百图生科首席AI科学家宋乐 帮助制药人逃逸 怪圈 双十 AI (百图生科首席科学家宋乐简介)
7 月 30 日,成立不到一年的百图生科(BioMap)宣布完成上亿美元的 A 轮融资,这家由李彦宏牵头发起并亲任董事长、原百度风投 CEO 刘维作为联合创始人兼 CEO 掌舵的「中国首家生物计算驱动的生命科学平台公司」向外界放出雄心:
公司致力于用高性能生物计算和多组学数据技术加速创新药物和早筛早诊等精准生命科学产品的研发,力图让更多疾病可预警、可控制、可治愈,为行业提供更好的生物地图(BioMap),帮助药厂找到化合物,帮助医生找到生物标志物,帮助科研人员找到各种生物数据背后的意义。
不久之前,国际机器学习大牛又宋乐加入李彦宏生物计算军团。为世界知名机器学习专家,他领导着百图生科 AI 算法团队,为独具特色的生物计算引擎研发提供技术动力。
宋乐博士是著名的机器学习和图深度学习专家,曾任美国佐治亚理工学院计算机学院终身教授、机器学习中心副主任,阿联酋 MBZUAI 机器学习系主任,蚂蚁金服深度学习团队负责人(P10)、阿里巴巴达摩院研究员,国际机器学习大会董事会成员,具有丰富的 AI 算法和工程经验。
自 2008 年起,宋乐博士在 CMU 从事生物计算相关的研究,利用机器学习技术对靶点挖掘、药物设计取得了一系列突破性成果,获得 NeurIPS、ICML、AISTATS 等主要机器学习会议的最佳论文奖。社区服务方面,他曾担任 NeurIPS、ICML、ICLR、AAAI、IJCAI 等 AI 顶会的领域主席,并将出任 ICML 2022 的大会主席,他还是同行评议期刊 JMLR、IEEE TPAMI 的副主编。
近日,由& 医健AI掘金志主办的GAIR「医疗科技高峰论坛」在深圳正式召开。
这一次,医健AI掘金志以「医疗AI的破局与新生 」为主题,将话筒传递给四位院士、5位IEEE Fellow、19位行业领袖,由他们以分别从历尽铅华的医学影像AI、和风劲正浓的AI制药两大赛道出发,为行业的发展提出自己的判断。
论坛之上,百图生科首席AI科学家,ICML 2022大会主席宋乐,以《用人工智能赋能新药研发》为题,发表了一场演讲。
宋乐教授提到,大家在憧憬AI可以在新药发现领域展现巨大作用的同时,还有三个问题要提前考虑。
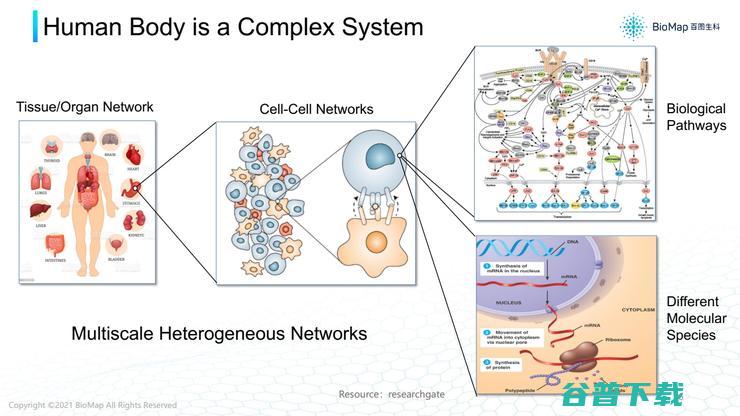
第一个挑战,了解复杂疾病的困难。例如胃癌,因为胃连接不同器官;细胞层面上,每个器官有不同细胞进行不同作用,细胞之间通性也是很复杂的网络;分子层面,细胞里有各种各样蛋白质等分子产生相互作用,也形成了很复杂的网络。所以,如果为一种胃部疾病找合适治疗靶点,就需要对整个网络有透彻的了解。
需要测量每一个环节、每一个尺度,包括整个机体组织尺度,整个组织的切片,细胞之间如何通信,如何表达这些基因。甚至要看到细胞里的蛋白质互相作用,收集这些数据会非常复杂。
例如,需要测量单个细胞基因表达量,蛋白质表达量。甚至还需要同时测量单个细胞基因表达、不同细胞在空间、组织里面的表达。
第二,对于包括基因层面的基因测序、表观组,蛋白质表达、蛋白质代谢,组织层面、机理层面等多维度、多尺度的数据,如何进行复杂且多样化的融合处理。
传统方式是对每个维度分开分析,再通过人来做整合;现在可以用AI将多尺度、多样化数据整合。 除了数据多样性问题,数据量增加也非常快,生物数据每7个月翻一倍。
第三个挑战,行业配合问题。数据分析与实验往往是两波人,他们之间的沟通缺乏一个非常高效的系统,将预测、模型输出和试验系统进行整合,加速迭代。
通常情况下,都是数据分析员根据根据已有知识在脑海里形成假设,然后让实验员做实验;有了数据后,再给数据分析团队分析,验证假设是否成立,决定下一次实验。
整个实验-数据分析-模型环节比较开环,但不是完全开环,缺少一个非常高效的系统,将预测或模型输出和实验系统整合,加速迭代过程。
以下是演讲的全部内容,做了不改变愿意的整理和编辑:
今天我分享一下对人工智能赋能医药的理解以及行业现状,人工智能在这个领域能做些什么。
首先,这个行业面临很大的挑战,我将其定义为双十挑战。
第一,医药研发漫长;每个新药从研发到上市需要10年时间甚至更多,药物筛选过程非常艰难。
很多药物都是小分子或蛋白质,种类极多,筛选空间甚至有10的60次方,从这么大范围找出最终的药物分子,并推到上市,其实非常艰难。
计算节点上,要从10的60次方中找到1万种,再从里面选几百个做Preclinical测试,之后再做临床试验,整个过程中每一步都有很高的失败率。
而且,前期筛选经常预测不到后期属性,导致产物后期无法使用,就要从头重新筛选,周而复始。

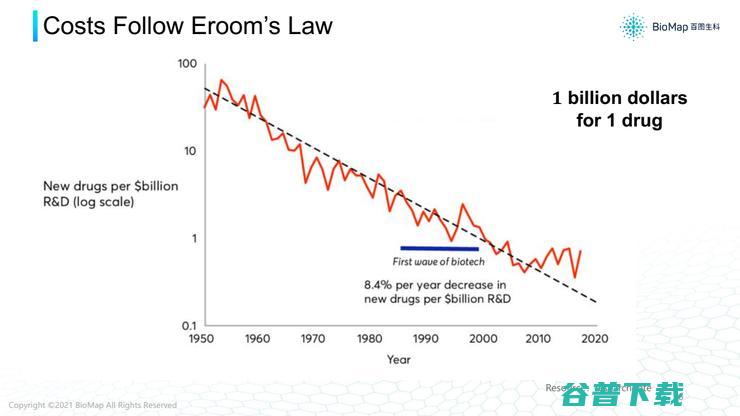
第二个“十”是指,开发一个新药大约需要10亿美金左右的造价。1950年还有很多比较容易治疗的疾病未被治愈,
如果当时有10亿美金投入,可以发现几十个药物。但现在面对的都是比较难的疾病,并且现在我们对药物的疗效、副作用减少的要求越来越高,监管要求越来越严。
所以10亿美金只能发现一个新药物。如果我们能把新药研发的造价降低、成功率提升的话,也可以节约研发经费,这个市场是巨大的。
所以AI新药研发面对的是一个非常广阔的市场,但大家在憧憬AI可以在新药发现领域展现巨大作用的同时,还有三个问题要提前考虑:
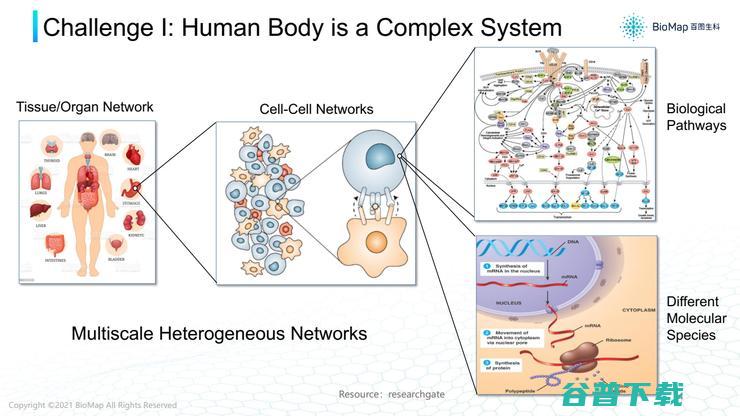
第一个挑战,了解复杂疾病的困难。例如胃癌,因为胃连接不同器官;
细胞层面上,每个器官有不同细胞进行不同作用,细胞之间通性也是很复杂的网络;
分子层面,细胞里有各种各样蛋白质等分子产生相互作用,也形成了很复杂的网络。
所以,如果为一种胃部疾病找合适治疗靶点,就需要对整个网络有透彻的了解。
需要测量每一个环节、每一个尺度,包括整个机体组织尺度,整个组织的切片,细胞之间如何通信,如何表达这些基因。甚至要看到细胞里的蛋白质互相作用,收集这些数据会非常复杂。
例如,需要测量单个细胞基因表达量,蛋白质表达量。甚至还需要同时测量单个细胞基因表达、不同细胞在空间、组织里面的表达。
第二,对于包括基因层面的基因测序、表观组,蛋白质表达、蛋白质代谢,组织层面、机理层面等多维度、多尺度的数据,如何进行复杂且多样化的融合处理。
传统方式是对每个维度分开分析,再通过人来做整合;现在可以用AI将多尺度、多样化数据整合。
除了数据多样性问题,数据量增加也非常快,生物数据每7个月翻一倍。
但是传统方式分析效率却不高,所以就需要AI模型用HPC方式,把数据里有用或微弱的信息整合。

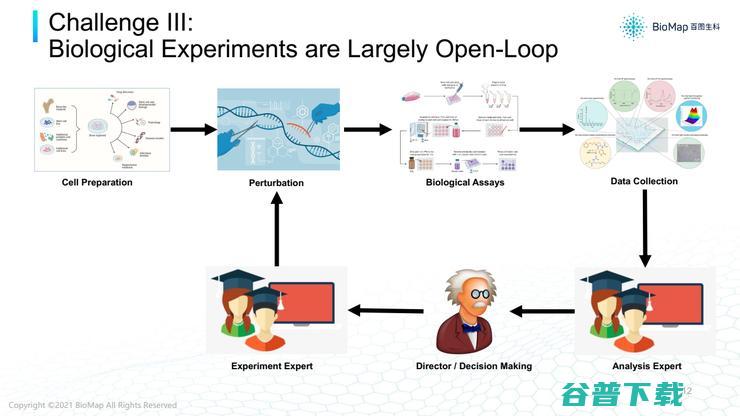
第三个挑战,行业配合问题。数据分析与实验往往是两波人,他们之间的沟通缺乏一个非常高效的系统,将预测、模型输出和试验系统进行整合,加速迭代。
通常情况下,都是数据分析员根据根据已有知识在脑海里形成假设,然后让实验员做实验;有了数据后,再给数据分析团队分析,验证假设是否成立,决定下一次实验。
整个实验-数据分析-模型环节比较开环,但不是完全开环,缺少一个非常高效的系统,将预测或模型输出和实验系统整合,加速迭代过程。
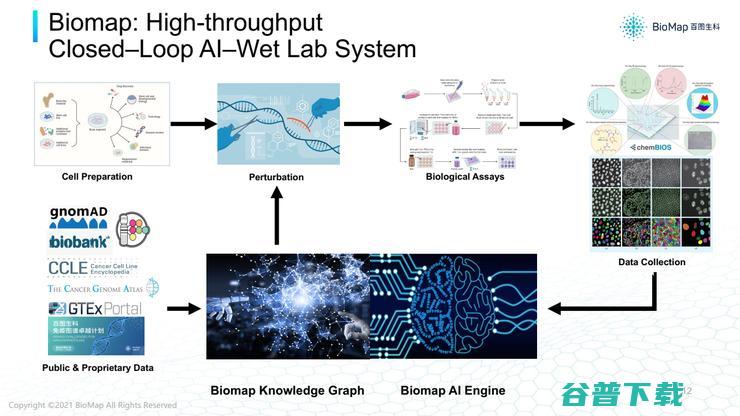
 为了解决这三个挑战,有必要形成一个AI-实验的闭环系统,把预测和湿试验的环节打通到同一个系统。
为了解决这三个挑战,有必要形成一个AI-实验的闭环系统,把预测和湿试验的环节打通到同一个系统。
百图生科建立了干湿试验闭环的高通量平台,这个平台在AI模型有一个巨大的场景,可以整合现有的数据,产生异构的、复杂的知识图谱。
基于知识图谱可以进行AI模型拟合,或者整合这些数据并且产生预测。例如要探究某个蛋白质是不是某个疾病的靶点,或者我们设计出方案是不是针对这个靶点有效,直接发放给实验系统,收集到的可能是生物实验数据,可能是翻译的数据,甚至是图像数据,
很快可以通过AI模型或者计算机视觉方法更新,再进行下一个实验。
接下来,我再介绍一下AI主要在每个环节可以做什么,大概分为三部分:
第一,在药物发现阶段找到新靶点;
第二,根据靶点设计新的药物分子;
第三,在试验闭环阶段进行交互学习。
下面具体列举几个案例:
第一个案例,AI找出目标蛋白质,例如在复杂蛋白质相互作用网络,或信号通路里找出蛋白质。
细胞膜上有很多蛋白质,阻断或激活膜蛋白的作用就会产生细胞间的生物作用。而且,每个蛋白质在不同疾病里,对应蛋白质表达单元也不一样。
寻找针对某个疾病表现的蛋白质,就需要把得到的细胞基因表达数据、蛋白质表达数据整合到同一网络里。
过去,有很多生物学家做了这方面研究,模型做得很复杂,将很多复杂的AI模型迁移到生物网络里。
例如在生物计算领域,蛋白质之间连接产生了非常复杂相互作用网络。
这个网络不单是两两蛋白质作用,也可能有三、四个蛋白质相互形成作用。蛋白质又关系到关键基因表达,每个节点有非常复杂的属性,就需要用图神经网络进行推理。
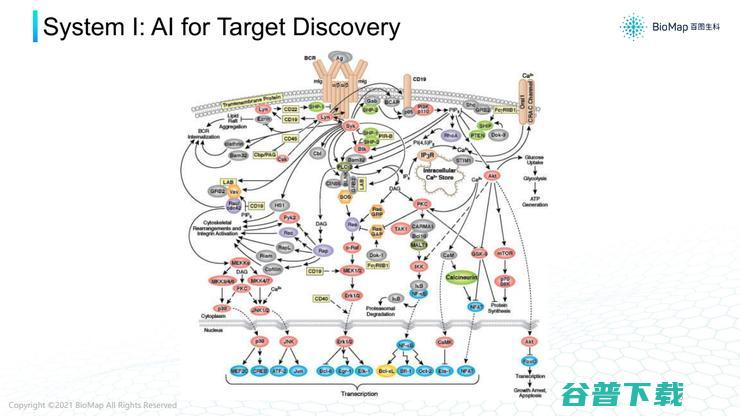
我们也可以借鉴其他领域的图神经网络模型,融合在一起学习更好的模型。
图神经网络是现在比较火的领域,大量搜索的经验都可以迁移到靶点发现领域,让靶点发现变得更有效,融合各种各样信息。
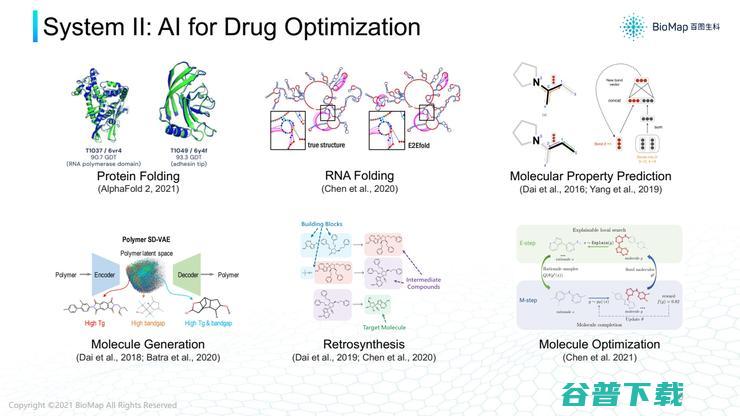
第二个案例,AI怎样针对靶点设计有效药物。一般药物都是有机小分子或大分子,或蛋白质或RNA。
所以,设计药物就要涉及很多小分子性质和大分子结构预测。例如AlphaFold 2可以根据给定序列预测蛋白质结构。
蛋白质的结构对其功能、作用非常关键,如果知道蛋白质功能结构就可以更好了解其功能,所以,准确蛋白质结构对设计结构非常关键。
除了蛋白质,AI领域还能看到各种各样搜索。例如RNA分子二级结构、三级结构,如果AI预测出这些结构对RNA药物设计也有帮助。
除此之外,各种各样小分子以及它们的属性,毒性、水溶性,针对某一个靶点的有效性,也都可以通过AI模型预测。
其实,生物制药的数据形态与传统互联网差异较大,生物制药数据中很多是图数据,而传统互联网主要以网络数据、人的行为数据为主。
在生物制药领域,如果想对一张图结构数据进行预测,或者对生成的小分子、大分子等生物序列比对,就需要各种各样图数据模型和VAE模型,甚至还要基于VAE模型学习小分子表征,进行小分子搜索和优化。
除了预测结构和功能外,AI在小分子性质优化上也有很多应用,例如已知一个小分子是潜在药物,利用AI更高效合成这些小分子,这就涉及到AI模型和博弈数搜索的结合。
目前,AI在小分子、大分子的应用已经非常完善,AlphaFold2本身就是非常复杂的AI模型。
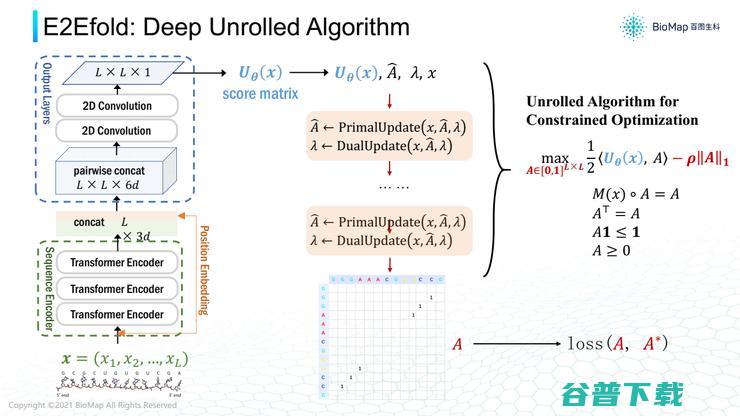
第三个案例,预测RNA二级结构折叠,通过RNA序列来预测结构。
我认为RNA药物未来可能是AI制药非常好的应用方向。
这是RNA二级结构预测展示,先输入RNA序列,如果需要预测RNA结构。就要在RNA 序列远端位点折叠,使空间上比较接近,位点接近程度用接触图表征。

AI模型可以在其中基于序列输入预测接触图,目前最好的手段就是深度学习,它的完善程度甚至超越了一些计算机视觉类模型。
用AI分析这样的数据,首先需要对序列分析,例如可以通过自然语言处理模型表征生物学序列。
这时,Transformer模型预测的是2D的结果,如果要生成图像数据,还需要做卷积神经网络产生特征,再预测接触图。
而且还要考虑结构的限制,AlphaFold 2就是采用类似的策略,这相比传统模型确实有巨大提高。
实验和AI模型闭环情况下,除了基因表达数据、蛋白质表达数据之外,AI还可以解决有细胞图像的数据。
细胞图像数据图像可能有六个频道荧光图像,如何基于荧光图像,描述出微妙的细胞状态变化,就需要做很多模型开发和设计。
此外,AI还可以提升一些信息含量比较高的实验的效率。
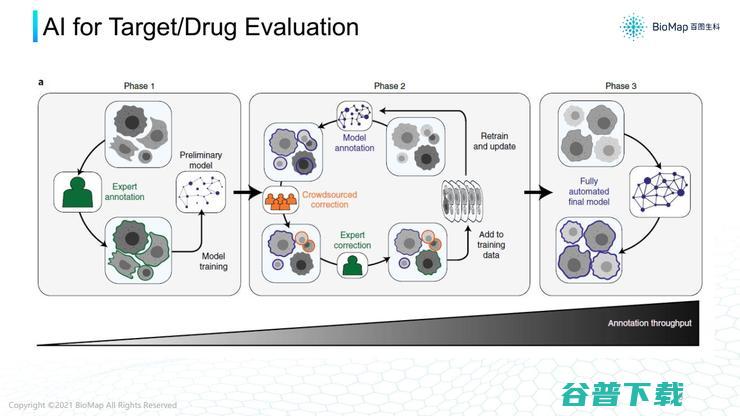
第四个案例,有效打标签。这不止是AI模型问题,也是系统设计的问题,而且也需要专家知识。
往往一开始只能获得少量精标签,训练一个尚可的模型。
但是如果让这个模型变成更准确的模型,就需要闭环的系统,让AI模型对大量没有标签的图像打标签,并呈现给无专业背景筛选,再给专家进行精标签;精标签打完后,再回流到AI模型更新,进行下一环。
整个过程如果在闭环情况下,就更有可能在少量精标签情况下,让模型继续对大量没有精标签的图像打标签。
此外,AI还可以输出分割标准,以及选择什么样图片打标签,在各个环节都有很多可以做东西,有很多可以提高的空间。
最后总结一下,我们目前面临的都还是非常复杂的问题,即使有很多观测手段,收集到大量数据,有如此多的AI模型,也还是杯水车薪。
未来,如何把AI模型、专家知识和实验手段结合在一起,还需要交叉学科的团队一起努力,希望感兴趣的同学加入这个领域,把生物计算交叉学科研究做得更好。
这是今天我想讲的就是以上这些,如果感兴趣,额外的信息可以关注我们公司的公众号并访问我们的网站。谢谢大家!
原创文章,未经授权禁止转载。详情见 转载须知 。


国内gpt4.0免费ai-ChatGPT官网免费入口

豆果美食为第一华人美食菜谱社区,提供各种美食、菜谱、食谱的做法,丰富的菜谱大全可以让您轻松地学会怎么做美食,展现自己的高超厨艺,与千万会员一同分享美味的人生!

云上黔南官网-云上公司注册,简称云上黔南官网-云上公司注册,是互联网线上虚拟园区,通过互联网的办法提供线下园区几乎所有的配套服务。除电子营业执照办理外,还能提供政策申报与兑现、线上培训、引导基金等服务。

小七玩卡专注三大运营商正规流量卡套餐测评,提供低月租、大流量、通话多的正规手机卡办理服务,在线比较,任你挑选!

视频服务平台,提供视频播放,视频发布,视频搜索,视频分享

医真云是专业的医疗云、影像云、医疗影像云平台,是以医疗过程为核心的云智一体化医疗服务,可以提供超强的医疗诊治、远程会诊、医疗影像等功能,能够满足科室级、全院级、区域级等工作流程,是国内唯一的全场景智能全医技云服务。

仓库通一款面向中小微企业的一站式的云进销存系统平台,为中小企业提供一站式仓储物流,进销存管理、仓库管理、资金管理等SaaS应用与服务,无需安装及维护,直接通过APP或电脑端在线使用。咨询热线:0571-81902717。

中国江西国际经济技术合作有限公司

黄金价格今天多少一克?现在金价是上涨还是下跌?今日黄金回收多少钱一克?金价查询网提供(国际/国内/香港)黄金价格报价实时走势行情及(周大福/老凤祥/老庙黄金/中国黄金/周六福/菜百)金店今日金价,查看黄金回收商回收价格。

赤赤旅游攻略网_提供最齐全的国内外旅游景点大全,您可以在这里找到关于旅游目的地最详细的图文介绍,可信赖的游览路线等等一系列关于旅游的资讯.

广州到上海物流公司,广州到上海物流专线,专业从事广州汽车托运,广州物流托运,广州货运物流,拥有辐射全国大部分城市的零担拼车直达专线业务。

安庆时讯

刚刚落下帷幕的8·22首届京东超级拍卖节上,有人75万买了个岛,有人265万买块表,还有人花864万买了瓶酒,这款中都拍卖上拍的,加拿大哈波特西岛,,低至1元的起拍价,不仅引来了高达10万人次的围观,更有101人报名,59次出价,最终以750,001元的价格成交,不同于今年6·18以1250万人民币的价格拍下,瓦努阿图珊瑚礁群岛,可享...。

解放碑,重庆的标志,周围隐藏着很多美食,对于到重庆旅游的人来说,解放碑是不得不去的地方,美食购物一网打尽,深受大家喜爱,但很多人由于初到重庆,对重庆解放碑有什么好吃的并不是很了解,下面小编为各位推荐几个,仅供参考,重庆解放碑有什么好吃的,重庆小面推荐理由,选料考究,口感独特去重庆解放碑游玩,又怎么能不吃重庆小面呢,重庆小面是一款发源于...。

为了在2025年实现消费级别的自动驾驶,Mobileye都做了什么,Mobileye近日在CES2021展会上进一步分享了其在ADAS及全自动驾驶领域的战略规划,并详细介绍了Mobileye为实现消费级别的全自动驾驶和,挽救生命,愿景所研发的几项技术,其中涵盖了芯片、雷达、地图、安全驾驶模型等各个方面,搭建消费级别的全自动驾驶系统为了...。

CNBC报道,微软联合创始人比尔盖茨,优步联合创始人TravisKalanick的10100基金和现任优步首席执行官DaraKhosrowshahi投资了一家AI芯片初创公司LuminousComputing,这家公司有一个雄心勃勃的计划,将世界上最大的超级计算机的计算能力放在一颗芯片上,据悉,Luminous总共获得了900万美元的...。

通义千问开源!8月3日,AI模型社区魔搭ModelScope上架两款开源模型Qwen,7B和Qwen,7B,Chat,阿里云确认其为通义千问70亿参数通用模型和对话模型,两款模型均开源、免费、可商用,在多个权威测评中,通义千问7B模型取得了远超国内外同等尺寸模型的效果,成为当下业界最强的中英文7B开源模型,今年4月,阿里云推出自研大模...。

发表在当贝投影仪2020,12,2219,48导读,智能投影仪可以通过蓝牙连接播放音乐,当贝f3怎么进入蓝牙音箱呢,下面就将方法分享给大家,简单操作按下关机键进入蓝牙音箱模式,打开手机蓝牙连接即可,当贝f3怎么进入蓝牙音箱1.按下当贝f3投影仪遥控器的关机键,在关机选项中选择蓝牙音箱;2.打开手机蓝牙,找到对应的当贝f3设备,进行连接...。

发表在综合交流大区2021,8,216,12如果需要使用投影仪播放电脑中的视频,但是身边没有U盘或者HDMI线怎么办,今天给大家分享一个方法,Samba共享,此教程需要大家在投影中安装kodi,在当贝市场直接搜索kodi下载就可以了,下载好的kodi是英文版,查看kodi如何设置中文界面的教程即可将界面设成中文,kodi播放电脑上的视...。

地球有两种,一种可以看到整个球面,另一种是放大版,两种都是根据你在的位置进行一天的光影变化,晚上的时候能看到万家灯火,然后还能看到地球背面的太阳不想看到绿点定位的话可以去设置,隐私,定位里把它关掉,...。

现在全国的美团外卖代理商已经禁止商家自配送方式,必须使用美团专送!而美团专送与商家自配送的区别又在哪呢?
1、首先,咱们关上手机阅读器,搜查央视直播,进入央视网官方,2、在右侧一切直播的央视频道中,找到CCTV5,频道点击,3、而后点击屏幕核心的播放按钮,期待广告加载终了,就可以在线观看直播了,4、假设播放窗口显示须要装置Flash,点击下方配置键,关上阅读器设置,5、找到初级设置——阅读器标识,将阅读器标识改为自动即可,假设显示手机就改...。

理论所说的mini属于中高品位的汽车,属于宝马旗下的经典小汽车关于大少数的车主而言,mini的外观是十分不错的,总是可以在最短的期间内吸引人们的留意力Mini领有让人觉得矮小上的外表,车身的线条动感十足但是,mini,宝马MINI是小型车级别,小型车普通指是A型车中的A0级车,这种车轴距普通在22米至23米之间宝马MINI系列车型包含...。

一、超市货架超市货架是开超市必备的设施,用以摆放各种商品,除超市货架外,水果架,蔬菜架,促销台或者也是常常出现的设施,二、收银系统收银系统普通包含收银台,收银机,收银软件,依据超市的规模选择收银设施的数量,普通放在进口处,三、制冷设施制冷设施有很多种,运谋生鲜须要冷藏冷冻设施;水果蔬菜须要水果保鲜柜和蔬菜保鲜柜;运营鲜奶饮料须要风幕柜...。
根据洛图科技,RUNTO,数据显示,2023年上半年,全球投影机市场出货量达到898万台,同比增长7.1%,增长的原因一部分在于去年同期疫情影响下的低基数效应,从今年的市场表现来看,供给端方面,主流品牌在疫后明显加快了产品布局和渠道建设,加大了促销力度和全球化的资源投入;需求端方面,新兴地区消费者对投影产品认知的提升、差旅等商务活动的...。

goodnotes怎样设置中文,goodnotes新打开的时候界面显示的是英文的界面,很多的用户使用非常的不方便,其实是可以更换成中文的,那么应该怎么设置呢,还不清楚的用户就一起来看看吧!...。

去年,麒麟970凭借全球首款搭载NPU的手机AI芯片备受关注,消息称今年麒麟980将升级NPU并首发全球7nm手机SoC,因此麒麟980吸引了更多关注,作为全球移动SoC的霸主,高通自然不会视而不见,雷锋网消息,高通新一代旗舰处理器骁龙855不仅将采用台积电7nm工艺,还将首次配备专用神经处理单元,NPU,另外,曝光的消息也指出新款...。

麦芽地网站上传播的,Wirelurker,木马估计让不少人震惊,未越狱的iPhone并非想象中安全,隐私泄露、远程控制这类病毒木马还是能存在,PANW的研究报告中显示,,Wirelurker,至少存在了6个月之久,受感染软件被下载超过35万次,直到被外媒曝光,苹果才反应过来修复,在这起事件中,,Wirelurker,木马传播网站麦芽地...。

数字化深入到千行百业,缺乏安全能力的企事业单位,成为数字产业链上最弱一环,为此,360将服务国家和大型头部组织的‘数字安全中国方案,云化,以托管服务模式复制给企业级客户,帮助其低成本、高效率地构建安全能力,360数字安全集团总裁胡振泉在第十一届互联网安全大会,以下简称,ISC2023,上指出,8月9日,以,安全即服务开创人工智能...。
