评测 英伟达Tesla 谷歌TPU二代来了 V100尚能战否 (英伟达口碑)

以下为 RiseML 对谷歌 TPUv2 和英伟达 Tesla V100 的对比评测,雷锋网AI 科技评论将其内容编译如下。
谷歌在 2017 年为加速深度学习开发了一款的定制芯片,张量处理单元 v2 (TPUv2)。TPUv2 是谷歌在 2016 年首次公开的深度学习加速云端芯片 TPUv1 的二代产品,被认为有着替代英伟达 GPU 的潜在实力。RiseML 此前撰写过一篇谷歌 TPUv2 的初体验,并随后收到了大家「将谷歌 TPUv2 与英伟达 V100 GPU 进行对比评测」的大量迫切要求。
但是将这两款深度学习加速芯片进行公平而又有意义的对比评测并非易事。同时由于这两款产品的对业界未来发展的重要程度和当前深度详细评测的缺失,这让我们深感需要自行对这两款重磅云端芯片进行深度评测。我们在评测过程中也尽可能地站在芯片对立双方倾听不同意见,因此我们也同时与谷歌和英伟达的工程师建立联系并让他们在本次评测文草稿阶段留下各自的意见。以上措施使得我们做出了针对 TPUv2 和 V100 这两款云端芯片的最全面深度对比评测。
实验设置
我们用四个 TPUv2 芯片(来自一个 Cloud TPU 设备)对比四个英伟达 V100 GPU,两者都具备 64GB 内存,因而可以训练相同的模型和使用同样的批量大小。该实验中,我们还采用了相同的训练模式:四个 TPUv2 芯片组成的一个 Cloud TPU 来运行一种同步数据并行分布式训练,英伟达一侧也是同样利用四个 V100 CPU。
模型方面,我们决定使用图像分类的实际标准和参考点在 ImageNet 上训练 ResNet-50 模型。虽然 ResNet-50 是可公开使用的参考实例模型,但是现在还没有能够单一的模型实现支持在 Cloud TPU 和多个 GPU 上进行模型训练。
对于 V100,英伟达建议使用 MXNet 或者 TensorFlow 的实现,可以在 NVIDia GPU Cloud 平台上的 Docker images 中使用它们。然而,我们发现 MXNet 或者 TensorFlow 实现直接拿来使用的话,在多 GPU 和对应的大训练批量下并不能很好地收敛。这就需要加以调整,尤其是在学习率的设置方面。
作为替代,我们使用了来自 TensorFlow 的 基准库(benchmark repository),并在 tensorflow/tensorflow:1.7.0-gpu, CUDA 9.0, CuDNN 7.1.2 下在 Docker image 中运行它。它明显快过英伟达官方推荐的 TensorFlow 实现,而且只比 MXNet 实现慢 3%。不过它在批量下收敛得很好。这就有助于我们在同样平台(TensorFlow 1.7.0)下使用相同框架,来对两个实现进行比较。
云端 TPU 这边,谷歌官方推荐使用来自 TensorFlow 1.7.0 TPU repository 的 bfloat16 实现。TPU 和 GPU 实现利用各个架构的混合精度训练计算以及使用半精度存储最大张量。
针对 V100 的实验,我们在 AWS 上使用了四个 V100 GPU(每个 16 GB 内存)的 p3.8xlarge 实例(Xeon E5-2686@2.30GHz 16 核,244 GB 内存,Ubuntu 16.04)。针对 TPU 实验,我们使用了一个小型 n1-standard-4 实例作为主机(Xeon@2.3GHz 双核,15GB 内存,Debian 9),并为其配置了由四个 TPUv2 芯片(每个 16 GB 的内存)组成的云端 TPU(v2-8)。
我们进行了两种不同的对比实验,首先,我们在人工合成自然场景(未增强数据)下,观察了两者在每秒图像处理上的原始表现,具体来说是数据吞吐速度(每秒处理的图像数目)。这项对比与是否收敛无关,而且确保 I / O 中无瓶颈或无增强数据影响结果。第二次对比实验,我们观察了两者在 ImageNet 上的准确性和收敛性。
数据吞吐速度结果
我们在人工合成自然场景(未增强数据)下,以每秒图像处理的形式观测了数据吞吐速度,也就是,在不同批量大小下,训练数据也是在运行过程中创造的。同时需要注意,TPU 的官方推荐批量大小是 1024,但是基于大家的实验要求,我们还在其他批量大小下进行了两者的性能测试。
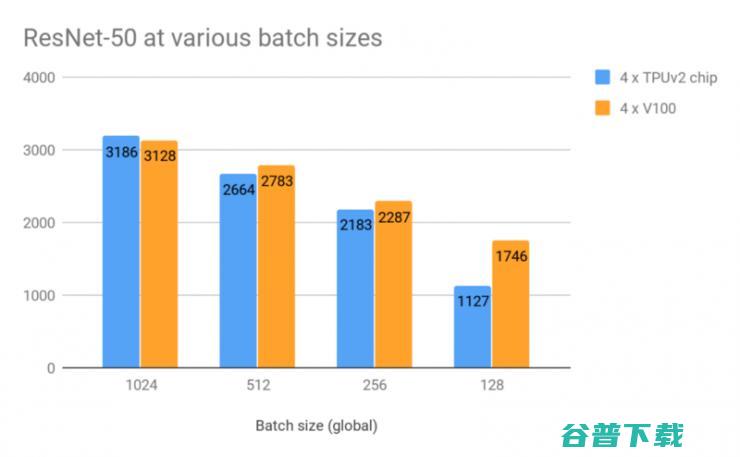
在生成的数据和没有数据增强的设置下,在各种批量大小下测试两者的每秒图像处理性能表现。批量大小为「global」总计的,即 1024 意味着在每个步骤中每个 GPU / TPU 芯片上的批量大小为 256
当批量大小为 1024,两者在数据吞吐速度中并无实际区别!谷歌 TPU 有约 2% 的轻微领先优势。大小越小,两者的性能表现会越降低,这时 GPU 就表现地稍好一点。但如上所述,目前这些批量大小对于 TPU 来说并不是一个推荐设置。
根据英伟达的官方建议,我们还在 MXNet 上使用 GPU 做了一个实验,使用的是 Nvidia GPU Cloud 上提供的 Docker image (mxnet:18.03-py3) 内的 ResNet-50 实现。在批量大小为 768 时(1024 太大),GPU 能每秒处理 3280 张图像。这比上面 TPU 最好的性能表现还要快 3%。但是,就像上面那样,在批量大小同为 168 时,多 GPU 上 MXNet 收敛得并不好,这也是我们为什么关注两者在 TensorFlow 实现上的表现情况,包括下面提及的也是一样。
云端成本
现在 google Cloud 已经开放了云端 TPU(四个 TPUv2 芯片)。只有在被要求计算时,云端 TPU 才会连接到 VM 实例。云端测试方面,我们考虑使用 AWS 来测试英伟达 V100(因为 Google Cloud 当前仍不支持 V100)。基于上面的测试结果,我们总结出了两者在各自平台和 provider 上的每秒处理图像数量上的花费成本(美元)。
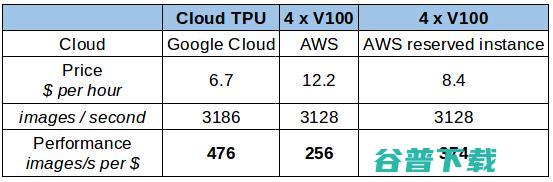
每秒图像处理上的成本(美元)
在上表所示的成本下,云端 TPU 显然是个赢者。然而,当你考虑长期租用或者购买硬件(云 TPU 现在还没有办法买到),情况可能会不同。以上情况还包括当租用 12 个月时的情况(在 AWS 上的 p3.8xlarge 保留实例的价格(无预付款))。这种租用情况将明显得将价格降低至每 1 美元处理 375 张图像的成本。
GPU 这边有一个更有意思的购买选项可以考虑,例如 Cirrascale 就提供了四个 V100 GPU 服务器的月租服务,月租金 7500 美元(约 10.3 美元/小时)。但是由于硬件会因 AWS 上的硬件配置(CPU 种类,内存以及 NVLink 支持等等)的不同而改变,而以 benchmarks 为基准的对比评测要求的是直接的对比(非云端租用)。
正确率和收敛
除报告两者的原始性能之外,我们还想验证计算(computation)是「有意义」的,也就是指,实现收敛至好的结果。因为我们比较的是两种不同的实现,所以一些误差是在预料之中的。因此,这是一项不仅仅是关于硬件速度,还会涉及到实现质量的对比评测。TPU 的 ResNet-50 实现中加入了非常高计算强度的图像预处理过程,这实际上牺牲了一部分数据吞吐速度。谷歌给出的实现中就是这样设计的,稍后我们也会看到这种做法确实获得了回报。
我们在 ImageNet 数据集上训练模型,训练任务是将一张图像分类至如蜂鸟,墨西哥卷饼或披萨的 1000 个类别。这个数据集由训练用的 130 万张图像(约 142 GB)以及 5 万张用于验证的图像(约 7 GB)组成。
我们在批量大小为 1024 的情况下,对模型进行了 90 个时期的训练,并将数据验证的结果进行了比较。我们发现,TPU 实现始终保持每秒处理 2796 张图像的进程,同时 GPU 实现保持每秒处理 2839 张。这也是根据上面数据吞吐速度结果所得的区别,我们是在未进行数据增强和使用生成的数据的情况下,对 TPU 和 GPU 进行的原始速度比较。
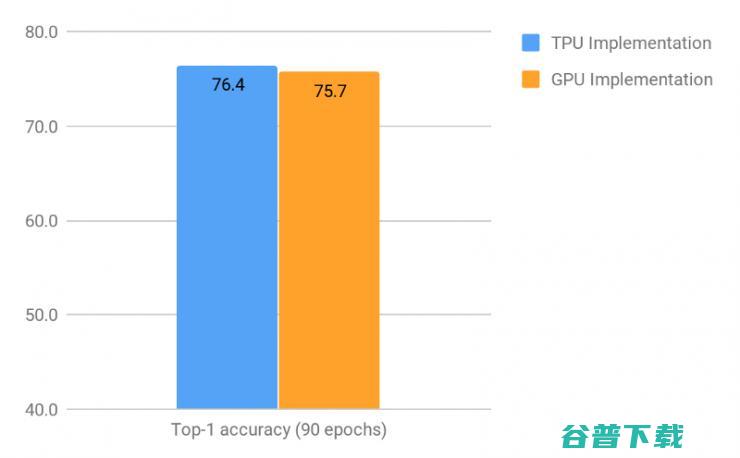
两个实现在进行了 90 个时期训练后的首位准确率(即只考虑每张图像具有最高可信度的预测情况下)
如上图所示,TPU 实现 进行了 90 个时期训练后的首位准确率比 GPU 多 0.7%。这在数值上可能看起来是很小的差别,但是在两者已经非常高的水平上进行提升是极度困难的,以及在两者在实际应用场景中,即便是如此小差距的提升也将最终导致在表现产生天壤之别。
让我们来看一下在不同的训练时期模型学习识别图像的首位准确率。
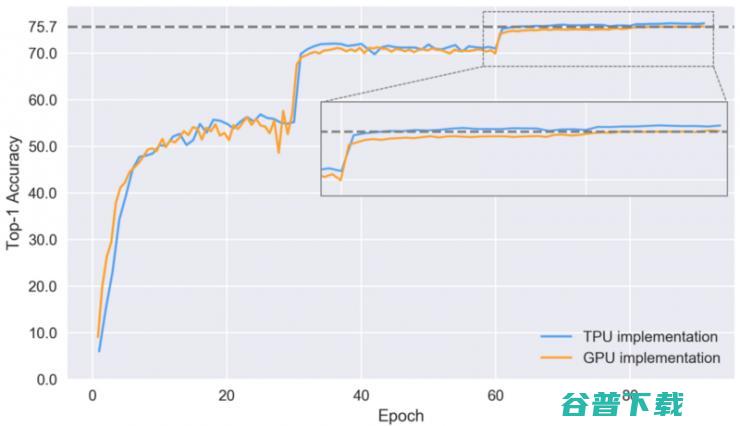
设置了验证的两个 实现的首位准确率
上表中放大图部分首位准确率的剧烈变化,与 TPU 和 GPU 这两个 实现上模型的学习速率是相吻合的。TPU 实现上的收敛过程要好于 GPU,并在 86 个时期的模型训练后,最终达到 76.4% 的首位准确率,但是作为对比,TPU 实现则只需 64 个模型训练时期就能达到相同的首位准确率。TPU 在收敛上的提升貌似归功于更好的预处理和数据增强,但还需要更多的实验来确认这一点。
基于云端的解决方案成本
最后,在需要达到一定的精确度的情况下,时间和金钱成本最为关键。我们假设精确度 75.7%(GPU 实现可实现的最高精确度)为可接受的解决方案,我们就可以计算出,基于要求的模型训练时期和模型图像每秒处理的训练速度,达到该精确度的所需成本。这还包括计算模型在某个训练时期节点上花费的时间和模型初始训练所需的时间。
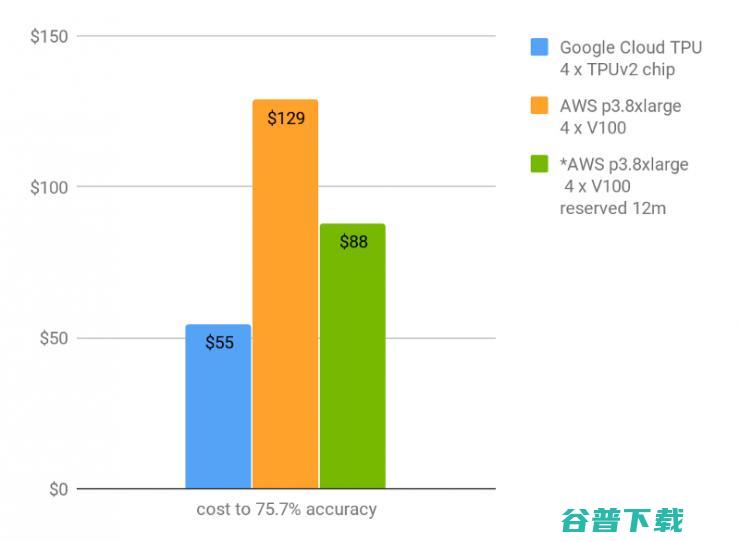
首位准确率达到 75.7% 的金钱成本(保留 12 个月的使用周期)
正如上表所示,云端 TPU 允许用户在 9 个小时内并且花费 55 美元,就能在 ImageNet 上从零开始训练模型精确度至 75.7%,花费 73 美元能将模型收敛训练至 76.4%。虽然V100 与 TPU 的运行速度同样,但V100 花费价格过高以及其收敛实现更慢,所以采用 TPU是明显更具性价比的解决方案。
需要再一次说明的是,我们本次所做的对比评测的结果取决于实现的质量以及云端服务器的标价。
另外一项两者的有趣对比将会是基于两者在能量功耗上的比较。然而,我们现在还无法得知任何公开的 TPUv2 能量功耗信息。
总结
基于我们的实验标准,我们总结出,在 ResNet-50 上四个 TPUv2 芯片(即一个云端 TPU)和四个 GPU 的原始运行速度一样快(2% 的实验误差范围内)。我们也期待将来能通过对软件(TensorFlow 或 CUDA)优化来提升两者在平台上的运行性能和改善实验误差。
在特定问题实例上达到特定的精确度的两者实际运用中,时间和云端成本最为关键。以目前的云端 TPU 定价,配合高水平的 ResNet-50 实现,在 ImageNet 上达到了令人钦佩的准确率对时间和金钱成本(仅花费 73 美元就能训练模型达到 76.4%的精确度)。
将来,我们还将采用来自其他领域的不同网络架构作为模型的基准以进行更深度的评测。还有一个有趣的实验点是,对于给定的硬件平台,想要高效地利用硬件资源需要花费多少精力。举例来说,混合精度的计算可以带来明显的性能提升,然而在 GPU 和 TPU 上的实现和模型表现却是迥异的。
最后,感谢弗莱堡大学的 Hannah Bast、卡耐基梅隆大学的 David Andersen、Tim Dettmers 和 Mathias Meyer 对本次对比评测草稿文的研读与矫正。
via RiseML Blog ,雷锋网 AI 科技评论编译。
原创文章,未经授权禁止转载。详情见 转载须知 。



家长赋能学习交流平台

冬瓜肉丸汤的做法,冬瓜肉丸汤怎么做请看步骤:1.绞肉或者剁肉加30-50克水或者葱姜水,猪肉最好选梅花肉,肉馅放碗里加1个蛋清,生抽10克,松鲜粉或者鸡精适量,耗油5克,淀粉5克,盐2–2.5克,姜2–3克,香油10克...

广西巴马晶硒岩泉水业有限公司位于巴马镇,专业从事天然矿泉水的生产与销售,巴马景泉矿泉水属于天然矿泉水、碱性瓶装矿泉水,水源地位于“世界长寿乡”之首的广西巴马瑶族自治县甘内村长寿山自涌泉。

360体育直播是国内最好的体育直播网站之一,主要提供足球直播,NBA直播等国内外体育赛事足球直播,360直播网能够让您第一时间了解当天所有NBA赛事内容资讯,让您观看比赛的同时有能了解最新赛事动态。我们是最用心做的足球直播和NBA直播吧。

山东嘉诺装饰设计工程有限公司专业的,淄博装修公司,淄博装饰公司,淄博家装公司,住宅整装,办公精装,酒店精装,建筑外装,商业精装全方位专业定制服务.

开关电源,明纬开关电源,LED电源,防水电源,医疗电源,明纬电源-明纬(广州)负责明纬电源产品(开关电源,明纬开关电源,LED电源,防水电源,医疗电源,明纬电源)的制造生产及国内外客户销售服务与技术支持,主要有:开关电源,明纬开关电源,LED电源,防水电源,医疗电源,明纬电源

武汉服务器托管,武汉算力中心,武汉机柜租用,武当云谷数据中心,武汉光谷服务器托管,武汉高电机柜,武汉高电机房

这是一个专为钓鱼爱好者打造的信息交流平台。在这里,您可以找到关于垂钓的一切资源,与众多钓友共同分享垂钓的乐趣,提升自己的垂钓技能。致力于为广大钓友提供最新、最全、最专业的垂钓交流空间。无论您是垂钓新手还是资深钓友,都可以在这里找到属于自己的乐园。

深圳市索晟科技有限公司(www.socen-tech.com)以进口欧、美、日等国外优质品牌产品,主要包括日本KITZ气动阀,日本FUJI气体分析仪,美国ADI采样泵等。

二维火,专注餐饮云收银系统的研发和应用,致力于帮助餐饮等行业实现互联网信息化,例如手机扫码点餐/支付、手机管理店铺、会员营销互动、中央厨房等,实现O2O线上线下融合,节省经营成本,提高服务效率。开店就用二维火,生意一定更红火!

湖南三昌泵业专业生产矿用多级泵,矿用水泵,煤安矿用泵,耐磨矿用泵,矿用防爆泵等水泵产品,三十余年厂家生产经验,产品两年质量保证,联系电话:0731-52266688/18975130378

上海服务器托管,上海GPU服务器托管,上海机柜租用托管,上海高电机房,上海高电机柜,上海主机托管,上海idc机房,上海自建机房


大家好,今天小编为大家带来的是托马斯小火车游戏下载2022的内容,这款游戏想必大家都是耳熟能详了,首先这是一个赛车类的火车游戏,我们大家童年想必也看过相关的动画片,现在有游戏开发商将这个题材做成了游戏,我们很多的小伙伴们都是非常激动啊,毕竟童年的回忆总是美好的,小火车也是陪伴着咱们一步步走完了我们的童年,下面就跟着小编一起来看看吧,托...。

消息,近日,前阿里巴巴及谷歌智能网卡团队负责人蒋晓维博士加入大禹智芯,任职首席科学家,负责大禹智芯DPU芯片研发工作,公开资料显示,蒋晓维本科和研究生就读于南京大学电子工程系,2009年获得美国北卡州立大学计算机工程博士学位,研究领域覆盖CPU有架构、芯片设计、网络、虚拟化技术等,博士毕业后,蒋晓维先后在英特尔、阿里巴巴和谷歌工...。
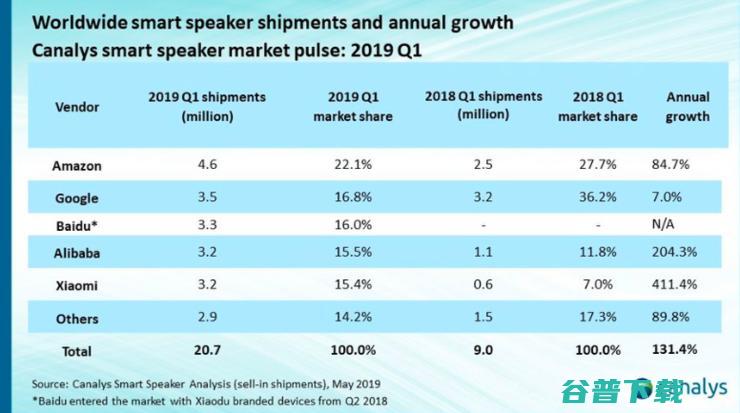
雷锋网消息,5月20日,市场调研机构Canalys、StrategyAnalytics相继公布了2019年Q1智能音箱市场出货情况,二者均特别针对中国智能音箱市场进行了分析和预测,并指出,2019年Q1中国智能音箱销量同比增长超过500%,就智能音箱全球出货量排名来看,依次为亚马逊、谷歌、百度、阿里、小米,其中,国内企业百度、阿里、小...。
本周内,Meta已经流失了两位高管,就在Meta首席运营官SherylSandberg,本周三宣布将于今年离职后,Meta人工智能团队在打散重组中,又失去了一位高管,6月2日,过去四年半在Meta担任人工智能实验室副总裁的JeromePesenti,在推特上官宣,将于今年6月中旬正式离职,Pesenti在2018年1月加入人工智能实验...。

我们手中拿到的这台小米游戏本是顶配,搭载了i7,7700HQ,以及GTX10606GB显存,配以16GB内存,256GBPM961和1TB希捷HDD组成的硬盘,性能很强悍,该款售价为8,999元,它的外观设计还是可以的,A面是一整块金属,而且还没有任何Logo在上面,看上去和摸上去的感觉都不错,但2cm的厚度以及2.7kg的重量,使得...。

姆巴佩小红书更新:评价一下我打开九月的方式吧,西甲,姆巴佩,小红书,皇家马德里,皇家贝蒂斯队

1、梦见他人抬起棺材的预兆人格之木立于地格土之上,适应天地人造之妙配,莫作木克土论,此局兆,乃必安泰自在,境遇坚挺稳妥,如立盘石之安泰普通,能完成兴旺,容易达成目标,名利双收,顺利开展,幸福短命,但切戒贪污,否则招凶以受尽职犯法之罪惩,大吉昌,吉凶指数,87,内容仅供参考,不代表本站立场,2、梦见他人抬起棺材的宜忌,宜,宜备雨具,宜...。

随着科技的飞速开展,电动汽车市场也日趋兴盛,日产作为世界出名汽车品牌,人造也不甘落后,推出了旗下全新的电动汽车——ARIYA艾睿雅,而Nismo版,作为日产性能级汽车的品牌标签,因其杰出的外观颜值和动力性能备受注目,日前,日产官网发布了一组关于ARIYA艾睿雅Nismo的官图,估量该车将在往年上市出售,本文将对ARIYA艾睿雅Nism...。

奇瑞A5的油耗大略在每百公里6,9升之间,这一油耗范畴是基于奇瑞A5的车型特点、能源系统以及普通驾驶条件综合思考得出的,奇瑞A5作为一款紧凑型轿车,理论驳回较为经济的发起机,如1.5L或1.6L的人造吸气发起机,这些发起机在提供足够能源的同时,也能坚持较低的油耗,此外,油耗还会遭到多种要素的影响,如驾驶习气、路线状况、车辆保养状况等,...。

图吧工具箱是一个系统检测软件合集,包括了一大堆系统软件,软件是一个启动器,能快速的启动各种工具。但是由于是易语言编写,很容易出现报毒。

MySQL是一种常用的关系型数据库管理系统,广泛应用于各种Web应用和企业级系统中。在开发和维护MySQL数据库时,性能优化和索引设计是非常关键的环节。本文将基于作者在项目中的经验总结MySQL性能优化和索引设计的一些实践方法和技巧。一、了解数据访问模式在进行性能优化和索引设计之前,首先需要了解数据库的数据访问模式。通过分析数据库中的查询语句和事务操作,可以

中国篮球荒诞选人:场均3分进国字号同龄16岁女姚明统治比赛无缘,姚明,女篮,张子宇,亚青赛,中国篮球,男子篮球,国际篮球赛事,奥林匹克运动会

人人都知道,IT行业基本属于,高薪,的代名词,同一所学校同一年毕业的大学生,学工程造价的、机械的、和学计算机的相比,也许当时大家的就业薪资都差不太多,但若半年后跳槽,或工作一两年积累了相关经验后,彼此的差距会迅速变大,正如知乎上某网友所说,曾经毕业时我高他三倍薪资的那个程序员,现在年薪已经是我的十倍了……天道有轮回,苍天绕过谁,01....。

苹果印度工厂暴乱,iPhone一夜被偷2万部中国台湾科技公司、苹果iPhone主要代工商之一纬创设在印度卡纳塔卡,Karnataka,的iPhone制造工厂于当地时间12月11日晚发生抗议暴动事件,警方在事发后已赶往现场维持秩序,目前累计已逮捕132人,目前,据统计,纬创损失高达43.7亿卢比,约3.88亿台币,,有超过2万部iPho...。

notability怎样填充颜色,notability是非常实用的记笔记软件,用户可以直接填色,不需要用画笔取涂抹,非常的方便,只要开启这个功能既可,那么不清楚的用户就一起来看看吧!...。

串串是常见的休闲小吃,其可以搭配多种不同食材进行制作,风味更是别具一格贴合年轻消费者的饮食口感,因此产品销量呈现出逐年递增的趋势,许多从业者的事业也得到快速发展,前景相当喜人,既然项目优势如此突出,那么创业者开家店运作显得切实可行,本文将对加盟串串怎么样进行解析,给有需要的读者提供必要的帮助,玫瑰串串立足餐饮行业已有多年之久,公司在经...。

最近车知事发现汉兰达居然有活动了,这可是一台终年加价能力提到现车的,标杆,欸,,加价,的硬气隐没不见,有点不敢置信,为了进一步务实,车知事在网上随机问了一下重庆两家广汽丰田4S店,都示意最近有肯定的活动,并且有现车,只是没有告知活动有多少,大家都知道,汉兰达不时以来在市场中的多少钱都十分的坚硬,即使是广汽丰田旗下其余产品打,多少钱战,...。
