显著降低模型训练成本的主动增量学习 CVPR 2017精彩论文解读 (显著降低模型的方法)
雷锋网 AI 科技评论按:计算机视觉盛会 CVPR 2017已经结束了,雷锋网 AI 科技评论带来的多篇大会现场演讲及收录论文的报道相信也让读者们对今年的 CVPR 有了一些直观的感受。
相对于 CVPR 2017收录的共783篇论文,即便雷锋网 AI 科技评论近期挑选报道的获奖论文、业界大公司论文等等是具有一定特色和代表性的,也仍然只是沧海一粟,其余的收录论文中仍有很大的价值等待我们去挖掘,生物医学图像、3D视觉、运动追踪、场景理解、视频分析等方面都有许多新颖的研究成果。
所以我们继续邀请了宜远智能的刘凯博士对生物医学图像方面的多篇论文进行解读,延续之前最佳论文直播讲解活动,陆续为大家解读2篇的论文。
刘凯博士是宜远智能的总裁兼联合创始人,有着香港浸会大学的博士学位,曾任联想(香港)主管研究员、腾讯高级工程师。半个月前宜远智能的团队刚刚在阿里举办的天池 AI 医疗大赛上从全球2887支参赛队伍中脱颖而出取得了第二名的优异成绩。
在 8 月 1 日的直播分享中,刘凯博士为大家解读了「Fine-tuning Convolutional Neural Networks for Biomedical Image Analysis: Actively and Incrementally」(用于生物医学图像分析的精细调节卷积神经网络:主动的,增量的)这篇论文,它主要解决了一个深度学习中的重要问题:如何使用尽可能少的标注数据来训练一个效果有潜力的分类器。以下为当天分享的内容总结。

刘凯博士:大家好,我是深圳市宜远智能科技有限公司的首席科学家刘凯。今天我给大家介绍一下 CVPR 2017 关于医学图像处理的一篇比较有意思的文章,用的是 active learning 和 incremental learning 的方法。
今天分享的主要内容是,首先介绍一下这篇文章的 motivation,就是他为什么要做这个工作;然后介绍一下他是怎么去做的,以及在两种数据集上的应用;最后做一下简单的总结,说一下它的特点以及还有哪些需要改进的地方。

其实在机器学习,特别是深度学习方面,有一个很重要的前提是需要有足够量的标注数据。但是这种标注数据一般是需要人工去标注,有时候标注的成本还是挺高的,特别是在医学图像处理上面。因为医学图像处理需要一些 domain knowledge,就是说医生对这些病比较熟悉他才能标,我们一般人是很难标的。不像在自然图像上面,比如ImageNet上面的图片,就是一些人脸、场景还有实物,我们每个人都可以去标,这种成本低一点。医学图像的成本就会比较高,比如我右边举的例子,医学图像常见的两种方式就是X光和CT。X光其实一个人一般拍出来一张,标注成本大概在20到30块钱人民币一张;CT是横断面,拍完一个人大概有几百张图片,标注完的成本就会高一点,标注的时间也会比较长。
举个例子,比如标1000张,这个数据对 deep learning 来说数据量不算太大,X光需要2到3万人民币、3到4天才能标完;CT成本就会更长,而且时间成本也是一个很重要的问题。那要怎么解决深度学习在医学方面、特别是医学图像方面的这个难题呢?就要用尽量少的标注数据去训练一个 promising 的分类器,就是说一个比较好的分类器。
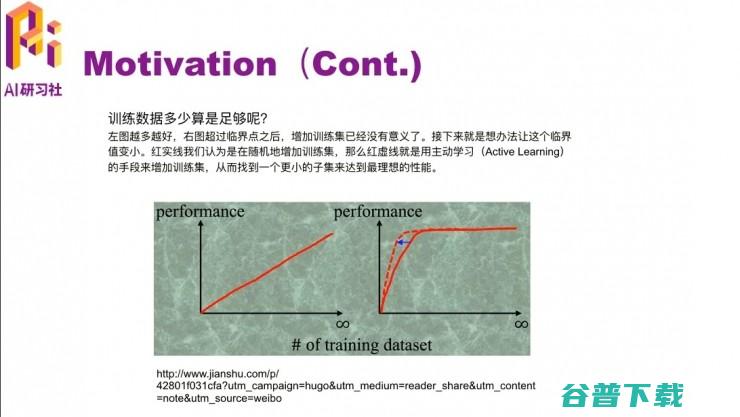
那我们就要考虑要多少训练数据才够训练一个 promising 的分类器呢?这里有个例子,比如左边这个图,这个模型的 performance 随着数据的增加是一个线性增长的过程,就是说数据越多,它的 performance 就越高。但在实际中,这种情况很少出现,一般情况下都是数据量达到一定程度,它的 performance就会达到一个瓶颈,就不会随着训练数据的增加而增加了。但是我们有时候想的是把这个临界点提前一点,让它发生在更小数据量的时候。比如右边这个图的红色虚线部分,用更小的数据达到了相同的 performance。这篇论文里就是介绍主动学习 active learning 的手段,找到一个小数据集达到大数据集一样的效果。

怎么样通过 active learning 的方式降低刚才右图里的临界点呢?就是要主动学习那些比较难的、容易分错的、信息量大的样本,然后把这样的样本标记起来。因为这些是比较难分的,容易分的可能几个样本就训练出来了,难分的就需要大量的数据,模型才能学出来。所以模型要先去学这些难的。
怎么去定义这个“难”呢?就是 “难的”、“容易分错”、“信息量大” ,其实说的是一个意思。这个“信息量大”用两个指标去衡量,entropy大和diversity高。entropy就是信息学中的“熵”,diversity就是多样性。这个数据里的多样性就代表了模型学出来的东西具有比较高的泛化能力。举个例子, 对于二分类问题,如果预测值是在0.5附近,就说明entropy比较高 ,因为模型比较难分出来它是哪一类的,所以给了它一个0.5的概率。
用 active learning 去找那些比较难的样本去学习有这5个步骤
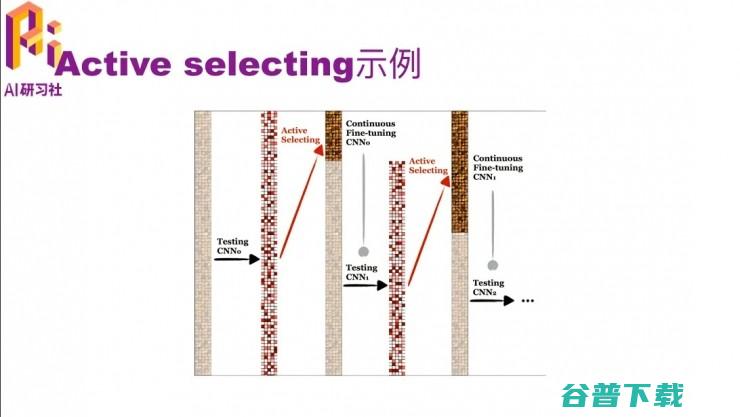
刚才的文字讲解可能不是很直观,我们用一个图来看一下。这个图从左到右看,一开始灰蒙蒙的意思是都还没有标注,然后用一个pre-trained model去预测一遍都是哪个类。这样每个数据上都有一个概率,可以根据这个概率去选择它是不是难分的那个数据,就得到了中间这个图,上面那一段是比较难的,然后我们把它标注出来。然后用一个 continuous fine-tune 的 CNN,就是在原来的模型上再做一次 fine-tune,因为有了一些标注数据了嘛,就可以继续 fine-tune了。fine-tune后的模型对未标注的数据又有了一个预测的值,再根据这些预测值与找哪些是难标的,把它们标上。然后把这些标注的数据和之前就标注好的数据一起,再做一次continuous fine-tune,就得到 CNN2了。然后依次类推,直到把所有的数据都标完了,或者是在没有标完的时候模型的效果就已经很好了,因为把其中难的数据都已经标完了。

刚才提到了两个指标来判定一个数据是不是难分的数据。entropy比较直观,预测结果在0.5左右就认为它是比较难分的;但diversity这个值不是很好刻画,就通过>

这就会产生一个问题,原始的图像,比如左边这只小猫,经过平移、旋转、缩放等一些操作以后得到9张图,每张图都是它的变形。然后我们用CNN对这9张图求是一只猫的概率,可以看到上面三个图的概率比较低,就是判断不出来是一只猫,我们直观的去看,像老鼠、狗、兔子都有可能。本来这是一个简单的例子,很容易识别出来这是一只猫,但是增强了以后反而让模型不确定了。这种情况是需要避免的。
所以这种时候做一个 majority selection,就是一个少数服从多数的方式,因为多数都识别出来它是一只猫了。这就是看它的倾向性, 用里面的6个预测值为0.9的数据,上面三个预测值为0.1的就不作为增强后的结果了 。这样网络预测的大方向就是统一的了。

这篇文章的创新点除了active learning之外,它在学习的时候也不是从batch开始,而是sequential learning。它在开始的时候效果就不会特别好,因为完全没有标注数据,它是从一个ImageNet数据库训练出的模型直接拿到medical的应用里来预测,效果应该不会太好。然后随着标注数据的增加,active learning的效果就会慢慢体现出来。这里是在每一次fine-tune的时候,都是在当前的模型基础上的进一步fine-tune,而不是都从原始的pre-train的model做fine-tune,这样就对上一次的模型参数有一点记忆性,是连续的学习。这种思路就跟学术上常见的sequntial learning和online learning是类似的。但是有一个缺点就是,fine-tune的参数不太好控制,有一些超参数,比如learning rate还有一些其它的,其实是需要随着模型的变化而变化的,而且比较容易一开始就掉入local minimal,因为一开始的时候标注数据不是很多,模型有可能学到一个不好的结果。那么这就是一个open的问题,可以从好几个方面去解决,不过解决方法这篇文章中并没有提。

这个方法在机器学习方面是比较通用的,就是找那些难分的数据去做sequntial的fine-tune。这篇论文里主要是用在了医学图像上面,用两个例子实验了结果,一个是结肠镜的视频帧分类,看看有没有病变、瘤之类的。结论是只用了5%的样本就达到了最好的效果,因为其实因为是连续的视频帧,通常都是差不多的,前后的帧都是类似的,不需要每一帧都去标注。另一个例子也是类似的,肺栓塞检测,检测+分类的问题,只用1000个样本就可以做到用2200个随机样本一样的效果。

这个作者我也了解一些,他是在 ASU 的PhD学生,然后现在在梅奥,美国一个非常著名的私立医院梅奥医院做实习,就跟需要做标注的医生打交道比较多。这相当于就是一个从现实需求得出来的一个研究课题。
总结下来,这篇文章有几个比较好的亮点。

我今天分享的大概就是这些内容。其实这里还有一个 更详细的解释 ,最好还是把论文读一遍吧,这样才是最详细的。
Q:为什么开始的时候 active learning 没有比random selection好?
A:其实不一定,有时候是没有办法保证谁好。active learning在一开始的时候是没有标注数据的,相当于这时候它不知道哪些数据是hard的,在这个医学数据集上并没有受到过训练。这时候跟 random selection 就一样了,正在迁移原来 ImageNet 图像的学习效果。random selection 则有可能直接选出来 hard的那些结果,所以有可能比刚开始的active selecting要好一点,但这不是每次都是 random selection 好。就是不能保证到底是哪一个更好。
(完)
雷锋网 AI 科技评论整理。系列后续的论文解读分享也会进行总结整理,不过还是最希望大家参与我们的直播并提出问题。
中山大学金牌队伍分享获奖经验:如何玩转图像比赛
原创文章,未经授权禁止转载。详情见 转载须知 。



刻度时间

万考网目前已为广大考友提供考试知识学习,提供计算机考试、外语考试、资格考试、学历考试、会计考试、工程考试、医学考试类等56种考试的报名时间、考试时间、考试大纲、成绩查询等相关资讯以及历年真题、模拟试题、名师辅导课程等备考资料。

天津宏皓达机电设备有限公司

米保险,最全最专业的保险咨询服务平台,帮助保险人合理规划保险风险,做好保险方案,选择适合被保人的保险产品,以及洞察保险行业最新新闻动态,让投保人掌握更专业的保险知识。

众意好医师是一个为小型医疗机构(个体诊所/小型门诊部/乡村卫生所/卫生服务站)、家庭医生和多点执业医生而建立的,为患者提供在线健康服务,为机构提供企业门户展示,基于众意好医师网站(www.haoyishi.com.cn)而建立的O2O网络信息平台。

音频网(yinpin.com),专业音频制作公司,音频网咨询电话:400-700-9100,为您提供专业音频制作、音频录音、音频制作、音频制作服务,包括广告音频制作、宣传片音频制作、专题片音频制作、解说词音频制作。音频网,专业音频制作。音频,音频网,音频网站,音频制作

江西新余康展高级技工学校是经江西人力资源和社会保障厅批准的,位于江西新余面向全国招生的一所全日制高级技工学校,为江西省重点建设精品专业学校,培养高技术人才,咨询热线:13879190154
有限公司")
福冈工具(沈阳)有限公司,2007年由日本ISポンプ有限会社独资设立的日本独资公司,2021年度分别被授予《科技型中小型企业》和《高新技术企业》。


飞游网是专为游戏玩家们打造的一个安全、快速、绿色专业的下载前沿基地,这里汇集全网各种最前沿最新手机资源和安卓应用app,让你率先在这里尝鲜各种手机游戏、应用app、攻略、资讯、教程等相关内容,给你一站式的游戏网站服务体验。

久益一修是一家全国连锁专业的房屋装潢装修公司,集老房子翻新装修、二手房墙面翻新、旧房局部整体改造、厨房卫生间翻新、房屋室内装修、全屋整装全包半包、墙面刷新刷墙、房屋防水补漏、家庭维修安装等施工服务

北京安图生物工程有限公司成立于2009年,位于北京市顺义区。公司专注于临床生化体外诊断领域,是一家集体外诊断生化产品研发、生产、销售、服务为一体的创新型国家高新科技企业。


手机上休闲的游戏确实比较多,割绳子吃糖果的游戏都有什么,这种类型游戏真的很有趣,玩法简单但挑战性十足,每个人都能在这款游戏中找到自己喜欢的点,玩得开心最重要嘛,毕竟游戏的本意就是给我们带来快乐,放松一下心情,希望大家能找到比较心动的那一款,让游戏变得更加快乐,1、,割绳子玩穿越,对于那些已经熟悉这个系列的老玩家来说,这款新游戏无疑是个...。

非常荣幸,我参加了2024百度云智大会,上周先是云栖大会,这周是云智大会,大家都是吹嘘这两家公司多么牛逼,发布了多少AI大模型,我偏不,就说说别的东西,文章虽短,但都是真情实感,车的核心应该是驾驶和安全吧?昨天参会,我问这个车用的什么AI系统,车企的人不知道,后面有叫来了另一个人,我估计她可能也不知道,因为那个姑娘洋洋洒洒说了一大堆,...。

近日有件事情挂到了微博热搜上,并且让很多的成年人都觉得自己是自愧不如的,事情的经过是安徽的某个公安局接到了报警,是一名小学六年级的学生,他说自己接到了诈骗电话,并条理清晰的复述了整个事件的经过,这位六年级的小同学以缜密的思维逻辑和脑内所存有的防骗意识,让骗子自己挂断了电话,然后这件事情就上了微博热搜,很多成年人都说这是个高手,毕竟自己...。
各位还在跑外卖的朋友们,注意啦!滴滴跑腿服务已经正式上线了!这可是一个不错的机会,赶紧加入吧!

申明,1.以上内容仅代表揭发者自己,不代表黑猫揭发立场,2.未经授权,本平台案例制止任何转载,违者将被清查法律责任,3.黑猫揭发处置揭发不收取任何费用,凡以黑猫揭发名义不要钱的均为混充、诈骗行为,请及时报警并与黑猫官网反应,揭发邮箱heimaotousu@vip.sina.com,4.请大家选用官网渠道处置生产纠纷,不要轻信第三方机构...。
给你讲3个方便的装置模式,1、进入360官方下载装置,网址为,,进入后你可以看到360一切的产品,找到360阅读器下载装置即可,如下图,2、搜查引擎搜查装置,关上网络、谷歌等搜查引擎,输入360阅读器,随意找一个能下载的网站,下载装置即可,如下图,3、电脑管家装置,假设你装置有360安捍卫士或腾讯安捍卫士等电脑管家,关上后,在软件治理...。

宝马318i这款车怎样?1、好处,方向盘很精准,指向很准,刹车挺棒,很有安保感,大鼻子可恶中带点肃穆,2、缺陷,空间有点小,前排座椅后移的话,后排坐起来很挤,3、外观,外观很青睐,特意士前面的猪鼻子,还有车头挺大,觉得很霸气的样子,4、内饰,318没有iDrive,所以很奢侈,然而用料都很真,全体觉得很舒适,5、空间,空间觉得较小,新...。

如何在Laravel中使用中间件处理表单验证,需要具体代码示例引言:在Laravel中,表单验证是非常常见的任务。为了确保用户输入的数据的有效性和安全性,我们通常会对表单提交的数据进行验证。Laravel提供了一个方便的表单验证功能,同时也支持使用中间件来处理表单验证。本文将详细介绍如何在Laravel中使用中间件处理表单验证,并提供具体的代码示例

在艾尔登法环这款游戏中一共有10个地图碎片,不过很多小伙伴们并不清楚其位置,那艾尔登法环地图碎片在哪?本期的新游资讯就为大家详细盘点一下这10个地图碎片的位置,有需要的小伙伴们快来看看吧~艾尔登法环地图碎片位置分享1、揭示Dragonba

尖叫吧小鸡仔,小鸡仔尖叫声惊天动地小鸡仔的尖叫声异常刺耳,让人听了也感到心惊胆战。每当小鸡仔感到惊恐或者生命受到威胁时,它就会发出这种刺耳的叫声,试图引起周围的注意并获得帮助。毫无疑问,小鸡仔的尖叫声是惊天动地的,它能够让任何一个人都感到害怕,更别说是一只小小的鸡仔了。2.拼了命要逃脱小鸡仔的生命受到威胁时,除了发出尖叫声以外,它还会拼了命地想要逃脱。当它感到害怕和危险时,它会毫不犹豫地寻找出路,试图逃脱险境。这时候,小鸡仔展现出来的求生意志和勇气令人钦佩。虽说它的行动力并不强,但在面临生死攸关的危机

2021第十届中国国际大学生微电影盛典作品征集 报送参赛作品截止时间:2021年9月15日 各大专院校在校学生、研究生,以及各影视机构工作人员、独立制作人、国内外视频拍摄爱好

美工常用设计字体打包,这是我们pc6.com下载站美工经常用到的字体,我做了个打包发给大家!字体包括:浪漫雅圆,晴圆,毛笔行书,时尚中黑,广告体,华康少女体,霹雳体等精美字体,您可以免费下载。

火锅店的淡季与旺季,加盟火锅要重视!在重庆,有一种奇怪的现象,不管是暴暑还是寒冬,街头小巷的火锅店生意总是络绎不绝,这是重庆人专属的美味,对重庆火锅行业来说,味道香,价格好,是没有淡旺季之分的!当您掌握了开店的诀窍,一年四季的生意都能如火如荼,如果您正在为选择一家合适的火锅品牌加盟,来重庆准没错,有品牌历史,生意更长红位于重庆渝中区枇...。

当年南下深圳,转战罗湖水贝珠宝圈,转眼间已逾二十载,佛曰,一花一世界,一叶一菩提,从初的加工制造,到后来的国产品牌化之路,水贝珠宝发展历程,一幕一幕,或痛苦、或喜悦、或激动,或振奋,都历历在目,更加让我坚定信念,做一个珠宝寻梦人,改革开放伊始,水贝乃至整个珠宝,由于历史原因,只能以为香港或者国外品牌代工生产、加工制造为发展策略,水贝珠...。

6月28日,腾讯云副总裁李力在A2M人工智能创新峰会上宣布,腾讯云推出基于公有云的成熟实践的专有云智算套件,该套件集合了腾讯云高性能计算集群构建模块、智能高性能网络IHN、高并发文件存储系统TurboFS、算力加速框架Taco以及GPU算力共享技术等核心能力,与腾讯云专有云平台TCE结合,能够支撑企业基于自有硬件搭建高性能的专有智算云...。

ATEC2022比赛背景科技促进产业数字化,是数字时代经济发展的重要命题,本届ATEC科技精英赛,通过考察选手对图学习、隐私计算、多模态识别、智能推荐等核心技术的掌握能力,解决营销数字化、产品数字化、融资数字化三大现实问题,帮助企业抵御安全风险、提升数字化运营能力,帮助从一个全新的数据维度来实现农作物的数字化,借助数字化技术提高农村金...。

发表在米家投影仪2022,7,816,14小米激光投影仪1S是近日上市的新品激光投影设备,具体这款投影仪的详细配置如何呢,下面就通过参数配置分析可以发现,看看小米激光投影仪1S的质量究竟怎么样,小米激光投影仪1S怎么样,1.光学参数小米激光投影仪1S采用的是ALPD激光光源,拥有不错的画质表现,同时亮度也相当高,实际亮度达到了2400...。
