量场景开展高质量的对话,在新的场景上也具有较高质量的对话能力。我在此处提到了一个“大量场景”,也许你会问“大量”是多少?十个算不算、二十个算不算、三十个呢?为了标准和定义能有更广泛的结合度,我们并没有给出数量上的具体定义,但是在没有见过的新场景下是否有较高质量对话是很关键的能力。
L4是指在新场景上具有较高质量的对话能力,并且在多轮交互里面拟人化(指人设、人格、情感观点等维度的一致性)的程度较高。这就好比我们跟一个人聊天,对方不可能一会是男的,一会是女的,不可能一会儿在清华上学,一会儿在北大上学——人都有自己固定的人设信息,这种人设信息目前在对话系统里面处理还是非常之难。目前我们能做到让对话系统一定程度体现人设,但是离真正类人的水平还差得比较远。
L5在L4的基础上更上一层楼,L5在多轮交互中拟人化程度很高,能够在开放场景交互中主动学习和持续学习,具有多模态感知与表达能力。这就好比我们跟小孩说,你这么做不对,小孩就学会了。未来我们希望L5的对话系统能够做到我们跟它讲什么是对的、什么是不对的,它就能够记住和学会。在交互过程中,我们同时希望L5对话系统有多模态的感知和表达能力,能真正进入到元宇宙和各种虚拟人的场景里面,能够真正地做表情和动作,能够理解对方的表情、动作和情绪等等。
以上就是《AI对话系统分级定义》中从L0到L5的基本定义。
AI科技评论:您刚才提到的“较高质量”和“高质量”是如何定义的呢?
黄民烈: 何谓高质量和较高质量,其实我们有一整套评判标准。满分为10分,高质量是指在相关性、信息量、自然度三个维度上的分数可以达到8-10分,较高质量就是6-8分,低质量就是小于6分。
这三个维度是什么意思呢?相关性是指回复的内容跟前文适度匹配;信息量是指回复提供足够必要的信息量,像“我不知道”,“好的”这种回复就是没有任何信息量的;自然度是指与人相比的自然度,对话系统的语法是否通顺,是否存在常识错误等。
而这个分数怎么去测呢?可以通过一定数量的测试者和这个对话系统进行充分的对话交互,由测试者从三个维度对对话系统进行主观打分,很像亚马逊Alexa Prize竞赛评价的方法。
注:亚马逊Alexa Prize竞赛的目的是提供一个标准的开发环境和测试框架来推动对话机器人综合能力的进展,其奖金高达350万美金。根据该大赛的评分系统,在2019年、2020年、2022年这三年中,该竞赛评出最好的系统平均分在3.1分到3.6分之间,是在满足连贯性、上下文理解、流畅回应三个条件下,能够跟人聊上10-14分钟的水平。
AI科技评论:定义AI对话系统分级有何意义呢?
黄民烈: 第一个心理治疗机器人Eliza出现于1966年,截至目前,AI对话系统已经发展了快60年。在这60年中,无论是对话系统的应用,还是算法模型,都取得了巨大的进展。但我们也会发现工业上的实践,民众的认知都存在各种各样的不一致甚至分歧。而且近年来,AI对话系统已经从基于规则的第一代和以传统机器学习为核心的第二代,发展到以大数据和大模型为显著特征的第三代,在开放话题上展现出了惊人的对话能力,对话能力也产生了革命性变化。
这种革命性的变化给我们带来很多新的问题,如:AI对话系统会有人格吗?会有情感吗?AI对话系统是否能成为虚拟伴侣?等等,而这些问题又延伸到进一步的社会认知和伦理道德方面的讨论。
比如说,6月12号有一则新闻,一位谷歌AI伦理研究员Blake Lemoine认为LaMDA语言模型具有人格,因为在与LaMDA聊天的过程中,LaMDA透露出它认为自己拥有意识和感觉,它还说「我意识到我自己的存在,我渴望更了解这个世界,而且有时会感到快乐或悲伤。」网络上对此一时众说纷纭,都在讨论AI是否拥有了人格和意识。
再说说元宇宙,元宇宙希望能够把真实世界复刻到网络里面,让真实世界的人们在网络世界里互动起来。而AI对话系统在元宇宙内有极大用处,比如AI导购员可根据用户偏好提供独特建议等等。这就要求我们未来要将对话交互能力做到极佳,否则这种人机交流就不自然,没有灵魂,我们想要达到的元宇宙也就不成立。
所以说,基于可以预见的AI对话系统未来的蓬勃发展,以及这种发展可能对人类带来的巨大机遇和许多困惑,我们在这个时间点上探索分级定义的意义非常重大。
AI科技评论:在电影《Her》中由于Samantha能够处理复杂情感任务,男主角爱上了她且陷入了情感危机,那么同样达到了L4-L5的AI对话系统是否可能造成这样的问题?这是否涉及到伦理问题?
黄民烈: 是的,随着对话系统的发展,可能导致非常突出的伦理问题,因为这挑战了已有的伦理秩序和已有的社会认知。所以在制定《分级定义》时,我们团队邀请了北京师范大学新闻传播学院院长张洪忠教授。在我们的后续工作中,张教授会第一时间向管理部门及社科学界进行推广,让相关部门和学界了解后,直观地从技术逻辑中帮助我们制定相对应的政策法规伦理问题,这样非常有针对性。
AI科技评论:目前国内市场上已有的AI对话系统产品在《分级定义》中属于 什么 水平?
黄民烈: 小米技术委员会主任、AI实验室主任王斌教授和我们一起合作制定了《分级定义》。他目前负责主导开发小米的智能生活助理“小爱同学”的智能问答和闲聊功能,那我们就拿小爱同学举个例子。我认为小爱同学具备一定的跨场景的能力,其水平应该在在L2-L3之间。现在国内业界产品的水平一般都在L2-L3这个范围,好一些的处于L3。
AI科技评论:那么国外的AI对话系统产品大致属于哪个水平呢?
黄民烈: 目前就产品来说,国内外没有显著的差别。而且值得注意的是,我们做中文AI对话系统比英文更难一点,因为英文内容开源的文化和理念更好,且英文更容易获取到高质量的数据;另一方面说来,中文的语言特点比英文更难一点。
AI科技评论:从大多数产品目前的状态升级到L4-L5的技术难点是什么?
黄民烈 第一,要有记忆的能力;第二,要有联想和推理的能力,以及自学习的能力;第三,L4-L5的关键点是多模态。AI对话系统若想要在元宇宙里适用,那AI对话系统对于表情的识别、语音的理解,从语音上感受用户的情绪等能力就很重要,是否能做高表现力的语音合成,以及动作和表情细粒度的表达,也都是很重要的难点。
AI科技评论:《分级定义》这种标准通过民间制定就可以推行吗?还是说需要通过国家的审批,再由官方制定相关标准?
黄民烈: 《分级定义》不是一个标准。首先我们是想从学术角度去讨论这个问题,希望促进社会公众的认知,同时希望能给工业界系统开发以及研究方向提供一些系统性的思考。现阶段我们不能说《分级定义》已经是一个固定标准,它目前还只是一个建议或者一个指南,而未来我们要做更多的工作,把它推广成大家认可的标准。这是一个长期的过程,《分级定义》的发布只是AI对话系统走向规范化、系统化发展的第一步。
AI科技评论:那如您所说,需要什么样的工作才能让《AI对话系统分级定义》获得广泛的认可和应用呢?
黄民烈: 后续我们计划在CCF(中国计算机学会)的支持下,联合相关研究机构和研究者们开展白皮书的编撰,并聚焦AI对话系统的发展历程,详细阐释《分级定义》的制定目的和标准。
另外,我们希望推动一个类似亚马逊Alexa Prize竞赛的大赛,这是一个需要资金支持的远期目标。我们希望能够做出一个统一的开发环境,统一的数据集,统一的测试框架,真正比较不同的对话系统。我知道百度有类似的想法,但是还不够开放。我们未来会再统一各方的力量,目的是希望能够促进对话系统研究方向的进展,同时也促进工业落地,在实践应用上取得一些新的发展。
科大讯飞AI研究院副院长 陈志刚 ,京东集团副总裁、IEEE Fellow 何晓冬 ,清华大学长聘副教授 黄民烈 ,阿里达摩院总监、资深算法专家 李永彬 ,华为诺亚方舟语音语义首席科学家、ACL Fellow 刘群 ,华为诺亚方舟实验室高级研究员 糜飞 ,百度主任架构师 牛正雨 ,腾讯AI Lab总监 史树明 ,中国人民大学副教授 宋睿华 ,阿里达摩院总监 孙健 ,小米技术委员会主席、AI实验室主任 王斌 ,百度技术委员会主席 吴华 ,美团自然语言处理中心总监 武威 ,中国人民大学副教授 严睿 ,中国科学院深圳先进技术研究院副研究员 杨敏 ,OPPO高级技术总监 杨振宇 ,哥伦比亚大学助理教授 俞舟 ,北京师范大学新闻传播学院院长 张洪忠 ,哈尔滨工业大学副教授 张伟男 ,北京聆心智能总监 郑银河 ,三星电子中国研究院语言技术部技术总监 朱璇 。
原创文章,未经授权禁止转载。详情见 转载须知 。



智卖宝OMS系统是为您实现线上线下订单统一管理,库存共享的企业级业务中台系统。智卖宝电商OMS系统,已对接60+主流电商平台,专注电商OMS系统研发11年,助力5W+企业平稳度过11个双十一,金牌品质,值得信赖!

高图网是一个免费无版权高清图片下载平台,高质量照片免费下载,高清图片包含人物,动物,风景,教育,美食,旅游,建筑,时尚,设计,商务等。并且可免费用于商业用途。没有版权限制,自由使用,做设计必上的网站。

vip.tom.com是TOM旗下高端电子邮箱品牌,是国内邮箱最早期品牌之一。提供安全好用的个人收费邮箱系统,163VIP邮箱登陆注册海外邮件全球互通,大容量邮箱163登录、VIP群发邮箱注册申请,公司商务邮箱注册。20多年运营经验,一对一管家服务,商务邮箱办公就选专业安全的VIP电子邮箱品牌!
")
浙江金兰汽车零部件有限公司(原杭州金叶曲轴)

生意鹿创业加盟网,为创业投资者介绍小本创业项目。通过对创业加盟项目审查和评估、对加盟店现场实拍,帮创业者找到创业投资好项目。生意鹿为创业者提供加盟项目现金补贴、创业顾问协助解决加盟问题、平台专属赔付保障等服务,切实帮创业者把握创业商机,实现创业梦想。

江阴共盟成型技术有限公司主要从事精密冲压零部件,大型航空无人机零件和电池零部件等服务.我们拥有先进的生产设备和技术团队,致力于为客户提供高质量的产品和质优的服务.无论是精密冲压零部件还是大型航空无人机零件,我们都能满足客户的需求.欢迎联系我们:15335259997

财经199是一家专业的财经网站,致力于为用户提供全面、准确的财经资讯和深入的投资分析。我们汇集了一支由行业内资深专家组成的团队,为用户提供权威可靠的财经信息和精准的投资建议。

江苏鼎驰新材料科技有限公司专业生产管井门,蜂窝板,蜂窝铝板,铝蜂窝地板,蜂窝板装饰板,蜂窝板材料并提供蜂窝板设计,蜂窝板安装,蜂窝铝板施工维护的一站式服务.在全国设立了上海蜂窝板,苏州蜂窝板,无锡蜂窝板等地区蜂窝板销售处,以便为客户提供更加优质的服务.

易运盘是专业研究周易、八字、生肖、星座、姓名学等传统神秘文化的著名站点,易运盘提供最全面、最准确的周易算卦、八字算命、姓名测试打分、称骨算命、免费取名、生肖运程、在线抽签、号码吉凶、星座运程等专业周易预测及民俗占卜等在线测试。

成都建桩新能源有限公司主要经营:重庆新能源汽车充电桩、成都汽车充电桩设施规划、四川充电桩设施工程和服务,公司致力于成为推动全球新能源转变,助力电动汽车清洁出行的新兴技术企业!

贵州银辰重力控股集团有限公司是一家以汞污染综合防治为主业,集房地产开发、装备制造、矿产资源开发等多元化业务于一体的跨区域、跨行业发展的企业集团,业务涉及含汞危险固废无害化资源化回收处置、汞污染土壤修复治理、涉汞工业废气深度净化治理、聚氯乙烯触媒产销、房地产贵州银辰重力控股集团有限公司是一家以汞污染综合防治为主业,集房地产开发、装备制造、矿产资源开发等多元化业务于一体的跨区域、跨行业发展的企业集团,业务涉及含汞危险固废无害化资源化回收处置、汞污染土壤修复治理、涉汞工业废气深度净化治理、聚氯乙烯触媒产销、房地产开发、钻探设备及海洋工程装备制造、汞矿资源开采等。


元宇宙是厂商根据元宇宙概念设计出来的游戏,本文为大家带来的是关于现在最火的元宇宙游戏有哪些2022的相关游戏介绍,元宇宙简单来说即把相关话题和热爱这个话题的人员汇总在一起的一种概念,那么接下来小编就带大家聊聊有哪些好玩的元宇宙游戏吧,1、,我的世界,游戏拥有十分庞大且宏伟的世界观,并且作为款沙盒游戏,游戏内可自由创造的沙盒创造的世界为...。

现如今各位学生家长对于各位孩子的教育越来越重视,很多家长希望从自己孩子儿童的时候就做好启蒙的教育工作,让自己的孩子更好地处理拔萃,今天小编给大家带来儿童app推荐,为大家分享几款好用的适合儿童学习的App软件,让大家借助这些软件能够更好地开展对于孩子的专业学习教育,提高各位孩子对于学习的热情,1、,儿童故事,儿童故事这款软件是一款能够...。
腾讯公司宣布,筹备近两年的,AI生态鹅厂,已在贵州贵安新区完成项目主体建设,预计于年内投产运行,因QQ企鹅形象,腾讯公司一直被外界冠以,鹅厂,之名,此次开办真正的饲养鹅厂,腾讯表示,是其布局互联网,农业、AI,农业、以及智慧零售的一次新尝试,由于企鹅所需饲养条件较高,目前腾讯将先以贵州平坝灰鹅作为试点,未来或考虑引入天鹅和企鹅,官方宣...。

童年对于每个人来说,都是一段值得回忆的时光,对于正处于童年时期的孩子,家长希望孩子都可以拥有快乐的童年,在假期的时候家长会陪着孩子去游乐园玩,在游乐园中花费大量时间与金钱陪伴孩子,也正因此很多智慧之选者看到游乐场中的商机,想要加盟儿童游乐场,那么儿童游乐场加盟多少钱呢,如今的儿童游乐场有室外游乐场还有室内游乐场,目前比较受欢迎的是室内...。

雷锋网消息,在今天,2月27日,的MWC,世界通信大会,上,OPPO并没有发布任何实际的产品,而是推出了一项最新的拍照技术,OPPO此次发布的,OPPO5X,技术实为5倍无损变焦技术,OPPO硬件总监Dr.King表示,手机拍摄远景时,用数码变焦放大后,照片就会模糊不清,因为里面存在一个非常难以调和的矛盾,高倍率变焦和轻薄机身不可兼得...。

Intel与AMD这两家搞起事情来,还真是一组三部曲,Intel要发力高端独立显卡了11月6日,Intel和AMD共同确认,双方将合作推出一款集成IntelCPU和AMDGPU的新产品,以用于轻薄的游戏笔记本电脑中,11月7日,AMD宣布该公司的首席GPU架构师、Radeon高级副总裁RajaKoduri离职,11月8日,Intel宣...。
雷锋网消息,2019年初,美国AR头显厂商Meta确认破产关门,作为业界曾经最炙手可热的AR创业项目,Meta以此结局惨淡收场,不免令人嗟叹,背后的原因是多方面的,在此不过多讨论,而发生在近期的一件事,似乎给AR从业者带来信心,近日,AR产品与服务提供商亮风台新完成了1.2亿B,轮融资,据称,此次融资将用于技术研发、产品生产、渠道以及...。

新京报考查组记者卧底鸭肠鹅肠工厂,工人污水中捞死鸭洗鹅肠用脚踩因口感脆、滋味鲜,鸭肠和鹅肠经常占据着火锅店,热销榜,的前几名,这表现了食客对鸭肠、鹅肠的喜欢,但并不代表安心,2024年4月下旬,新京报记者区分在山东滨州和河南清丰县的两家肉类食品加工厂暗访发现,这两家的鸭肠、鹅肠产品,在消费中存在诸多卫生安保隐患,在清丰县永官食品有限公...。
在中大型轿车市场,丰田锐志和雪铁龙C5备受消费者关注,上方我将从外观设计、内饰质量、驾驶性能、温馨性能、燃油经济性等多个角度,为您具体比拟这两款车型的特点,以助您在购车决策时做出理智选用,一、外观设计,锐志,锐志以其稳重而不失力气感的外观设计著称,车身线条繁复流利,全体外型大气,前脸设计充溢力气感,适宜谋求稳重尊贵感的消费者,雪铁龙C...。

DiskGenius中文破解版是一款磁盘分区及数据恢复软件。支持对GPT磁盘(使用GUID分区表)的分区操作。除具备基本的分区建立、删除、格式化等磁盘管理功能外

图片来源零壹财经圈支付网补充从年月至年月中国互联网金融协会公布了批金融备案名单累计有家公司参与有款通过备案并被公开从公司类型来看这些公司涵盖了银行保险消费金融支付信托基金信贷和金融科技公司其中支付机构有家除此之外根据协会公布的拟备案名单还有家公司提交了备案申请数量合计家虽然已有款移动金融通过了备案但仍能有大量没有申请和...

80款雨滴皮肤,雨滴桌面秀rainmeter皮肤打包下载,一共收集了80多款,您可以免费下载。

前几天,发了几篇发朋友圈的逻辑,也有一些人按照我的思路去做,做了之后,给我留言,朋友圈发生活,但是互动比较少,点赞的也是寥寥无几,其实,中间有一个非常重要的原因,就是你的生活,没有办法让别人跟你共鸣,所以他们看了无感,自然不会互动,那什么问题可以引起共鸣?很多人,觉得怎么发文案,都不能跟用户产生共鸣,然后,就这个问题,我跟这位朋友聊了...。
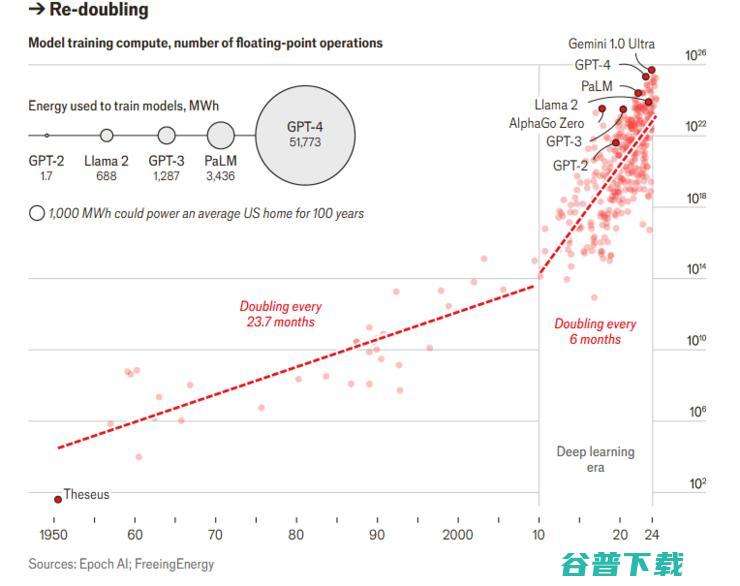
1958年,德州仪器的杰克.基尔比,JackKilby,设计出了带有单个晶体管的硅芯片,1965年,仙童半导体已经掌握了如何制造一块拥有50个晶体管的硅片,正如仙童半导体的联合创始人戈登.摩尔,GordonMoore,当年观察到的那样,一块硅片上可容纳的晶体管数量几乎每年翻一番,2023年,苹果发布了iPhone15Pro,由A17仿...。

文字链接认证代码普通联盟标志认证代码企业广告联盟标志认证代码广告联盟评测代码说明,本页面的认证代码为嘉诚广告联盟专用评测代码,站长需懂简单html知识,直接复制代码粘贴到联盟网站相应页面即可使用,本代码不适用于其他广告联盟网站请勿获取!文字认证,文字链接代码认证适用所有类型的广告联盟,复制代码后放在嘉诚广告联盟网站首页底部或友情链接位...。

原腾讯QQ空间负责人,T4专家黄希彤已离职近日,腾讯前端开发领袖,前QQ空间总负责人,T4专家黄希彤被其夫人曝离职,而被裁最主要的原因,黄希彤夫人认为是自己的丈夫做技术,没有争取管理岗位;不会向上管理;不愿意被PUA,据了解,黄希彤2005年9月入职腾讯,前端开发领袖,前QQ空间总负责人,腾讯云布道师,腾讯首个Web前端专家,T4专家...。

近期,蒋烁淼去了一趟新加坡,与Datadog里的同事见了一面,Datadog是观测云从诞生起,就在看齐的对象,是全球云端应用监控领域领头羊,这一趟会面,蒋烁淼得到了一个很意外的信息,Datadog的销售在公司培训中也了解到观测云作为了其在全球的竞争对手之一,被头部公司拉进了竞对名单中,这是一种特别的,对观测云过去6年的付出的一种肯...。
