清华团队再获突破!研制出全球首款多阵列忆阻器存算一体系统 能效比GPU高两个数量级 (清华团队再获金牌)
有很多童鞋可能不知道忆阻器是什么?在开始今天的话题之前,雷锋网编辑先为大家普及下忆阻器是什么。
所谓忆阻器,全称记忆电阻器(Memristor),是继电阻、电容、电感之后的第四种电路基本元件,表示磁通与电荷之间的关系,这种组件的的电阻会随着通过的电流量而改变,而且就算电流停止了,它的电阻仍然会停留在之前的值,直到接受到反向的电流它才会被推回去,等于说能“记住”之前的电流量。
简言之,忆阻器(memristor)可以在断电之后,仍能“记忆”通过的电荷,其所具备的这种特性与神经突触之间的相似性,使其具备获得自主学习功能的潜力。因此,基于忆阻器的神经形态计算系统能为神经网络训练提供快速节能的方法,但是,图像识别模型之一 的卷积神经网络还没有利用忆阻器交叉阵列的完全硬件实现。
不过,最近雷锋网了解到,清华大学微电子所、未来芯片技术高精尖创新中心钱鹤、吴华强教授团队与合作者在《自然》在线发表了题为“ Fully hardware-implemented memristor convolutional neural network ”的研究论文,报道了基于忆阻器阵列芯片卷积网络的完整硬件实现。
他们提出用高能效比、高性能的均匀忆阻器交叉阵列实现 CNN,该实现共集成了 8个 PE ,每个 PE 包含2048 个单元的忆阻器阵列,以提升并行计算效率。此外,研究者还提出了一种高效的混合训练方法,以适应设备缺陷,改进整个系统的性能。研究者构建了基于忆阻器的五层 CNN 来执行 MNIST 图像识别任务,识别准确率超过 96%。

除了使用不同卷积核对共享输入执行并行卷积外,忆阻器阵列还复制了多个相同卷积核,以并行处理不同的输入。相较于当前最优的图形处理器(GPU),基于忆阻器的 CNN 神经形态系统的能效要高出一个数量级,且实验证明该系统可扩展至大型网络,如残差神经网络。该结果或可促进针对深度神经网络和边缘计算提供基于忆阻器的非冯诺伊曼(non-von Neumann)硬件解决方案,在处理卷积神经网络(CNN)时的能效比图形处理器芯片(GPU)高两个数量级,大幅提升了计算设备的算力,成功实现了以更小的功耗和更低的硬件成本完成复杂的计算。
首个完全基于忆阻器的 CNN 硬件实现
据介绍,当前国际上的忆阻器研究还停留在简单网络结构的验证,或者基于少量器件数据进行的仿真。基于忆阻器阵列的完整硬件实现仍然有很多挑战。
比如,器件方面,需要制备高一致、可靠的阵列;系统方面,忆阻器因工作原理而存在固有缺陷(如器件间波动、器件电导卡滞、电导状态漂移等),会导致计算准确率降低;架构方面,忆阻器阵列实现卷积功能需要以串行滑动的方式连续采样、计算多个输入块,无法匹配全连接结构的计算效率。
在这些研究成果的基础之上,钱鹤、吴华强团队逐渐优化材料和器件结构,制备出了高性能的忆阻器阵列。
在器件方面,该研究成功实现了一个完整的五层 mCNN,用于执行 MNIST 手写数字图像识别任务。优化后的材料堆栈(material stack)能够在 2048 个单晶体管单忆阻器(one-transistor–one-memristor,1T1R)阵列中实现可靠且均匀的模拟开关行为。使用该研究提出的混合训练机制后,实验在整个测试集上的识别准确率达到了 96.19%。
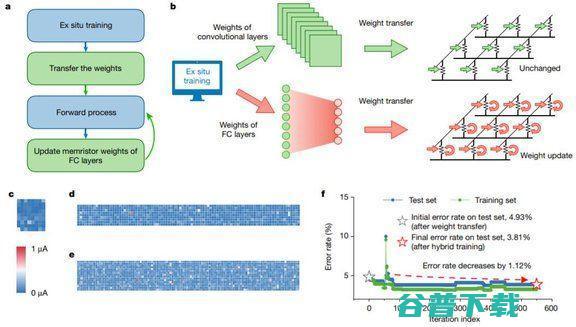
利用混合训练方法得到 mCNN
此外,该研究在三个并行忆阻器卷积器中复制了卷积核,从而将 mCNN 的延迟降低约 2/3。该研究得到的高度集成神经形态系统弥补了基于忆阻器的卷积运算和全连接 VMM 之间的吞吐量差距,从而为大幅提升 CNN 效率提供了可行的解决方案。
架构方面,之前基于忆阻器的 demo 依赖于单一阵列,其主要原因是生成高度可重复的阵列面临巨大挑战。忆阻器设备的易变性和不完美特性被认为是神经形态计算应用的主要瓶颈。该研究提出了一种基于忆阻器的灵活计算架构,适用于神经网络。
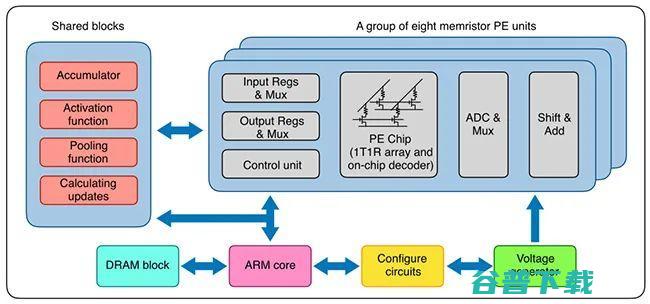
忆阻器单元使用 TiN/TaO_x/HfO_x/TiN 的材料堆叠,通过调节电场和热,在增强(SET)和抑制(RESET)这两种情况下均展现出连续电导率调节能力。材料和制造流程与传统的 CMOS 流程兼容,从而使忆阻器阵列可以方便地内置在晶圆的后段制程中,以减少流程变动,实现高复现性。得到的交叉阵列在同等的编程条件下具备均匀的模拟开关行为。因此,多忆阻器阵列硬件系统基于自定义印刷电路板(PCB)和 FPGA 评估板(ZC706, Xilinx)构建。
系统方面,该系统主要包含八个基于忆阻器的处理元件(PE)。每个 PE 集成了 2048 个单元的忆阻器阵列。每个忆阻器与晶体管的漏级端相连,即 1T1R 配置。核心 PCB 子系统具备八个忆阻器阵列芯片,每个忆阻器阵列具备 128 × 16 个 1T1R 单元。在水平方向上共有 128 条并行字线和 128 条源线,在垂直方向上共有 16 条位线。

基于忆阻器的硬件系统具备可靠的多级电导率状态
该阵列展示了极具可重复性的多级电导率状态,成功证明了存算一体架构全硬件实现的可行性。
有何优势?
众所周知,CNN 是最重要的深度神经网络之一,在图像处理相关任务中发挥关键作用,如图像识别、图像分割和目标检测。
CNN 的典型计算步骤需要大量滑动卷积操作。从这个方面来看,CNN 需要支持并行乘积累加运算(MAC)的计算单元。而这需要重新设计传统的计算系统,以便以更高的性能、更低的能耗来运行 CNN,这些计算系统包括通用应用平台(如 GPU)、应用特定的加速器等。
但是,计算效率的进一步提升最终受限于系统的冯诺伊曼架构,该架构中的内存和处理单元是物理分离的,从而导致大量能耗,以及不同单元之间数据搬运的高延迟。
与之相反,基于忆阻器的神经形态计算可以提供非冯诺伊曼计算范式,即存储数据,从而消除数据迁移的消耗。忆阻器阵列直接使用欧姆定律进行加法运算,使用基尔霍夫定律(Kirchhoffs law)进行乘法运算,因而能够实现并行存内(in-memory)MAC 运算,从而模拟存内计算(in-memory computing),并实现速度和能效的大幅提升,减小误差。
雷锋网编译自 Nature:Fully hardware-implemented mermrist or convolutional netural network
原创文章,未经授权禁止转载。详情见 转载须知 。


在“互联网+教育精准扶贫”的背景下,慕华成志联合友成基金会发起乡村教育创新计划,联合清华控股成员企业与南涧县共同打造教育公益平台“慕华-南涧互联网学校”,联合更多企业扶贫助学等,全面推动优质教育资源的广泛共享,实现全国范围内教育教学质量的有效提升。

是高品质的以APP、网站为核心的软件方案设计及开发公司,追求极致,承诺按时交付,为国内外企业定制UI交互设计、iOS开发、安卓开发、H5开发、web开发,微信端开发等。成功案例涉及有物联网、电商平台、O2O、在线教育、医疗行业、金融行业、OA系统等

网咖装修选新迈途|13年|专注网咖商业模式研究+4大核心设计+精益施工,为您提供系统网咖解决方案,提高网吧30%上座率!网咖装修多少钱?咨询:400-870-8150

消防设备工程

泰安市安泰弯管有限公司是一家专业金属弯卷成型企业,专门从事金属材料的中频煨弯、机械模弯、型材拉弯。主营产品有中频弯管、型材拉弯、换热盘管、弯头、焊接钢构件等。电话:13355381966

极致科技专注于物业管理信息化19年,专注于物业数字化和智慧社区业务的国家高新技术企业,拥有140项软件著作权和专利,携手60多家物业百强,服务2000多家物管企业,超过25000个物业项目。提供物业管理系统、移动办公APP、极致云、智慧停车系统、园区和社区等综合解决方案,覆盖住宅、智慧园区、写字楼、商业和后勤,智能门禁、物联网全面提升物业服务品质,构建智慧社区美好生活。

深圳忠迅国际物流为客户提供国际物流运输、国际快递服务、电池快递、亚马逊物流、FBA头程等国际货运代理服务,已开通美国专线、欧洲专线、欧洲卡航和中港快递等业务.

埃享制造互联平台是埃夫特专为中小家具企业研发的家具管理软件,帮助企业在客户管理、供应商管理、仓库、物料、生产、排期提供一体化的系统解决方案,埃享制造以SAAS账号租赁的形式为企业降低运营成本和提升工作效率。

兔巴士应用提供手机游戏推广,手游排行榜,最新手机游戏第一手发布资料,兔巴士提供最安全的手机游戏免费下载,最新手机游戏排行,手机游戏应用怎么推广?当然选择兔巴士。

南京网站、小程序、公众号建设领跑者,高端网站制作品牌服务商,12年专注高端网站建设、手机移动网站建设、微网站制作,服务器运维,为企业客户的互联网应用提供一站式服务解决方案.

东莞亚群科技是一家专业从事营销型网站建设和H5响应式网站制作的全国性网站开发公司,我们最大优势就是把SEO优化技术融入到网站建设中,让网站更容易获得比较好的百度排名。东莞建站公司电话076927192000

深圳市前海百富源股权投资管理有限公司为百富源集团旗下的投资管理公司之一,注册资本为1000万元。主营业务为:股权投资管理、投资管理顾问及咨询相关服务。


很多人在想的时候应该都梦想自己能成为一名裁缝,这样就可以随意的设计喜欢的衣服样式,还能根据自己的身材制作各种各样漂亮的小裙子,那可以一起看一下自由剪衣服的游戏推荐,可以在游戏中先成为一名小裁缝,在这里各种灵感都能轻松的实现,想要体验自由裁剪衣服的玩家可以看一下下面这几个游戏,绝对都能满足裁剪和设计的需求,在森林中玩家会开设一些裁缝店,...。

现在女性对自己的健康要求都很高,特别是孕产妇更是大家关注的对象,很多创业者也能根据这一类人群的需求开展各种服务项目,昕孕瑜伽就能满足很多消费者的需求,给大家提供各种课程体验和选择,昕孕瑜伽加盟怎么样,如何开店,这也是创业者比较关注的问题,昕孕瑜伽专注于孕妇产妇健康已经有20多年时间,服务顾客数量突破上百万,公司有自己的线上课程平台,采...。

11月15日,,全球AI,智适应教育峰会,在北京嘉里中心大酒店盛大开幕,峰会由雷锋网联合乂学教育松鼠AI,以及IEEE,美国电气电子工程师学会,教育工程和自适应教育标准工作组共同举办,汇聚国内外顶尖阵容,AI智适应学习是目前产学研三界关注度最高的话题之一,此次峰会,主办方邀请了美国三院院士、机器学习泰斗MichaelJordan,全球...。

天猫魔屏A1c民间测评,购买前看了很多同价位的对比做了很多功课最后决定选择了这款真的没有让我失望清晰度白天拉一半窗帘的效果,画面还不错,晚上的忘记照相真的很满意这个清晰度我和妈妈一个劲夸奖哈哈,聚焦聚焦问题是我买之前最担心的问题我看有人说A1c要不停的聚焦很担忧做好了如果不行就退货的打算到实际使用中真的无需调节只要一开始调好了就会一直...。

发表在坚果投影仪2023,8,113,06坚果N1Air是最近上市的投影仪,价格仅三千元,那么和价格相近的当贝D5X对比有什么区别呢,下面就通过详细的参数配置进行对比分析,看看坚果N1Air和当贝D5X哪款好,看看两款投影仪区别有哪些,一、坚果N1Air和当贝D5X区别,1.光学参数对比坚果N1Air和当贝D5X的标准分辨率都达到了1...。

歼,歼,英文名,J,,是由中国航空工业团体沈阳飞机设计钻研所研制、中国航空工业团体沈阳飞机工业,团体,有限公司消费的新一代隐...中国国内航空航天博览会中国国内航空航天博览会,简称中国,珠海,航展或珠海航展,由中央政府同意举行,是国内性专业航空航天展览,以实物展现、贸易洽谈、学术......。

[全球网报道记者姜蔼玲]据多家外媒此前报道,外地期间11日在华盛顿举办的北约峰会上,美国总统拜登误把乌克兰总统泽连斯基叫成,普京总统,据路透社外地期间13日报道,泽连斯基今日对这一事情做出回应,路透社称,泽连斯基13日在爱尔兰接受记者采访时回应称,,这是一个错误,但,我以为美国给了乌克兰很多允许,咱们可以遗记一些错误,我是这么以为...。

曾经惊动全国的玛莎拉蒂撞宝马案终于有了却果,这起交通意外的结果十分严重,而且形成了多人受伤两人死亡,给社会形成了十分顽劣的影响,这起意外当中的几位人员背景都不便捷,意外出现之后,谭明明作为主犯,遭到了更多的关注,而她的身份背景也被大家扒得一干二净,随后就连他的两位同伙身份也被网友扒进去,咱们一同来看看他们究竟是有着怎样样的背景,玛莎拉...。

成都作为四川省的省会城市,领有许多大型超市供市民和游客选用,以下是一些货品完全、值得一逛的大型超市,沃尔玛,Walmart,沃尔玛是世界最大的批发连锁企业之一,在成都有多个分店,以种类丰盛、多少钱正当著称,从日常生存用品到食品、服装、电子产品等简直包罗万象,沃尔玛还提供线上购物和线下取货的服务,十分便利,家乐福,Carrefour,...。

下载地址,类型,安卓游戏,破解游戏版本,91y游戏核心大厅v7.3.0大小,52.00M言语,中文平台,安卓APK介绍星级,评分,★★★★★游戏标签,91y游戏核心91y91y游戏核心官方手机版app是91y游戏大厅的手机客户端,一款十分不错的手机棋牌游戏平台,软件收录了海量的手机棋牌游戏和休闲游戏,如,斗地主、血战麻将、双扣、捕鱼...。

达尔优EM902鼠标驱动,嗜血狂分为黑色和电竞版,黑色版表面搭配着规则不一的线条与圆点,尤其星空闪亮;电竞版采用了经典的红蓝双色组合图形设计,通过灯光的搭配,让鼠标质感更进一步。产品特色稳定的游戏光学引擎采用了性能稳定的A3050游戏光学引擎,刷新率高达6600帧/秒,全速USB接口,报告率高达1000HZ,缩短报告响应时间加快至1ms。DPI自由切换分辨率高达4000dpi,通

EV录屏电脑版是一款不收费、不限时的高性能电脑录屏软件。它与目前市面上类似视频录制直播软件最大的不同点在于其完全免费,无广告界面

斗罗大陆2电视剧演员表阵容官宣,周翊然饰演唐三,张予曦饰演小舞,陈牧驰饰演戴沐白,孔雪儿饰演朱竹清,许佳琪饰演胡列娜,斗罗大陆2剧情,全大陆高级魂师学院精英赛决赛后,唐三与小伙伴们依依惜别,他们约定五年后再聚首,随即分头踏上各自的人生道路,之后,唐三跟随父亲唐昊来到隐秘山谷特训,精进能力,在唐昊帮助下,唐三在增强经验的同时愈发沉稳,能...。

少人则安,无人则安,,并不是某些自动驾驶企业的自嗨,自动驾驶发展至今,一路上受到过不少非议,甚至被认为是在,革司机的命,然而,这一观点在远离城市喧嚣的矿山中似乎站不住脚——在那里,司机更像是一种劳动力短缺的高危职业,工作性质使然,不少司机两三年就会得尘肺病、胃下垂、腰间盘突出等职业病;矿山中道路往往不规则、狭长且陡坡多,加之矿卡体...。

消息,8月24日下午,在第五届中国芯应用创新技术研讨会上,由飞腾公司与萤火工厂联合开发的开源硬件产品——飞腾派正式发布,这是首款基于飞腾定制芯片的国产开源硬件产品,并采用飞腾自主设计的定制款嵌入式CPU,产品售价599元起,目前已经可以在ICEsay和天猫商城上购买,最初有一批树莓派的粉丝进入飞腾,说我们要做派,我们当时不理解...。

在人传统的生活习惯中,早起吃个包子油条喝碗豆浆是件再惬意不过的事情了,不过,各家制作包子的技艺参差不齐,要想品尝到正规味道的话,一些品牌您不得不知晓,比如庆丰包子,庆丰包子是一个有着六十余年历史的品牌,起源于,万兴居,,因此至今仍有人铭记,庆丰包子在发展中融会了现代化运营理念,开放了特许经营模式,那么,怎样加盟庆丰包子铺,加盟的人多吗...。

早晨洗净等这种遗传性精气病,早期脑梗的病人,一天不喂屎就浮现出渴屎症,早上预备好的热屎都放凉了,但也得喂他多吃点,万一到了周六日只喝屎水,没屎吃会饿晕,下周一就来不了,...。
