这套477页的开源电子书和598页的课件 是一份写给机器翻译爱好者的学习资料 (479页)
自然语言处理是人工智能皇冠上的明珠,而填补语言鸿沟的机器翻译则是自然语言处理最典型的应用技术之一。自20世纪90年代起,机器翻译迈入了基于统计建模的时代,发展到今天,深度学习等机器学习方法已经在机器翻译中得到了大量的应用,因此目前也是相当火爆。想必同学们也会经常在网上找一些好的学习资源。
最近,笔者在 github 上发现了一份机器翻译的教程,项目的 GitHub 地址为:
(文末附一键下载地址)



这套教程对机器翻译的统计建模和深度学习方法进行较为系统地介绍,不仅有相应的原理介绍和实现代码,还提供了实战案例,并通过图例对一些形式化定义和算法进行解释(共320张插图),对初学者来说,极为友好,可以学会建立自己的模型。
值得一提的是,这份机器翻译教程还很贴心地提供slides,每个章节都有对应的课件,slides 共有 598页之多。整理好的slides,直接下载pdf就能使用,这人文关怀,无微不至。
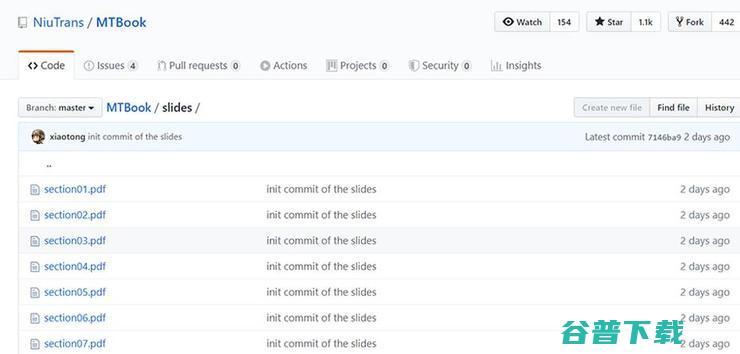

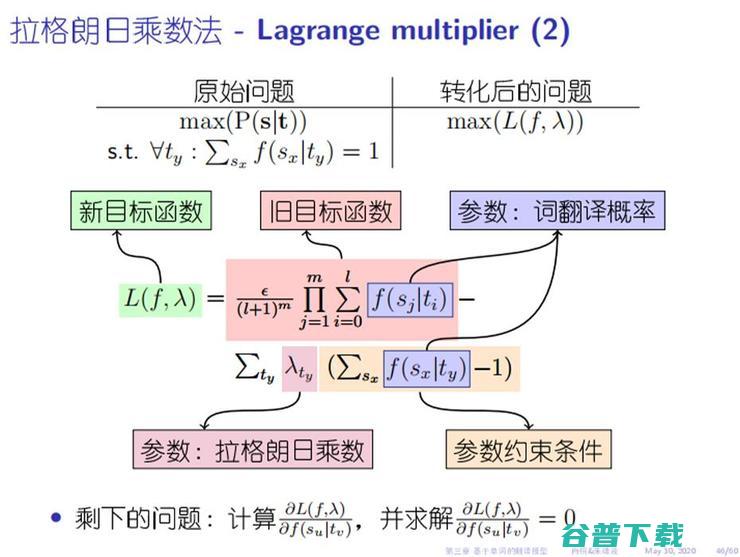
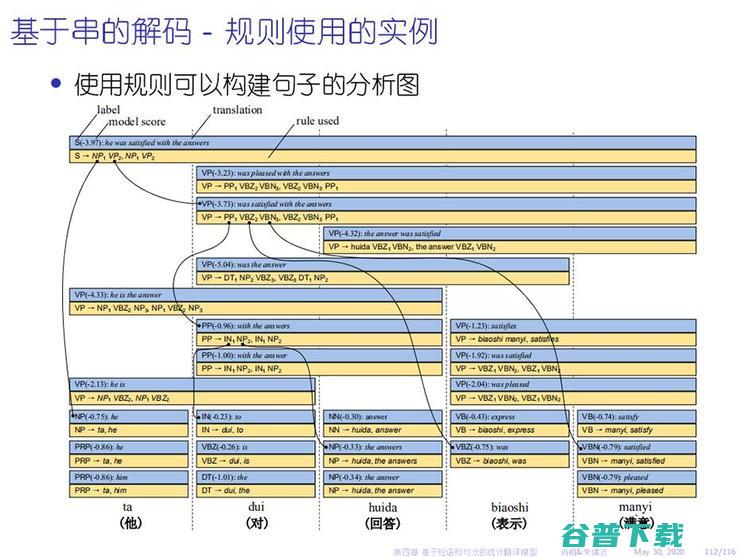
就有网友评价道:算法、参数设置实验都比较细致,对小白友好,对专业领域的小伙伴很有帮助。

废话就不多说了,让我们一起来具体看看都有哪些内容吧:本教程共分为七个章节,章节的顺序参考了机器翻译技术发展的时间脉络,同时兼顾了机器翻译知识体系的内在逻辑。各章节的主要内容包括:

如果在学习中遇到相关问题,还可以点击下面的网址,加入讨论区答疑:
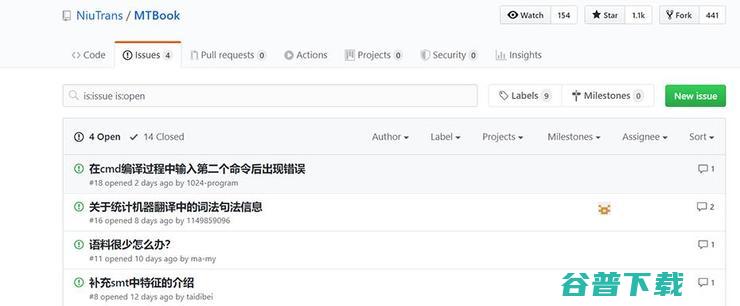
这份名为《机器翻译:统计建模与深度学习方法》的教程是由肖桐、朱靖波老师编著,东北大学自然语言处理实验室· 小牛翻译联合出品的。作者表示, 开源的本质是,通过对于源代码的免费共享使得无论软件还是硬件都可以通过社会化协作的方式,吸引更多志同道合者 。这种“人人为我,我为人人”也是他们团队做开源项目所推崇的。撰写这份教程的目的,是让更多的人理解并学会机器翻译技术,并让这项技术帮助更多有需要的人。这套教程可以供计算机相关专业高年级本科生及研究生学习之用,也可以作为自然语言处理,特别是机器翻译领域相关研究人员的参考资料。
目前,所有源代码均已开放。上架不到一周的时间,在GitHub上的热度已经突破1000颗星星~这么好的资源,同学们赶快学起来吧!
一键下载电子书和PPT地址:


新闻媒体网站排名,根据网站的综合值按照不同的新闻媒体网站进行筛选排名结果,通过筛选新闻媒体网站可以看到每个新闻媒体网站里面的网站排名优质的网站是哪些

LOL网址导航网是专业的上网导航网站,精心收录各类优质热门网站信息,同时提供天气、快递、违章等各种生活便民查询工具网址,为您提供安全便捷的上网导航服务,现已被众多网友设为上网主页,网址导航大全首选LOL网址导航.

泰州卫生间免砸砖修漏水电话400-1566-200,专业防水补漏,泰州本地上门勘察,多年防水经验,使用先进检测维修设备和优质防水材料,快速彻底解决房屋漏水问题。

果博东方公司客服电话19048888882【190-4888-8882】果博东方24小时在线客服,果博东方客服电话,果博东方公司直属客服,果博东方公司直属开户,果博东方公司客服联系方式

江苏探感物联(www.etagrfid.com.cn)作为RFID厂家,专注于RFID电子耳标,抗金属rfid标签,超高频rfid标签,超高频rfid读写器,工业rfid读写器等rfid设备。主要应用有RFID资产管理系统,RFID仓储管理系统等一站式RFID服务。

气象在线为您提供完整的气象服务解决方案,包括:天气预报、分钟级降水、空气质量、景区天气、机场天气、国际城市天气、灾害预警、气象新闻、气象科普等服务内容;

小手游戏是中国最大的游戏运营平台,为中外游戏玩家提供最新、热门的精品游戏;致力于成为中国最具影响力的游戏联运平台!

北京中巴租车公司租车价格低,带司机租车,5-55座大巴中巴小巴商务车车型齐全,北京旅游商务班车展会租车,全网低价,贵就赔!车型多,租方便!福泽租车,放心的服务,放心的价格,去哪里还是找福泽!

九萌移民业务地区有美国、爱尔兰、加拿大、葡萄牙、新西兰、西班牙、欧洲、澳大利亚、瓦努阿图,希腊、意大利、马耳他等地区,移民项目涵盖雇主担保,投资移民,技术移民,商业移民,购房移民,九萌移民致力于通过互联网技术和思维重构传统移民行业,为全世界华人提供精准全面的海外信息和优质服务。

开阔是一家以互联网为基础的服务公司,通过技术丰富互联网用户的生活,助力企业发展升级。我们的使命是“为企业及个人工作降低成本,提升效率

西鱼AI资源导航是一个汇聚集国内外优秀AI应用工具网址导航平台,包括AI绘画、AI内容设计、AI语音生成、AI短视频生成、AI自媒体写作、AI客服、AI办公、AI营销、数字人等人工智能工具。提供一站式AI工具导航服务,帮助用户提升工作效率和创作能力,定时更新分享优质AI工具应用书签。

以权威、公正、领先的视角树立商品真伪验证,维护消费者安全,保障消费者权益,推动中国商品无假货健康发展。


百货店是大家都比较熟悉的一类零售门店,在国内很多城市地区都有着专业的百货零售门店火热经营发展,其中很多的零售百货品牌以出色的产品获得了消费者的喜爱,恋惠优品快时尚百货作为业内出色的百货零售品牌,在业内有着较好的品牌发展成绩,以休闲快时尚百货获得业内外诸多人士的关注和认可,选择恋惠优品快时尚百货进行加盟是很多创业人士的想法,那么,加盟恋...。

餐饮品牌店有很多,为了给大家提供更好产品选择,市场也出现了很多受欢迎的日式料理品牌店得到大家关注,有喜屋可以给顾客带来更满意的产品选择,打造受欢迎的品牌,出餐速度也很快,有喜屋加盟支持有哪些,有喜屋门店在筹备过程中,会根据公司的需求做好门店的筹备,总部能够以日式料理店的运营为主,保持门店出餐速度更快,给顾客带来健康营养美食,拥有更好的...。

本文作者李王,创客马拉松深大站参赛选手,深职院大二学生,本文详细介绍了他自己DIY的一款,8X8X8,点阵3D显示器,下图,的全部制作过程,3Dcube8,光立方,是一个由LED组成的3D显示器,是一个集实际型、经济型、性价比高的艺术品,它不仅仅局限于装饰,更是能够帮助更好的学习C语言实际应用、满足单片机爱好者对单片机的研究的个好工具...。

发表在当贝投影仪2024,4,1816,15当贝D6X是最新上市的激光投影设备,配备有云台支架,那么和同价位的极米RS10mini对比有哪些不同呢,下面就通过详细的参数配置进行对比分析,看看当贝D6X和极米RS10mini区别有哪些,哪款投影仪更值得入手,一、当贝D6X和极米RS10mini区别有哪些,1.画质不同光源方面,当贝D6X...。

好吃的零食加盟店,多为经油炸类、坚果类、干燥类、腌制类,包括凉果、蜜饯,、烘炒类或者糖果、膨化类等等,但在华人普遍的概念不包括糕点面包类食物、冰激凌、汽水在内,零食多食无益,在选购零食时宜选择健康零食,好吃的零食加盟店,20平方米零食店装修费,1万元,首批货款,2万元,每两月进货费,1万,2万元,房租,2000块钱,水电费,300,4...。

文字链接认证代码普通联盟标志认证代码企业广告联盟标志认证代码广告联盟评测代码说明,本页面的认证代码为龙凤广告联盟专用评测代码,站长需懂简单html知识,直接复制代码粘贴到联盟网站相应页面即可使用,本代码不适用于其他广告联盟网站请勿获取!文字认证,文字链接代码认证适用所有类型的广告联盟,复制代码后放在龙凤广告联盟网站首页底部或友情链接位...。

申明,1.以上内容仅代表揭发者自己,不代表黑猫揭发立场,2.未经授权,本平台案例制止任何转载,违者将被清查法律责任,3.黑猫揭发处置揭发不收取任何费用,凡以黑猫揭发名义不要钱的均为混充、诈骗行为,请及时报警并与黑猫官网反应,揭发邮箱heimaotousu@vip.sina.com,4.请大家选用官网渠道处置生产纠纷,不要轻信第三方机构...。

手机qq浏览器ios版app腾讯公司专为苹果手机用户打造的浏览器,聚合了海量腾讯资源,视频、小说、新闻、漫画...应有尽有,享受极致上网体验,上网速度超快流畅深受广大用户喜爱。赶快下载试试看吧!qq浏览器苹果版介绍【漫画新界面】全新界面,漫画放送季,海量正版

重庆分类目录网站将2020年03月共113个网站收录信息按收录时间分类整理归档列表,可以方便网友浏览按年月查询,更好地享受精彩网站的魅力!

《保健食品原料目录营养素补充剂(2023年版)》等四个保健食品目录发布,保健食品原料目录营养素补充剂,监管总局,营养素,保健食品,补充剂

根据进程名获取句柄并设置全部enable工具,根据文件名查找窗口句柄,设置显示隐藏,鼠标获取句柄,enable按钮等,这是一个可用于破解方面的小工具,可通过鼠标指向方式获取某个控件的句柄,程序自动将所有控件设置为enable,解除灰色按钮等,您可以免费下载。

360极速浏览器app是360旗下的一款ios浏览器应用。360极速浏览器手机版采用简约的设计风格、全新的版面布局、强大的智能搜索、海量的优质内容,带来极致的浏览体验;您可以免费下载。

快餐的市场相当广阔,快餐连锁是餐饮的一种商业组织形式和经营模式,指快餐企业经过连锁经营和特许经营的方式品牌拓展,根据商务部发布的,特许经营管理办法,,连锁企业必须具备2店1年才有出售特许经营权的权利,快餐连锁是餐饮业发展到一定程度时的一个必然的产物,是特色餐饮的一种发展模式,餐饮行业能好众所周知,随着我国国民经济稳定快速增长,城乡居民...。

始终保持每年技术进步30%,这是科大讯飞对技术的要求,也是公司每一位科研人员的自我要求,巴别塔本是犹太教是,圣经·旧约·创世记,中的一个故事,说的是人类产生不同语言的起源,在这个故事中,人类联合起来兴建希望能通往天堂的高塔;为了阻止人类的计划,上帝让人类说不同的语言,使人类相互之间不能沟通,计划因此失败,人类自此各散东西,语言是作为最...。

根据联合国世界卫生组织的划定,44岁以上的才叫中年,我现在还是青年好吧,当我让李宇浩先生回忆自己的青年时代时,他语气认真的打趣道,李宇浩丰富的职业经历堪比一位连续创业者,那股爱折腾的劲,贯穿始终,回看他的职业生涯,其先后涉足半导体显示公司、投资公司、IT公司、地产公司、机器人公司,行业跨度之大,乍看之下似乎让人有些摸不着头脑,而经...。
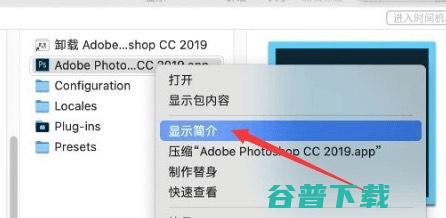
很多的用户在使用了M1芯片后需要用到ps进行办公,但是就有很多的用户反馈说在使用液化等一些格式的时候电脑就会黑屏,菜单栏什么的就没法正常显示了,那么PS2019M1芯片版液化黑屏不能用怎么办,下面就跟小编一起来看看吧!PS2019M1芯片版液化黑屏不能用解决办法1、安装ps2019的m1版本后,打开应用程序文件夹,找到Photosho...。

11月13日,国务院台办举办例行资讯发布会,有记者问,台陆委会日前提示台商留意赴大陆投资危险,对此有何评论,发言人朱凤莲示意,这种说法齐全是无事生非,是民进党当局争光大陆的习用手段,大陆经济开展能源足、韧性强,市场化、法治化、国际化营商环境继续提升,往年前三季度,大陆经济同比增长4.8%,增速谢环球关键经济体中位居前列,其中高技术产业...。
