Goes Brrr Compute 重温强化学习之父Sutton关于AI的70年惨痛教训
双语原文链接: Compute Goes Brrr: Revisiting Sutton’s Bitter Lesson for Artificial Intelligence
回顾理查德·萨顿关于AI的惨痛教训
就在不久前的过去,在一个与我们今天相差无几的世界上,在达特茅斯学院,有这样一个雄心勃勃的项目,志在弥合人类与机器智能之间的鸿沟。那是1956年。虽然 达特茅斯夏季 人工智能 研究项目 并不是第一个对思考机器的潜力提出设想的研究项目,但它的确为这个领域取了一个公认的名字(“人工智能”),并建立了由具有影响力的研究者们所组成的一座“万神殿”。在约翰·麦卡锡、马文·闵斯基、克劳德·香农与纳撒尼尔·罗切斯特共同撰写的提案中,作者们的目标虽然仍不成熟,但他们的雄心壮志,即使今天看来也足够奇妙有趣。
最初的人工智能
从那时起到现在,关于 人工智能的研究 ,经历过车水马龙的盛况,也不乏门可罗雀的冷落。在1956年,盛行的方法包括元胞自动机、控制论(cybernetics)、信息论。随着时间的流逝,专家系统、形式推理、连接主义等方法也轮番亮相,各领风骚。
今日,AI的复兴源于连接主义一脉相承的最新成果—— 深度学习 。尽管一些新思想的确也在这个领域造成了相当大的冲击(仅举几例:注意力机制、残差连接、批量归一化),大部分关于建立和 训练深度神经网络 的思想,早在上世纪八九十年代就已经被提出。然而今天,AI与AI相关的技术所扮演的角色,却并不是任何在之前的“AI之春”中活跃的研究者所想象的那个样子。例如,几乎没有人能预见到,广告科技(adtech)和驱动的新闻供稿的盛行与社会反响。我也很确信,他们中的很多人会为今天的社会如此缺少仿真机器人而感到失望。

约翰·麦卡锡,达特茅斯提案的共同作者,以及“人工智能”一词的发明者。 图源
约翰·麦卡锡曾经 抱怨过,落实到现实世界的AI技术,总是会变得不那么吸引人,并会逐渐失去“AI”的名字。不过,这并非我们今天所见的现象——也许我们要归咎于风险投资和政府基金,因为是它们鼓励大家去做了截然相反的事情。伦敦风险投资公司MMC的一份 调查 显示,在2019年的欧洲,高达40%自称的AI创业公司实际上并不将AI作为它们业务的核心构成部分。
与AI研究之间的区别
深度学习时代与之前那些AI研究的那些暖春期之间的区别,似乎可以被归结为摩尔定律的S形曲线。许多人将“ImageNet时刻”视为今天AI/ML复兴的起点——一个名叫的模型,以压倒性优势赢得了2012年ImageNet大规模视觉识别挑战赛()。AlexNet的结构,与在它20多年前就被提出的并没有很大的差别。
拥有5个卷积层的AlexNet,比拥有3个的LeNet要稍大一些。它总共有8层,而LeNet有7层(其中2层是池化层)。而其中的重大突破,则在于图形处理单元(gpu)以并行处理的方式实现最基础的神经网络运算(卷积与矩阵乘法),以及由李飞飞和她在斯坦福大学的实验室所整理的、兼具规模和质量的 ImageNet数据集 。
硬件加速的惨痛教训
硬件加速的存在,在今天的从业者看来已经是理所当然。它是诸如、 TensorFlow 、等热门深度学习库不可缺少的部分。深度学习研究者队伍的壮大,和面向AI/ML的商业需求的日益增长,构建了一个 协同反馈的循环 ,从而推动了良好的硬件支持的形成。而当基于FPGA、ASIC甚至是光子或量子芯片的新型硬件加速器逐渐为人们所用,各类热门学习库的软件支持也自然紧随其后。
ML硬件加速器与其赋予AI研究的更多算力所带来的冲击,被理查德·萨顿简洁地概括在了一篇相(臭)当(名)出(昭)名(著)的短文《 惨痛的教训 》中。文中,萨顿——这位曾(共同)撰写过 强化学习 的 教科书 的人物——却声称AI研究者们所付出的所有勤奋努力和聪明才华,对于整个大框架几乎没有起到任何推动作用。根据萨顿的说法,当前AI进步的主要驱动者,是日益提升的算力被用于实现我们既有的简单的学习和搜索的结果,而其中包含的硬编码的人类知识只是所需的最低水平。而萨顿认为,基于AI的方法应该是尽可能普适的方法,诸如无约束搜索和学习。
不出所料地,许多研究者都对萨顿所说的这个教训有着截然不同的观点。毕竟,他们中的许多人都将毕生心血投入到关于AI的各种技巧和理论基础的研究上,以期推动AI发展的进程。许多AI研究者并不局限于探索如何达到最先进的指标,而是希望学习所谓智能的本质,或更抽象地说,人类在整个宇宙中所扮演的角色。萨顿的表述似乎在支持这样一个令人失望的结论,即:对理论神经科学、数学、认知心理学等学科的探索,对于推动AI的发展是毫无帮助的。

另一张
关于“惨痛教训”的多方质疑
对萨顿的这篇短文,值得关注的一些批评包括了机器人学家罗德尼·布鲁克斯的《 更好的一课 》 (译注:原文标题为“A Better Lesson”,与萨顿的标题“A Bitter Lesson”仅一字之差) ,牛津大学计算机科学教授西蒙·怀特森的 一串推文 ,以及Shopify的数据科学家凯瑟琳·贝利的一篇 博客 。贝利反驳道,虽然萨顿对现代AI领域中那些仅局限于追求指标的课题的论断也许是对的,但这样的短视却完全没有抓住关键。AI研究的终极目标,应该是从可利用的角度去理解智能,而不是对每个特定的指标优化问题都从头训练出一个新模型——这需要付出极大的金钱和精力。贝利认为,现代的机器学习从业者,常常会 误将指标当作目标 ;研究者们之所以要造出超越人类的下棋机器或围棋机器人,不是为了他们自己,而是因为这些工作对于人类智能的某些方面,可能是至关重要的例证。
布鲁克斯和怀特森则反驳道,萨顿所提及的所有“不涉及人类先验”的例子,实际上都是大量人类智慧的结晶。例如,如果没有卷积层的平移不变性,那么很难想象,深度神经网络可以表现得像今天的 残差网络 (ResNet)一样好。我们也可以发现当前网络仍具有的很多不足,例如不满足旋转不变性或颜色不变性。此外,网络结构和训练细节也十分依赖人类的直觉和智慧。虽然比起人类工程师手动设计的模型,自动化的神经结构搜索(NAS) 有时可以找到更好的网络结构 ,但NAS最初的搜索范围,也是从所有的可能性里大大缩减后得到的——而缩小搜索范围,一直是人类设计者所管辖的领域。
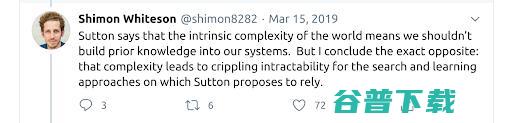
怀特森反驳道,搭建机器学习系统的人类智慧对解决复杂问题而言是必需,而不是阻碍。
对“惨痛教训”发声的批评人士中,也包括不少 对深度学习整体都存有怀疑 的研究者。依旧维持着令人印象深刻的庞大规模, 投入算力的开支不断膨胀 ,关于其 能源消耗 影响环境的担忧也日益加重。而且,没人能够保证,在未来的某个时刻,深度学习不会撞到一堵难以逾越的南墙——也许很快了。
距离边际收益无法再承受额外的支出,还有多久?深度学习的进步让人吃惊的原因之一,在于模型本身是很难被人们理解的;一个模型的表现,是从具有数以万亿计的参数所构成的复杂系统中突然出现的产物。要预测或分析它们到底能做到什么地步,相当困难。
也许我们所有人都应该认真记住符号人工智能(GOFAI)的经典,由斯图尔格·罗素和彼得·诺维格合著的《 人工智能:一种现代方法 》里的一课。在书中临近最后一章的结尾,我们发现了以下的警告:在关于AI的研究中,我们偏爱的方法——对我们来说是深度学习——也许就像:
作者们在这里换了一种方式表述了 休伯特·德雷福斯 在1992年所著的《计算机不能做什么》中的一个比喻,而这常常会回到那个月球旅行的树栖策略的比喻。尽管许多原始的智人曾经尝试过这个方法,但实际上,要登上月亮,首先要从树上下来,然后开始为太空计划扎扎实实地做准备。
结果不言自明
尽管这些批评听起来颇有说服力,但它们留给别人的印象,也只比酸葡萄稍微好一点。当学术界还在被知识分子们无法满足的“更多算力”的呼声拖后腿的时候,大型私人研究机构的研究者们马不停蹄地在各种项目里登上头条。而他们在工程上花费的心血,基本上都 直接投入到了规模化 当中。
而在这方面最臭名昭著的,莫过于OpenAI。
OpenAI在去年从非盈利组织转变为有限合伙企业,而它的核心人员从未掩饰过他们对于海量算力的偏爱。其创始人格雷格·布罗克曼与伊尔亚‧苏茨克维,与许多蓬勃成长的公司里的科技人士一样, 正是 理查德·萨顿的“惨痛教训”所形容的那样的人。OpenAI为冲刺里程碑所需的大量训练任务,促使相应的基础工程建设成为一大亮点。
OpenAI Five打败了(人类)Dota2世界冠军队伍OG,而它“仅仅”只用了45,000年——即 每天进行大约250年的游戏 ——来进行学习。在10个实时月内,它始终维持着800pefaflop/s-days(pfs-day)的算力。 (译注:1pfs-day指一天内可进行约10的20次方次加法或乘法运算) 如果以世界最先进的性能功耗比, 每瓦特进行170亿次运算 来计算,其能量消耗甚至超过 1.1吉瓦时 ,即一个正常美国家庭92年的总用电量。
OpenAI的另一个高规格、高消耗的项目,则是他们的,Shadow机器灵巧手项目。该项目的高光时刻,是机器手可以灵巧地解出魔方(虽然选择解法的步骤是由一个确定的求解器完成的)。这一解魔方的项目,是建立在大约 13,000年的模拟器经验 之上的。此外,DeepMind与之相当的AlphaStar( 44天,384块TPU训练12个智能体 ,模拟进行了数千年的游戏)或 AlphaGo系列 (AlphaGo Zero: 约1800pfs-day )等项目,也需要在计算资源上投入大量开支。
但结果也会对不上
但在“惨痛教训”所描述的潮流以外,也存在着这样一个鲜明的反例:训练游戏智能体的AlphaGo系列,在取得更好的表现的同时,实际上所需的算力反而。 AlphaGo系列 的确是个很有趣的例子,因为它无法融入“惨痛教训”所提出的框架之内。没错,这个项目一开始确实调用了压倒性的高性能计算资源用于训练:AlphaGo使用了176块GPU,并会在测试阶段消耗4万瓦特的能量。但从AlphaGo到MuZero之间的每一次更新换代,无论在训练阶段还是实际展示阶段,都消耗了更少的能量以及算力。
实际上,在AlphaGo Zero对阵 “鳕鱼” ——前时代最先进的下棋引擎——的时候,它的搜索次数比起StockFish要少得多,也要有针对性得多。虽然AlphGo Zero使用了蒙特卡罗树搜索,但为其“引路”的价值函数却是由一个深度神经网络所确定的。而“鳕鱼”所用的Alpha-beta剪枝搜索法,则有着更广的搜索范围:在每个回合中,“鳕鱼”所考虑的棋盘走位大概是AlphaGo Zero的400倍。
“惨痛教训”应该比针对性方法表现更佳吗?
你应该还记得,无约束搜索是萨顿曾列举的一个普适方法的例子。而如果我们全盘接受“惨痛教训”,那么它的表现应该比一个搜索范围更窄的针对性方法要来得更好。然而在AlphaGo系列的例子里,我们却发现:在每次更新换代(AlphaGo, AlphaGo Zero, AlphaZero, MuZero)之后,新方法比旧方法大体上都表现得更优秀,然而它们的 学习和搜索都是更有针对性的 。在Muzero中,原先用于搜索的基准真实游戏模拟器,被换成了名字以Alpha开头的所有前辈们。它们都有着一个学习好的深度模型,用于表示游戏状态、游戏的动态数据,并进行预测。
设计一个学习好的游戏模型,所需的人力远超最初的AlphaGo。然而,Muzero却拓展出了更通用的学习能力,在57个Atari游戏上都达到了当前最先进的表现,而之前的那些Alpha模型只学习了象棋、将棋和围棋。Muzero在每个搜索节点上所用的运算量比AlphaZero小了20%,并且也归功于硬件设施的改进,在训练过程中节省了4到5倍的TPU。

(被AlphaGo Zero打败后)被腌制晾干的鳕鱼 图源为公共领域。
由Deepmind研发的AlphaGo系列游戏机器人,是深度强化学习发展进程中的一个格外精妙的案例。而如果说,AlphaGo的研究队伍能成功地在降低计算需求的同时,还持续实现性能和通用学习能力的提升,这不就直接反驳了“惨痛教训”吗?
若是如此,它又为人们对通用智能的探索展示了什么呢?根据许多人的说法,强化学习是实现通用人工智能(AGI)的一个出色的候选方案,因为它与人和动物面向奖励的学习模式相近。不过,也有其他形式的智能,同样被一部分人认为是通用人工智能的先驱的候选者。
语言模型:大规模模型的王者
萨顿的文章受到新一轮的重视(最近KDNuggets甚至 将它列为一篇顶级文章 )的一大原因,是OpenAI万众瞩目的语言模型和应用程序接口(API)的发布。GPT-3是一个参数多达1750亿的Transformer,以略超10倍的数量,打破了之前由 微软的Turing-NLG 保持的语言模型规模的记录。GPT-3也比那个“危险得不能发布”的GPT-2大了100倍以上。
GPT-3的发布,是OpenAI的测试版API公告中的一个核心部分。这个API基本允许实验人员使用GPT-3模型(但不能对参数进行微调),并调节一些可以操纵推理过程的超参数。可以理解,那些足够幸运地用上了这个API的测试版用户,抱着极大的激情打开了GPT-3——而 结果 也是 令人印象深刻的 。实验人员开发了基于文本的游戏、用户界面的生成器、假博客,以及其他许多对这个大型模型的创新性应用。GPT-3的表现比GPT-2有显著性的提高,而其间唯一的主要区别,就是规模。
语言模型规模逐渐扩大的趋势,早在这些巨大的GPT出现之前就存在,并且也不局限于OpenAI的研究。但直到 《你只需要注意力》 一文引入了第一个Transformer,这一趋势才真正开始快速发展。在不知不觉间,Transformer的参数量已经平稳增长到数以百亿计。假如在一年多之后,就有人提出一个上万亿参数的Transformer,那我也不会感到惊讶。Transformer看起来十分适合拓展到更大的规模,而它的结构也并不局限于面向文本的自然语言处理。Transformer已经被应用于 强化学习 、 化学反应预测 、生成 音乐 和 图片 等领域。关于Transformer模型所用的注意力机制的可视化解释,参见 此处 。
按当前的模型增长速度计算,不出数年,就会有人训练出一个参数量堪比一个人类大脑中的所有神经元突触数量( 约100万亿 )的模型。科幻作品充斥着这样的例子:只要 具有足够大的规模和复杂度 ,机器就能获得自我意识和通用智能。这会是Transformer不断增长的终点吗?
关于AI未来的答案,介于两个极端之间

(图片文字:只有杰出的研究科学家才会以极端的方式行事!)
巨大的Transformer自然有着令人印象深刻的表现,而这一随着规模而递进的发展趋势,也符合“惨痛教训”所述。然而,将所有关于AI的工作都归为关于规模化的工作,是既不得体也不能令人满意的。此外,随之而来的能源需求也引起了人们的担忧。云端训练,将许多大实验室的研究者与低效的训练过程相隔离。但在一间小办公室或小公寓里运行实验的人们,则会身陷热浪之中。这热浪从他们的工作台背后不断冒出,一直提醒着他们(这训练是多么消耗能量)。

Steve Jurvetson 修改 的理查德·萨顿的 肖像
(图片文字:结束了,学者们,我有算力!)
以超参数搜索和架构搜索训练一个庞大的NLP Transformer的碳排放量,可以轻易超过一个 小型研究队伍 的所有成员进行所有其他活动所产生的总排放量。
我们知道,智能体是可以在持续以20瓦特(以及额外用于机体运转的80瓦特)运行的“硬件”上运行的。如果你对此抱有怀疑,那么你应该在自己的双耳之间找到这一存在的证据。而与之相反的是,用于训练OpenAI Five的能量消耗,却比一个人类玩家 活一辈子所需的热量还要多 ,足以支撑他90年的寿命。
一个细心的观察者会指出,一个人类大脑所需的20瓦特的能量消耗,并不代表整个学习的总消耗。然而,它的架构和运行规则,也是一个运行长达40亿年的漫长的黑箱优化过程——其名为“进化”——所得到的结果。如果将所有人类祖先的全部能量消耗一并加总,也许人类和机器游戏玩家之间的对比可以显得更有意义些。即便如此,在模型架构和训练算法上的一切进步,与纯粹的通用随机搜索仍然相差甚远。但在机器智能上由人类驱动的进步,当然比动物界之中智能的进化要快得多。
所以,“惨痛教训”是对是错?
一个显然的,但也许对绝对主义者不够友好的答案是:既不是这边,也不是那边。注意力机制、卷积层、乘法循环连接以及其他许多大模型中常见的机制,都是人类智慧的结晶。换句话说,它们是令人类思想推动学习任务运行得更好的前提,也对我们目前所见的一系列规模化的进步至关重要。故意忽略这些发明,一味地维护摩尔定律和“惨痛教训”的话,便与纯粹依靠手动编码的专家知识一样短视。
一个设计错误的优化过程,即使 运行到宇宙的终结,也解不出一个问题 。在享受规模化所带来的红利时,一定要将这一课铭记于心。

(图片文字:你低估了我的!)
AI研习社是AI学术青年和AI开发者技术交流的在线社区。我们与高校、学术机构和产业界合作,通过提供学习、实战和求职服务,为AI学术青年和开发者的交流互助和职业发展打造一站式平台,致力成为中国最大的科技创新人才聚集地。
如果,你也是位热爱分享的AI爱好者。欢迎与译站一起,学习新知,分享成长。

版权文章,未经授权禁止转载。详情见 转载须知 。



PR值全称为PageRank(网页级别),取自Google的创始人LarryPage。它是Google排名运算法则(排名公式)的一部分,PR查询可以根据域名查出对应网站(可查内页)的PR。

中捷职业技术学校

河南成人高考网为考生提供2022河南成人高考报名时间、报名条件、报名费用、招生院校、招生专业、考试时间、考试科目、历年试题及答案、分数线、成绩查询等资讯。

悦动户外团建

东莞市德企包装制品有限公司通过ISO9001-2015体系认证环保14001认证,拥有先进的生产设备、公司产品以优质著称、公司主营PO胶袋、PE胶袋、PP胶袋、OPP胶袋、PPE胶袋、PVC挂勾袋。环保和防静电的工业包装袋,精美印刷、食品袋、制衣厂各种平挂、斜挂袋、信贴袋、单R、双R、航空速递邮包袋、商场各种购物袋、广告袋、自封袋、叉耳袋、手提袋、手挽袋、卡头袋、纸袋、无纺布环保袋。等代客户设计制版、立志为客户提供优质的产品。一流售后服务产品通过SGS检测和符合欧盟REACH、SVHC检测、有检测报告。

淘得过-优惠券折扣直播第一站!每天更新千款,纯人工筛选验货,限时限量特卖,全场1折包邮!

摩点是专注于文化创意领域的众筹社区。致力于帮助创作者募集资金,找到支持者,让新鲜有趣的好创意成为现实。

东莞市圣珂新能源环保科技有限公司是一家从事RDF成型机、生物质成型机、圣珂颗粒机的企业,提供RDF成型产品相关服务和产品,欢迎来电咨询。

步步轻松

连线网,ulinix,music,nahxa
有限公司")
立讴立彩广告(北京)有限公司是一家从事广告设计代理,平面设计,广告制作等业务的公司,成立于2006年11月07日

主要用于,机构设置,政务公开,新闻中心,网上办事,公众参与,专题报道,服务热线,友情链接,其他功能,厦门市政务信息化项目管理服务平台等信息的发布


酒店是大家都比较熟悉的一类服务门店,在国内所有的城市地区都有着大量的酒店门店存在,市场的发展规模巨大,而且酒店行业发展层次丰富,各种定位、风格、主题、样式的酒店项目深受诸多消费者的喜爱,郁锦香酒店作为业内实力酒店品牌,背靠总部实力酒店集团发展资源,在实际的项目发展上取得了出色的成绩,获得了很多加盟创业人士的关注,那么,郁锦香酒店的选址...。

娱乐至上的时代,各大电影、电视剧、综艺节目层出不穷,好坏掺杂,为了让大众能快速地找到真正的好节目,于是各种评分APP纷纷崛起,这其中,豆瓣就深受大众喜欢,其巅峰时候日均活跃用户超2亿,这是互联网世界极少见的,按道理说,豆瓣必定是赚得盆满钵满,然而真实情况却是——豆瓣真的太不会赚钱了,2011年,其创始人阿北说豆瓣实现基本盈利,2015...。

大众创业,万众创立的格局已然形成,创业市场前景一片大好,一些为知名的商业品牌为促进公司的持续发展和鼓励大众的创业热情,开始推出,加盟,和,直营,的两种创业经营形式,而这两种形式亦是当下创业者选择较多两种经营方式,虽然这两种形式都是很受欢迎经营方式,但是它们在管理、经营政策方面还是存在一些细微的差异,那么到底加盟店与直营店的区别在哪里,...。

中国品牌迎来了里程碑式的历史时刻,乘联会发出了如此评论,4月11日,乘联会公布了今年3月份国内乘用车市场厂商排名,在批发销量的排行中,长安汽车以13.2万辆的成绩超越南北大众,夺得榜首,尽管长安在燃油车市场的成绩无可挑剔,但一直以来,其在新能源车市场的数据显得有些单薄,没有代表性的新能源车型是最主要的症结所在,不过,这样的情况也许...。
2020年,时代呈现出前所未有的波谲云诡,人们几乎每一天都在见证历史,在新冠肺炎疫情肆虐的大背景下,全球经济受到重创,中美双边关系到陷入到谷底,欧盟正式与英国达成脱欧协议……在动荡不安的世界局势下,包括互联网、教育、医疗、半导体等在内,几乎每一个行业都在经历着前所未有的沉浮,本文关注的,是在世界范围内都足以产生巨大影响力的中国智能手机...。

agent22981入门级投影控发表于2018,11,13不少朋友在选购投影时,都会发现很多投影仪产品的简介中都有这么一句话,采用美国德州仪器DMD芯片,DMD芯片,是个什么元件,应用在投影仪上到底有什么作用呢,今天我们就一起来探究一下投影仪,心脏,——DMD芯片的秘密,投影仪的,心脏,——投影芯片投影仪主要由光源和光机两大部分组...。
温馨提示,创维电视第三方刷机固件下载方法一,准备工作,从电脑里下载好当贝市场,点击立即下载,和影视快搜,点击立即下载,并拷贝到U盘;的主页,选择,酷开应用圈,,进入后选择推荐,打开左下角,搜索,功能;的USB接口,然后在,搜索,功能界面输入,XCX,并下载安装;四、打开,小程序,,这时候需要输入密码,密码输入正确后就可以自动识别U盘内...。

柬埔寨国防部5日确认,中国将向柬埔寨提供两艘056型护卫舰,以增强该国的海上进攻才干并确保海上安保,柬埔寨国防部发言人玛丽·淑洁达6日称,这两艘军舰是柬方依据进攻需求主意向中国放开的,将用于海上巡查、搜救义务以及其他人道主义优惠,依据方案,这两艘护卫舰估量将于2025年前后交付,据了解,056型护卫舰是中国海军的一种轻型护卫舰,该舰集...。

4日下午至5日上午,习近平总书记先后在湖北省孝感市、咸宁市调查,在咸宁市,习近平总书记调查了嘉鱼县潘家湾镇蔬菜长廊,了解外地推动农村片面复兴等状况,新华社记者定格下这样一个瞬间——立冬将至,蔬菜长廊放眼望去仍是满目碧绿,村道两旁的地里成片的甘蓝长势喜人,行将迎来收获期,潘家湾镇肖家洲村村民叶祥松正在地里除草,看到习近平总书记走进菜地,...。

7月5日,湖南岳阳市华容县团洲垸洞庭湖一线堤防出现决口,6日15时10分,华容县团洲垸洞庭湖一线堤防溃口处正式开局合龙作业,中国安能团体第一工程局安保环保部部长张轩庄引见,估量堵口作业工程周期在4天左右,6日23时许,堤防决口处多辆开掘机正在作业,每隔三四分钟,就有一辆重卡将满载的石料泼洒至溃口处,现场一名抢险接济人员示意,依照目前的...。

自2013年上市以来,长安汽车旗下的紧凑型轿车艾瑞泽7一度备受市场追捧,成为长安汽车旗下的明星车型,但是,近日有信息称,艾瑞泽7将停售,引发了不少消费者的不懂和关注,终究是什么要素造成了艾瑞泽7的停售呢,关于这一疑问,长安汽车相关人士曾示意,艾瑞泽7的停售是由于市场需求和消费方案等要素综合思考所致,详细的要素须要思考多方面的要素,但是...。

LG拼接屏的价格因素有哪些?,像素,对比度,lg拼接屏

棋盘游戏不仅能带来乐趣,还能锻炼我们的思维和策略能力,今天小编就来给大家推荐一下有趣的棋盘游戏有哪几个,在这些游戏中,你将感受到智慧的碰撞和策略的较量,不管是经典的棋类,还是创新的玩法,都能让你沉浸其中,准备好重新点燃那份对棋盘游戏的热爱了吗,1、,天天象棋,天天象棋,这款游戏特别是适合那些超级带象棋的玩家,可以随时随刻就来上一把快...。

是一个人口大国,所以但凡是关乎到百姓生活的一些项目,都有很大的经营前景,如今,让创业者们很满意的则是餐饮的市场,因为吃总是人们生活中离不开的一个需求,而现阶段吃的好更是大家普遍的餐饮方式,耙二哥是一个以腰片为主食材的火锅品牌,自制的锅底,在没有大厨的情况下也可以轻松经营,因此,这是一个很让创业者信赖的品牌,那么,加盟耙二哥腰片王老火锅...。

7月17日消息,今年5月11日,网易服务器出现大面积瘫痪,致多数网易产品和客户端无法连接和刷新,后来网易回应称因骨干网络遭受攻击,导致网易旗下部分服务暂时无法正常使,这才没过多久,网易邮箱又出了问题,昨天晚上10,11点之间,微博上陆续有网友反馈网易邮箱出现登陆故障,具体表现为客户端提示无法登陆,网页端显示,繁忙的系统暂时需要停下歇歇...。

米线是餐饮市场上一中大众化的小吃,劲道爽滑的口感,丰富营养价值,在市场上拥有一大批顾客粉丝,不管走到哪里,都能见到各种米线店,多种美食组合,丰富口味,店面生意很好,老汤和乌鸡米线致力为消费者带去好吃不贵的米线系列美食,实惠消费价格,受众群体广,发展前景广,博得一些创业者的关注,那么老汤和乌鸡米线加盟需要多少钱,怎么开店,老汤和乌鸡米线...。

沃尔玛周二宣布,计划增加提供无人机送货的门店数量,未来将在六个州34个地点空运货物,包括亚利桑那州、阿肯色州、佛罗里达州、德克萨斯州、犹他州和弗吉尼亚州部分地区的400万户家庭,这是一个显著的增长,当该公司于2021年11月推出该项目时,还只在阿肯色州的一个城镇提供服务,沃尔玛一直在测试如何使这种小型无人驾驶飞机改变零售业的游戏规则,...。
