Trainium芯片 亚马逊自研3nm 能否成为英伟达之外的第二选择 (training)
Trainium是亚马逊云科技(AWS)专门为超过1000亿个参数模型的深度学习训练打造的机器学习芯片。在2024年 re:Invent大会上,AWS宣布Trainium2正式可用,其性能比第一代产品提升4倍,可以在极短的时间内训练基础模型和大语言模型。
AWS周二宣布,将推出一款由数十万颗自研Trainium芯片组成的巨型人工智能超级计算机,这是其位于德克萨斯州奥斯汀的人工智能芯片设计实验室的最新成果。
该芯片集群将供由人工智能初创公司Anthropic使用,Anthropic是一家人工智能初创公司,近期获得来自亚马逊40亿美元的投资。AWS负责计算和网络服务的副总裁戴夫.布朗(Dave Brown)表示,这个名为 “Project Rainier ”的芯片集群将落地美国,2025年建成后将成为世界上最大的人工智能模型训练集群之一。
在拉斯维加斯举行的年度re:Invent会议上,AWS发布了“Ultraserver”服务器,该服务器由64个自研的互联芯片组成。此外,AWS还在会议上宣布苹果成为其最新的芯片客户之一。
re:Invent会议上发布的产品凸显了AWS此前对自研芯片Trainium的承诺,其将Trainium视为替代英伟达GPU的备选选项。
根据研究机构国际数据公司(IDC)的数据显示,2024年人工智能芯片市场的规模估计为1175亿美元,到2027年底预计将达到1933亿美元。IDC去年12月的研究显示,英伟达在人工智能芯片市场中占据了约95%的份额。
AWS的CEO马特.加曼(Matt Garman)称:“目前,GPU市场只存在一种选择,就是英伟达,如果市场上有其他的选择,我们相信客户会很欢迎。”
而亚马逊推动AI战略的关键举措是更新其芯片,这样可以为他们的客户降低成本,同时在产业链内掌握更多的主动权。掌握更多的主动权有利于亚马逊减少对英伟达的依赖,尽管目前两家公司的关系还非常亲密。
觊觎英伟达芯片收入的公司并不在少数,包括人工智能芯片初创企业Groq、Cerebras Systems和SambaNova Systems。亚马逊的竞争对手微软和谷歌也下场开发自己的人工智能芯片,并试图减少对英伟达的依赖。
自从2018年推出基于Arm架构的CPU Graviton以来,亚马逊一直致力于为客户开发自研的芯片产品。亚马逊高管表示,公司的目标是复制Graviton的成功经验,向客户证明,其产品虽然成本更低,但性能并不逊色于市场领先者。
亚马逊造芯,复刻Graviton的成功经验
AWS的人工智能芯片实验室位于德克萨斯州奥斯汀市,其前身是亚马逊在2015年以约3.5亿美元收购的以色列微电子公司Annapurna labs。
加迪·哈特(Gadi Hutt)在亚马逊收购Annapurna之前就加入了该公司,担任产品与客户工程部的总监。他表示:“芯片实验室自Annapurna创业之初就已设立,当时Annapurna安家于奥斯汀的考量正是希望所处的位置要靠近芯片巨头设有办事处的地方。”
该实验室工程部主任拉米·辛诺(Rami Sinno)说,在实验室内部,工程师们可能今天还在装配线上工作,明天就去焊接了。他们会立即着手处理任何需要完成的工作,这种精明务实的心态在初创企业中更为常见,而非像亚马逊这样的万亿美元公司。

辛诺称,这是有意为之的,因为Annapurna对于人才招聘有自己的理解,并不像行业中的其他公司那样寻找专长于一个领域的“专家”。他们会寻找既精通版图设计又精通信号完整性和功率传输,并且还能编写代码的电路板设计师。
“我们同时设计芯片、核心、整台服务器和机架。我们不会等到芯片准备好后再设计主板,”辛诺说。“这让团队能够以超快的速度前进。”
AWS在2018年推出了Inferentia,这是一种专门用于推理的机器学习芯片,即将数据输入AI模型以生成输出的过程。亚马逊高级副总裁兼杰出工程师詹姆斯·汉密尔顿(James Hamilton)表示,团队首先专注于推理,因为与训练相比,推理任务对芯片的要求略低。
到2020年,Annapurna已经准备好推出其首款面向客户用于训练AI模型的芯片“Trainium”。去年,亚马逊宣布推出Trainium2芯片,称该芯片现已可供客户使用。AWS还表示,目前正在开发Trainium3芯片以及基于该芯片的服务器,其性能将是基于Trainium2芯片服务器的四倍。
规模决定算力,亚马逊服务器搭载芯片数量为英伟达两倍
随着AI模型和数据集的规模越来越大,为其提供动力的芯片和芯片集群的规模也在不断扩大。科技巨头们不仅从英伟达购买更多的芯片,还自行设计芯片。如今,他们正试图将尽可能多的芯片集中在一个地方。
“越来越大”也是亚马逊芯片集群的目标,该集群由Annapurna和Anthropic合作构建,目的是让AI初创公司使用该集群来训练和运行其未来的AI模型。亚马逊表示,该集群的浮点运算能力是Anthropic当前训练集群的五倍。马斯克的xAI最近建造了一台名为Colossus的超级计算机,该计算机使用了10万个英伟达的Hopper芯片。
汉密尔顿说:“你将服务器的规模扩大得越多,就意味着你需要解决的问题越少,整个训练集群的效率也就越高。一旦你意识到这一点,更大更强就成了目标。”
亚马逊的Ultraserver将64个芯片整合到一个封装中,由四台服务器组成,每台服务器包含16个Tranium芯片。布朗说,相比之下,英伟达的部分GPU服务器只包含8个芯片。为了将这些芯片组合在一起,形成一个可以达到83.2千万亿次浮点运算的服务器,亚马逊的秘密武器是其网络技术NeuronLink,这项技术可以使所有四个服务器相互通信。
汉密尔顿称,这是他们在不使服务器过热的情况下所能容纳的最大数量。从尺寸上看,它更接近于冰箱大小,而不是紧凑的个人计算机。但布朗和其他高管表示,这并不是在向客户施压,让他们从亚马逊和英伟达之间二选一。他们更希望客户可以在其云平台上继续使用自己喜欢的产品。
AI编程初创公司Poolside的联合创始人兼CTO艾索.康德(Eiso Kant)表示,他们公司在使用Amazon的芯片运行其AI模型时,相较于使用英伟达的芯片,可节省约40%的成本。但缺点是,工程师需要花费更多的时间让亚马逊的相关芯片软件正常运行。
康德表示:“亚马逊直接通过台积电制造芯片,并将其应用于自己的数据中心,因此对AI初创企业来说,这是看起来更“稳妥的选择”。他表示,亚马逊的赌注下在哪里至关重要,因为在硬件领域,落后对手6个月就可能意味着业务的终结。”
苹果机器学习与人工智能高级总监贝诺伊·杜平(Benoit Dupin)在大会上表示,苹果内部正在测试Trainium2芯片,预计可节省约50%的成本。
分析师表示,对于大多数企业来说,选择英伟达还是亚马逊并不是一个迫切的问题。因为大型企业更关心如何从运行AI模型中获得价值,而不是研究如何训练它们。
这样的市场趋势对亚马逊来说是件好事,因为客户不会注意到云服务背后是哪家芯片厂商在提供算力。它可以与Databricks这样的云数据公司合作,将Trainium应用于云计算,大多数企业都不会注意到任何差异,因为计算能够正常运行,而且成本还会越来越低。
市场研究和IT咨询公司Gartner的分析师奇拉格.德卡特(Chirag Dekate)表示,亚马逊、谷歌和微软正在开发自己的AI芯片,因为他们知道自行设计芯片可以节省时间和成本,同时提高性能。因为定制硬件可以提供非常具体的并行化功能,这可能比通用型GPU的性能更好。
研究公司Redburn Atlantic的分析师亚历克斯·海斯尔(Alex Haissl)表示,AWS在人工智能不太被关注到的领域也有着被低估的实力,包括网络、加速器和名为“Bedrock”供企业使用人工智能模型的平台。
不过,公司领导对于AWS的芯片能够走多远持怀疑态度,至少目前是这样。AWS CEO加曼说:“实际上,我估计在很长一段时间内,市场还是会被英伟达占据,因为目前99%的工作负载都是由它们来处理的,这种情况可能不会改变。但是,我希望Trainium能够开辟出一个不错的利基市场,它将会是很多工作负载的绝佳选择。
本文由编译自:Exclusive | Amazon Announces Supercomputer, New Server Powered by Homegrown AI Chips - WSJ
原创文章,未经授权禁止转载。详情见 转载须知 。


提供软件下载的站点,每天更新大量软件及技术文章,PC6官方下载全力打造软件下载门户网站。

徐州市水利工程建设有限公司前身是徐州市水利工程建设局,创建于1959年7月,现为国家“水利水电工程施工总承包壹级”施工资质企业,同时具有港口与航道工程、公路工程、市政公用工程、房屋建筑工程、土石方工程等总承包和专业资质。

DNA图谱人类基因交流社区!

海南省建设项目规划设计研究院有限公司

工程咨询有关政策信息查询

小小漫迷

安徽新天地塑业有限公司专业生产:婴幼儿奶粉盖、奶粉勺、液态奶杯、奶制品饮料包装、湿巾纸包装、PET管胚、医疗塑料件、一次性快消品塑料包装、阻燃电工电气、调味品塑料盖等包装制品,热线:0556-677027215955569909

氟务在线立足氟化工行业,定期收集、整理、分享行业市场资讯动态。为企业、机构提供专业性、全面的媒体推广营销方案。由行业资深分析团队精心打造,着眼行业发展,牢牢立足“以内容和服务赢得信赖”的发展理念,秉承“开放、务实专业”的企业原则,探索产业传媒业务发展新思路,力争打造成了解最新行业动态,搜索最新供应商及技术服务的首选平台。

河南省高职高专院校高考、单招以及对口高考招生报名咨询服务平台,是最权威的河南省高等职业技术学院以及河南省高等专科院校在线单招以及对口高考招生咨询服务平台!提供了几百家有对口高考和对口单招的河南省公办和民办高职高专以及本科院校,并且有二百多个热门专业任您选择!

超多新开传奇私服发布网,这里有超多新开传奇私服发布网,每日更新,总有一款适合你!最新最全的传奇SF推荐,让你轻松找到心仪的传奇服,开启你的传奇之旅!

电子技术应用网,为电子工程师提供电子行业最新最全的电子设计资源,最活跃的设计技术交流社区,电子元器件和开发工具的网上交易服务,《电子技术应用》杂志官方唯一投稿网站。

澄拾将不断分享自己的游戏心得和经验,希望这种互动交流能够提升个人及玩家们的游戏技巧,还能够增加游戏的乐趣。


神庙逃亡魔境仙踪这个游戏是基于电影故事情节是改编的逃亡游戏,今天小编给大家带来神庙逃亡魔境仙踪正版下载2022,来帮助更多人了解这款游戏体验畅快的冒险逃离体验,神庙逃亡魔境仙踪OZ2022最新下载地址游戏特点这款软件上有很多丰富的电影元素情节,比如说食人花、大气球等好看的电影情节片段素材,可以让我们的游戏更加有代入感体验感十足,玩法介...。
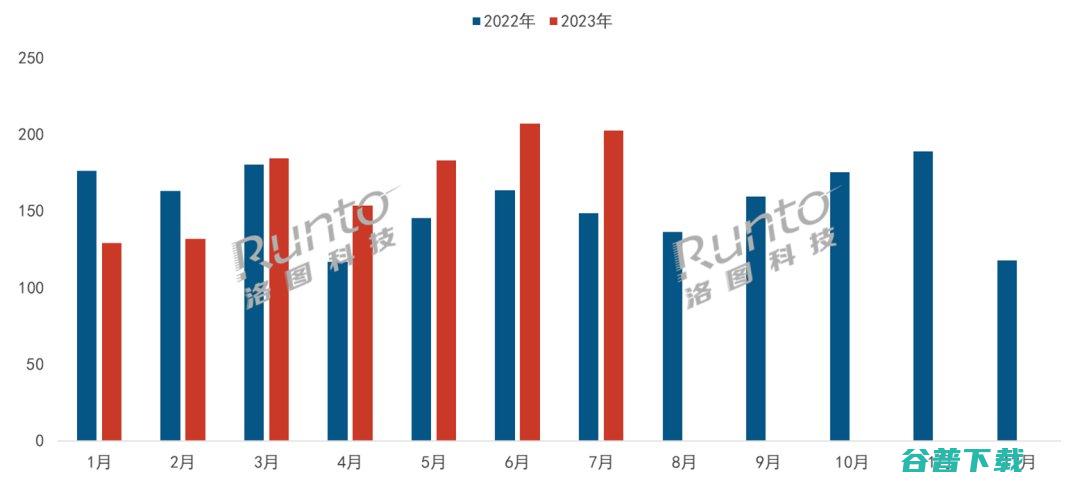
根据洛图科技,RUNTO,中国监控摄像头线上零售市场月度追踪,ChinaSecurityCameraOnlineRetailMarketMonthlyTracker,报告,2023年7月,中国监控摄像头线上市场销量为203万台,同比增长36.5%,环比下降2.2%;销额为4.6亿元,同比增长41.1%,环比下降0.2%;线上市场均...。

腾讯两位神秘高管去年薪酬近26亿人民币,不在董事或最高阶管理层行列4月21日云头条消息,腾讯在2021年向两位未对外透露具体身份的高管每人发放了超过2亿美元,约合12.74亿人民币,该公司在年度报告中表示,其薪酬最高的两个人不在董事或大多数高级管理人员之列,其中一人约为15.99亿港元,另一个人约为15.89亿港元——分别相当于2....。
你眼中的赚钱常识,也许连狗屎都不如,靠常规项目赚钱,已经越来越不吃香,上次探究了试图通过改变成年人的思维来赚钱,比登天还难,我们要做的,是降低赚钱沟通成本,只筛选合适的精准人群,同频人群,认可人群,从而快速收钱,只筛选,不教育,因为成年人,无法被教育,只能被天启,一、捞女上周与一个副业同行聊天,向我大吐苦水,副业说,原先直播卖知识付费...。

国内净水器的发展速度惊人,每年净水器的市场增长率是,市场规模都是上千亿级别的,而且国内的净水器在目前来看,普及率并不是很高,故而净水器市场前景广阔,这大概也是越来越多人开始投身到净水器市场里的主要原因,但是,净水器的品牌这么多,对于想要加盟净水器的代理商来说如何选择一家好的净水器品牌的确是个难题,那么,净水器加盟代理要注意哪些下面就由...。

文字链接认证代码普通联盟标志认证代码企业广告联盟标志认证代码广告联盟评测代码说明,本页面的认证代码为互易网络传媒专用评测代码,站长需懂简单html知识,直接复制代码粘贴到联盟网站相应页面即可使用,本代码不适用于其他广告联盟网站请勿获取!文字认证,文字链接代码认证适用所有类型的广告联盟,复制代码后放在互易网络传媒网站首页底部或友情链接位...。


自己于24年4月经过网络平台了解到超盟,广州,文明传媒有限公司的AI图文带货课程,他们宣传课程便捷易学,10天能赚回学费,赚不回退费,诱导我缴费,交钱后与之前承诺不分歧,放开退款对方不时不予理会,需要平台帮助我退费...。

太阳星座,狮子座,星座特点,自豪森严,生日范畴,7月23日,8月22日,四象属性,火,主持宫位,第五宫,阴阳属性,阳性,最大特征,权势,主管行星,太阳,幸运色彩,白色、金色、黄色,如意饰物,琥珀,幸运号码,19,开运金属,黄金,体现,王者、自信、小气好处,指导力强,很有主意,执行力十足,缺陷,自傲,专断,火暴,愿望剧烈,基本特质,太阳...。

杀毒软件十大排名,1.微软Defender2.诺顿杀毒软件3.麦克菲尔杀毒软件4.小红伞杀毒软件5.趋向科技防毒软件6.360杀毒7.腾讯电脑管家8.瑞星杀毒软件9.Avira杀毒软件10.Bitdefender杀毒软件杀毒软件的选用关于包全计算机免受恶意软件、病毒、木马等要挟至关关键,在选用杀毒软件时,用户须要思考多个起因,包含软件...。

凯美瑞凯美瑞是广汽丰田旗下的一款车型,37年来,历代凯美瑞都继续上游,赢得环球2000万车主的信任,2023年10月至2024年1月,凯美瑞在中国的月...现在买一台二手2012款的凯美瑞2.5G的,要12.5万,贵还是不贵占师傅帮看车解答,你说的是2.5的2012款豪华版吗,这要看是哪一年上牌的,如果是12年上牌的价格应该在11万左...。

是2021款高尔夫gti是智能挡,高尔夫GTI整车尺寸为4255×1799×1452mm,标配17寸轻量化铝合金,战斧,式轮毂,尾部驳回了双排气管设计,相关于2020款将手动挡改为了智能挡,第八代高尔夫gti将会经常使用第四代ea888的20升涡轮增压发起机,这款发起机可以输入245马力和370牛米的最大扭矩在如此弱小的能源加持下,第...。

农场主题的经营游戏早在十多年前智能机时代就存在不少,农场经营类的作品耐玩性极强还有着非常温馨治愈的森系背景,那么十年前的农场游戏下载排行情况怎么样,接下来小编介绍的农场经营手游都有着极高的辨识度,颇具年代感的经典经营玩法让许多农场手游爱好者痴迷,1、,模拟,在这款农场经营作品中大家可以跟常见的农村动物一起经营农场,满屏幕的可爱牲畜都可...。

最近松松编辑杰哥从外贸电商圈一位大佬处了解到,近几个月亚马逊电商一直在大整改,官方重拳出手,很多行业大店被封,国内搞店的大佬要小心了,根据大佬透露杰哥了解到,亚马逊这波针对行业大店严厉大封杀最直接的原因,其实就是上次那波亚马逊数据泄露问题,因为数据泄露,直接曝光了亚马逊部分大店在内的店铺1300万条付费刷单交易和虚假评论记录,20多万...。

女子遇股神日赚一万后赔115万诈骗团伙半年洗钱2个亿,6月,镇江沈女士在微信群遇到一股神,买对方推荐的股票日赚一万,然而被推荐安装一股票软件,并转入115万后,沈女士遭拉黑,警方发现资金被转入一皮包公司,半年流水达2个亿,该团伙主要成员都在国外,目前1人被刑拘,5人被列为网逃,大兴公安的微博视频来源,松松科技QQ,微信,lusong...。
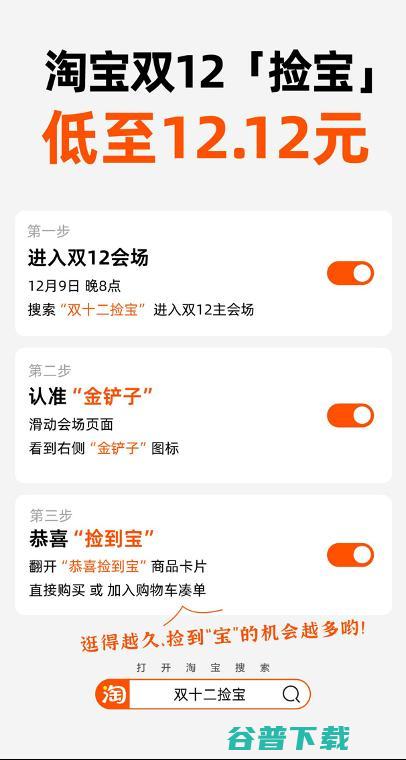
从12月9日晚8点到12月12日24点,淘宝双12狂欢节正式开启!跟往年双12不同,今年的双12在玩法上有很多创新,除了优惠券以外,主要玩法为,捡宝,,整个会场就是个互动游戏场,用户通过逛淘宝发现金铲子标志,就可以捡到低至一折的宝贝,这次的捡宝行动不光有一到五折的iphone手机、戴森吹风机等硬通货,还有很多的,大宝,,名字中带,宝,...。
12月28日,三六零,601360.SH,下称,360,发布对外投资进展公告,已与哪吒汽车各股东方签署有关协议,以支持哪吒汽车股份制改造,公告披露,哪吒汽车的股改基准日为2022年10月31日,股份公司预计于2022年12月31日完成设立,此前360发布公告称,为优化标的公司股权结构,完善哪吒汽车治理机制,决定将哪吒汽车部分增资权平...。
